全套教程请点击:微软 AI 开发教程
第三篇:激活函数和损失函数(一)
在这一章,我们将简要介绍一下激活函数~
激活函数
看神经网络中的一个神经元,为了简化,假设该神经元接受三个输入,分别为\(x_1, x_2, x_3\),那么\(z=\sum\limits_{i}w_ix_i+b_i\),
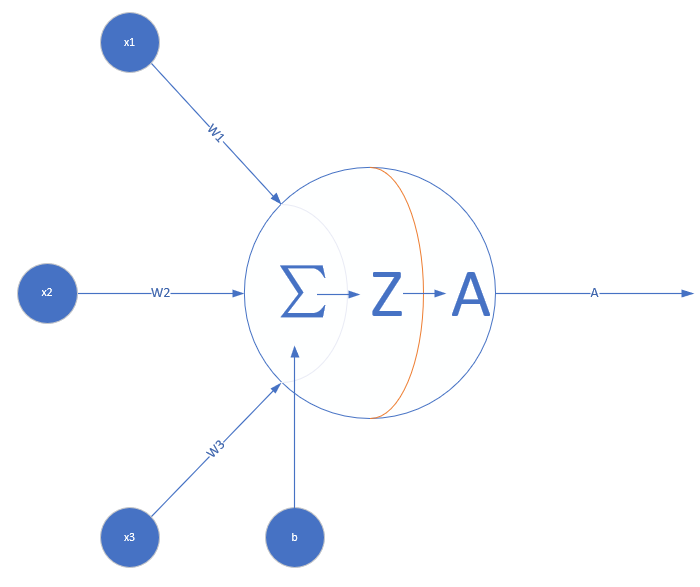
激活函数也就是\(A=\sigma(Z)\)这一步了,他有什么作用呢?
- 从模仿人类大脑的角度来说:
神经元在利用突触传递信息时,不是所有信息都可以传递下去的,每个神经元有自己的阈值,必须要刺激强过某个阈值才会继续向后传递。激活函数在某些方面就可以扮演这样一个激活阈值的作用,不达到一定要求的信号是不可以继续向后传递的
- 说得形象一点,
假设老张家有一个在滴(漏)水的水龙头:水龙头漏水这件事情的严重等级有0~9这样10个的等级,凭借自己的力量可以解决0~2这样3的等级的情况,维修部门可以解决3~6这样的等级,然后譬如需要修改水管线路什么的就是需要更加专业的部门了,他们可以解决7~9这样等级的情况。发现一个等级为5的漏水事件,处理步骤是什么样的呢?
首先,看到水龙头在滴水,通过视觉细胞处理成信号输入大脑,经过大脑这个黑盒子复杂的处理,判断出这不是简简单单拧紧或者拍拍就能解决的漏水的问题,也就是说,判断出这个事情的严重等级大于2,执行这样一个处理函数:
if 严重等级 > 2: 老张打电话给隔壁老王寻求帮助 else: 自己解决
这件事情的严重等级超过了自己能力的阈值,所以需要开始传递给隔壁老王,之后老王执行一个类似的判断
if 严重等级 > 6: 寻求物业公司帮助 else: 老王拿着管钳去老张家帮忙
类似这个例子中的判断需不需要更专业的人来解决问题,如果严重等级超过了某个设定的阈值,那就需要寻找更专业的人来帮助。在这里的阈值就是能解决的严重等级的上限。
激活函数在神经网络中起到的就是在控制自己接收到的消息到底是不是需要向后传播的作用。
- 从数学的角度来说
形如\(z=\sum\limits_{i}w_ix_i+b_i\)的传递是一种线性的传递过程。如果没有非线性函数添加非线性,直接把很多层叠加在一起会怎么样呢?
以两层为例:
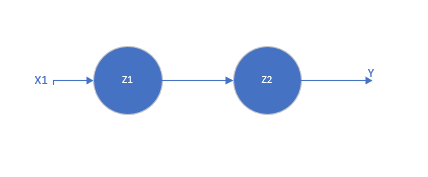
\[z_1 = w_1x_1 + b_1 \tag{1}\]
\[z_2 = w_2z_1 + b_2 = w_2(w_1x_1 + b_1) + b_2 = (w_2 w_1) x_1 + (w_2b_1 + b_2)=w_{3}x_1+b_{3} \tag{2}\]
\(z_1, z_2\)即为这两个神经元结点的输出。可以看到,叠加后的\(z_2\)的输出也是一个线性函数。
以此类推,如果缺少非线性层,无论如何叠加,最后得到的还只是一个线性函数。
然而,按照生活经验来说,大多数的事情都不是线性规律变化的,比如身高随着年龄的变化,价格随着市场的变化。所以需要给这样一个线性传递过程添加非线性才可以更好的去模拟这样一个真实的世界。具体该怎么做呢?
