此笔记是博主在学习python的时候进行记录的,里面的所有内容都是博主在学习python的时候遇到的知识点,此笔记最适合进行复习以及快速查找相关知识点进行使用,博主也会随着学习的深入不断的增加新的python知识点。
一、Python常用的命令
1、>python:进入python环境,写python的程序
2、>>>exit():退出python环境
二、Pip中常用的命令
3、>pip list: 列出匹配管理的包有哪些
4、 >pip install 包名 :安装外援(pip install redis)
5、>pip uninstall 包名:卸载外援
6、pip -V:查看版本
7、pip freeze > requirements.txt:将你的项目依赖的包输出到指定的requirements.txt文件
8、pip install -r requirements.txt:使用pip安装requirements.txt中依赖的文件
三、安装Python常见问题
10、runtime error:运行时错误 出现此问题说明windows系统中缺少me某个补丁
9、python -m pip install --upgrade pip:升级pip(当出现黄色或者红色警告时) 版本–>20.1.1

11、Python3.6.5(解释器 python.exe+lib(内置库)+pip(包管理器:pip.exe))
12、外援装在Python安装目录下的Lib目录下的site-packages
13、当更新pip时出现ModuleNotFoundError: No module named ‘pip’
–解决方案
python -m ensurepip
python -m pip install --upgrade pip
14、virtualenv env:创建虚拟环境
15、
四、Python关键字
‘False’, ‘None’, ‘True’, ‘and’, ‘as’, ‘assert’, ‘break’, ‘class’, ‘continue’, ‘def’, ‘del’, ‘elif’, ‘else’, ‘except’, ‘finally’, ‘for’, ‘from’, ‘global’, ‘if’, ‘import’, ‘in’, ‘is’, ‘lambda’, ‘nonlocal’, ‘not’, ‘or’, ‘pass’, ‘raise’, ‘return’, ‘try’, ‘while’, ‘with’, ‘yield’
五、Python注释
1、#:单行注释
2’’’ ’’’:多行注释 保留字符串输出格式
六、Python字符串、列表、字典、集合内建函数
字符串插入变量
1、用法: print(value, …, sep=’ ‘, end=’\n’)
2、占位符:%s(str) %d(digut) %f(float)
用法:print(‘订单的收货人是:%s,收货地址是:%s,联系方式:%s,商品数量是:%s’%(person,address,phone,num))
3、format():格式化输出 用法:message=’{}今年{}岁了,最喜欢{},有零花钱{}’.format(name,age,hobby,money) {}中可添加数字来匹配format中的参数
字符串内建函数(语法:str.内建函数)
1、capitalize():将字符串的第一个字符转成大写
2、title():每个单词的首字母大写
3、upper():将字符串全部转成大写的表现形式
4、lower():将字符串全部转换成小写的表现形式
5、find(a,start,end):查找字符串中是否出现a a:要查找的字符串 返回a的下标
6、rfind(a,start,end):从右边开始查找字符串中是否出现a a:要查找的字符串 返回a的下标
7、index():用户和find()用法一样 只不过find()找不到时返回-1 而index()则报异常 (使用较少)
8、replace(old,new,[max]):替换字符串 old:被替换的部分 new:替换成的部分 max:指定替换的次数
9、encode(字符集):编码 decode(字符集):解码 常用字符集(gbk:中文 gb2312:简体中文 utf-8:编码汇总)
10、startswith():判断是否是以xxx开头
11、endswith():判断是否是以xxx结尾
12、isalpha():判断字符串是否是纯字母组成
13、isdigit():判断字符串是否是纯数字组成
14、join:将列表或者字符串拼接为新的字符串 语法:’-’.join(‘abc’)
15、split(a,b):分割字符串并将分割后的字符串保存到列表中 a:分割符
b:次数
16、strip():去除字符串前后空格 lstrip():去除字符串左侧空格
