说起这个mysql的架构啊,相信大家的脑海里会浮现一张图:
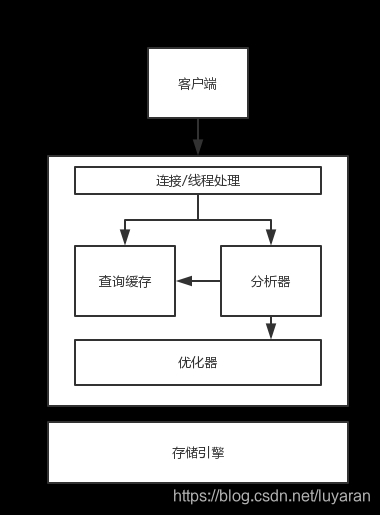
老生常谈的话题,咱们先来分析下这张图,主要有三个层次:
- 最上面的一层,连接层,主要是连接与线程处理,这一层并不是MySQL独有,一般的基于C/S架构的都有类似组件,比如连接处理、授权认证、安全等。
- 第二次叫sql处理层,也叫MySQL服务器层,这是MySQL的核心部分,还可以叫做 SQL Layer,包括缓存查询、解析器、优化器,在 MySQL据库系统处理底层数据之前的所有工作都是在这一层完成的,这一层包含了MySQL核心功能,包括解析、优化SQL语句,查询缓存目录,内置函数(日期、时间、加密等函数)的实现,还有各个存储引擎提供的功能都集中在这一层,如存储过程,触发器,视 图等。
- 最后就是数据存储层,也叫存储引擎层,负责数据存储,存储引擎的不同,存储方式、数据格式、提取方式等都不相同,这一部分也是很大影响数据存储与提取的性能的。但是,与分层的思想一致,SQL处理层是通过API与存储引擎通信的,API屏蔽了下层的差异,下层提供对外接口,上层负责调用即可,不必清楚下层是怎么实现的。
我们来总结下从上图中了解到的一些信息:
- 1)mysql是一个C/S架构模型,客户端通过与服务端建立连接来操作服务端数据;
- 2)服务端的连接模块,将每一个客户端发送来的请求作为一个线程处理;
- 3)分析器分析请求,并转发给优化器;
- 4)通过缓存的方式提高查询性能;
- 5)优化器负责和底层的存储引擎进行交互,存储和查询mysql的数据;
既然MySQL是基于C/S架构的,这里的客户端自然是专门的,能访问到MySQL服务器的,主要有这么几类,操作客户端:单纯的操作MySQL服务器中的数据(这里数据包括库、表、索引、表中数据等),比如常用的native、phpMyAdmin、Sequal Pro等;应用客户端:应用程序通过程序访问数据库,比如JDBC、ODBC、PHP程序、python程序等。不管是哪种,其实最后都转换为SQL语句访问MySQL。
好,到这里嘞,咱们来具体看下上述的mysql架构的三个层次是咋工作的???
