http
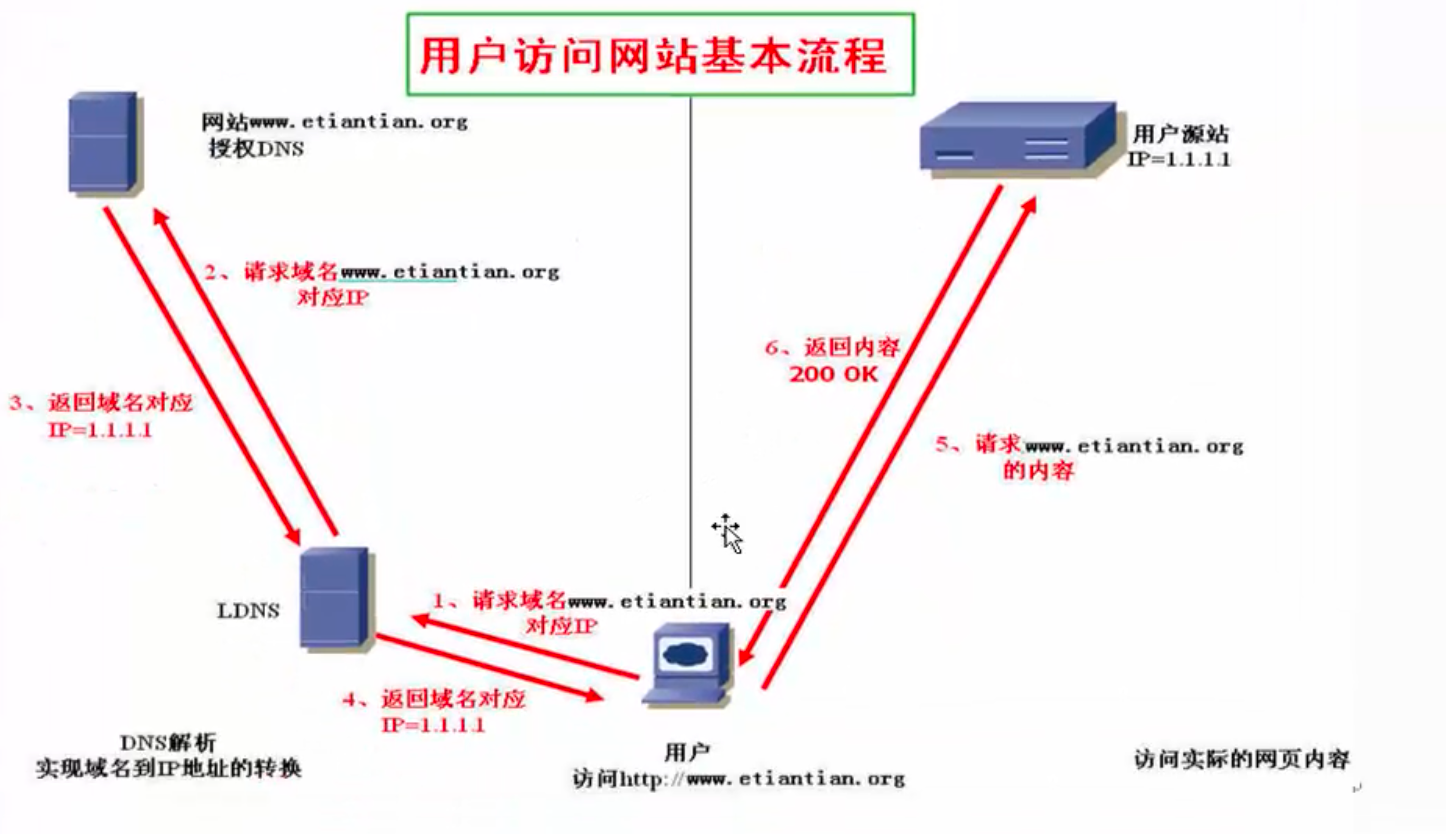
用户访问网站基本流程
- 我们每天都会使用Web客户端上网浏览网页。最常见的Web客户端就是Web浏览器,如通用的微软Internet Explorer(IE)以及技术人员偏爱的火狐浏览器,谷歌浏览器等。当我们在Web浏览器里输入网站地址(例如:www.baidu.com)时,很快就会看到网站的内容。这看起来很神奇的背后,到底是怎样的实现流程呢?也许普通的上网者无需关注,但作为一个IT技术人员,特别是合格的Linux运维人员,就需要清晰的掌握了。
-
下面就给大家介绍从客户端用户在Web浏览器里输入网站地址,到看到网站内容的完整访问流程。
-
[x] 第一步:客户端用户从浏览器里输入www.baidu.com网站地址,回车后,系统首先会查找系统本地的DNS缓存及hosts文件信息,查找是否存在www.baidu.com域名对应的IP解析记录,如果有就直接获取IP地址,然后去访问这个IP地址对应域名www.baidu.com的服务器,一般第一次请求时,DNS缓存是没有解析记录的,而hosts多在内部临时测试时使用。
-
[x] 第二步:如果客户端本地hosts及DNS缓存及hosts文件没有www.baidu.com域名对应的解析记录,那么,系统会把浏览器的解析请求发送给客户端本地设置的DNS服务器地址(通常称此DNS为LDNS,即Local DNS)解析,如果LDNS服务器的本地缓存有对应的解析记录就会直接返回IP地址给客户端,如果没有,则LDNS会负责继续请求其他的DNS服务器。
-
[x] 第三步:LDNS会从DNS系统的(.)开始请求www.baidu.com域名的解析,针对各个层级的DNS服务器系统进行一系列的查找,最终会查找到baidu.com域名对应的授权DNS服务器,而这个授权DNS服务器正是企业购买域名时用于管理域名解析的服务器,这个授权服务器会有www.baidu.com对应的IP解析记录,如果此时没有,就表示企业的域名管理人员没有为www.baidu.com域名做解析设置,即网站还没架设好。
-
[x] 第四步:baidu.com域名的授权DNS服务器会把www.baidu.com对应的最终IP解析记录发给LDNS。
-
[x] 第五步:LDNS把收到的来自授权DNS服务器www.baidu.com对应的IP解析记录发给客户端浏览器,并且再LDNS把本地域名和IP的对应解析缓存起来,以便下一次更快的返回相同解析请求的记录,这些缓存记录在指定的时间(DNS TTL值控制)内不会过期。
-
[x] 第六步:客户端浏览器获取到了www.etiantian.org的对应IP地址,接下来,浏览器会请求获得的IP地址对应的网站服务器,网站服务器接收到客户端的请求并响应处理(此处的处理可能是数百台集群的服务器系统,也可能是一台云主机),将客户请求的内容返回给客户端浏览器,至此,一次访问浏览网页的完整过程就完成了。
2)DNS系统解析基本流程
- 了解完用户访问网站的基本流程后,再来了解下DNS解析的基本流程,这是企业针对运维岗位进行招聘时经常会面试的问题,因此,必须要熟练掌握了。
- DNS,全称Domain Name System/Serve,它在一个网站运行中起来了至关重要的作用,它的主要作用是负责把网站域名解析为对应的IP地址,例如:把www.baidu.com解析为对应的IP地址记录如1.1.1.1,这个从域名到IP的解析过程,称作A记录,即Address Record。
- DNS系统除了负责这个最重要的A记录解析外,还有很多的功能。例如:
- 设置CNAME别名记录,这个别名解析功能常被CDN加速服务商应用。
- 设置MX邮件记录,这个MX记录功能,在购买或搭建邮件服务时会被用到。
- 设置PTR记录,反向解析,即把IP地址解析为对应的域名,和A记录的解析相反,邮件服务等业务中会用到。
- DNS 系统的架构类似于一颗倒挂着的树(和Linux系统目录结构类似),它的顶点也是根("."),只不过这个根是用点(.)来表示的,不是目录的根斜线(/)。

DNS解析原理流程

(1)DNS解析流程说明
- 在“用户访问网站基本流程”一节,我们了解了用户访问网站的基本实现过程,那么客户端是怎样一步步通过各个层级的DNS,获取到域名对应的IP的呢?这里给大家做一个较为详细的说明。
- DNS的解析流程实际上就是从用户在客户端浏览器中输入网站地址并按回车开始的,一直持续到获取域名对应的IP,整个过程可分为如下几个步骤。
- [x] 第一步:客户端用户从浏览器里输入www.baidu.com网站地址后回车,系统首先会查找系统本地的DNS缓存及hosts文件信息,确定是否存在www.baidu.com域名对应的IP解析记录,如果有就直接获取到IP地址,然后去访问这个IP地址对应的www.baidu.com域名的服务器,一般第一次请求时,DNS缓存是没有解析记录的,而hosts多为内部临时测试使用。
- [x] 第二步:如果客户端DNS缓存及本地hosts文件没有www.baidu.com域名对应的解析记录,那么,系统会把浏览器的解析请求发送给在客户端本地设置的DNS服务器地址(通常称此DNS为LDNS,即:Local DNS)解析,如果LDNS服务器的本地缓存有对应的解析记录就会直接返回IP地址给客户端:如果没有,则LDNS会负责继续请求其他的DNS服务器。