rstrip():去除字符串右侧空格
17、count(ages):求(字符串、元组、字典)中ages出现的次数
18、len():获取字符串、元组、列表、字典和集合的长度
19、round(number,precision):四舍五入取小数
20、ceil(number):取整数
21、contains(’content’):查看是否包含指定内容
22、ord(’ '):获取字符的ASCLL码值
23、chr(’ASCLL’):生成ASCLL码对应的字符
24、string.ascii_letters:生成26个大小写英文字幕
列表内建函数
1、del(列表名[index]):删除列表中的值 语法 del 列表名[下标]
2、append() :末尾追加值
3、extend():末尾添加一组元素 +也可以实现合并
4、insert(a,b):指定位置添加 a:下标 b:参数
5、sum():求整形列表所有元素和
6、sort ():对整形列表进行排序
7、remove():删除列表第一次出现的元素 返回值是None 如果没有找到要删除的元素则报异常
8、pop(a):弹栈 移除列表中的最后一个元素 返回值是删除的那个元素 pop(0):从头开始删除
默认删除最后一个,但是也可以指定下标删除 a:元素下标
9、clear():清除列表(里面的所有元素全部删除) 返回值是None
10、reverse():将列表的元素进行反转 返回值为None
11、zip(list1,list2):将两个列表中的元素一一对应拼接成列表嵌套元组
字典内建函数
1、items():取出字典中的kv(横向)
2、values(): 取出字典中所有的value值(纵向)
3、keys():获取字典中所有的key键(纵向)
4、get(key,default):获取字典中的值 key:字典的键 default:默认值
等同于dict[key]=value(可以不存在时会报错)
5、pop(key,default):删除字典的键值对返回值为键所对应的值 key:字典中的键 default:默认值
6、update():字典合并操作 相当于{}+{} 当key重复时 则value被覆盖
当不存在是则返回默认值 语法:dict1.update(dict2)
7、fromkeys(seq,default):将seq(包括字符串、元组、列表)转成字典的表达形式,如果没有指定的默认的value则用None,如果指定default,则用default代替None这个value值
8、popitem():随机删除键值对(通常删除最后一个键值对)
9、locals():将当前函数内部的变量生成字典对象,变量名为字典的key,变量值为字典的value
10、setdefault(key,default_value):如果不存在会在原字典里添加一个 key:default_value 并返回 default_value。(用法与get相似)
集合内建函数
1、add():添加一个元素
2、update():添加多个元素
3、remove():删除指定元素,如果不存在则报错
4、discard():删除指定元素
5、pop():随机删除(通常删除第一个元素)
6、-:差集 difference()
7、|:并集 union()
8、&:交集 intersection()
9、^:对称差集:symmetric()
七、运算符
1、**: 幂运算 用法:a**b a乘以b的幂次方
2、//:整除 用法:a//b a整除
3、三目运算符:结果 if 表达式 else 结果 案例:result=(a+b)if a>b else (a-b)
4、* :倍数
6、a in b:判断a字符串是否在b字符串里面 返回布尔值
7、a not in b:判断a字符串是否不在b字符串里面 返回布尔值
8、is:比较内存地址是否相同
9、r:保留原格式(转义无效)
10、[]:通过下标获取字母(用于字符串和列表) 常与:联用 表示截取字符串 [a:b](包前不包后) a:起始位置 b:结束位置 -a:反向起始位置 -b:反向结束位置
[a,b,c] c:表示方向和步长 1:表示从左往右 -1:表示从右往左
11、all((条件1,条件2)):条件1和条件2同时满足时则为True
12、any((条件1,条件2)):条件1和条件2有一个满足时则为True
八、函数
1、range(a,b):生成序列(包前不包后) a:起始位置 b:结束位置
2、type:判断参数的数据类型 语法:type(参数)
3、str():强制类型转换 转换为字符串
4、int():强制类型转换 转换成整型
5、list():强制类型转换 转换成列表
6、enumerate(list):枚举 index value
7、sorted():排序 当对字典进行排序的时候需要用到用到匿名函数