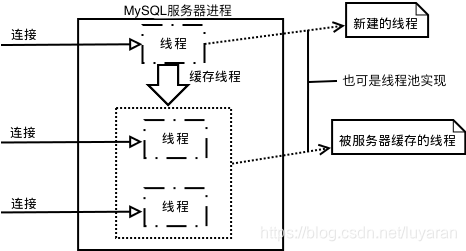
首先就是连接层,也就是当MySQL启动(MySQL服务器就是一个进程),完事就等待客户端连接,每当一个客户端发送连接请求,服务器都会新建一个线程处理(如果是线程池的话,则是分配一个空的线程),每个线程独立,拥有各自的内存处理空间,但是,如果这个请求只是查询,没关系,但是若是修改数据,很显然,当两个线程修改同一块内存是会引发数据同步问题的,来看下连接处理的流程图:
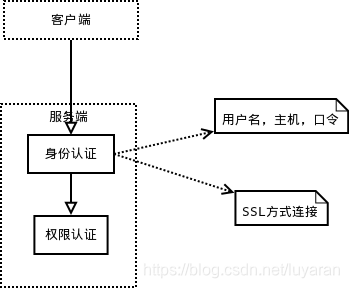
之后,当我们连接到服务器时,服务器需要对其进行验证,也就是用户名、IP、密码验证,一旦连接成功,还要验证是否具有执行某个特定查询的权限(例如,是否允许客户端对某个数据库某个表的某个操作) 来看下这个认证过程的流程图:
到这里,相信大家会有一点点明了了,再来最后总结下,如下:
在我们服务器内部,每个client连接都有自己的线程,这个连接的查询都在一个单独的线程中执行,同时这些线程轮流运行在某一个CPU内核(多核CPU)或者CPU中。然而,我们的服务器缓存了线程,因此不需要为每个client连接单独创建和销毁线程 。当clients(也就是应用程序)连接到了MySQL服务器。服务器就需要对它进行认证(Authenticate),这个认证也就是基于用户名,主机,以及密码,但是,对于使用了SSL(安全套接字层)的连接,还使用了X.509证书。最后嘞,clients一连接上,服务器就验证它的权限 (如是否允许客户端可以查询world数据库下的Country表的数据)。
好啦,咱们再来看下第二层,也就是sql处理层。
这一层主要功能有:SQL语句的解析、优化,缓存的查询,MySQL内置函数的实现,跨存储引擎功能(所谓跨存储引擎就是说每个引擎都需提供的功能(引擎需对外提供接口)),例如:存储过程、触发器、视图等。
咱们先来简单看下执行sql的一个流程图:
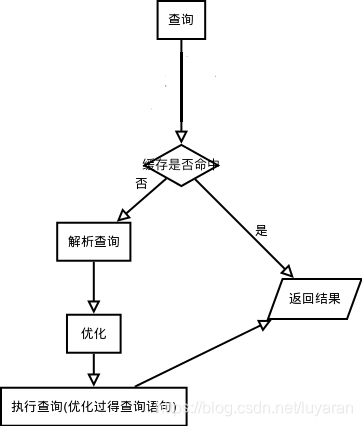
上图呢,只是一个简单的过程,不是特定的某个类型的sql,我们可以来代入下试试。
如果是查询语句(select语句),首先会查询缓存是否已有相应结果,有则返回结果,无则进行下一步(如果不是查询语句,同样调到下一步)。
另外嘞,我们来看下这个MySQL在这一步,进行的操作。
首先,它在解析查询之前,要查询缓存,这个缓存只能保存查询信息以及结果数据。如果请求一个查询在缓存中存在,就不需要解析,优化和执行查询了,可以直接返回缓存中所存放的这个查询的结果,反之嘞,就会解析查询,并创建了一个内部数据结构(解析树),然后对其进行各种优化。这些优化包括了,查询语句的重写,读表的顺序,索引的选择等等。用户可以通过查询语句的关键词传递给优化器以便提示使用哪种优化方式,这样就影响了优化器的优化方式,咱这里先不说好坏啊。另外,用户也可以请求服务器给出优化过程的各种说明,以获知服务器的优化策略,为用户提供了参数基准,以便用户可以重写查询,架构和修改相关服务器配置,便于mysql更高效的运行。