- [x] 第三步:LDNS会从DNS系统的(.)根开始请求www.baidu.com域名的解析,根DNS服务器在全球一共有13台,根服务器下面是没有www.baidu.com域名解析记录的,但是根下面有www.baidu.com对应的顶级域.org的解析记录,因此,根会把.org对应的DNS服务器地址返回给LDNS。
- [x] 第四步:LDNS获取到.org对应的DNS服务器地址后,就会去.org服务器请求www.baidu.com域名的解析,而.org服务器下面也没有www.baidu.com域名对应的解析记录,但是有baidu.com域名的解析记录,因此,.org服务器会把baidu.com对应的DNS服务器地址返回给LDNS
- [x] 第五步:同理,LDNS获取到baidu.com对应的DNS服务器地址后,就会去baidu.org服务器请求www.baidu.com域名的解析,baidu.com域名对应的DNS服务器是该域名的授权DNS服务器,这个DNS服务器正是企业购买域名时管理解析所在的服务器(也可能是自建的授权DNS服务器),这个服务器会有www.baidu.com对应的IP解析记录,如果此时没有,就表示企业的域名人员没有为www.baidu.com域名做解析,即网站还没架设好。
- [x] 第六步:baidu.com域名DNS服务器会把www.baidu.com对应的IP解析记录发给LDNS
- [x] 第七步:LDNS把收到的来自授权DNS服务器www.baidu.com对应的IP解析记录发给客户端浏览器,并且LDNS会把本地域名和IP的对应解析记录缓存起来,以便下一次更快的返回相同解析请求的记录。至此,整个DNS的解析流程就完成了。
(2)DNS解析流程图

二、HTTP协议
1)HTTP协议简介
- HTTP协议,全称HyperText Transfer Protocol,中文名为超文本传输协议,是互联网中最常用的一种网络协议。HTTP的重要应用之一是WWW服务。设计HTTP协议最初目的就是提供一种发布和接收HTML(一种页面标记语言)页面的方法(请求返回)。
- HTTP协议是互联网上常用的通信协议之一。它有很多的应用,但最流行的就是用于Web浏览器和Web服务器之间的通信,即WWW应用或称Web应用。
- WWW,全称World Wide Web,常称为Web,中文译为“万维网”。它是目前互联网上最受用户欢迎的信息服务形式。HTTP协议的WWW服务应用的默认端口为80(端口的概念),另外的一个加密的WWW服务应用https的默认端口为443,主要用于网银,支付等和钱相关的业务。当今,HTTP服务,WWW服务,Web服务三者的概念已经混淆了,都是指当下最常见的网站服务应用。
2)常见的HTTP请求方法
| HTTP方法 | 作用描述 |
|---|---|
| GET | 客户端请求指定资源信息,服务器返回指定资源 |
| HEAD | 只请求响应报文中的HTTP首部 |
| POST | 将客户端的数据提交到服务器,例:注册表单 |
| PUT | 从客户端向服务器传送的数据取代指定的文档内容 |
| DELETE | 请求服务器删除Request-URI所标识的资源 |
| MOVE | 请求服务器将制定的页面移至另一个网络地址 |
3)HTTP状态码
- HTTP状态码(HTTP Status Code)是用来表示Web服务器响应http请求状态的数字代码。每当Web客户端向Web服务器发送一个HTTP请求时,Web服务器都会返回一个状态响应代码。这个状态码是一个三位数字代码,作用是告知Web客户端此次的请求是否成功,或者是否要采取其他的动作方式。
- HTTP协议1.1版本中的状态吗可以分为五大类,如下表:
| 状态码范围 | 作用描述 |
|---|---|
| 100-199 | 用于指定客户端相应的某些动作 |
| 200-299 | 用于表示请求成功 |
| 300-399 | 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息 |
| 400-499 | 用于指出客户端的错误 |
| 500-599 | 用于指出服务器端的错误 |
生产场景常见的状态吗及其对应的作用
| 状态代码 | 详细描述说明 |
|---|---|
| 200~OK | 服务器成功返回网页,这是成功的http请求,返回的标准状态码 |
| 301-Moved Permanently | 永久跳转,所有请求的网页将永久跳转到被设定的新的位置,例如:从baidu.com跳转到www.baidu.com |
| 403-Forbidden | 禁止访问,这个请求是合法的,但是服务器端因为匹配了预先设置的规则而拒绝响应客户端的请求,此类问题一般为服务器或服务权限配置不当所致。 |
| 404-Not Found | 服务器找不到客户端请求的指定页面,可能是客户端请求了服务器上不存在的资源导致 |
| 500-Internal Server Error | 内部服务器错误,服务器遇到了意料不到的情况,不能完成客户的请求。这是一个较为笼统地报错,一般为服务器的设置或者内部程序问题导致。例如SElinux开启,而又没有为http设置规则许可,客户端访问就是500 |
| 502-Bad Gateway | 坏的网关,一般是代理服务器请求后端服务时,后端服务不可用或没有完成响应网关服务器。一般为反向代理服务器下面的节点出问题导致。 |
| 503-Service Unavailable | 服务当前不可用,可能因为服务器超载或停机维护导致,或者是反向代理服务器后面没有可以提供服务的节点 |