8、isinstance(a,b):判断a是否是b类型
9、lambda():匿名函数 语法:func=lambda a,b:a+b
func:匿名函数名 a:参数1 b:参数2
10、max():取出列表中的最大值 当对字典进行排序的时候需要用到用到匿名函数
11、min():取出列表中的最小值 当对字典进行排序的时候需要用到用到匿名函数
12、map(a,b):对列表中的元素进行统一操作 a:匿名函数 b:列表
list1=[3,4,6,7,8,9,9,0,2,5]
result=map(lambda x:x+2,list1)
13、reduce(a,b):对列表中的元素进行加减乘除运算 a:匿名函数 b:列表
tuple1=(3,5,7,8,9,1)
result=reduce(lambda x,y:x+y,tuple1)
14、filter():对字典、列表、元组等进行过滤操作 a:匿名函数 b:列表
当对字典进行排序的时候需要用到用到匿名函数
15、dir():查看类或者对象中的所有属性 或者对象或类.__dir__()
文件函数
1、open(file,mode,buffering,emcoding): file:文件路径 mode:读取模式
(r:读 w:写 b:二进制 )
2、read():读取文件内容
3、readline():每次读取一行内容
4、readlines():读取所有的行保存到列表中
5、readable():判断是否可读
6、write():写入当前内容 如果文件不存在则会自动创建文件
7、writelines(Iterable):迭代写入(没有换行效果)
8、close():关闭流
9、with as:常与open联用(可以帮助我们自动释放资源)语法:
with open(path) as stream:
10、stream.name:获取文件名
os.path常用函数
1、abspath():通过相对路径获取绝对路径 os.path.abspath(__file__) 获取当前文件的绝对路径
2、isdir():判断路径是否为目录
3、isfile():判断路径是否为文件
4、split():分割文件目录与文件名
5、splitext():分割文件与扩展名
6、getsize():获取文件的大小 单位字节
7、join(path1,path2):返回拼接后的新路径
8、dirname(a):获取文件所在的目录(绝对路径)__file__表示当前文件
9、exists():判断文件或文件夹是否存在
10、isabs():判断是否是绝对路径
os常用函数
1、getcwd():获取当前文件夹目录
2、listdir():浏览文件夹
3、mkdir():创建文件夹
4、rmdir():删除空文件夹
5、remove():删除文件
6、chdir():切换目录
九、循环控制语句
1、控制语句的语法:
if 条件表达式 :
执行语句
elif 条件表达式:
执行语句
else:
执行语句
2、循环语句语法:
for i in 循环对象:
执行语句
else:
执行语句
十、可变参数
*:表示元组 用法:def func (a,*b) 调用 可变参数放在后面 装包
**:表示字典 def func(**kwargs) key=value 如果传入的值为字典的话 需要拆包 **传入参数
十一、模块
time****模块
1、time.time():获取时间戳
2、time.sleep(a) a:时长
3、time.ctime(t):将时间戳转换成字符串
4、time.localtime(t):将时间戳转换成元组 t:时间戳
5、time.mktime(t):将元组的转成时间戳 t:时间元组
6、time.strftime(时间戳,‘日期格式’):底层将时间戳转换成元组再将元组转成字符串
7、time.strptime(‘字符串时间’,‘日期格式’):将字符串转成元组的方式
datetime模块
1、datetime.date(2020,6,20):创建date对象
2、datetime.date.today():获取当天的日期
3、datetime.datetime.now():得到当前的日期和时间
4、datetime.timedelta(days=?,weeks=?,minutes=?,hours=?):设置时间间隔
random模块
1、random.random():产生0-1之间的随机小数
2、random.randrange(start,stop,step):生成指定范围的随机整数 不包含stop
3、random.randint(start,stop,step):生成指定范围的随机整数 包含stop
4、random.choice(列表):随机选择列表内容
5、random.shuffle(pai):打乱顺序
6、random.uniform(start,stop):生成指定范围的随机浮点数数
