solr是什么呢?
一、Solr它是一种开放源码的、基于 Lucene Java 的搜索服务器,易于加入到 Web 应用程序中。
二、Solr 提供了层面搜索(就是统计)、命中醒目显示并且支持多种输出格式(包括XML/XSLT 和JSON等格式)。它易于安装和配置,而且附带了一个基于 HTTP 的
管理界面。Solr已经在众多大型的网站中使用,较为成熟和稳定。
三、Solr 包装并扩展了 Lucene,所以Solr的基本上沿用了Lucene的相关术语。更重要的是,Solr 创建的索引与 Lucene 搜索引擎库完全兼容。
四、通过对Solr 进行适当的配置,某些情况下可能需要进行编码,Solr 可以阅读和使用构建到其他 Lucene 应用程序中的索引。
五、此外,很多 Lucene 工具(如Nutch、 Luke)也可以使用Solr 创建的索引。可以使用 Solr 的表现优异的基本搜索功能,也可以对它进行扩展从而满足企业的需要。
solr的优点
通过上面Solr的简介,可知solr的优点包括以下几个方面:
①高级的全文搜索功能;
②专为高通量的网络流量进行的优化;
③基于开放接口(XML和HTTP)的标准;
④综合的HTML管理界面;
⑤可伸缩性-能够有效地复制到另外一个Solr搜索服务器;
⑥使用XML配置达到灵活性和适配性;
⑦可扩展的插件体系。
solr VS Lucene!?
在比较solr和Lucene之前,要知道什么是Lucene,那么首先就来回顾Lucene是个什么东东?
Lucene是一个基于Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是 Apache Jakarta(雅加达) 家族中的一个开源项目。也是目前最为流行的基于Java开源全文检索工具包。目前已经有很多应用程序的搜索功能是基于 Lucene ,比如Eclipse 帮助系统的搜 索功能。Lucene能够为文本类型的数据建立索引,所以你只要把你要索引的数据格式转化的文本格式,Lucene 就能对你的文档进行索引和搜索。
那么,solr和它相比,是”输“了?还是“赢”了呢?
其实,Solr与Lucene 并不是竞争对立关系,恰恰相反Solr 依存于Lucene,因为Solr底层的核心技术是使用Lucene 来实现的,Solr和Lucene的本质区别有以下三点:搜索服务器,企业级和管理。Lucene本质上是搜索库,不是独立的应用程序,而Solr是。Lucene专注于搜索底层的建设,而Solr专注于企业应用。Lucene不负责支撑搜索服务所必须的管理,而Solr负责。所以说,一句话概括 Solr: Solr是Lucene面向企业搜索应用的扩展。
下面是solr和 lucene的架构图:
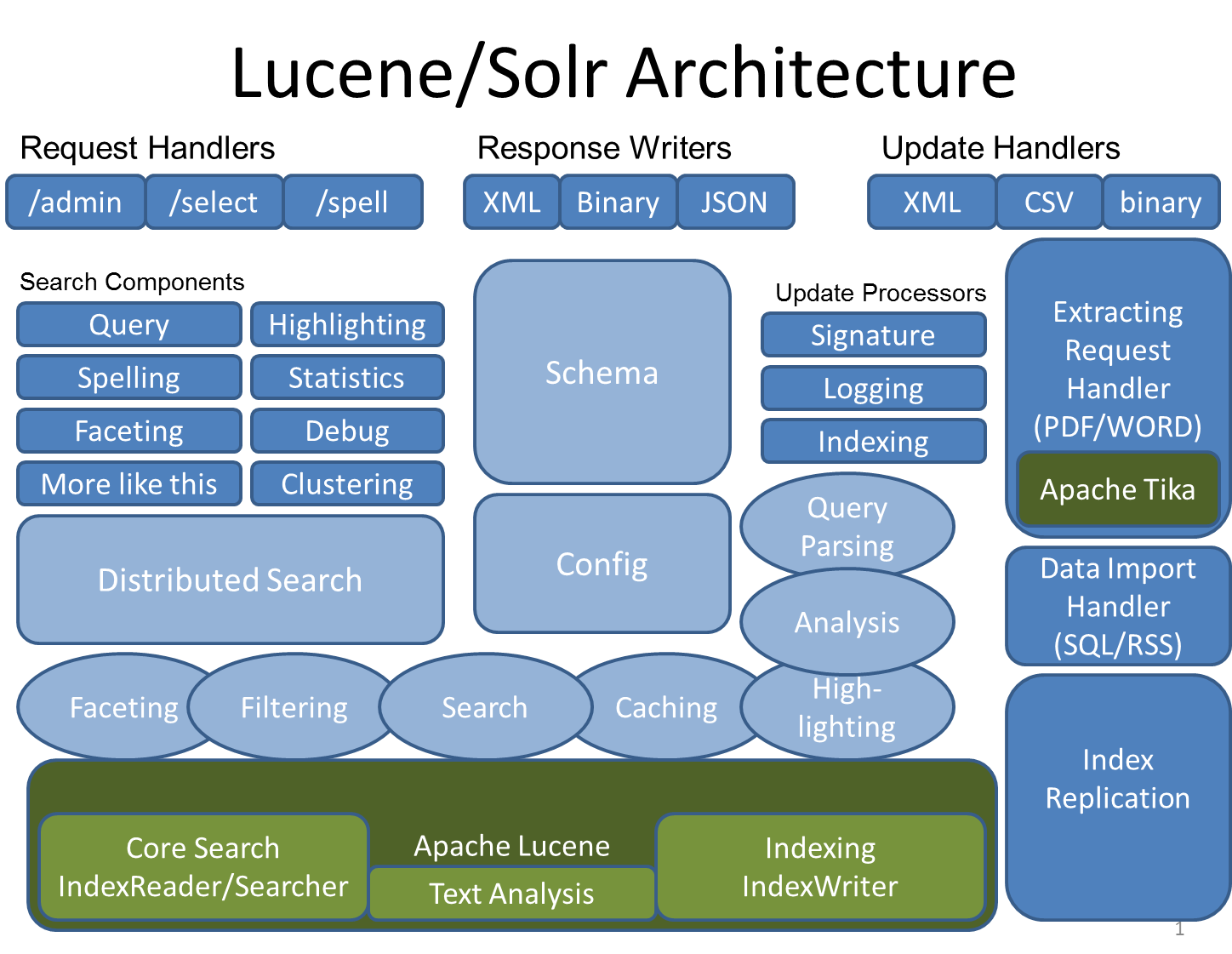
这个图很繁琐,看不懂,大家不要灰心,在后面的代码里你就能够了解了这个图所讲的。
不难看出,绿色的就是lucene的模块,而蓝色的就是solr扩展了lucene。从图上可以看出以下几点:
a. 一个真正的拥有动态字段(Dynamic Field)和唯一键(Unique Key)的数据模式(Data Schema)
b. 对Lucene查询语言的强大扩展!
c. 支持对结果进行动态的分组和过滤
d. 高级的,可配置的文本分析
e. 高度可配置和可扩展的缓存机制
f. 性能优化
g. 支持通过XML进行外部配置
h. 拥有一个管理界面
i. 可监控的日志
j. 支持高速增量式更新(Fast incremental Updates)和快照发布(Snapshot Distribution)
说到这,solr的简介就到此结束了,相信大家也对solr有了初步的了解,下面开始介绍一下solr的常用属性有哪些?
solr的使用属性及配置文件
Document 包括一个或多个 Field。Field 包括名称、内容以及告诉 Solr 如何处理内容的元数据。
例如,Field可以包含字符串、数字、布尔值或者日期,也可以包含你想添加的任何类型,只需用在solr的配置文件中进行相应的配置即可。Field可以使用大量的选项来描述,这些
选项告诉 Solr 在索引和搜索期间如何处理内容。
现在,查看以下图片 中列出的重要属性的子集:

在这就先提一下solr的重要文件之一,就是schema.xml的配置文件。
(一) schema.xml
schema.xml这个配置文件可以在你下载solr包的安装解压目录的\solr\example\solr\collection1\conf中找到,它就是solr模式关联的文件。
打开这个配置文件,你会发现有详细的注释。模式组织主要分为三个重要配置:
一、Fieldtype
Fieldtype:就是属性类型的意思,像int,String,Boolean种类型,而在此配置文件中,FieldType就有这种定义属性的功能,看下面的图片:

图片上有我们熟悉的int,String,boolean,那么,后面的配置,是什么呢?那么我们就来介绍一下后面的参数:

二、Field
Field:是添加到索引文件中出现的属性名称,而声明类型就需要用到上面的type,如图所示:

ps:①field: 固定的字段设置;②dynamicField: 动态的字段设置,用于后期自定义字段,*号通配符.例如: test_i就是int类型的动态字段。
还有一个特殊的字段copyField,一般用于检索时用的字段这样就只对这一个字段进行索引分词就行了copyField的dest字段如果有多个source一定要设置multiValued=true,否则会报错的。