| 504-Gateway Timeout | 网关超时,一般是网关代理服务器请求后端服务时,后端服务没有在特定的时间内完成处理请求,一般是服务器过载导致没有在指定的时间内返回数据给前端代理服务器。 |
4)HTTP响应报文介绍
HTTP响应报文由起始行,响应头部,空行和响应报文主体几个部分组成,和HTTP请求报文格式类似。报文如下表:
| 报文格式 | 报文信息 |
|---|---|
| 起始行 | 协议及版本号 数字状态码 状态信息 |
| 响应头部 | 字段1:值1 字段2:值2 |
| 空行 | 空白内容 |
| 响应报文主体 | 就是html的网页 |
下面对响应报文的每个部分逐一阐述:
(1)起始行
响应报文的起始行,也叫状态行,用来说明服务器响应客户端请求的状况。一般为协议及版本号,数字状态码,状态情况。例如:HTTP/1.1 200 OK
(2)响应头部
和请求报文类似,起始行的后面一般有若干个头部字段。每个头部字段都包含一个名字和一个值,两者之间用冒号分隔。头部结尾也是以一个空行结束。常见的头部信息有:
(3)空行
最后一个响应头部信息之后是一个空行,发送回车符和换行符,通知客户端空行下文无头部信息。
(4)响应报文主体
响应报文主体中装载了要返回给客户端的数据。这些数据可以是文本,也可以是二进制的(图片,视频)。
三、URL介绍
用户发起的请求,就叫用户发起了URL
所谓的网址就是URL
网址=域名+资源位置(URI)
URL=域名+URIURL,全称Uniform Resource Location,中文翻译为统一资源定位符,也被称为网页地址(网址)。如同在网络上的门牌,它是因特网上标准的资源唯一地址。通俗地说,URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户端和服务器程序上。采用URL可以用一种统一的格式来描述各种信息资源,包括文件,服务器的地址和目录等。严格的说,每个URL都是一个URI,它标识一个互联网资源,并指定对其进行操作或取得该资源的方法。
URL的格式由下列三部分组成:
第一部分是协议,例如:http
第二部分是主机资源服务器IP地址或域名(端口号),例如:www.baidu.com
第三部分是主机资源的具体地址,如目录和文件名等,例如:yunjisuan/index.html提示:
第一部分和第二部分之间用“://”符号隔开,第二部分和第三部分用"/"符号隔开。第一部分和第二部分是不可缺少的,第三部分可以省略。
URI介绍
URI,全称Uniform Resource Identifier,中文翻译为统一资源标识符,是一个用于标识某一互联网资源名称的字符串。这个字符串在世界范围内唯一标识并定位某一个信息资源。互联网上每个可用的数据资源,如HTML,图片,视频等皆通过统一资源标识符进行定位。
URL是URI命名机制的一个子集
四、静态网页资源
在网站设计中,纯粹HTML格式的网页(可以包含图片,视频,JS(前端功能实现),CSS(样式)等)通常被称为“静态网页”,早期的网站大多都是静态的。静态网页是相对于动态网页而言的,是指没有后台数据库,不含程序(如php,jsp,asp)和可交互的网页。
静态网页资源特点
静态网页资源的特点是,开发者编写的是什么,它显示的就是什么,一旦编写完成,就不会有任何改变。静态网页的维护和更新相对比较麻烦,每个不同的网页都需要单独编集更新,静态网页一般适用于更新较少的宣传展示型网站(例如:酒,家具,猪饲料等的宣传网站),是早期很多中小网站展示的形式。
静态网页资源的对应程序及资源文件的常见扩展名为:
纯文本类程序或文件,如htm,html,xml,shtml,js,css等图片类文件或数据文档,如jpg,gif,png,bmp,txt,doc,ppt等视频类流媒体文件,如mp4,swf,avi,wmv,flv等
静态网页资源重要的特征
每个网页都有一个固定的URL地址,且URL一般以.html,.html,shtml等常见形式为后缀,而且地址中不含邮问号“?”或“&”等特殊符号。网页内容一经发布到网站服务器上,无论是否有用户访问,每个网页的内容都是保存在网站服务器文件系统上的,也就是说,静态网页是实实在在保存在服务器上的文件实体,每个网页都是一个独立的文件。网页内容是固定不变的,因此,容易被搜索引擎收录(容易被用户找到)(优点)网页没有数据库支持,在网站制作和维护方面工作量较大,因此当网站信息量很大时完全依靠静态网页制作的方式比较困难(缺点)网页的交互性较差,在程序功能实现方面有较大的限制(缺点)网页程序在用户浏览器端解析,如IE浏览器,程序解析效率很高,由于服务端不进行解析,并且不需要读取数据库,因此服务器端可以接受更多的并发访问。当客户端向服务器请求数据时,服务器直接把数据从磁盘文件系统上返回(不做任何解析),待客户端拿到数据后,在浏览器端解析展现出来(优点)
网站静态页面的特点就相当于在餐馆吃火锅,餐馆把原材料和工具都给你准备好,你自己只需要涮着吃就行,不需要饭店大厨给你炒菜做菜了,因此,对于饭店来讲,服务顾客的效率大大提高了。而对于静态页面来讲就是不需要服务器端解析,因此提供网站方服务器的压力也大大减轻了。
静态网页语言
常见的静态网页语言有html,js,css,xml,shtml等。
静态网页的核心特点
程序在客户浏览器端解析,不读取后端数据库,因此性能和效率很高。
因为后端没有数据库支持,所以和用户的交互性较差,功能实现也很少。
静态网页的架构思想