hashlib模块
1、hashlib.md5():对字符串进行md5加密
语法:msg=‘马少强最帅’
md5=hashlib.md5(msg.encode('utf-8'))
print(len(md5.hexdigest()))
2、hashlib.sha1():对字符串进行sha1
sha1=hashlib.sha1(msg.encode('utf-8'))
print(len(sha1.hexdigest()))
3、hashlib.sha256():对字符串进行sha256
sha256=hashlib.sha256(msg.encode('utf-8'))
print(len(sha256.hexdigest()))
re模块
1、match(pattern,str) 从开头匹配一次
案例:
qq='14944689962'
result=re.match('^\[1-9\][0-9]{4,10}$',qq)
2、search(pattern,str) 只匹配一次
案例:
sername='admin001'
result=re.search('^\[^\d]\w{5,}$',username)
3、findall(pattern,str) 查询所有 re.S:可以匹配’\n’
案例:
msg='a*py ab.txt bb.py kk.png uu.py apyb.txt'
result=re.findall(r'\w*\.py\b',msg)
4、sub(pattern,new,str) 替换 new:新的内容(可以是字符串也可以是函数)
案例:
msg='java:99,python:100'
result=re.sub('\d+','90',msg)
print(result)
5、split(pattern,str)
案例:
result=re.split(r’[,:]’,msg)#在字符串中搜索如果遇到:或者,就分割将分割的内容都保存到列表中
6、group(num):获取组中匹配内容
案例:
1、number \number 引用第number组的数据
msg='<html><hi>abc</hi></html>'
result=re.match(r'<(\w+)><(\w+)>(.+)</\2></\1>$',msg)
print(result.group(1)) #html
2、?P<名字>
msg='<html><hi>123</hi></html>'
result=re.match('<(?P<name1>\w+)><(?P<name2>\w+)>(.+)</(?P=name2)></(?P=name1)>',msg)
print(result.group(1)) #html
7、导入模块的三种方式:
方式一:import 模块名(默认是在根目录下)
方式二:from 模块名 import 变量|函数|类
方式三:from 模块名 import * 导入模块中的所有内容
__all__=[使用*可以访问到的东西]
8、__name__:__name__就是标识模块名字的一个系统变量 在本模块中:__main__
在其他模块中:模块名
9、注意:
# from 模块名 import * 表示可以使用模块里面的所有内容,如果没有定义__all__所有的都可以访问,但是如果添加了__all__,只有__all__=[’’,’’]列表中的可以访问的
#from 包 import * 表示该包中的内容(模块)是不能完全访问的,就需要在__init__.py文件中定义__all__=[可以访问的模块]
unittest模块
1、from unittest import TestCase:导入单元测试
2、class TestBank(TestCase):创建单元测试类
3、注意:单元测试类中的方法名以"test_"开头
4、self.assertIs(测试值,预期值,失败执行):定义断言
成功则执行断言下的代码,失败则执行失败执行
simplejson模块
1、dump():生成json的类文件对象
2、dumps(字典):生成json字符串()
3、load():解析j类文件对象的json数据
4、loads():解析字符串格式的json数据
十二、数据异常
1、捕获异常:
try:
pass
except Exception as err:
print(err)
else:
pass(有异常则进入except,没有异常则进入else)
finally:
pass(无论有没有异常都会执行finally)
2、raise Exception (err):抛出异常 err:自定义异常信息
十三、列表推导式
列表推导式: 格式:[表达式 for 变量 in 旧列表 if 条件]
案例:将1-100之间能同时被3和5整除,组成一个列lt
