一致性Hash 分析和实现
---
title: 1.一致性Hash
date: 2018-02-05 12:03:22
categories:
- 一致性Hash
---
一下分析来源于网络总结:算法参照自己实现,共参考和指正。
一致性Hash算法背景
一致性哈希算法在1997年由麻省理工学院的Karger等人在解决分布式Cache中提出的,设计目标是为了解决因特网中的热点(Hot spot)问题,初衷和CARP十分类似。一致性哈希修正了CARP使用的简单哈希算法带来的问题,使得DHT可以在P2P环境中真正得到应用。
但现在一致性hash算法在分布式系统中也得到了广泛应用,研究过memcached缓存数据库的人都知道,memcached服务器端本身不提供分布式cache的一致性,而是由客户端来提供,具体在计算一致性hash时采用如下步骤:
- - 首先求出memcached服务器(节点)的哈希值,并将其配置到0~232的圆(continuum)上。
- - 然后采用同样的方法求出存储数据的键的哈希值,并映射到相同的圆上。
- - 然后从数据映射到的位置开始顺时针查找,将数据保存到找到的第一个服务器上。如果超过232仍然找不到服务器,就会保存到第一台memcached服务器上。
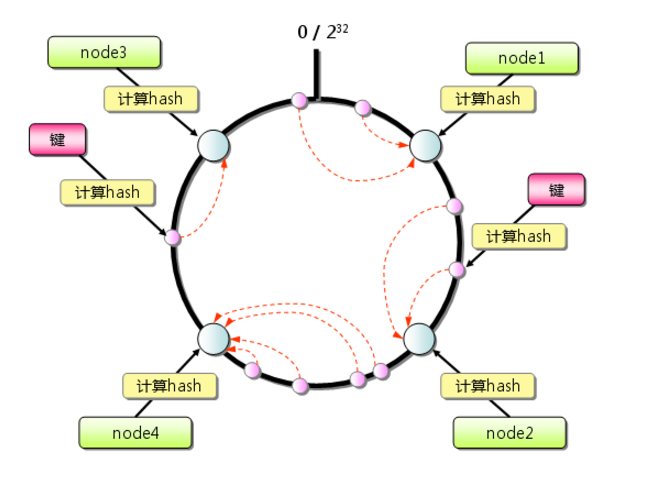
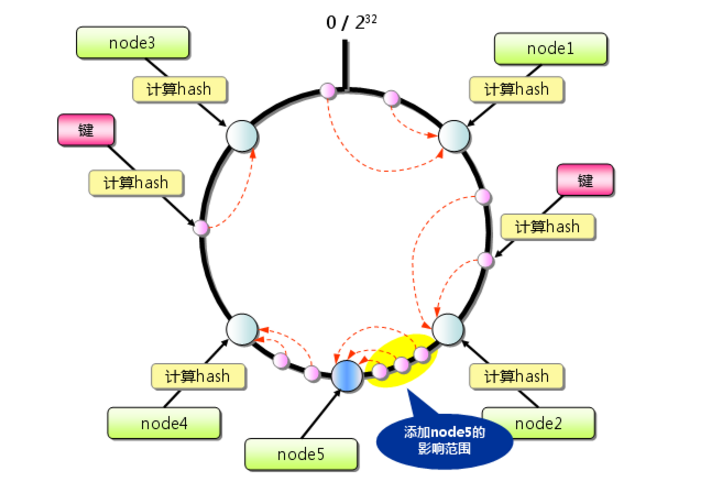
从上图的状态中添加一台memcached服务器。余数分布式算法由于保存键的服务器会发生巨大变化而影响缓存的命中率,但Consistent Hashing中,只有在园(continuum)上增加服务器的地点逆时针方向的第一台服务器上的键会受到影响,如下图所示:
原理
基本概念
简单来说,一致性哈希将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希空间环如下:

整个空间按顺时针方向组织。0和232-1在零点中方向重合。
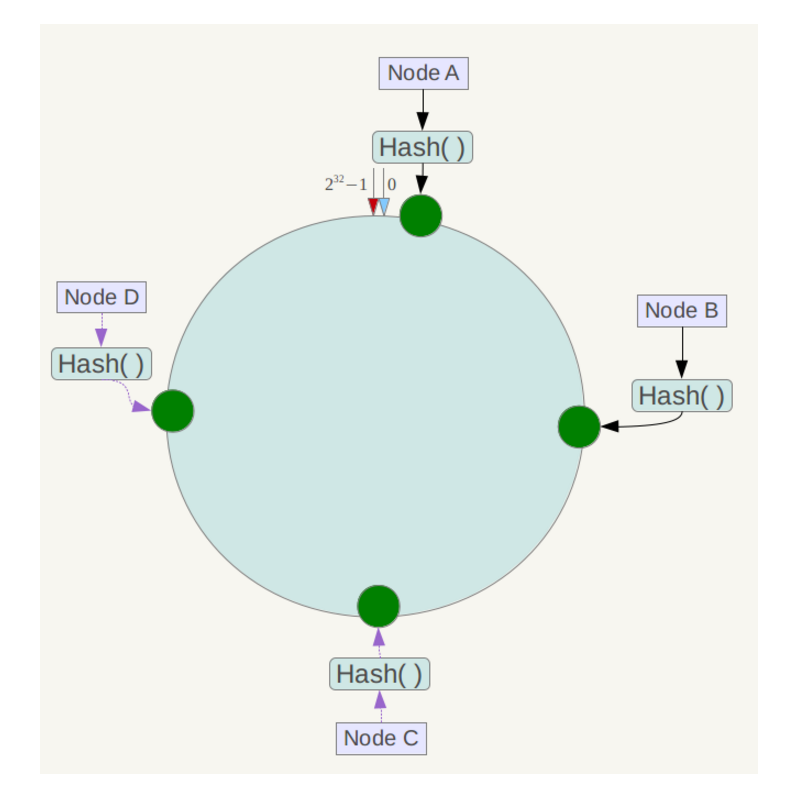
下一步将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置,这里假设将上文中四台服务器使用ip地址哈希后在环空间的位置如下:
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