在高并发,高访问量的场景下做架构优化,涉及的关键环节就是把动态网页转成静态网页,而不直接请求数据库和动态服务器,并且可以把静态内容推送到前端缓存(或CDN)中提供服务,这样就可以提升用户体验,节约服务器和维护成本。
五、动态网页资源
所谓的动态网页是与静态网页相对而言的,也就是说,动态网页的URL后缀不是.htm,.html,.shtml,.xml,.js,.css等静态网页的常见后缀扩展名形式,而是以.asp,.aspx,.php,.js,.do,.cgi等形式作为后缀的,并且一般在动态网页网址中会有标志性的符号--“?,&”,此外,在大多数情况下后端都需要有数据库支持等。
动态网页资源特点
1)网页扩展名后缀常见为:.asp,.aspx,.php,.jsp,.do,cgi等
2)网页一般以数据库技术为基础,大大降低了网站维护的工作量
3)采用动态网页技术的网站可以实现更多的功能,如用户注册,用户登录,在线调查,投票,用户管理,订单管理,发博文等等
4)动态网页并不是独立存在于服务器上的网页文件,当用户请求服务器上的动态程序时,服务器解析这些程序并可能读取数据库返回一个完整的网页内容。
5)动态网页中的“?”在搜索引擎的收录方面存在一定问题,搜索引擎一般不会从一个网站的数据库中访问全部网页,或者出于技术等方面的考虑,搜索蜘蛛一般不会去抓去网址中“?”后面的内容,因此在企业通过搜索引擎进行推广时,需要针对采用动态网页的网站做一定的技术处理(伪静态技术),以便适应搜索因穷的抓取要求。
6)程序在服务器端解析,这相当于顾客点餐,饭店厨师做饭做菜,耗时长,效率低。由于程序在服务端解析,因此,会消耗大量的CPU和内存,I/O等资源,并且多数还要读取数据库等服务,因此,其访问效率远不如静态网页,在服务端解析动态程序的服务常见的有PHP引擎,Java容器(tomcat,resin,jboss,weblogic)
有关动态网页的架构思想
一般来说,静态网页的性能效率是动态网页的10~30倍。且动态网站效率很差,并发能力也很低,在高并发场景中,应尽可能转换成静态网页提供服务。动态转静态几乎是所有高并发网站必备的架构方案思路,也是高级架构师的职责所在。
此外,动态转静态也要根据业务需求设计,例如,对于更新频繁的网站如果设计不好就可能会产生数据不一致的情况,即用户看到的数据不是网站最新的内容,而是静态的内容。
六、网络流量度量术语
IP(internet Protocol)
IP(独立IP)即Internet Protocol,这里指独立IP数,独立IP数是指不同IP地址的计算机访问网站时被计算的总次数。独立IP数是衡量网站流量的一个重要指标。一般一天内(00:00 - 24:00)相同IP地址的客户端访问网站页面只被计算为一次,记录独立IP的时间可为一天或一个月,目前通用的标准为“一天”。
假设有部分同学同时在某处的局域网中打开了www.baidu.com,请问对于百度来说网站是几个独立IP?答:是一个独立IP。这是因为,国内几乎所有的公司都是采用局域网共享上网的,即通过路由器NAT地址转换上网,每个计算机在局域网内的私有IP是不同的,但是在外网上,就必须都要由路由器把每个私网地址转换成了路由器接口的固定公网IP(多IP映射暂不考虑),所以说,对于网站来说一天内多个相同公司的IP的客户端访问计算为一个独立IP
再假设一个客户端用户通过ADSL等直接拨号上网,但是上网的时候偶尔掉线,一共重新拨号了3次(相近时间重新拨号IP相同的几率是极少的),然后每次都继续打开百度的网页地址,请问此时,网站独立IP数是多少?还是一个独立IP
由此可见,通过独立iP数度量网站访问量,和实际的访问情况不是很匹配。国内的企业,学校大多数使用的NAT上网的,一个独立IP背后可能有数十上百个客户端访问。独立IP数虽然不是很准,但却是IT技术人员比较关心的一个衡量网站的指标。
PV(Page View)
PV(访问量)即Page View,中文翻译为页面浏览,即页面浏览器或点击量,不管客户端是不是相同,也不管IP是不是相同,用户每次访问一个网站页面都会被计算一个PV。
PV的具体度量方法就是从客户浏览器发出一个对Web服务器的请求(Request),Web服务器接到这个请求后,将该请求对应的一个网页(Page)发送给浏览器,就产生一个PV。这里有一个问题,就是只要这个请求发送给了浏览器,无论这个页面是否完全打开(或下载完成),那么都是会被计数为1个PV(服务器日志),一般为了防止用户快速刷PV,很多网站把PV的统计程序放在页面的最下面。
用PV衡量网站时,PV数反映的是浏览某网站的页面数量,每刷新一次页面也算一次。因此,可以说PV数与来访用户的数量成正比,但PV数并不是真正的页面来访者数量,而是网站被访问的页面数量,因为一个来访者可能产生多个PV。
UV(Unique Visitor)
UV(独立访客)即Unique Visitor,同一台客户端(PC或移动端)访问网站被计算为一个访客。一天(00:00-24:00)内相同的客户端访问同一个网站只计算一次UV。UV一般是以客户端Cookie等技术作为统计依据的,实际统计会有误差。
考虑到一台客户端电脑可能会有多人使用的情况,因此,UV(独立访客)实际上并不一定是独立的自然人访问。
1.http请求报文:浏览器版本,OS
2.http响应报文:cookie(id)
并发连接
理解:网站服务器在单位时间内能够处理的最大连接数。
统计并发数的基本方法
统计当下时刻的linux的网络连接数并发,netstat -an|grep -i “est”|wc -l
nginx web 层 active status
测试磁盘的存储性能?