result=[num for num in range(1,101) if num%3==0 and num%5==0]
案例:[(偶数,奇数),(偶数,奇数),(偶数,奇数)]
result=[(x,y) for x in range(5) if x%2==0 for y in range(10) if y%2!=0 ]
案例:if薪资大于5000加200,低于等于5000加500
result=[employee['salary']+200 if employee['salary']>5000 else employee['salary']+500 for employee in list1
集合推导式:{}类似于列表推导式,在列表推导式的基础上添加了一个去除重复项的功能
案例:list=[1,2,1,3,5,2,1,8,9,8,7]
set1={
x-1 for x in list if x>5}
字典推导式:
案例:dict1={‘a’:‘A’,‘b’:‘B’,‘c’:‘C’,‘d’:‘C’}
result={
value:key for key,value in dict1.items()}
print(result)
十四、生成器(协程)
1、第一种生成器方式:g=(x*3 for x in range(20))
2、第二种生成器方式:
def func():
n=0
while True:
n+=1
# print(n)
yield n #return n + 暂停
3、第一种调用生成器方式:next(生成器对象)
4、第二种调用生成器方式:生成器对象.__next__()
5、send函数案例
def gen():
i=0
while i<5:
temp=yield i
print('temp',temp)
for i in range(temp):
print('---------->')
print('*\*\*\*\*\***\*\*')
i+=1
return '没有更多的数据了'
g=gen()
send(None)
send(3)
十五、面向对象
1、普通方法:
def 方法名(self[,参数,参数]);
pass
2、类方法:
@classmethod
def test(cls):
pass
3、静态方法:
@staticmethod
def test():
pass
魔术方法:
1、__init__:初始化(绑定)对象属性 (相当于java中的构造方法)
触发时机:初始化对象时触发(不是实例化触发,但是和实例化在一个操作中)
2、__new__:实例化的魔术方法
触发时机:实例化对象时触发
3、__call__:对象调用的魔术方法
触发时机:将对象当成函数使用的时候,会默认调用此函数中内容
4、__del__:删除对象的魔术方法
触发时机:对象没有指针引用的时候触发,99%都不需要重写
5、__str__:打印对象名时能够给开发者提供更多的信息 相当于tostring()
触发时机:打印对象名,自动触发去调用__str__里面的内容
注意:一定要在__str__方法中添加return,return后面内容就是打印对象看到的内容
6、super():父类
7、python支持多继承 java 支持单继承
8、python3多继承中:默认的继承循序是广度优先
9、inspect.getmro(a) a.__mro__:多继承中的搜索顺序 a:类 import inspect
10、属性__:定义私有属性 例如:__field
11、对象:对象类型:使用对象时带有属性提示
案例:upload_file:FileStorage = request.files.get('user_photo')
封装私有化数据的两种方式:
1、定义公有的set和get方法 语法:
#set是为了赋值
def setAge(self,age):
if age>0 and age<=120:
self.age=age
else:
print('输入的姓名不在范围内')
#get是为了赋值
def getAge(self):
return self.age
2、使用装饰器@property 语法:
@property
def age(self):
return self.age
@age.setter
def age(self,age):
self.age=age
十六、自定义装饰器
import functools
import time
# 定义的查看执行时间的装饰器
def calculate_time(view_function):
# 防止装置器修改被装饰函数的名称和函数属性
@functools.wraps(view_function)
def wrapper(*args,**kwargs):
start_time = time.time()
view_function(*args,**kwargs)
end_time = time.time()