例如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:
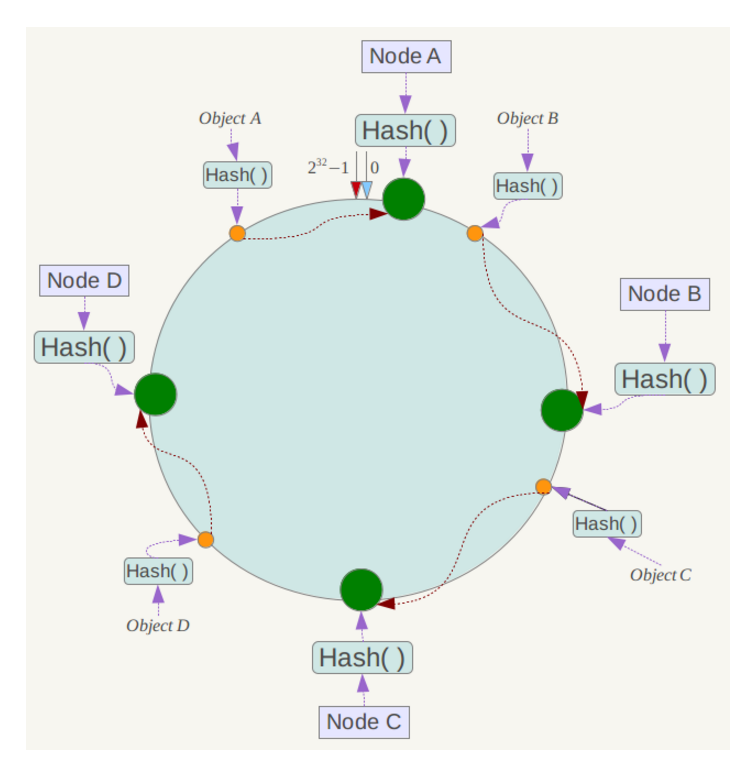
根据一致性哈希算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
下面分析一致性哈希算法的容错性和可扩展性。现假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
下面考虑另外一种情况,如果在系统中增加一台服务器Node X,如下图所示:
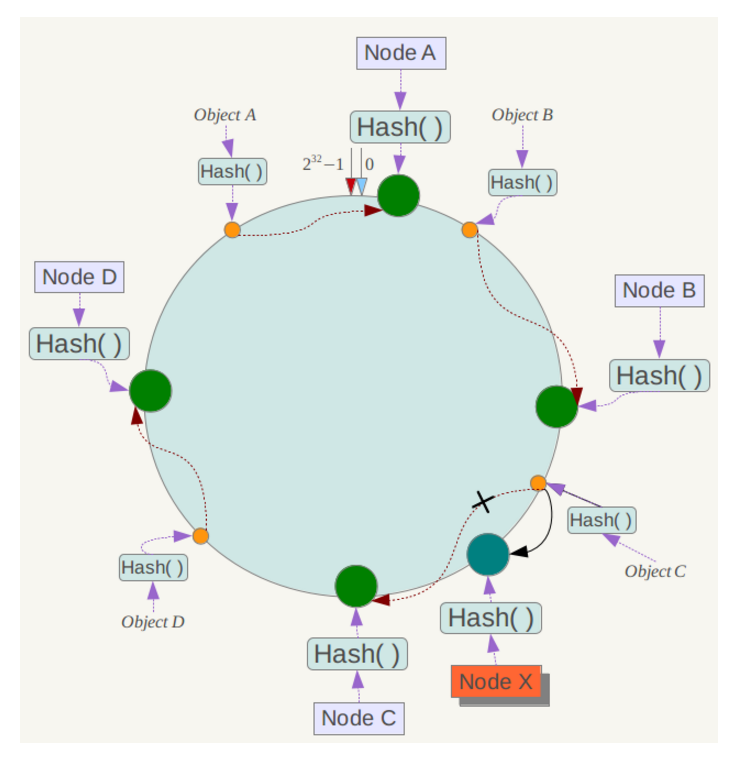
此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X 。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
算法实现:
1 package com.maozw.algorithm; 2 3 import java.util.SortedMap; 4 import java.util.TreeMap; 5 6 /** 7 * @author MAOZW 8 * @Description: 不带虚拟节点的一致性Hash算法 9 * @date 2018/11/22 16:30 10 */ 11 public class ConsistentHashNoNode { 12 13 /** 14 * 初始化 key表示服务器的hash值,value表示服务器的名称 15 */ 16 private static SortedMap<Integer, String> serverHashMap = new TreeMap<Integer, String>(); 17 18 public static String getServer(String data) { 19 return serverHashMap.get(serverHashMap.tailMap(hash(data)).firstKey()); 20 } 21 22 /** 23 * 构建hash环 24 * @param servers 25 */ 26 public ConsistentHashNoNode(String[] servers) { 