咱要注意的是,优化器并是不关心表使用了哪种存储引擎,但是存储引擎对服务器优化查询的方式是有影响的。优化器需要知道存储引擎的一些特性:具体操作的性能和开销方面的信息,以及表内数据的统计信息。例如,存储引擎支持哪些索引类型,这对于查询是非常有用的。
来看下最后一层,存储数据的层面。我们只需要知道,不同的存储引擎会采用不同的技术(存储机制、索引机制、锁定机制)存储数据,这主要是为了满足数据存储要求,比如有的数据不需要大量的改动,只用来查询,而有的数据则需要常常修改(数据插入、删除、更新),针对各种业务情况,为了更好的数据处理效率采用不同的数据存储技术(即不同存储引擎)。还要注意的是,MySQL的存储引擎是插件式的,也就是说,用户可以随时切换MySQL的存储引擎:针对表或针对库都可(通过SQL语句命令)。这种灵活性也是为什么MySQL受到欢迎的一个重要原因。MySQL集合了多种引擎:MyISAM、InnoDB、BDB、Merge、Memory等,默认的是InnoDB(MySQL5.5开始,以前是MyISAM)。
这个存储引擎接口模块可以说是 MySQL 数据库中最有特色的一点了,我们可以看到,目前各种数据库产品中,基本上只有 MySQL 可以实现其底层数据存储引擎的插件式管理。实际上这个模块只是一个抽象类,但正是因为它成功地将各种数据处理高度抽象化,才成就了今天 MySQL 可插拔存储引擎的特色。
咱们不废话啊,再来看下MySQL的物理文件组成,包含三个模块:
1)日志文件
1-1)Error log 错误日志:记录遇到的所有严重的错误信息、每次启动关闭的详细信息;
1-2)Binary log 二进制日志:也就是binlog,记录所有修改数据库的操作;
1-3)Query log 查询日志:记录所有查询操作,体积较大,开启后对性能有影响;
1-4)Slow Query log 慢查询日志:记录所有执行时间超过long_query_time的sql语句和达到min_examined_row_limit条距离的语句;
1-5)InnoDB redo log:记录InnoDB所做的物理变更和事务信息;
2)数据文件
2-1).frm文件:表结构定义信息
2-2).MYD文件:MyISAM引擎的数据文件;
2-3).MYI文件:MyISAM引擎的索引文件;
2-4).ibd文件和.ibdata文件:InnoDB的数据和索引;.ibdata配置为共享表空间时使用,.ibd配置为独享表空间时使用;
3)其它文件
3-1)系统配置文件:/etc/my.cnf
3-2) pid文件:存储自己的进程ID
3-3)socket文件:连接客户端使用
最后,就是今天最最重要的sql逻辑模块组成这一部分了。
mysql逻辑架构采用sql层和存储引擎分离的方式,实现了数据存储和逻辑业务的分离,我们在宏观层次上可以分为三个组成部分,如下:
- 连接处理层
- 分析、缓存处理层
- 优化器层
我感觉有点笼统啊,咱们再来细细的化分下:
- 初始化模块:数据库启动时,对数据库的初始化操作;
- 核心API模块:底层操作的优化功能;
- 网络交互模块:对外提供可接收发送数据的API接口;
- 服务器客户端交互协议模块:实现客户端服务端的交互协议;
- 用户模块:控制用户连接登录和授权;
- 访问控制模块:监控用户的每一个操作,依赖于用户模块;