在Field里也有一些属性需要了解,看图: 

三、其他配置
①uniqueKey: 唯一键,这里配置的是上面出现的fileds,一般是id、url等不重复的。在更新、删除的时候可以用到。
②defaultSearchField:默认搜索属性,如q=solr就是默认的搜索那个字段
③solrQueryParser:查询转换模式,是并且还是或者(AND/OR必须大写)
(二)solrconfig.xml
solrconfig.xml这个配置文件可以在你下载solr包的安装解压目录的E:\Work\solr-4.2.0-src-idea\solr\example\solr\collection1\conf中找到,这个配置文件内容有点多,主要内容有:使
用的lib配置,包含依赖的jar和Solr的一些插件;组件信息配置;索引配置和查询配置,下面详细说一下索引配置和查询配置.
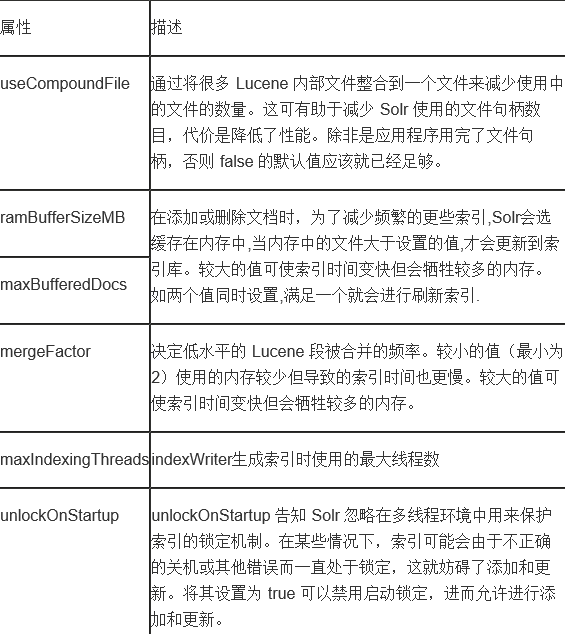
一、索引indexConfig
Solr 性能因素,来了解与各种更改相关的性能权衡。 下表概括了可控制 Solr 索引处理的各种因素:

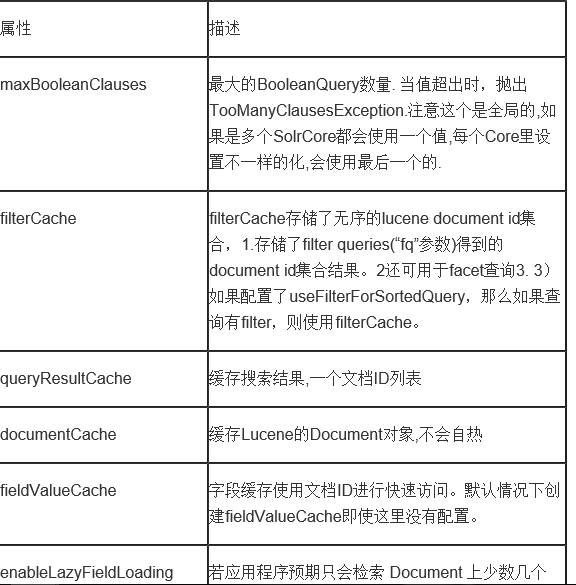
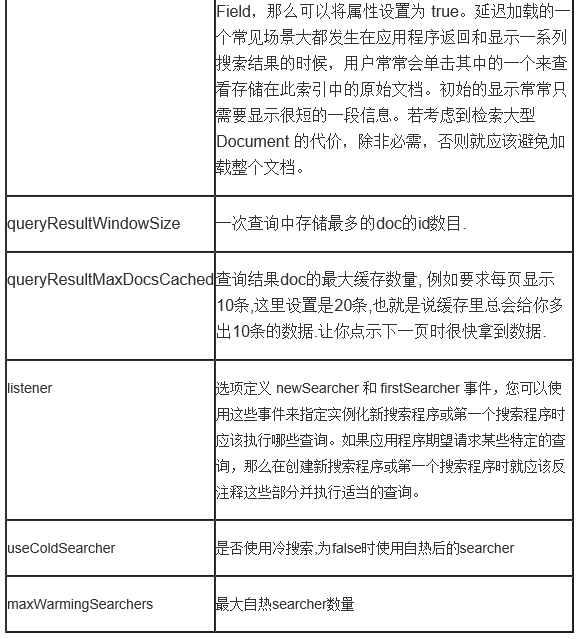
二、查询配置query
(三)加入中文分词器
中文分词在solr里面是没有默认开启的,需要我们自己配置一个中文分词器。目前可用的分词器有smartcn,IK,Jeasy,庖丁。其实主要是两种,一种是基于中科院ICTCLAS的
隐式马尔科夫HMM算法的中文分词器,如smartcn,ictclas4j,优点是分词准确度高,缺点是不能使用用户自定义词库;另一种是基于最大匹配的分词器,如IK ,Jeasy,庖丁,
优点是可以自定义词库,增加新词,缺点是分出来的垃圾词较多。各有优缺点看应用场合自己衡量选择吧。
下面给出两种分词器的安装方法,任选其一即可,推荐第一种,因为smartcn就在solr发行包的contrib/analysis-extras/lucene-libs/下,就是lucene-analyzers-smartcn-4.2.0.jar,首选
在solrconfig.xml中加一句引用analysis-extras的配置,这样我们自己加入的分词器才会引到的solr中.
<lib dir="../../../contrib/analysis-extras/lib" regex=".*\.jar" />
一、 smartcn 分词器的安装
首选将发行包的contrib/analysis-extras/lucene-libs/ lucene-analyzers-smartcn-4.2.0.jar复制到\solr\contrib\analysis-extras\lib下,在solr本地应用文件夹下,打开/solr/conf/scheme.xml,
编辑text字段类型如下,添加以下代码到scheme.xml中的相应位置,就是找到fieldType定义的那一段,在下面多添加这一段就好了:

01.<fieldType name="text_smartcn" class="solr.TextField" positionIncrementGap="0"> 02. 03. <analyzer type="index"> 04. 05. <tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/> 06. 07. <filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/> 08. 09. </analyzer> 10. 11. <analyzer type="query"> 12. 13. <tokenizer class="org.apache.lucene.analysis.cn.smart.SmartChineseSentenceTokenizerFactory"/> 14. 15. <filter class="org.apache.lucene.analysis.cn.smart.SmartChineseWordTokenFilterFactory"/> 16. 17. </analyzer> 18. 19.</fieldType>
如果需要检索某个字段,还需要在scheme.xml下面的field中,添加指定的字段,用text_ smartcn作为type的名字,来完成中文分词。如 text要实现中文检索的话,就要做如下的配置:
<field name ="text" type ="text_smartcn" indexed ="true" stored ="false" multiValued ="true"/>
还有一个就是 IK分词器,因为在5.0之后才有的IKAnalyzer的jar包,这里学习用的是solr4.9版本,在这里就不多详细介绍IKAnalyzer。有兴趣的同学可以根据下面的路径下载Jar包:
路径:http://ik-analyzer.googlecode.com/files/IK%20Analyzer%202012FF_hf1.zip.
下载后解压出来文件中的三个复制到\solr\contrib\analysis-extras\lib目录中.
IKAnalyzer2012FF_u1.jar 分词器jar包
IKAnalyzer.cfg.xml 分词器配置文件
Stopword.dic 分词器停词字典,可自定义添加内容
复制后就可以像smartcn一样的进行配置scheme.xml了.
01.<fieldType name="text_ik" class="solr.TextField"> 02. 03. <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> 04. 05. </fieldType> 06. 07. <field name ="text" type ="text_ik" indexed ="true" stored ="false" multiValued ="true"/>
现在来验证下是否添加成功,首先使用StartSolrJetty来启动solr服务,启动过程中如果配置出错,一般有两个原因:一是配置的分词器jar找不到,也就是你没有复制jar包到\solr\contrib\analysis-extras\lib目前下;二是分词器版本不对导致的分词器接口API不一样出的错,要是这个错的话就在检查分词器的相关文档,看一下支持的版本是否一样.
如果在启动过程中没有报错的话说明配置成功了.我们可以进入到http://localhost:8983/solr地址进行测试一下刚加入的中文分词器.在首页的Core Selector中选择你配置的Croe
后点击下面的Analysis,在Analyse Fieldname / FieldType里选择你刚才设置的字段名称或是分词器类型,在Field Value(index)中输入:中国人,点击右面的分词就行了。
solr的POJO
一、什么是POJO?
POJO(Plain Ordinary Java Object)简单的Java对象,实际就是普通JavaBeans,是为了避免和EJB混淆所创造的简称。
使用POJO名称是为了避免和EJB混淆起来, 而且简称比较直接. 其中有一些属性及其getter setter方法的类,没有业务逻辑,有时可以作为VO(value -object)或dto(Data Transform
Object)来使用.当然,如果你有一个简单的运算属性也是可以的,但不允许有业务方法,也不能携带有connection之类的方法。
二、POJO的特点
POJO特点如下:
①POJO是Plain OrdinaryJava Object的缩写不错,但是它通指没有使用Entity Beans的普通java对象,可以把POJO作为支持业务逻辑的协助类。
②POJO实质上可以理解为简单的实体类,顾名思义POJO类的作用是方便程序员使用数据库中的数据表,对于广大的程序员,可以很方便的将POJO类当做对象来进行使用,
当然也是可以方便的调用其get,set方法。POJO类也给我们在struts框架中的配置带来了很大的方便。
三、POJO的代码演示
POJO有一些private的参数作为对象的属性。然后针对每个参数定义了get和set方法作为访问的接口。例如:
1 public class User {
2
3 private long id;
4
5 private String name;
6
7 public void setId(long id) {
8
9 this. id = id;
10
11 }
12
13 public void setName(String name) {
14
15 this. name=name;
16
17 }
18
19 public long getId() {
20
21 return id;
22
23 }
24
25 public String getName() {
26
27 return name;
28
29 }
30
31 }
POJO对象有时也被称为Data对象,大量应用于表现现实中的对象。如果项目中使用了Hibernate框架,有一个关联的xml文件,使对象与数据库中的表对应,对象的属性与表中的字段相对应。