27 for (int i = 0; i < servers.length; i++) { 28 int hash = hash(servers[i]); 29 serverHashMap.put(hash, servers[i]); 30 } 31 } 32 33 /** 34 * FNV1_32_HASH 百度 35 * @param str 36 * @return 37 */ 38 public static int hash(String str) { 39 final int p = 16777619; 40 int hash = (int)2166136261L; 41 for (int i = 0; i < str.length(); i++) { 42 hash = (hash ^ str.charAt(i)) * p; 43 } 44 hash += hash << 13; 45 hash ^= hash >> 7; 46 hash += hash << 3; 47 hash ^= hash >> 17; 48 hash += hash << 5; 49 return Math.abs(hash); 50 } 51 52 public static void main(String[] args) { 53 //构建服务器列表 54 String[] servers = {"192.168.1.0:098", "192.168.1.0:099", "192.168.1.0:100","192.168.1.0:111", "192.168.1.1:112", "192.168.1.2:113", "192.168.0.3:114", "192.168.0.4:115"}; 55 new ConsistentHashNoNode(servers); 56 for (int i = 0; i < 10; i++) { 57 System.out.println("data : " + i + ", hash " + hash(String.valueOf(i)) + " >>>>>>> " + getServer(String.valueOf(i))); 58 } 59 } 60 }
输出结果:
data : 0, hash 1360261864 >>>>>>> 192.168.0.4:115 data : 1, hash 1081142246 >>>>>>> 192.168.0.3:114 data : 2, hash 1310673766 >>>>>>> 192.168.0.4:115 data : 3, hash 895667540 >>>>>>> 192.168.0.3:114 data : 4, hash 1066967047 >>>>>>> 192.168.0.3:114 data : 5, hash 1039214538 >>>>>>> 192.168.0.3:114 data : 6, hash 853429834 >>>>>>> 192.168.0.3:114 data : 7, hash 679338660 >>>>>>> 192.168.0.3:114 data : 8, hash 570677376 >>>>>>> 192.168.0.3:114 data : 9, hash 1632757952 >>>>>>> 192.168.1.0:098
另外,一致性哈希算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜问题。例如系统中只有两台服务器,其环分布如下,
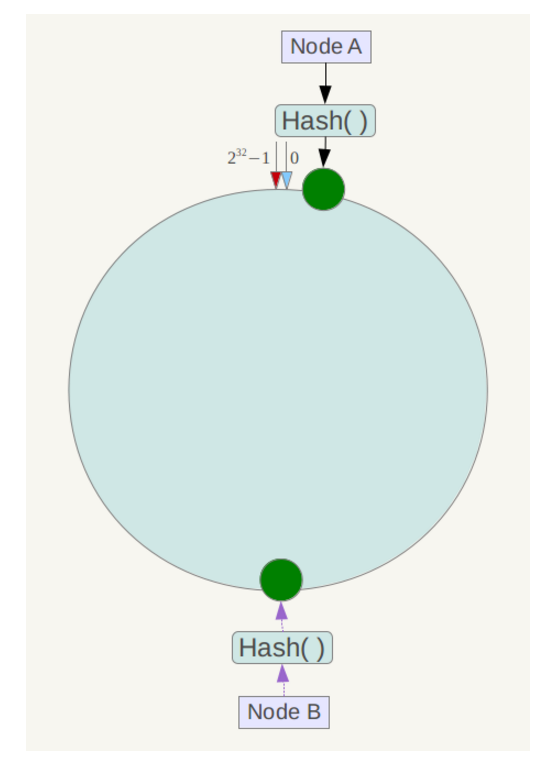
此时必然造成大量数据集中到Node A上,而只有极少量会定位到Node B上。为了解决这种数据倾斜问题,一致性哈希算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器ip或主机名的后面增加编号来实现。例如上面的情况,可以为每台服务器计算三个虚拟节点,于是可以分别计算 “Node A#1”、“Node A#2”、“Node A#3”、“Node B#1”、“Node B#2”、“Node B#3”的哈希值,于是形成六个虚拟节点:
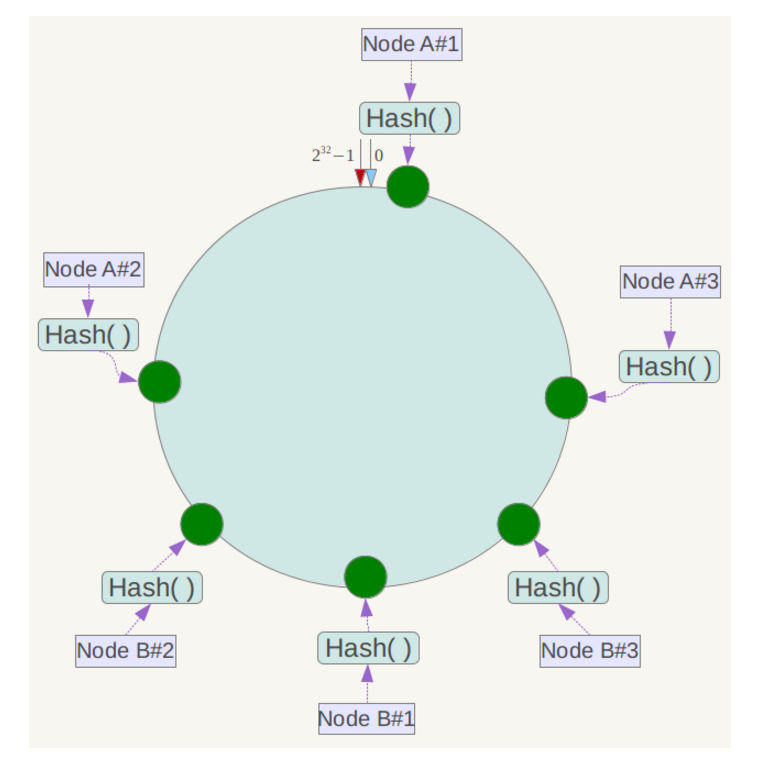
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,例如定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上。这样就解决了服务节点少时数据倾斜的问题。在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。