run_time = end_time - start_time
print("程序运行时间:%d" % run_time)
return wrapper
# 被装饰器修饰的函数
@calculate_time
def test():
for i in range(500):
print(i)
if __name__ == '__main__':
test()
十七、进程与线程
1、os.name():该变量返回当前操作系统的类型
2、os.getpid():获取当前进程id
3、os.getppid():获取当前进程的父进程id
创建进程:
from multiprocessing import Process
process = Process(target=函数,name=进程的名字,args=(给函数传递参数))
1、process.start():启动进程并执行任务
2、process.run():只是执行了任务但是没有启动进程
3、terminate():终止进程
创建进程池:
非阻塞式:全部添加到队列中,立刻返回,并没有等待其他的进程执行完毕,但是回调函数是等待任务完成之后调用。
阻塞式:添加一个任务执行一个任务,如果一个任务不结束另一个任务就进不来
from multiprocessing import Pool
pool=Pool(max):max:创建进程的容量
1、pool.apply(target,args=(给函数传递参数),callback=函数):创建阻塞式进程池
2、pool.apply_async(target,args=(给函数传递参数)) 创建非阻塞式进程池
3、pool.close():关闭进程池
4、pool.join():让进程让步
创建队列
from multiprocessing import Queue
q=Queue(max) max:创建进程的容量
1、q.qsize():查看队列的容量
2、q.put(值,timeout=时间):将值放入队列中 如果队列满了则只能等待
3、q.full():查看队列是否装满
4、q.empty():查看队列是否是空的
5、q.get():获取队列中的值
创建线程
import threading
t=threading.Thread(target=函数,name=进程的名字,daemon=True(开启守护进程),args=(给函数传递参数))
1、t.start():启动线程并执行任务
2、t.join():等待线程结束
3、GIL:全局解释器
创建线程锁
import threading
lock=threading.Lock()
1、lock.acquire() 请求得到锁 返回值为:True或False
2、lock.release() 释放锁
3、用法try-finally模式 with模式
import threading
lock=threading.Lock()
# try-finally模式
lock.acquire()
try:
# do something
finally:
lock.release()
# with模式
with lock:
# do somethihng
4、线程池的使用(ThreadPoolExecutor)
from concurrent.futures import ThreadPoolExecutor, as_completed
# 第一种方式 map函数很简单
with ThreadPoolExecutor() as pool:
results = pool.map(craw, urls)
for result in results:
print(result)
# 第二种方式 future模式更强大
with ThreadPoolExecutor() as pool:
futures = [ pool.submit(craw, url) for url in urls ]
# 第一种遍历方式
for future in futures:
print(future.result())
# 第二种遍历方式
for future in as_completed(futures):
print(future.result())
5、线程池加速Web服务
# 导入模块
from concurrent.futures import ThreadPoolExecutor
from flask import Flask
# 创建线程池对象
pool = ThreadPoolExecutor()
app = Flask(__name__)
def func():
return '111'
# 视图函数
@app.route('/')
def index():
result = pool.submit(func)
return result.result()