连续的读写向磁盘中写入大的文件
dd if=/dev/zero of=/tmp/test01.bin bs=1K count=10000
七、www服务软件介绍
常用来提供静态Web服务的软件
Apache:这是中小型Web服务的主流,Web服务器中的老大哥。
Nginx:大型网站Web服务主流,曾经Web服务器中的初生牛犊,现已长大。Nginx的分支tengine(http://tengine.taobao.org/)目前也在飞速发展。
Lighttpd:这是一个不温不火的优秀的Web软件,社区不活跃,静态解析效率很高。在Nginx流行前,它是大并发静态业务的首选,国内百度贴吧,豆瓣等众多网站都有lighttpd奋斗的身影。
常用来提供动态服务的软件
PHP(fastcgi):大中小型网站都会使用,动态网页语言PHP程序的解析容器。它可配合Apache解析动态程序,不过,这里的PHP不是Fastcgi守护进程模式,而是mod_php5.so(module).也可配合Nginx解析动态程序,此时的PHP常用Fastcgi守护进程模式提供服务。
tomcat:中小企业动态Web服务主流,互联网Java容器主流(如jsp,do)
resin:大型动态Web服务主流,互联网Java容器主流(如jsp,do)
IIS(internet information services):微软Windows下的Web服务软件(asp,.aspx)
www 静态程序服务软件apache
Apache软件有几个重要的版本系列,分别为:Apache1.3,Apache2.0,Apache2.2,Apache2.4等,其中,APache1.3和Apache2.0系列已经成为过去时,官方的网站也看不见其踪影了,目前主流的Apache为2.2系列,正在向Apache2.4系列过渡阶段。如果没有特别要求,建议读者当下使用Apache2.2系列。
官方地址:http://www.apache.org/
www静态服务软件Nginx
Nginx的版本只有一个系列,但是版本更新很快,仅仅半年就有数个版本,这也看出来社区的活跃程序。具体内容参见文档地址:http://www.nginx.org/以及http://www.nginx.org/en/docs/
www 动态服务软件Resin
Resin官方号称是世界上最快的Web服务,是大型动态Web服务主流,为互联网Java程序的解析容器,百度,人人都曾用过Resin
目前企业用的较多的是3.1系列,正在向4.0过度
www动态服务软件PHP
PHP软件是大中小型网站程序前台页面开发的首选,存世开源软件众多,也是中小企业网站开发的首选,它是动态网页语言PHP程序的解析容器。PHP的版本系列有PHP5.2,PHP5.3,PHP5.4,PHP5.5,PHP5.6,其中最经典的版本为PHP5.2系列,企业应用的主流版本可以说是百花争艳。
值得注意的是PHP提供解析的方式,在配合Apache解析动态程序时,用的是mod_php5.so(module)模块的方式:在配合nginx解析动态程序时,常用Fastcgi守护进程模式提供服务。
用户访问网站基本流程
- 我们每天都会使用Web客户端上网浏览网页。最常见的Web客户端就是Web浏览器,如通用的微软Internet Explorer(IE)以及技术人员偏爱的火狐浏览器,谷歌浏览器等。当我们在Web浏览器里输入网站地址(例如:www.baidu.com)时,很快就会看到网站的内容。这看起来很神奇的背后,到底是怎样的实现流程呢?也许普通的上网者无需关注,但作为一个IT技术人员,特别是合格的Linux运维人员,就需要清晰的掌握了。
-
下面就给大家介绍从客户端用户在Web浏览器里输入网站地址,到看到网站内容的完整访问流程。
-
[x] 第一步:客户端用户从浏览器里输入www.baidu.com网站地址,回车后,系统首先会查找系统本地的DNS缓存及hosts文件信息,查找是否存在www.baidu.com域名对应的IP解析记录,如果有就直接获取IP地址,然后去访问这个IP地址对应域名www.baidu.com的服务器,一般第一次请求时,DNS缓存是没有解析记录的,而hosts多在内部临时测试时使用。
-
[x] 第二步:如果客户端本地hosts及DNS缓存及hosts文件没有www.baidu.com域名对应的解析记录,那么,系统会把浏览器的解析请求发送给客户端本地设置的DNS服务器地址(通常称此DNS为LDNS,即Local DNS)解析,如果LDNS服务器的本地缓存有对应的解析记录就会直接返回IP地址给客户端,如果没有,则LDNS会负责继续请求其他的DNS服务器。
-
[x] 第三步:LDNS会从DNS系统的(.)开始请求www.baidu.com域名的解析,针对各个层级的DNS服务器系统进行一系列的查找,最终会查找到baidu.com域名对应的授权DNS服务器,而这个授权DNS服务器正是企业购买域名时用于管理域名解析的服务器,这个授权服务器会有www.baidu.com对应的IP解析记录,如果此时没有,就表示企业的域名管理人员没有为www.baidu.com域名做解析设置,即网站还没架设好。
-
[x] 第四步:baidu.com域名的授权DNS服务器会把www.baidu.com对应的最终IP解析记录发给LDNS。
-
[x] 第五步:LDNS把收到的来自授权DNS服务器www.baidu.com对应的IP解析记录发给客户端浏览器,并且再LDNS把本地域名和IP的对应解析缓存起来,以便下一次更快的返回相同解析请求的记录,这些缓存记录在指定的时间(DNS TTL值控制)内不会过期。
-
[x] 第六步:客户端浏览器获取到了www.etiantian.org的对应IP地址,接下来,浏览器会请求获得的IP地址对应的网站服务器,网站服务器接收到客户端的请求并响应处理(此处的处理可能是数百台集群的服务器系统,也可能是一台云主机),将客户请求的内容返回给客户端浏览器,至此,一次访问浏览网页的完整过程就完成了。
2)DNS系统解析基本流程
- 了解完用户访问网站的基本流程后,再来了解下DNS解析的基本流程,这是企业针对运维岗位进行招聘时经常会面试的问题,因此,必须要熟练掌握了。
- DNS,全称Domain Name System/Serve,它在一个网站运行中起来了至关重要的作用,它的主要作用是负责把网站域名解析为对应的IP地址,例如:把www.baidu.com解析为对应的IP地址记录如1.1.1.1,这个从域名到IP的解析过程,称作A记录,即Address Record。
- DNS系统除了负责这个最重要的A记录解析外,还有很多的功能。例如:
- 设置CNAME别名记录,这个别名解析功能常被CDN加速服务商应用。
- 设置MX邮件记录,这个MX记录功能,在购买或搭建邮件服务时会被用到。
- 设置PTR记录,反向解析,即把IP地址解析为对应的域名,和A记录的解析相反,邮件服务等业务中会用到。
- DNS 系统的架构类似于一颗倒挂着的树(和Linux系统目录结构类似),它的顶点也是根("."),只不过这个根是用点(.)来表示的,不是目录的根斜线(/)。