四、POJO与JavaBean的区别
POJO和JavaBean是我们常见的两个关键字,一般容易混淆,POJO全称是Plain Ordinary Java Object / Pure Old Java Object,中文可以翻译成:普通Java类,具有一部分
getter/setter方法的那种类就可以称作POJO,但是JavaBean则比POJO复杂很多,Java Bean是可复用的组件,对 Java Bean并没有严格的规范,理论上讲,任何一个 Java 类都可以是一个 Bean 。但通常情况下,由于 Java Bean 是被容器所创建(如 Tomcat) 的,所以 Java Bean 应具有一个无参的构造器,另外,通常 Java Bean还要实现 Serializable 接口用于实现 Bean 的持久性。 Java Bean 是不能被跨进程访问的。JavaBean是一种组件技术,就好像你做了一个扳子,而这个扳子会在很多地方被拿去用,这个扳子也提供多种功能(你可以拿这个扳子扳、锤、撬等等),而这个扳子就是一个组件。一般在web应用程序中建立一个数据库的映射对象时,我们只能称它为POJO。POJO(Plain Old Java Object)这个名字用来强调它是一个普通java对象,而不是一个特殊的对象,其主要用来指代那些没有遵从特定的Java对象模型、约定或框架(如EJB)的Java对象。理想地讲,一个POJO是一个不受任何限制的Java对象(除了Java语言规范)[1] 。
错误的认识
POJO是这样的一种“纯粹的”JavaBean,在它里面除了JavaBean规范的方法和属性没有别的东西,即private属性以及对这个属性方法的public的get和set方法。我们会发现这样的JavaBean很“单纯”,它只能装载数据,作为数据存储的载体,而不具有业务逻辑处理的能力。
真正的意思
POJO = “Plain Old Java Object”,是MartinFowler等发明的一个术语,用来表示普通的Java对象,不是JavaBean, EntityBean 或者 SessionBean。POJO不担当任何特殊的角色,也不实现任何特殊的Java框架的接口如,EJB,JDBC等等。即POJO是一个简单的普通的Java对象,它不包含业务逻辑或持久逻辑等,但不是JavaBean、EntityBean等,不具有任何特殊角色和不继承或不实现任何其它Java框架的类或接口。
下面是摘自Martin Fowler个人网站的一句话:
“We wondered why people were so against using regular objects in their systems and concluded that it was because simple objects lacked a fancy name. So we gave them one, and it’s
caught on very nicely.”--Martin Fowler
我们疑惑为什么人们不喜欢在他们的系统中使用普通的对象,我们得到的结论是——普通的对象缺少一个响亮的名字,因此我们给它们起了一个,并且取得了很好的效果。——Martin Fowler
solr软件安装与简介
温馨提示:
一、保证环境必须在JDK1.7上;
二、tomCat建议在tomcat7以上版本;
三、如若不是solr4.9版本的,solr5.0以上建议tomCat在tomcat8以上;
四、solr4.9版本的核心类及常用的属性,和solr5.0以上的差不多,但是还有细微的区别,请注意!
一、安装solr步骤
步骤一、配置solr与TomCat集成
先把solr的压缩包去官网(http://archive.apache.org/dist/lucene/solr/)下载并解压,名称为: 

点击解压之后的文件夹,如图所示:
看到如上图所示,就证明下载和解压成功。接下来就是与tomcat集成(在此次学习中,我用的是tomcat8.0.33);
以下就是集成具体的步骤:
1、将解压之后 的文件夹里example文件夹下的solr文件夹中的所有文件(不含solr文件夹本身)
2、拷贝到D:\solrDemo\Solr文件下(solrDemo文件夹和Solr需自己手动创建),如下图所示:
3、将解压后的solr-4.9.0下的dist目录下的solr-4.9.0.war 文件
4、拷贝到D:\apache-tomcat-7.0.54\webapps文件夹下,重命名为solr.war,一定要自己解压这个war文件,(启动tomcat会自动解压,但是这个文件里面的lib目录的东西好像是解压不出来),看到webapps下面多了一个solr文件夹,如下图:
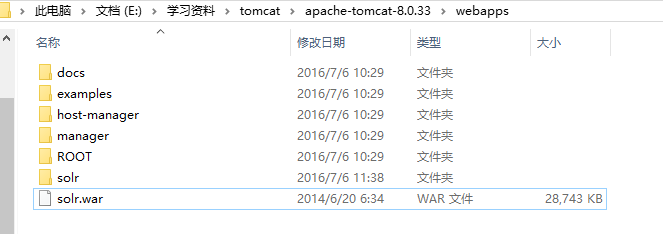
5、打开D:\solrDemo\Solr\collection1\conf下的solrconfig.xml文件:

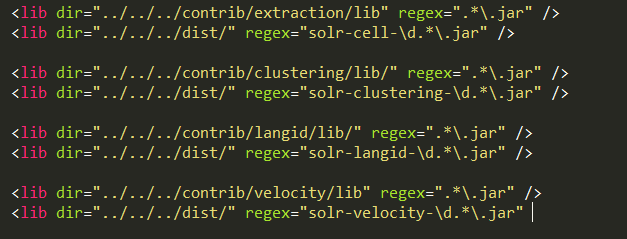
6、把以下这几个配置注释掉,因为用不到。
7、继续往下找到DataDir节点,修改值为${solr.data.dir:d:/solrDemo/Solr/data} ,data文件夹为存储查询索引和数据的地方,data文件夹自己创建。

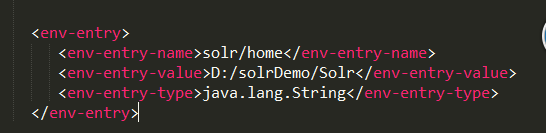
8、打开E:\学习资料\tomcat\apache-tomcat-8.0.33\webapps\solr\WEB-INF文件夹下的web.xml文件,增加env-entry节点(默认是注释掉的),修改值为value>D:/solrDemo/Solr,注意斜线。
9、将解压后的solr-4.9.0文件夹下的dist/solrj-lib下的所有jar包
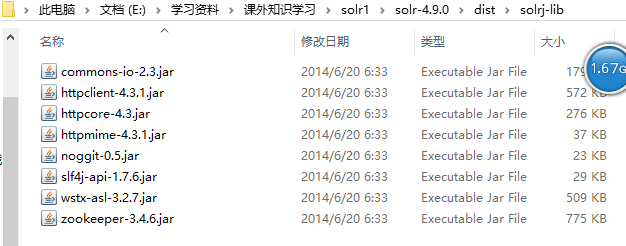
10、拷贝到E:\学习资料\tomcat\apache-tomcat-8.0.33\lib文件夹下
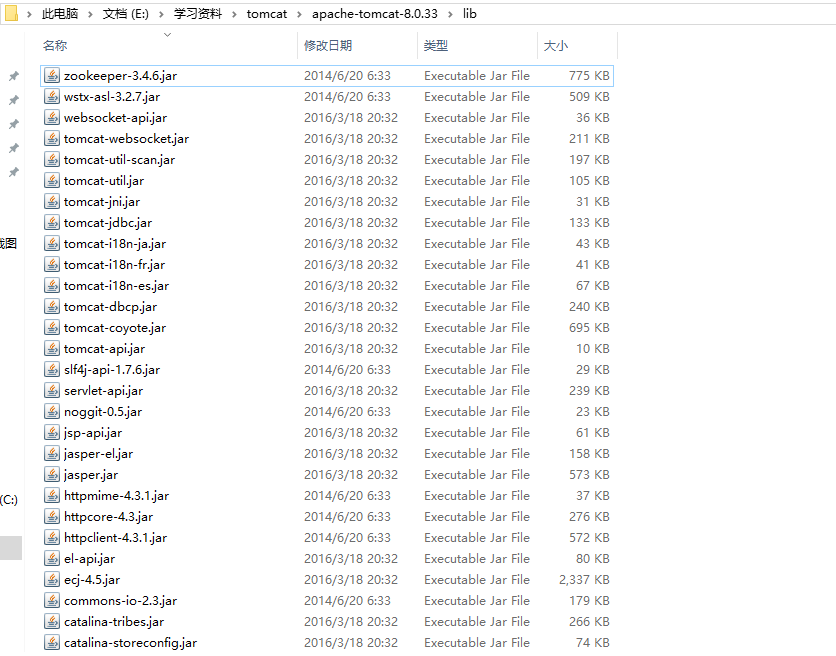
11、启动Tomcat之后,在地址栏输入:http://localhost:8080/solr,会出现以下报错的地方,如图所示:

这个错误就是缺jar包(缺slf4j.jar)。把E:\学习资料\课外知识学习\solr1\solr-4.9.0\example\lib\ext这个路径下的所有jar包,
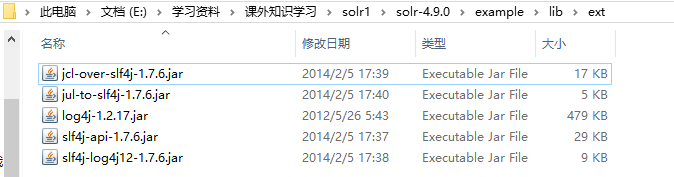
拷进E:\学习资料\tomcat\apache-tomcat-8.0.33\webapps\solr\WEB-INF\lib这个文件夹,也就是应用的lib文件夹下。同时把solr包下的E:\学习资料\课外知识学习\solr1\solr-4.9.0\example\resources\log4j.properties这个日志文件

拷进E:\学习资料\tomcat\apache-tomcat-8.0.33\webapps\solr\WEB-INF\classes(没有classes文件夹自己手工创建一下)就可以了。
然后再重启tomcat。
tomcat重启中……………….
在访问http://localhost:8080/solr,出现下图,书名配置solr环境成功:

二、介绍solr软件
在这出现了一个软件就是Solr的软件,下面就和大家一起来看看这个软件怎么用
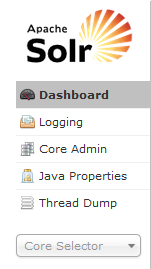
上图为安装solr环境的软件的左面截图,首先来看看这幅图的讲解:
1、Dashboard:就是上面全图就是这个按钮的功能;
2、Logging:查看日志;
3、Core Admin:添加core用户,这个可重要也可不重要,默认是collection1,这个就是添加一个和collection1具有一样功能的用户,用来检索和查询。点击之
后会出现下面的截图: 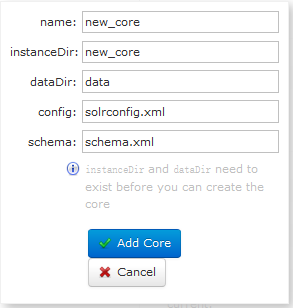
提示一下:
name:给core随便起个名字;
instanceDir:core的安装目录,这里就是之前在tomcat/solrhome/目录下创建的core1文件夹;
dataDir:指定用于存放lucene索引和log日志文件的目录路径,该路径是相对于core根目录(在单core模式下,就直接是相对于solr_home了),默认值是当前core目录下的data;
config:用于指定solrconfig.xml配置文件的文件名,启动时会去core1/config目录下去查找;
schema:即用来配置你的schema.xml配置文件的文件名的,schema.xml配置文件应该存放在当前core目录下的conf目录下。但是下载的solr里没有这个文件,所以我也不管了;
属性都填上,然后点击Add Core,就创建完成了。
再看最下面的下拉框:点击之后会出现collection1,点击collection1出现如下截图:
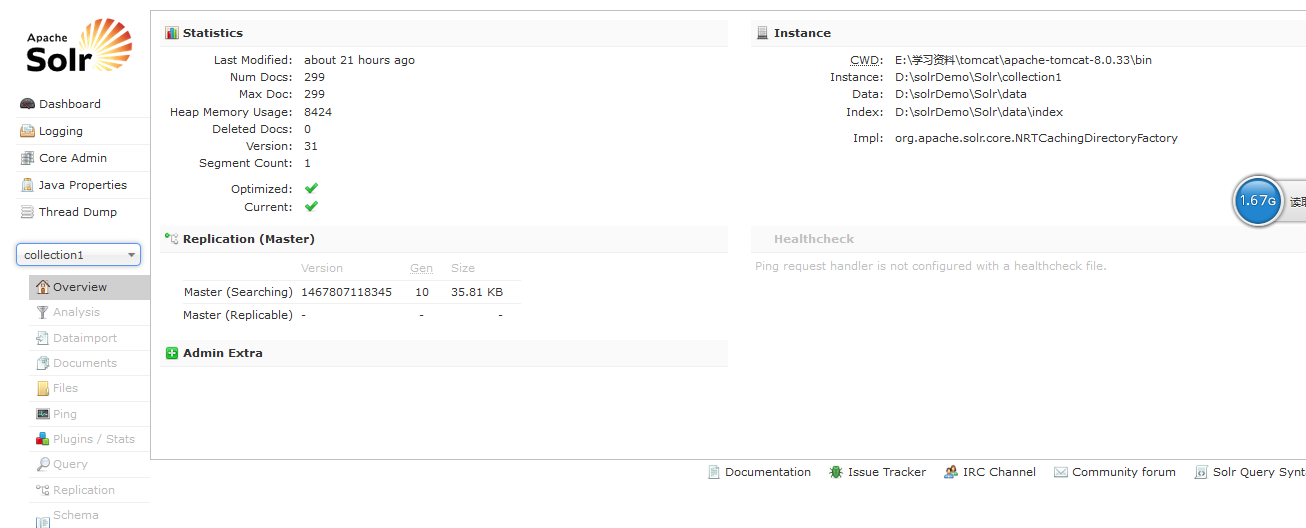
因为我在这之前添加了一个索引文档,所以我的显示的Num Docs和Max Doc 是有值的,没有安装就是为0;
就来介绍一下选中core角色后生成的一些按钮功能。
1、Overview:是浏览你的索引文档。其中包括最后开启时间、文档内存数量、文档最大数量等等一些信息;
2、Analysis:解析浏览。如下图:
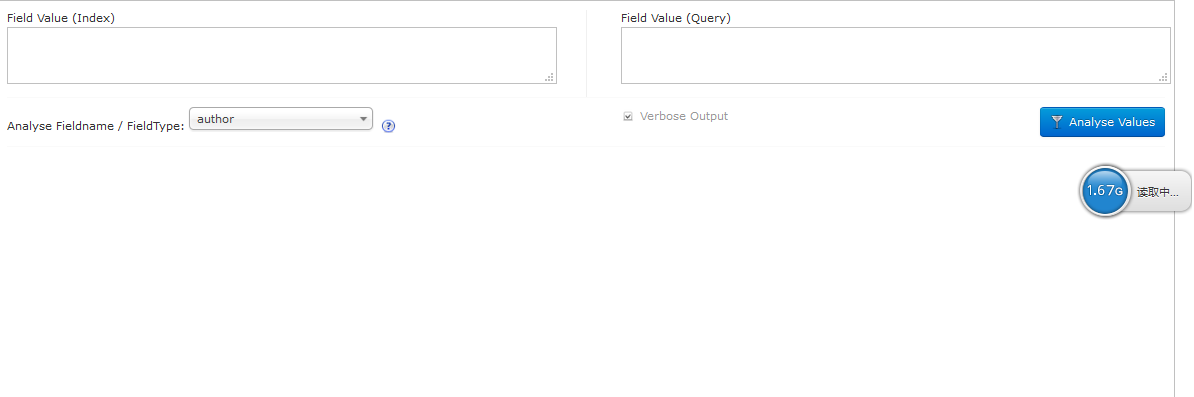
看左上方的Field Value(Index):这个是定义你要索引的属性值;
右上方的Field Value(Query):这个是根据输入的值,来进行查找;
底下的Analyse Fieldname / FieldType :就是你要往哪个属性里添加索引的值。
3、dataImport:就是数据的引进。
4、FIles、Ping、Pligins/Stats 这些不怎么常用,这里就不多详细介绍了。
5、Query:是根据索引属性查询,效果如下:
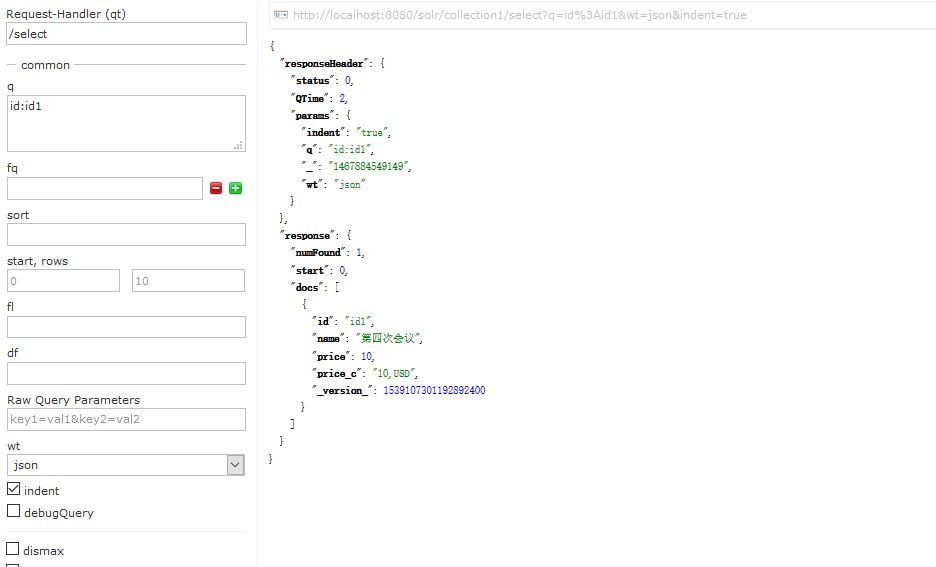
看到这,相信有的同学就要问了,拿这些是干嘛的呢?下面就介绍一下他们是干嘛的:
q:查询字符串,必须写,格式为:“索引属性:属性值”,必须遵守这种格式,否则查不出来。
fq:filter query。使用Filter Query可以充分利用Filter Query Cache,提高检索性能。作用:在q查询符合结果中同时是fq查询符合的,例如:
q=mm&fq=date_time:[20081001 TO 20091031],找关键字mm,并且date_time是20081001到20091031之间的。
fl:field list。指定返回结果字段。以空格“ ”或逗号“,”分隔。
start:用于分页定义结果起始记录数,默认为0。
rows:用于分页定义结果每页返回记录数,默认为10。
sort:排序,格式:sort=field name+desc|asc 。示例:(inStock desc, price asc)表示先 “inStock” 降序, 再 “price” 升序,默认是相关性降序。
df:默认的查询字段,一般默认指定。
q.op:覆盖schema.xml的defaultOperator(有空格时用”AND”还是用”OR”操作逻辑),一般默认指定。必须大写
wt:writer type。指定查询输出结构格式,默认为“xml”。在solrconfig.xml中定义了查询输出格式:xml、json、python、ruby、php、phps、custom。
qt:query type,指定查询使用的Query Handler,默认为“standard”。
explainOther:设置当debugQuery=true时,显示其他的查询说明。
defType:设置查询解析器名称。
timeAllowed:设置查询超时时间。
omitHeader:设置是否忽略查询结果返回头信息,默认为“false”。
indent:返回的结果是否缩进,默认关闭,用 indent=true|on 开启,一般调试json,php,phps,ruby输出才有必要用这个参数。
version:查询语法的版本,建议不使用它,由服务器指定默认值。
debugQuery:设置返回结果是否显示Debug信息。
以上这些就是solr的一些参数,下面就来介绍一下,查询的语法有哪些?
语法:
1.匹配所有文档::
2.强制、阻止和可选查询:
1) Mandatory:查询结果中必须包括的(for example, only entry name containing the word make)
Solr/Lucene Statement:+make, +make +up ,+make +up +kiss
2) prohibited:(for example, all documents except those with word believe)
Solr/Lucene Statement:+make +up -kiss
3) optional:
Solr/Lucene Statement:+make +up kiss
3.布尔操作:AND、OR和NOT布尔操作(必须大写)与Mandatory、optional和prohibited相似。
1) make AND up = +make +up :AND左右两边的操作都是mandatory
2) make || up = make OR up=make up :OR左右两边的操作都是optional
3) +make +up NOT kiss = +make +up –kiss
4) make AND up OR french AND Kiss不可以达到期望的结果,因为AND两边的操作都是mandatory的。
- 子表达式查询(子查询):可以使用“()”构造子查询。
示例:(make AND up) OR (french AND Kiss)
5.子表达式查询中阻止查询的限制:
示例:make (-up):只能取得make的查询结果;要使用make (-up :)查询make或者不包括up的结果。
6.多字段fields查询:通过字段名加上分号的方式(fieldName:query)来进行查询
示例:entryNm:make AND entryId:3cdc86e8e0fb4da8ab17caed42f6760c
7.通配符查询(wildCard Query):
1) 通配符?和:“”表示匹配任意字符;“?”表示匹配出现的位置。
示例:ma?(ma后面的一个位置匹配),ma??(ma后面两个位置都匹配)
2) 查询字符必须要小写:+Ma +be**可以搜索到结果;+Ma +Be**没有搜索结果.
3) 查询速度较慢,尤其是通配符在首位:主要原因一是需要迭代查询字段中的每个term,判断是否匹配;二是匹配上的term被加到内部的查询,当terms数量达到1024的时候,查询会失败。
4) Solr中默认通配符不能出现在首位(可以修改QueryParser,设置
setAllowLeadingWildcard为true)
5) set setAllowLeadingWildcard to true.
8.模糊查询、相似查询:不是精确的查询,通过对查询的字段进行重新插入、删除和转换来取得得分较高的查询解决(由Levenstein Distance Algorithm算法支持)。
1) 一般模糊查询:示例:make-believ~
2) 门槛模糊查询:对模糊查询可以设置查询门槛,门槛是0~1之间的数值,门槛越高表面相似度越高。示例:make-believ~0.5、make-believ~0.8、make-believ~0.9
9.范围查询(Range Query):Lucene支持对数字、日期甚至文本的范围查询。结束的范围可以使用“*”通配符。
示例:
1) 日期范围(ISO-8601 时间GMT):sa_type:2 AND a_begin_date:[1990-01-01T00:00:00.000Z TO 1999-12-31T24:59:99.999Z]
2) 数字:salary:[2000 TO *]
3) 文本:entryNm:[a TO a]
10.日期匹配:YEAR, MONTH, DAY, DATE (synonymous with DAY) HOUR, MINUTE, SECOND, MILLISECOND, and MILLI (synonymous with MILLISECOND)可以被标志成日期。
示例:
1) r_event_date:[* TO NOW-2YEAR]:2年前的现在这个时间
2) r_event_date:[* TO NOW/DAY-2YEAR]:2年前前一天的这个时间
在solr里,也有函数,接下来就看看solr是怎样通过函数查询的:
函数查询 可以利用 numeric字段的值 或者 与字段相关的的某个特定的值的函数,来对文档进行评分。
- 使用函数查询的方法
这里主要有三种方法可以使用函数查询,这三种s方法都是通过solr http接口的。
1) 使用FunctionQParserPlugin。ie: q={!func}log(foo)
2) 使用“val”内嵌方法
内嵌在正常的solr查询表达式中。即,将函数查询写在 q这个参数中,这时候,我们使用“val”将函数与其他的查询加以区别。
ie:entryNm:make && val:ord(entryNm)
3) 使用dismax中的bf参数