- 连接管理、连接线程和线程管理模块:监听和管理与客户端连接的线程;
- 转发模块:将请求转发到对应的处理模块;
- 缓存模块:将查询请求的结果缓存,提高性能;
- 优化器模块:根据查询请求计算提高查询访问速度的优化策略,根据最优策略返回查询语句;
- 表变更模块:DML和DDL的语句处理;
- 表维护模块:检测表状态、分析、优化表结构、修复表;
- 系统状态管理模块:将各种状态数据返回,如:show status;
- 表管理器:维护系统生成的表文件如:.frm文件.ibd文件...将表结构的信息缓存,另外该模块还管表级别的锁;
- 日志记录模块:负责整个数据库逻辑层的日志文件;
- 复制模块:分为Master模块和Slave模块;Master模块负责复制binary文件,并与Slave端I/O线程交互;Slave模块主要负责从Master端接收binary日志,并写入本地I/O线程,以及从relay log文件中读取日志,解析成Slave端执行的命令,交给Slave端的SQL线程处理;
- 存储引擎接口模块:实现了底层存储引擎插件式管理,将数据处理高度抽象化;
再来看下sql逻辑模块是如何协调工作的哈,流程图如下:
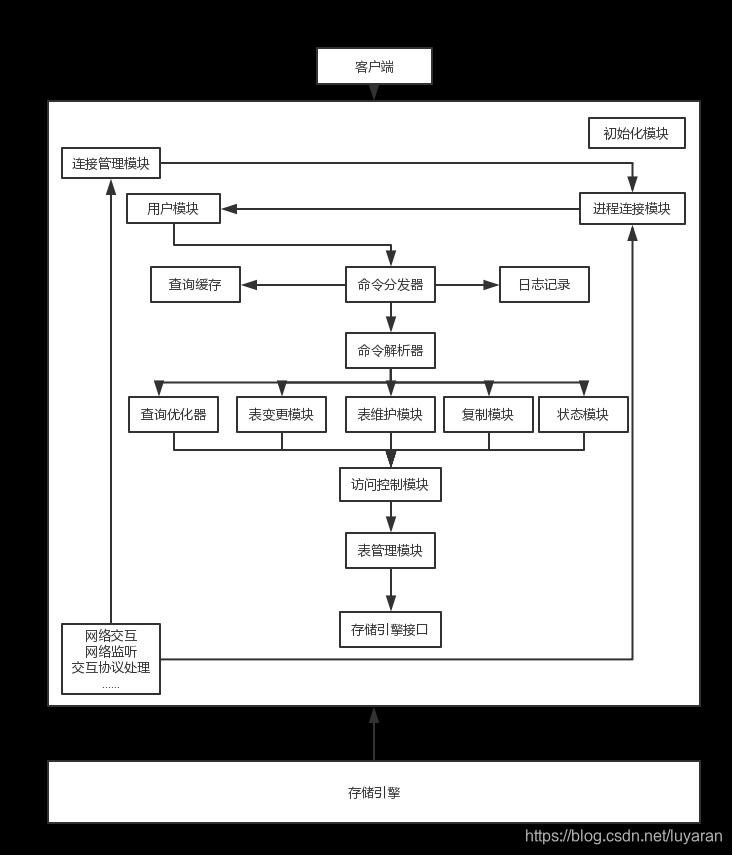
解析如下:
- mysql启动以后,初始化模块就从系统配置文件中读取系统参数和命令参数,初始化整个系统,同时存储引擎也会启动;
- 初始化结束后,连接管理模块会监听客户端的连接请求,并将连接请求转发给线程管理模块去请求一个连接线程;
- 线程模块接到请求后会调用用户模块进行授权检查,通过授权以后会检查是否又空闲线程,如果有取出并与客户端连接,如果没有则新建立建立一个线程与客户端连接;
- mysql请求分为两种,一种是需要命令解析和分发才能执行,另一种可以直接执行;不管哪种,如果开启了日志,那么日志模块会记录日志;
- 如果是Query类型的请求,会将控制权交给Query解析器,Query解析器检查是否Select类型,如果是则启动查询缓存模块,如果缓存命中则将缓存数据返回给连接线程模块,连接线程将数据传递到客户端;如果没有缓存或者不是一个可以缓存的查询,此时解析器会进行相应的处理,通过查询分发器给相关的处理模块;
- 如果解析器结果是DML/DDL,则交给变更模块;如果是检查、修复的查询交给表维护模块,如果是一条没有被缓存的语句,则交给查询优化器模块。实际上表变更模块又分为若干小模块,例如:insert处理器、delete处理器、update处理器、create处理器,以及alter处理器这些小模块来负责不同的DML和DDL。总之,查询优化器、表变更模块、表维护模块、复制模块、状态模块都是根据命令解析器的结果不同而分发给不同的类型模块,最后和存储引擎进行交互。
- 当一条命令执行完毕后,控制权都会还给连接线程模块,在上面各个模块处理过程中都依赖于核心API模块,比如:内存管理、文件I/O,字符串处理等。
到这里嘞,就差不多结束了。
希望通过这篇文章,能够让大家对于这个MySQL的所谓的架构有一些简单的了解。
好啦,本次记录就到这里了。
如果感觉不错的话,请多多点赞支持哦。。。