6、多线程多进程知识梳理

7、异步IO库 asyncio

8、控制异步IO并发度

十八、数据结构
1、队列:先进先出 两端畅通 举例:火车 电梯
2、栈:先进后出 低端堵住 举例:支付宝 洗碗
十九、自省函数
1、type():获取参数类型
2、getattr(object,attr):获取参数对象的舒心
3、hasattr(object,attr):判断对象是否含有某个属性
4、id():获取参数的id值(地址)
5、__dict__:查看类或类对象属性
二十、元类
1、 https://www.jianshu.com/p/c1ca0b9c777d:元类基础概念讲解
2、 https://www.jianshu.com/p/3263077933d3:元类进阶概念讲解
3、 type(class_name,(parent_class),{‘key’:’value’}) 创建元类
4、 metaclass:指定元类
二十一、Cerlery使用
-
Cerlery执行流程图
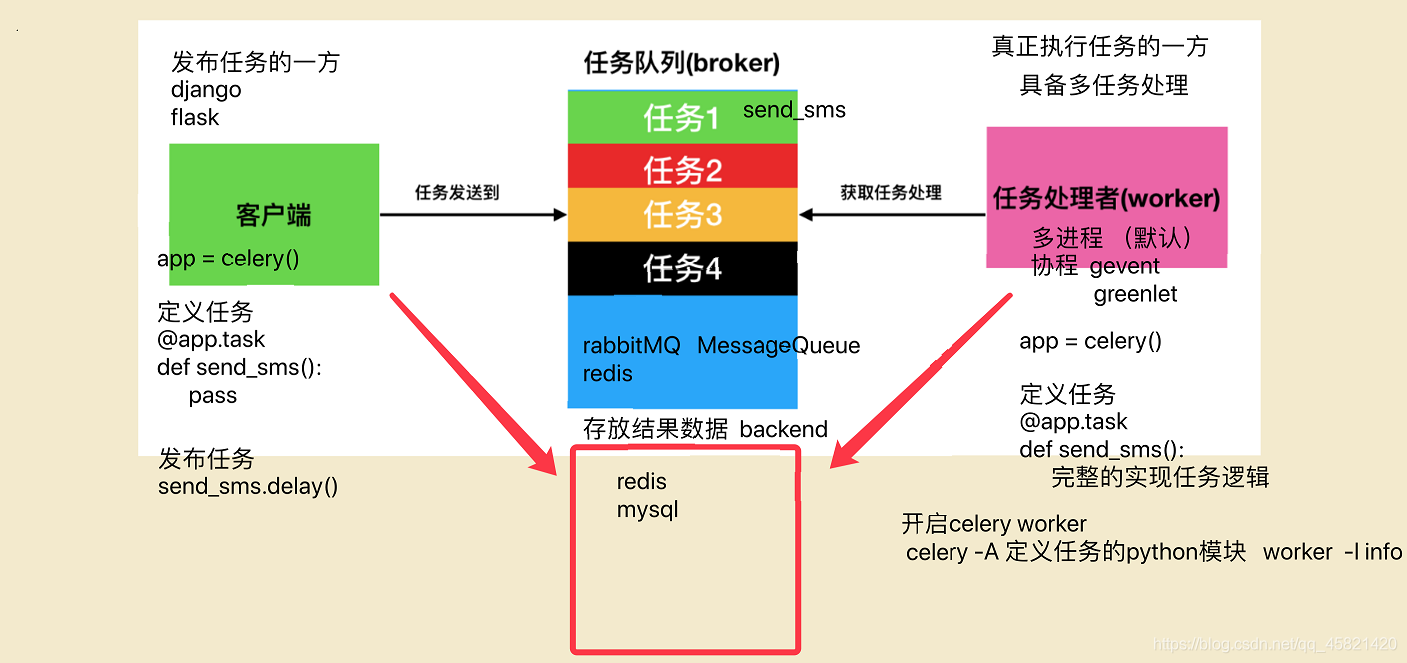
-
启动命令
celery -A ihome.tasks.task_sms(celery实例化文件) worker -l info
-
使用流程
- 初始化文件
from celery import Celery from ihome import SmsSDK # 定义celery对象 celery_app = Celery("ihome",broker="redis://127.0.0.1:6379/1") @celery_app.task def send_sms(to,datas,temp_id): """发送短信的异步任务""" SmsSDK.sendMessage(temp_id,to,datas)- 使用文件
from ihome.tasks.task_sms import send_sms send_sms.delay("1", mobile, (sms_code, constants.SMS_CODE_REDIS_EXPIRES // 60))
二十二、Python中Redis使用
-
redis的pipeline使用
import redis # 创建redis实例对象 redis_store = redis.StrictRedis(host=config_class.REDIS_HOST,port=config_class.REDIS_PORT,decode_responses=True) # 创建redis管道对象,可以一次执行多个语句,开启多个语句的记录 pipeline = redis_store.pipeline() pipeline.multi() pipeline.hset(redis_key, page, resp_json) pipeline.expire(redis_key, constants.HOUES_LIST_PAGE_REDIS_CACHE_EXPIRES) # 执行语句 pipeline.execute()
二十三、logging模块的使用
1、scrapy
- settings中设置LOG_LEVEL=“WARNING”
- settings中设置LOG_FILE="./a.log" #设置日志保存的位置,设置会后终端不会显示日志内容
- import logging,实例化logger的方式在任何文件中使用logger输出内容
2、普通项目中
- import logging
- logging.basicConfig(…) #设置日志输出的样式,格式
- 实例化一个
logger=logging.getLogger(__name__) - 在任何py文件中调用logger即可
二十四、面试题
1、小整数对象池(-5,256) 源程序和交互式对于大整数的处理方式不同
2、高并发(C10k)的解决方案:异步+消息队列(RabbitMQ)
3、并行:多个任务同时在运行,一般指的是多进程
4、并发:在特定时间段内,多个任务同时运行,一般指的是多线程
二十五、接口文档
-
书写格式
1、接口名字 例如:获取图片验证码
2、描述信息(描述清除接口的功能) 例如:前端访问可以获取到验证码图片
3、url 例如:/api/v1.0/image_codes/<image_code_id>
4、请求方式 例如:GET
5、传入参数
格式:路径参数(参数是查询字符串、请求体的表单、json、xml)
名字 类型 是否必须 说明
image_code_id 字符串 是 验证码图片的编号
返回值:
格式:正常:图片 异常:json
名字 类型 是否必须 说明
errno 字符串 否 错误代码
errmsg 字符串 否 错误内容
实例:
‘{“errno”:“40001”,“errmsg”:“保存图片验证码失败”}’
6、返回值