使用明确为函数查询的参数,比如说dismax中的bf(boost function)这个参数。 注意:bf这个参数是可以接受多个函数查询的,它们之间用空格隔开,它们还可以带上权重。所以,当我们使用bf这个参数的时候,我们必须保证单个函数中是没有空格出现的,不然程序有可能会以为是两个函数。
示例:
q=dismax&bf=”ord(popularity)^0.5 recip(rord(price),1,1000,1000)^0.3
- 函数的格式(Function Query Syntax)
目前,function query 并不支持 a+b 这样的形式,我们得把它写成一个方法形式,这就是 sum(a,b).
- 使用函数查询注意事项
1) 用于函数查询的field必须是被索引的;
2) 字段不可以是多值的(multi-value)
- 可以利用的函数 (available function)
1) constant:支持有小数点的常量; 例如:1.5 ;SolrQuerySyntax:val:1.5
2) fieldvalue:这个函数将会返回numeric field的值,这个字段必须是indexd的,非multiValued的。格式很简单,就是该字段的名字。如果这个字段中没有这样的值,那么将会返回0。
3) ord:对于一个字段,它所有的值都将会按照字典顺序排列,这个函数返回你要查询的那个特定的值在这个顺序中的排名。这个字段,必须是非multiValued的,当没有值存在的时候,将返回0。例如:某个特定的字段只能去三个值,“apple”、“banana”、“pear”,那么ord(“apple”)=1,ord(“banana”)=2,ord(“pear”)=3.需要注意的是,ord()这个函数,依赖于值在索引中的位置,所以当有文档被删除、或者添加的时候,ord()的值就会发生变化。当你使用MultiSearcher的时候,这个值也就是不定的了。
4) rord:这个函数将会返回与ord相对应的倒排序的排名。
格式: rord(myIndexedField)。
5) sum:这个函数的意思就显而易见啦,它就是表示“和”啦。
格式:sum(x,1) 、sum(x,y)、 sum(sqrt(x),log(y),z,0.5)
6) product:product(x,y,…)将会返回多个函数的乘积。格式:product(x,2)、product(x,y)
7) div:div(x,y)表示x除以y的值,格式:div(1,x)、div(sum(x,100),max(y,1))
8) pow:pow表示幂值。pow(x,y) =x^y。例如:pow(x,0.5) 表示开方pow(x,log(y))
9) abs:abs(x)将返回表达式的绝对值。格式:abs(-5)、 abs(x)
10) log:log(x)将会返回基数为10,x的对数。格式: log(x)、 log(sum(x,100))
11) Sqrt:sqrt(x) 返回 一个数的平方根。格式:sqrt(2)、sqrt(sum(x,100))
12) Map:如果 x>=min,且x<=max,那么map(x,min,max,target)=target.如果 x不在[min,max]这个区间内,那么map(x,min,max,target)=x.
格式:map(x,0,0,1)
13) Scale:scale(x,minTarget,maxTarget) 这个函数将会把x的值限制在[minTarget,maxTarget]范围内。
14) query :query(subquery,default)将会返回给定subquery的分数,如果subquery与文档不匹配,那么将会返回默认值。任何的查询类型都是受支持的。可以通过引用的方式,也可以直接指定查询串。
例子:q=product(popularity, query({!dismax v=’solr rocks’}) 将会返回popularity和通过dismax 查询得到的分数的乘积。
q=product(popularity, query($qq)&qq={!dismax}solr rocks 跟上一个例子的效果是一样的。不过这里使用的是引用的方式
q=product(popularity, query($qq,0.1)&qq={!dismax}solr rocks 在前一个例子的基础上又加了一个默认值。
15) linear: inear(x,m,c)表示 m*x+c ,其中m和c都是常量,x是一个变量也可以是一个函数。例如: linear(x,2,4)=2*x+4.
16) Recip:recip(x,m,a,b)=a/(m*x+b)其中,m、a、b是常量,x是变量或者一个函数。当a=b,并且x>=0的时候,这个函数的最大值是1,值的大小随着x的增大而减小。例如:recip(rord(creationDate),1,1000,1000)
17) Max: max(x,c)将会返回一个函数和一个常量之间的最大值。
例如:max(myfield,0)
solr用POJO添加和删除文档并用软件查询
pom.xml
1 <!-- https://mvnrepository.com/artifact/org.apache.solr/solr-solrj --> 2 <dependency> 3 <groupId>org.apache.solr</groupId> 4 <artifactId>solr-solrj</artifactId> 5 <version>4.4.0</version> 6 </dependency> 7 <!-- https://mvnrepository.com/artifact/commons-logging/commons-logging --> 8 <dependency> 9 <groupId>commons-logging</groupId> 10 <artifactId>commons-logging</artifactId> 11 <version>1.2</version> 12 </dependency>
代码需要用到一个POJO,即简单的javaBean,代码如下:
1 package solrPOJOPackage;
2
3 import java.util.List;
4
5 import org.apache.solr.client.solrj.beans.Field;
6
7 public class NewsBean {
8
9 @Field
10 private String id;
11
12 @Field
13 private String name;
14
15 @Field
16 private String author;
17
18 @Field
19 private String description;
20
21 @Field("links")
22 private List<String> relatedLinks;
23
24 public NewsBean(){
25
26 }
27
28 public String getId() {
29 return id;
30 }
31
32 public void setId(String id) {
33 this.id = id;
34 }
35
36
37 public String getName() {
38 return name;
39 }
40
41 public void setName(String name) {
42 this.name = name;
43 }
44
45 public String getAuthor() {
46 return author;
47 }
48
49 public void setAuthor(String author) {
50 this.author = author;
51 }
52
53 public String getDescription() {
54 return description;
55 }
56
57 public void setDescription(String description) {
58 this.description = description;
59 }
60
61 public List<String> getRelatedLinks() {
62 return relatedLinks;
63 }
64
65 public void setRelatedLinks(List<String> relatedLinks) {
66 this.relatedLinks = relatedLinks;
67 }
68
69 }
以下是代码的实现:
首先是用POJO来添加索引文档:
1 package solrPOJOPackage;
2
3 import java.util.ArrayList;
4 import java.util.Arrays;
5 import java.util.Collection;
6 import java.util.List;
7 import java.util.Random;
8
9 import org.apache.solr.client.solrj.impl.BinaryRequestWriter;
10 import org.apache.solr.client.solrj.impl.HttpSolrServer;
11
12 //采用POJOs增加、删除索引
13 public class solrTest {
14
15 //定义全局solr软件路径
16 public static final String SOLR_URL = "http://localhost:8080/solr";
17
18 public static void main(String[] args) {
19
20 // 通过浏览器查看结果?
21 // 要保证bean中各属性的名称在conf/schema.xml中存在,如果查询,要保存被索引
22 // http://172.168.63.233:8983/solr/collection1/select?q=description%3A%E6%94%B9%E9%9D%A9&wt=json&indent=true
23
24 //删除索引文档
25 //delBeans();
26
27 //添加索引文档
28 AddBeans();
29 }
30
31 //看文档random.docs
32 public static Random rand = new Random(47);
33
34 //定义String数组,用来定义authors
35 public static String[] authors = { "张三", "李四", "王五", "赵六", "张飞", "刘备","关云" };
36
37 //定义links属性的数组
38 public static String[] links = {
39
40 "http://repository.sonatype.org/content/sites/forge-sites/m2e/",
41
42 "http://news.ifeng.com/a/20140818/41626965_0.shtml",
43