DNS解析原理流程
(1)DNS解析流程说明
- 在“用户访问网站基本流程”一节,我们了解了用户访问网站的基本实现过程,那么客户端是怎样一步步通过各个层级的DNS,获取到域名对应的IP的呢?这里给大家做一个较为详细的说明。
- DNS的解析流程实际上就是从用户在客户端浏览器中输入网站地址并按回车开始的,一直持续到获取域名对应的IP,整个过程可分为如下几个步骤。
- [x] 第一步:客户端用户从浏览器里输入www.baidu.com网站地址后回车,系统首先会查找系统本地的DNS缓存及hosts文件信息,确定是否存在www.baidu.com域名对应的IP解析记录,如果有就直接获取到IP地址,然后去访问这个IP地址对应的www.baidu.com域名的服务器,一般第一次请求时,DNS缓存是没有解析记录的,而hosts多为内部临时测试使用。
- [x] 第二步:如果客户端DNS缓存及本地hosts文件没有www.baidu.com域名对应的解析记录,那么,系统会把浏览器的解析请求发送给在客户端本地设置的DNS服务器地址(通常称此DNS为LDNS,即:Local DNS)解析,如果LDNS服务器的本地缓存有对应的解析记录就会直接返回IP地址给客户端:如果没有,则LDNS会负责继续请求其他的DNS服务器。
- [x] 第三步:LDNS会从DNS系统的(.)根开始请求www.baidu.com域名的解析,根DNS服务器在全球一共有13台,根服务器下面是没有www.baidu.com域名解析记录的,但是根下面有www.baidu.com对应的顶级域.org的解析记录,因此,根会把.org对应的DNS服务器地址返回给LDNS。
- [x] 第四步:LDNS获取到.org对应的DNS服务器地址后,就会去.org服务器请求www.baidu.com域名的解析,而.org服务器下面也没有www.baidu.com域名对应的解析记录,但是有baidu.com域名的解析记录,因此,.org服务器会把baidu.com对应的DNS服务器地址返回给LDNS
- [x] 第五步:同理,LDNS获取到baidu.com对应的DNS服务器地址后,就会去baidu.org服务器请求www.baidu.com域名的解析,baidu.com域名对应的DNS服务器是该域名的授权DNS服务器,这个DNS服务器正是企业购买域名时管理解析所在的服务器(也可能是自建的授权DNS服务器),这个服务器会有www.baidu.com对应的IP解析记录,如果此时没有,就表示企业的域名人员没有为www.baidu.com域名做解析,即网站还没架设好。
- [x] 第六步:baidu.com域名DNS服务器会把www.baidu.com对应的IP解析记录发给LDNS
- [x] 第七步:LDNS把收到的来自授权DNS服务器www.baidu.com对应的IP解析记录发给客户端浏览器,并且LDNS会把本地域名和IP的对应解析记录缓存起来,以便下一次更快的返回相同解析请求的记录。至此,整个DNS的解析流程就完成了。
(2)DNS解析流程图
二、HTTP协议
1)HTTP协议简介
- HTTP协议,全称HyperText Transfer Protocol,中文名为超文本传输协议,是互联网中最常用的一种网络协议。HTTP的重要应用之一是WWW服务。设计HTTP协议最初目的就是提供一种发布和接收HTML(一种页面标记语言)页面的方法(请求返回)。
- HTTP协议是互联网上常用的通信协议之一。它有很多的应用,但最流行的就是用于Web浏览器和Web服务器之间的通信,即WWW应用或称Web应用。
- WWW,全称World Wide Web,常称为Web,中文译为“万维网”。它是目前互联网上最受用户欢迎的信息服务形式。HTTP协议的WWW服务应用的默认端口为80(端口的概念),另外的一个加密的WWW服务应用https的默认端口为443,主要用于网银,支付等和钱相关的业务。当今,HTTP服务,WWW服务,Web服务三者的概念已经混淆了,都是指当下最常见的网站服务应用。
2)常见的HTTP请求方法
| HTTP方法 | 作用描述 |
|---|---|
| GET | 客户端请求指定资源信息,服务器返回指定资源 |
| HEAD | 只请求响应报文中的HTTP首部 |
| POST | 将客户端的数据提交到服务器,例:注册表单 |
| PUT | 从客户端向服务器传送的数据取代指定的文档内容 |
| DELETE | 请求服务器删除Request-URI所标识的资源 |
| MOVE | 请求服务器将制定的页面移至另一个网络地址 |
3)HTTP状态码
- HTTP状态码(HTTP Status Code)是用来表示Web服务器响应http请求状态的数字代码。每当Web客户端向Web服务器发送一个HTTP请求时,Web服务器都会返回一个状态响应代码。这个状态码是一个三位数字代码,作用是告知Web客户端此次的请求是否成功,或者是否要采取其他的动作方式。
- HTTP协议1.1版本中的状态吗可以分为五大类,如下表:
| 状态码范围 | 作用描述 |
|---|---|
| 100-199 | 用于指定客户端相应的某些动作 |
| 200-299 | 用于表示请求成功 |
| 300-399 | 用于已经移动的文件并且常被包含在定位头信息中指定新的地址信息 |
| 400-499 | 用于指出客户端的错误 |
| 500-599 | 用于指出服务器端的错误 |
生产场景常见的状态吗及其对应的作用
| 状态代码 | 详细描述说明 |
|---|---|
| 200~OK | 服务器成功返回网页,这是成功的http请求,返回的标准状态码 |
| 301-Moved Permanently | 永久跳转,所有请求的网页将永久跳转到被设定的新的位置,例如:从baidu.com跳转到www.baidu.com |
| 403-Forbidden | 禁止访问,这个请求是合法的,但是服务器端因为匹配了预先设置的规则而拒绝响应客户端的请求,此类问题一般为服务器或服务权限配置不当所致。 |
| 404-Not Found | 服务器找不到客户端请求的指定页面,可能是客户端请求了服务器上不存在的资源导致 |
| 500-Internal Server Error | 内部服务器错误,服务器遇到了意料不到的情况,不能完成客户的请求。这是一个较为笼统地报错,一般为服务器的设置或者内部程序问题导致。例如SElinux开启,而又没有为http设置规则许可,客户端访问就是500 |
| 502-Bad Gateway | 坏的网关,一般是代理服务器请求后端服务时,后端服务不可用或没有完成响应网关服务器。一般为反向代理服务器下面的节点出问题导致。 |
| 503-Service Unavailable | 服务当前不可用,可能因为服务器超载或停机维护导致,或者是反向代理服务器后面没有可以提供服务的节点 |
| 504-Gateway Timeout | 网关超时,一般是网关代理服务器请求后端服务时,后端服务没有在特定的时间内完成处理请求,一般是服务器过载导致没有在指定的时间内返回数据给前端代理服务器。 |
4)HTTP响应报文介绍
HTTP响应报文由起始行,响应头部,空行和响应报文主体几个部分组成,和HTTP请求报文格式类似。报文如下表:
| 报文格式 | 报文信息 |
|---|---|
| 起始行 | 协议及版本号 数字状态码 状态信息 |
| 响应头部 | 字段1:值1 字段2:值2 |
| 空行 | 空白内容 |
| 响应报文主体 | 就是html的网页 |
下面对响应报文的每个部分逐一阐述:
(1)起始行
响应报文的起始行,也叫状态行,用来说明服务器响应客户端请求的状况。一般为协议及版本号,数字状态码,状态情况。例如:HTTP/1.1 200 OK
(2)响应头部
和请求报文类似,起始行的后面一般有若干个头部字段。每个头部字段都包含一个名字和一个值,两者之间用冒号分隔。头部结尾也是以一个空行结束。常见的头部信息有:
(3)空行
最后一个响应头部信息之后是一个空行,发送回车符和换行符,通知客户端空行下文无头部信息。
(4)响应报文主体
响应报文主体中装载了要返回给客户端的数据。这些数据可以是文本,也可以是二进制的(图片,视频)。
三、URL介绍
用户发起的请求,就叫用户发起了URL
所谓的网址就是URL
网址=域名+资源位置(URI)
URL=域名+URIURL,全称Uniform Resource Location,中文翻译为统一资源定位符,也被称为网页地址(网址)。如同在网络上的门牌,它是因特网上标准的资源唯一地址。通俗地说,URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户端和服务器程序上。采用URL可以用一种统一的格式来描述各种信息资源,包括文件,服务器的地址和目录等。严格的说,每个URL都是一个URI,它标识一个互联网资源,并指定对其进行操作或取得该资源的方法。
URL的格式由下列三部分组成:
第一部分是协议,例如:http
第二部分是主机资源服务器IP地址或域名(端口号),例如:www.baidu.com
第三部分是主机资源的具体地址,如目录和文件名等,例如:yunjisuan/index.html提示:
第一部分和第二部分之间用“://”符号隔开,第二部分和第三部分用"/"符号隔开。第一部分和第二部分是不可缺少的,第三部分可以省略。
URI介绍
URI,全称Uniform Resource Identifier,中文翻译为统一资源标识符,是一个用于标识某一互联网资源名称的字符串。这个字符串在世界范围内唯一标识并定位某一个信息资源。互联网上每个可用的数据资源,如HTML,图片,视频等皆通过统一资源标识符进行定位。
URL是URI命名机制的一个子集
四、静态网页资源
在网站设计中,纯粹HTML格式的网页(可以包含图片,视频,JS(前端功能实现),CSS(样式)等)通常被称为“静态网页”,早期的网站大多都是静态的。静态网页是相对于动态网页而言的,是指没有后台数据库,不含程序(如php,jsp,asp)和可交互的网页。
静态网页资源特点
静态网页资源的特点是,开发者编写的是什么,它显示的就是什么,一旦编写完成,就不会有任何改变。静态网页的维护和更新相对比较麻烦,每个不同的网页都需要单独编集更新,静态网页一般适用于更新较少的宣传展示型网站(例如:酒,家具,猪饲料等的宣传网站),是早期很多中小网站展示的形式。
静态网页资源的对应程序及资源文件的常见扩展名为:
纯文本类程序或文件,如htm,html,xml,shtml,js,css等图片类文件或数据文档,如jpg,gif,png,bmp,txt,doc,ppt等视频类流媒体文件,如mp4,swf,avi,wmv,flv等
静态网页资源重要的特征
每个网页都有一个固定的URL地址,且URL一般以.html,.html,shtml等常见形式为后缀,而且地址中不含邮问号“?”或“&”等特殊符号。网页内容一经发布到网站服务器上,无论是否有用户访问,每个网页的内容都是保存在网站服务器文件系统上的,也就是说,静态网页是实实在在保存在服务器上的文件实体,每个网页都是一个独立的文件。网页内容是固定不变的,因此,容易被搜索引擎收录(容易被用户找到)(优点)网页没有数据库支持,在网站制作和维护方面工作量较大,因此当网站信息量很大时完全依靠静态网页制作的方式比较困难(缺点)网页的交互性较差,在程序功能实现方面有较大的限制(缺点)网页程序在用户浏览器端解析,如IE浏览器,程序解析效率很高,由于服务端不进行解析,并且不需要读取数据库,因此服务器端可以接受更多的并发访问。当客户端向服务器请求数据时,服务器直接把数据从磁盘文件系统上返回(不做任何解析),待客户端拿到数据后,在浏览器端解析展现出来(优点)
网站静态页面的特点就相当于在餐馆吃火锅,餐馆把原材料和工具都给你准备好,你自己只需要涮着吃就行,不需要饭店大厨给你炒菜做菜了,因此,对于饭店来讲,服务顾客的效率大大提高了。而对于静态页面来讲就是不需要服务器端解析,因此提供网站方服务器的压力也大大减轻了。
静态网页语言
常见的静态网页语言有html,js,css,xml,shtml等。
静态网页的核心特点
程序在客户浏览器端解析,不读取后端数据库,因此性能和效率很高。
因为后端没有数据库支持,所以和用户的交互性较差,功能实现也很少。
静态网页的架构思想
在高并发,高访问量的场景下做架构优化,涉及的关键环节就是把动态网页转成静态网页,而不直接请求数据库和动态服务器,并且可以把静态内容推送到前端缓存(或CDN)中提供服务,这样就可以提升用户体验,节约服务器和维护成本。
五、动态网页资源
所谓的动态网页是与静态网页相对而言的,也就是说,动态网页的URL后缀不是.htm,.html,.shtml,.xml,.js,.css等静态网页的常见后缀扩展名形式,而是以.asp,.aspx,.php,.js,.do,.cgi等形式作为后缀的,并且一般在动态网页网址中会有标志性的符号--“?,&”,此外,在大多数情况下后端都需要有数据库支持等。
动态网页资源特点
1)网页扩展名后缀常见为:.asp,.aspx,.php,.jsp,.do,cgi等
2)网页一般以数据库技术为基础,大大降低了网站维护的工作量
3)采用动态网页技术的网站可以实现更多的功能,如用户注册,用户登录,在线调查,投票,用户管理,订单管理,发博文等等
4)动态网页并不是独立存在于服务器上的网页文件,当用户请求服务器上的动态程序时,服务器解析这些程序并可能读取数据库返回一个完整的网页内容。
5)动态网页中的“?”在搜索引擎的收录方面存在一定问题,搜索引擎一般不会从一个网站的数据库中访问全部网页,或者出于技术等方面的考虑,搜索蜘蛛一般不会去抓去网址中“?”后面的内容,因此在企业通过搜索引擎进行推广时,需要针对采用动态网页的网站做一定的技术处理(伪静态技术),以便适应搜索因穷的抓取要求。