44 "http://news.ifeng.com/a/20140819/41631363_0.shtml?wratingModule_1_9_1",
45
46 "http://news.ifeng.com/topic/19382/",
47
48 "http://news.ifeng.com/topic/19644/"
49 };
50
51
52 public static String genAuthors() {
53
54 //JDK中,List接口有一个实例方法List<E> subList(int fromIndex, int toIndex),其作用是返回一个以fromIndex为起始索引(包含),以toIndex为终止索引(不包 //含)的子列表(List)。
55 //subList: 取List中下标为0到6的元素。
56 //rand.nextInt(7): 给定一个参数n,nextInt(n)将返回一个大于等于0小于n的随机数,即:0 <= nextInt(n) < n。
57 List<String> list = Arrays.asList(authors).subList(0, rand.nextInt(7));
58
59 //定义空的字符串,接收从list集合中取出的author属性
60 String str = "";
61 for (String tmp : list) {
62
63 str += " " + tmp;
64
65 }
66
67 return str;
68
69 }
70
71 //截取从list集合中取出下标为0-4的links属性值
72 public static List<String> genLinks() {
73
74 return Arrays.asList(links).subList(0, rand.nextInt(5));
75
76 }
77
78 //添加索引信息
79 public static void AddBeans() {
80 String[] words = { "中央全面深化改革领导小组", "第四次会", "审议了国企薪酬制度改", "考试招生制度改革",
81 "传统媒体与新媒体融合", "相关邵内容文件", "习大大强调要", "逐步规范国有企业收入分配秩序",
82 "实现薪酬水平适当", "结构合理、管理规范监督有效", "对不合理的偏", "过高收入进行调整",
83 "深化考试招生制度改革", "总的目标是形成分类", "综合评价", "多元录取的试招生模", "健全促进公平",
84 "科学选才", "监督有力的体制机", "多样", "手段先进", "具有竞争力的新型主流媒体",
85 "建成几家拥有强大实力和传播力", "公信", "影响力的新型媒体集团" };
86
87 long start = System.currentTimeMillis();
88 Collection<NewsBean> docs = new ArrayList<NewsBean>();
89 //1、DocumentObjectBinder binder = new DocumentObjectBinder();
90 for (int i = 1; i < 300; i++) {
91 NewsBean news = new NewsBean();
92 news.setId("id" + i);
93 news.setName("news" + i);
94 news.setAuthor(genAuthors());
95 news.setDescription(words[i % 21]);
96 news.setRelatedLinks(genLinks());
97 // 2、 SolrInputDocument doc1 = binder.toSolrInputDocument(news);
98 docs.add(news);
99 }
100 try {
101
102 //通过路径得到服务器
103 HttpSolrServer server = new HttpSolrServer(SOLR_URL);
104
105 //向服务器请求写入
106 server.setRequestWriter(new BinaryRequestWriter());
107
108
109 // 第一种方式写入:增加后经过执行commit函数commit (981ms)
110 // 3、server.addBeans(docs);
111 //4、server.commit();
112
113 // 第二种方式写入:增加doc后立即commit (946ms)
114 // UpdateRequest req = new UpdateRequest();
115 //req.setAction(ACTION.COMMIT, false, false);
116 // req.add(docs);
117 //UpdateResponse rsp = req.process(server);
118
119 // 第三种方式写入:增加docs,其中server.add(docs.iterator())效率更快。
120 // the most optimal way of updating all your docs
121 // in one http request(481ms)
122 //迭代把索引文档加到服务器上去。
123 server.addBeans(docs.iterator());
124
125 //优化索引;
126 server.optimize();
127 } catch (Exception e) {
128 System.out.println(e);
129 }
130 System.out.println("添加索引信息成功,共花费了"
131 + (System.currentTimeMillis() - start)+"毫秒");
132
133 //添加成功效果见图一
134 //solr软件添加成功之后查询效果见图二
135 }
136
137 //再加上删除文档的代码吧
138 public static void delBeans() {
139 //开始计时(m/s)
140 long start = System.currentTimeMillis();
141
142 try {
143
144 //得到服务器的入口
145 HttpSolrServer server = new HttpSolrServer(SOLR_URL);
146
147 //定义id的集合
148 List<String> ids = new ArrayList<String>();
149
150 //循环得到id
151 for (int i = 1; i < 300; i++) {
152 ids.add("id" + i);
153 }
154
155 //删除
156 server.deleteById(ids);
157
158 // 提交
159 server.commit();
160
161 } catch (Exception e) {
162 System.out.println(e);
163 }
164 System.out.println("删除索引信息成功,共花费了"
165 + (System.currentTimeMillis() - start)+"毫秒");
166
167 //删除成功效果见图三
168 //solr软件删除之后查询效果见图四
169 }
170 }
以上代码中,看到有三种颜色的字体。这三种不同颜色字体的代码都是向服务器写入索引对象,字体为红色的代码第1句是实例化DocumentObjectBinder对象,第2句就是把NewsBean的POJO转成SolrInputDocument对象,这么做的目的是:减少了Document文档和JavaBean相互转换时的麻烦,1、2、3、4句是一起出现而组成了第一种写入方法;而紫色字体的相比较红色字体来说呢,处理的效率要快一点,但是还是不太理想,而绿色字体的代码效率快,值得选择。
注:
虽然作者是这样说的,但是我自己测试之后,情况并不是完全如其所说,仁者见仁智者见智,大家可以自己多测试测试,根据自己的情况选择。如下是我测试的结果:
第三种方法:
添加索引信息成功,共花费了3837毫秒
删除索引信息成功,共花费了3824毫秒
添加索引信息成功,共花费了2023毫秒
删除索引信息成功,共花费了1337毫秒
添加索引信息成功,共花费了2759毫秒
删除索引信息成功,共花费了1274毫秒
添加索引信息成功,共花费了2049毫秒
删除索引信息成功,共花费了1330毫秒
第二种方法:
添加索引信息成功,共花费了3243毫秒
删除索引信息成功,共花费了1380毫秒
添加索引信息成功,共花费了2005毫秒
删除索引信息成功,共花费了1393毫秒
添加索引信息成功,共花费了2621毫秒
删除索引信息成功,共花费了1398毫秒
第一种办法:
添加索引信息成功,共花费了2134毫秒
删除索引信息成功,共花费了1869毫秒
添加索引信息成功,共花费了2024毫秒
删除索引信息成功,共花费了1311毫秒
添加索引信息成功,共花费了2264毫秒
删除索引信息成功,共花费了1445毫秒
绿色字体代码里有一个是optimize,这个是优化索引的功能,看看源码: (参考:http://my.oschina.net/qige/blog/173008)
优化索引 :
public UpdateResponse optimize(boolean waitFlush, boolean waitSearcher, int maxSegments ) throws SolrServerException, IOException {
return new UpdateRequest().setAction( UpdateRequest.ACTION.OPTIMIZE, waitFlush, waitSearcher, maxSegments ).process( this );//同样调用process,通过setAction参数,在CommonHttpSolrServer类方法request()中主要执行的是合并和压缩 setAction都是为了对对象ModifiableSolrParams(这个对象在最终CommonHttpSolrServer的request方法中用的到)进行赋值
}
紫色字体里的setAction:
public UpdateResponse commit( boolean waitFlush, boolean waitSearcher ) throws Solr ServerException, IOException {
//看到了吗?setAction都是为了对对象ModifiableSolrParams(这个对象在最终CommonHttpSolrServerrequest的request方法中用的到)
在提交索引的时候也是调用的process方法
return new UpdateRequest().setAction( UpdateRequest.ACTION.COMMIT, waitFlush, waitSearcher ).process( this );
}
图一:

图二:
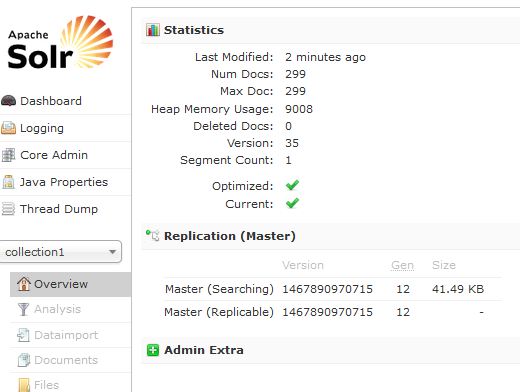
图三:

图四:
最后总结一下步骤,步骤如下:
1、创建POJO;
2、创建Java项目;
3、创建一个含有main方法的类,包含addBeas和DelBeans两个自调方法;
4、运行mian方法;
5、运行成功,打印台出现标记;
6、去solr软件查看。
采用SolrInputDocument对象添加和删除索引并用软件查询
1 package solrSolrInputDocumentPackage;
2
3 import java.util.ArrayList;
4 import java.util.Collection;
5 import java.util.List;
6
7 import org.apache.solr.client.solrj.impl.HttpSolrServer;
8 import org.apache.solr.client.solrj.request.AbstractUpdateRequest.ACTION;
9 import org.apache.solr.client.solrj.request.UpdateRequest;
10 import org.apache.solr.client.solrj.response.UpdateResponse;
11 import org.apache.solr.common.SolrInputDocument;
12
13 //采用 SolrInputDocument对象 增加、删除索引
14 public class solrSolrInput {
15
16 public static final String SOLR_URL = "http://localhost:8080/solr";
17
18 public static void main(String[] args) {
19
20 //通过浏览器查看结果
21 //http://172.168.63.233:8983/solr/collection1/select?q=name%3A%E6%94%B9%E9%9D%A9&wt=json&indent=true
22 AddDocs();
23 //delDocs();
24 }
25
26 public static void AddDocs() {
27
28 String[] words = { "中央全面深化改革领导小组", "第四次会议", "审议了国企薪酬制度改革", "考试招生制度改革",
29 "传统媒体与新媒体融合等", "相关内容文件", "习强调要", "逐步规范国有企业收入分配秩序",
30 "实现薪酬水平适当", "结构合理、管理规范、监督有效", "对不合理的偏高", "过高收入进行调整",
31 "深化考试招生制度改革", "总的目标是形成分类考试", "综合评价", "多元录取的考试招生模式", "健全促进公平",
32 "科学选才", "监督有力的体制机制", "着力打造一批形态多样", "手段先进", "具有竞争力的新型主流媒体",
33 "建成几家拥有强大实力和传播力", "公信力", "影响力的新型媒体集团" };
34
35 long start = System.currentTimeMillis();
36
37 Collection<SolrInputDocument> docs = new ArrayList<SolrInputDocument>();
38
39 for (int i = 1; i < 300; i++) {
40 SolrInputDocument doc1 = new SolrInputDocument();
41 doc1.addField("id", "id" + i, 1.0f);
42 doc1.addField("name", words[i % 21], 1.0f);
43 doc1.addField("price", 10 * i);
44 docs.add(doc1);
45 }
46
47 try {
48
49 HttpSolrServer server = new HttpSolrServer(SOLR_URL);
50
51 // 可以通过三种方式增加docs,其中server.add(docs.iterator())效率最高
52 //1、 增加后通过执行commit函数commit (936ms)
53 server.add(docs);
54 server.commit();
55
56 // 2、增加doc后立即commit (946ms)
57 UpdateRequest req = new UpdateRequest();
58 req.setAction(ACTION.COMMIT, false, false);
59 req.add(docs);
60 UpdateResponse rsp = req.process(server);
61
62 // 3、the most optimal way of updating all your docs
63 // in one http request(432ms)
64 server.add(docs.iterator());
65 } catch (Exception e) {
66 System.out.println(e);
67 }
68 System.out.println("time elapsed(ms):"
69 + (System.currentTimeMillis() - start));
70 }
71
72 public static void delDocs() {
73 long start = System.currentTimeMillis();
74 try {
75 HttpSolrServer server = new HttpSolrServer(SOLR_URL);
76 List<String> ids = new ArrayList<String>();
77 for (int i = 1; i < 300; i++) {
78 ids.add("id" + i);
79 }
80 server.deleteById(ids);
81 server.commit();
82 } catch (Exception e) {
83 System.out.println(e);
84 }
85 System.out.println("time elapsed(ms):"
86 + (System.currentTimeMillis() - start));
87 }
88
89
90 }
看完以上代码,感觉和POJO的添加,删除索引没什么差别,但是,总有不同之处,
在POJO里有一个索引优化,不知大家还记不记得, server.optimize(); 就是这个,就是因为这个方法,才会使得效率大大提高,这也就是细微之处的差别。
这个方法虽然和POJO的添加、删除的功能是一样的,但是大多数会选用POJO这种方法来进行索引管理。
solr用普通方法处理查询结果
这个方法不是常用,因为在solr的软件里都有对应的查询功能,只不过这里把软件转换成Java代码了,话不多说,现在来看看具体代码,只了解一下即可。
代码如下:
1 package solrPublicToQueryPackage;
2
3 import java.io.IOException;
4
5 import org.apache.solr.client.solrj.SolrQuery;
6 import org.apache.solr.client.solrj.SolrQuery.ORDER;
7 import org.apache.solr.client.solrj.SolrServerException;
8 import org.apache.solr.client.solrj.impl.BinaryRequestWriter;
9 import org.apache.solr.client.solrj.impl.HttpSolrServer;
10 import org.apache.solr.client.solrj.impl.XMLResponseParser;
11 import org.apache.solr.client.solrj.response.QueryResponse;
12 import org.apache.solr.common.SolrDocument;
13 import org.apache.solr.common.params.ModifiableSolrParams;
14
15 //普通方式处理查询结果
16 public class solrPublicQuery {
17
18 public static final String SOLR_URL = "http://localhost:8080/solr";
19
20 public static void main(String[] args) throws SolrServerException, IOException {
21
22 HttpSolrServer server = new HttpSolrServer(SOLR_URL);
23
24 server.setMaxRetries(1);
25 server.setMaxRetries(1); // defaults to 0. > 1 not recommended.
26 server.setConnectionTimeout(5000); // 5 seconds to establish TCP
27
28
29 //正常情况下,以下参数无须设置
30 //使用老版本solrj操作新版本的solr时,因为两个版本的javabin incompatible,所以需要设置Parser
31 server.setParser(new XMLResponseParser());
32 server.setSoTimeout(1000); // socket read timeout
33 server.setDefaultMaxConnectionsPerHost(100);
34 server.setMaxTotalConnections(100);
35 server.setFollowRedirects(false); // defaults to false
36
37
38 // allowCompression defaults to false.
39 // Server side must support gzip or deflate for this to have any effect.
40 server.setAllowCompression(true);
41
42 //1、使用ModifiableSolrParams传递参数
43
44 ModifiableSolrParams params = new ModifiableSolrParams();
45
46 //192.168.230.128:8983/solr/select?q=video&fl=id,name,price&sort=price asc&start=0&rows=2&wt=json
47 // 设置参数,实现上面URL中的参数配置
48
49 // 查询关键词
50 // params.set("q", "name");
51
52 // // 返回信息
53 // params.set("fl", "id,name,price,price_c");
54
55 // // 排序
56 // params.set("sort", "price asc");
57
58 // // 分页,start=0就是从0开始,rows=5当前返回5条记录,第二页就是变化start这个值为5就可以了
59 // params.set("start", 2);
60 // params.set("rows", 2);
61
62 // // 返回格式
63 // params.set("wt", "javabin");
64 // QueryResponse response = server.query(params);
65
66 //2、使用SolrQuery传递参数,SolrQuery的封装性更好
67 server.setRequestWriter(new BinaryRequestWriter());
68
69 SolrQuery query = new SolrQuery();
70 query.setQuery("name");
71 query.setFields("id","name","price","price_c");
72 query.setSort("price", ORDER.asc);
73 query.setStart(0);
74 query.setRows(2);
75 query.setRequestHandler("/select");
76
77 QueryResponse response = server.query(query);
78
79
80
81 // 搜索得到的结果数
82 System.out.println("Find:" + response.getResults().getNumFound());
83
84 // 输出结果
85 int iRow = 1;
86
87 for (SolrDocument doc : response.getResults()) {
88
89 System.out.println("----------" + iRow + "------------");
90 System.out.println("id: " + doc.getFieldValue("id").toString());
91 System.out.println("name: " + doc.getFieldValue("name").toString());
92 System.out.println("price: "
93 + doc.getFieldValue("price").toString());
94 System.out.println("price_c: " + doc.getFieldValue("price_c"));
95 iRow++;
96 }
97 }
98
99 }
顺便提一下,看见标有1、2两种方法的查询方式都是可以用的,但是方法2是最佳方案;
熟悉完代码之后,大家在看看solr软件,是不是这里的好多设置和软件是一样的 ,只不过是代码而已。
以上代码只供了解,用代码查询,大多数用的是POJO的处理查询结果,下面就来介绍一下用POJO怎样来处理查询结果?
solr用POJO处理查询结果
1 package solrPOJODealWithQueryResult;
2
3 import java.io.IOException;
4 import java.util.List;
5
6 import org.apache.solr.client.solrj.SolrQuery;
7 import org.apache.solr.client.solrj.SolrServerException;
8 import org.apache.solr.client.solrj.beans.DocumentObjectBinder;
9 import org.apache.solr.client.solrj.impl.HttpSolrServer;
10 import org.apache.solr.client.solrj.response.FacetField;
11 import org.apache.solr.client.solrj.response.QueryResponse;
12 import org.apache.solr.common.SolrDocument;
13 import org.apache.solr.common.SolrDocumentList;
14
15 import solrPOJOPackage.NewsBean;
16
17 //采用POJOs方式处理查询结果
18 public class solrPOJODealWithResult {
19
20 public static final String SOLR_URL = "http://localhost:8080/solr";
21
22 public static void main(String[] args) throws SolrServerException, IOException {
23
24 // http://172.168.63.233:8983/solr/collection1/select?q=description%3A%E6%80%BB%E7%9B%AE%E6%A0%87&facet=true&facet.field=author_s
25 HttpSolrServer server = new HttpSolrServer(SOLR_URL);
26
27 server.setMaxRetries(1);
28 server.setMaxRetries(1); // defaults to 0. > 1 not recommended.[,rekə'mendɪd]
29 server.setConnectionTimeout(5000); // 5 seconds to establish [ɪ'stæblɪʃ; e-] (创立)TCP
30 // server.setRequestWriter(new BinaryRequestWriter());
31 SolrQuery query = new SolrQuery();
32 query.setQuery("description:改革");
33 query.setStart(0);
34 query.setRows(2);
35 query.setFacet(true);
36 query.addFacetField("author_s");
37
38 QueryResponse response = server.query(query);
39 // 搜索得到的结果数
40 System.out.println("Find:" + response.getResults().getNumFound()+"毫秒");
41 // 输出结果
42 int iRow = 1;
43
44 //response.getBeans存在BUG,将DocumentObjectBinder引用的Field应该为 org.apache.solr.client.solrj.beans.Field
45 SolrDocumentList list = response.getResults();
46 DocumentObjectBinder binder = new DocumentObjectBinder();
47 List<NewsBean> beanList=binder.getBeans(NewsBean.class, list);
48 for(NewsBean news:beanList){
49 System.out.println("news的ID为:"+news.getId());
50 }
51
52 for (SolrDocument doc : response.getResults()) {
53 System.out.println("----------" + iRow + "------------");
54 System.out.println("id: " + doc.getFieldValue("id").toString());
55 System.out.println("name: " + doc.getFieldValue("name").toString());
56 iRow++;
57 }
58 for (FacetField ff : response.getFacetFields()) {
59 System.out.println(ff.getName() + "," + ff.getValueCount() + ","
60 + ff.getValues());
61 }
62 }
63
64 }
在打印台的效果演示:

在solr服务器上查询,顺便验证一下:

结果证明了:
我的查找是正确,所以,在大多数常态下,会用到的就是solr,相比较Lucene来说,
solr是不是更加的强大呢?
以上就是我的solr介绍的全部内容,希望可以帮到大家,有什么不足的地方,希望大家能够共同进步!
最后给大家提供一些别的博客地址:
1、solr和zookepper的集群:访问http://www.iigrowing.cn/solr-zong-jie.html
2、tomcat和solr的集成:访问http://www.tuicool.com/articles/uAzQnaz