6)程序在服务器端解析,这相当于顾客点餐,饭店厨师做饭做菜,耗时长,效率低。由于程序在服务端解析,因此,会消耗大量的CPU和内存,I/O等资源,并且多数还要读取数据库等服务,因此,其访问效率远不如静态网页,在服务端解析动态程序的服务常见的有PHP引擎,Java容器(tomcat,resin,jboss,weblogic)
有关动态网页的架构思想
一般来说,静态网页的性能效率是动态网页的10~30倍。且动态网站效率很差,并发能力也很低,在高并发场景中,应尽可能转换成静态网页提供服务。动态转静态几乎是所有高并发网站必备的架构方案思路,也是高级架构师的职责所在。
此外,动态转静态也要根据业务需求设计,例如,对于更新频繁的网站如果设计不好就可能会产生数据不一致的情况,即用户看到的数据不是网站最新的内容,而是静态的内容。
六、网络流量度量术语
IP(internet Protocol)
IP(独立IP)即Internet Protocol,这里指独立IP数,独立IP数是指不同IP地址的计算机访问网站时被计算的总次数。独立IP数是衡量网站流量的一个重要指标。一般一天内(00:00 - 24:00)相同IP地址的客户端访问网站页面只被计算为一次,记录独立IP的时间可为一天或一个月,目前通用的标准为“一天”。
假设有部分同学同时在某处的局域网中打开了www.baidu.com,请问对于百度来说网站是几个独立IP?答:是一个独立IP。这是因为,国内几乎所有的公司都是采用局域网共享上网的,即通过路由器NAT地址转换上网,每个计算机在局域网内的私有IP是不同的,但是在外网上,就必须都要由路由器把每个私网地址转换成了路由器接口的固定公网IP(多IP映射暂不考虑),所以说,对于网站来说一天内多个相同公司的IP的客户端访问计算为一个独立IP
再假设一个客户端用户通过ADSL等直接拨号上网,但是上网的时候偶尔掉线,一共重新拨号了3次(相近时间重新拨号IP相同的几率是极少的),然后每次都继续打开百度的网页地址,请问此时,网站独立IP数是多少?还是一个独立IP
由此可见,通过独立iP数度量网站访问量,和实际的访问情况不是很匹配。国内的企业,学校大多数使用的NAT上网的,一个独立IP背后可能有数十上百个客户端访问。独立IP数虽然不是很准,但却是IT技术人员比较关心的一个衡量网站的指标。
PV(Page View)
PV(访问量)即Page View,中文翻译为页面浏览,即页面浏览器或点击量,不管客户端是不是相同,也不管IP是不是相同,用户每次访问一个网站页面都会被计算一个PV。
PV的具体度量方法就是从客户浏览器发出一个对Web服务器的请求(Request),Web服务器接到这个请求后,将该请求对应的一个网页(Page)发送给浏览器,就产生一个PV。这里有一个问题,就是只要这个请求发送给了浏览器,无论这个页面是否完全打开(或下载完成),那么都是会被计数为1个PV(服务器日志),一般为了防止用户快速刷PV,很多网站把PV的统计程序放在页面的最下面。
用PV衡量网站时,PV数反映的是浏览某网站的页面数量,每刷新一次页面也算一次。因此,可以说PV数与来访用户的数量成正比,但PV数并不是真正的页面来访者数量,而是网站被访问的页面数量,因为一个来访者可能产生多个PV。
UV(Unique Visitor)
UV(独立访客)即Unique Visitor,同一台客户端(PC或移动端)访问网站被计算为一个访客。一天(00:00-24:00)内相同的客户端访问同一个网站只计算一次UV。UV一般是以客户端Cookie等技术作为统计依据的,实际统计会有误差。
考虑到一台客户端电脑可能会有多人使用的情况,因此,UV(独立访客)实际上并不一定是独立的自然人访问。
1.http请求报文:浏览器版本,OS
2.http响应报文:cookie(id)
并发连接
理解:网站服务器在单位时间内能够处理的最大连接数。
统计并发数的基本方法
统计当下时刻的linux的网络连接数并发,netstat -an|grep -i “est”|wc -l
nginx web 层 active status
测试磁盘的存储性能?
连续的读写向磁盘中写入大的文件
dd if=/dev/zero of=/tmp/test01.bin bs=1K count=10000
七、www服务软件介绍
常用来提供静态Web服务的软件
Apache:这是中小型Web服务的主流,Web服务器中的老大哥。
Nginx:大型网站Web服务主流,曾经Web服务器中的初生牛犊,现已长大。Nginx的分支tengine(http://tengine.taobao.org/)目前也在飞速发展。
Lighttpd:这是一个不温不火的优秀的Web软件,社区不活跃,静态解析效率很高。在Nginx流行前,它是大并发静态业务的首选,国内百度贴吧,豆瓣等众多网站都有lighttpd奋斗的身影。
常用来提供动态服务的软件
PHP(fastcgi):大中小型网站都会使用,动态网页语言PHP程序的解析容器。它可配合Apache解析动态程序,不过,这里的PHP不是Fastcgi守护进程模式,而是mod_php5.so(module).也可配合Nginx解析动态程序,此时的PHP常用Fastcgi守护进程模式提供服务。
tomcat:中小企业动态Web服务主流,互联网Java容器主流(如jsp,do)
resin:大型动态Web服务主流,互联网Java容器主流(如jsp,do)
IIS(internet information services):微软Windows下的Web服务软件(asp,.aspx)
www 静态程序服务软件apache
Apache软件有几个重要的版本系列,分别为:Apache1.3,Apache2.0,Apache2.2,Apache2.4等,其中,APache1.3和Apache2.0系列已经成为过去时,官方的网站也看不见其踪影了,目前主流的Apache为2.2系列,正在向Apache2.4系列过渡阶段。如果没有特别要求,建议读者当下使用Apache2.2系列。
官方地址:http://www.apache.org/
www静态服务软件Nginx
Nginx的版本只有一个系列,但是版本更新很快,仅仅半年就有数个版本,这也看出来社区的活跃程序。具体内容参见文档地址:http://www.nginx.org/以及http://www.nginx.org/en/docs/
www 动态服务软件Resin
Resin官方号称是世界上最快的Web服务,是大型动态Web服务主流,为互联网Java程序的解析容器,百度,人人都曾用过Resin
目前企业用的较多的是3.1系列,正在向4.0过度
www动态服务软件PHP
PHP软件是大中小型网站程序前台页面开发的首选,存世开源软件众多,也是中小企业网站开发的首选,它是动态网页语言PHP程序的解析容器。PHP的版本系列有PHP5.2,PHP5.3,PHP5.4,PHP5.5,PHP5.6,其中最经典的版本为PHP5.2系列,企业应用的主流版本可以说是百花争艳。
值得注意的是PHP提供解析的方式,在配合Apache解析动态程序时,用的是mod_php5.so(module)模块的方式:在配合nginx解析动态程序时,常用Fastcgi守护进程模式提供服务。