习惯上,用‘1’来代表一个神经元被激活,‘0’代表一个神经元未被激活,那预期的函数图像是这个样子的:
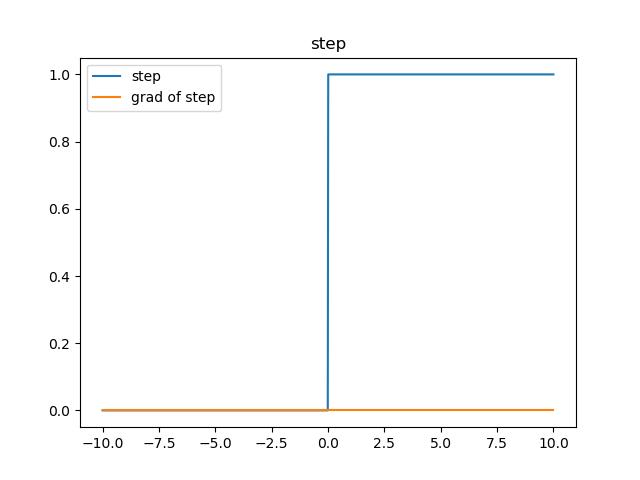
这个函数有什么不好的地方呢?主要的一点就是,他的梯度(导数)恒为零(个别点除外)。
想想我们说过的反向传播公式?梯度传递用到了链式法则,如果在这样一个连乘的式子其中有一项是零,结果会怎么样呢?这样的梯度就会恒为零。这个样子的函数是没有办法进行反向传播的。
那有没有什么函数可以近似实现这样子的阶梯效果而且还可以反向传播呢?常用的激活函数有哪些呢?
sigmoid函数
公式:\(f(z) = \frac{1}{1 + e^{-z}}\)
反向传播: \(f^{'}(z) = f(z) * (1 - f(z))\),推导过程请参看数学导数公式。
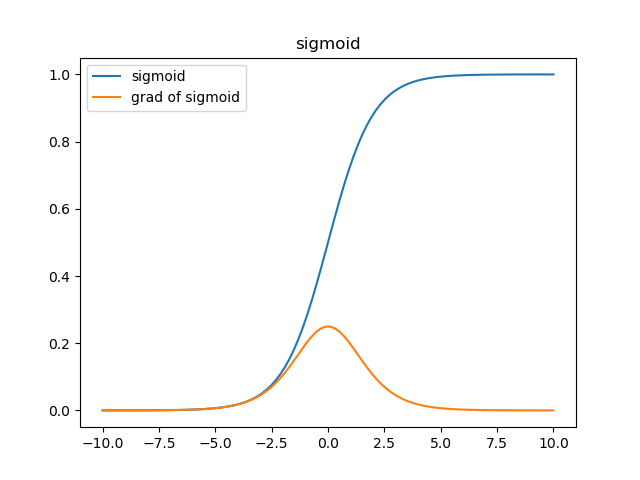
从函数图像来看,sigmoid函数的作用是将输入限制到(0, 1)这个区间范围内,这种输出在0~1之间的函数可以用来模拟一些概率分布的情况。他还是一个连续函数,导数简单易求。
用mnist数据的例子来通俗的解释一下:
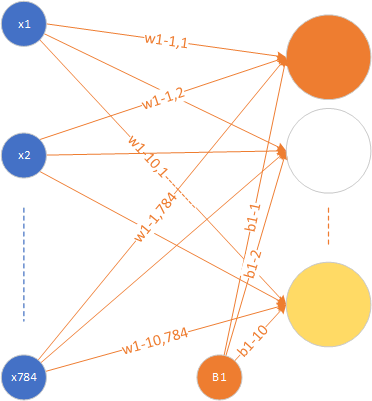
形象化的说,每一个隐藏层神经元代表了对某个笔画的感知,也就是说可能第一个神经元代表是否从图中检测到有一条像1一样的竖线存在,第二个神经元代表是否有一小段曲线的存在。但是在实际传播中,怎么表示是不是有这样一条直线或者这样一段曲线存在呢?在生活中,我们经常听到这样的对白“你觉得这件事情成功概率有多大?”“我有六成把握能成功”。sigmoid函数在这里就起到了如何把一个数值转化成一个通俗意义上的把握的表示。值越大,那么这个神经元对于这张图里有这样一条线段的把握就越大,经过sigmoid函数之后的结果就越接近100%,也就是1这样一个值,表现在图里,也就是这个神经元越兴奋(亮)。
但是这个样子的激活函数有什么问题呢?
从梯度图像中可以看到,sigmoid的梯度在两端都会接近于0,根据链式法则,把其他项作为\(\alpha\),那么梯度传递函数是\(\alpha*\sigma'(x)\),而\(\sigma'(x)\)这时是零,也就是说整体的梯度是零。这也就很容易出现梯度消失的问题,并且这个问题可能导致网络收敛速度比较慢,比如采取MSE作为损失函数算法时。
给个纯粹数学的例子吧,假定我们的学习速率是0.2,sigmoid函数值是0.9,如果我们想把这个函数的值降到0.5,需要经过多少步呢?
我们先来做公式推导,
第一步,求出当前输入的值
\[\frac{1}{1 + e^{-x}} = 0.9\]
\[e^{-x} = \frac{1}{9}\]
\[x = ln{9}\]
第二步,求出当前梯度
\[grad = f(x)\times(1 - f(x)) = 0.9 \times 0.1= 0.09\]
第三步,根据梯度更新当前输入值
\[x_{new} = x - \eta \times grad = ln{9} - 0.2 \times 0.09 = ln(9) - 0.018\]
第四步,判断当前函数值是否接近0.5
\[\frac{1}{1 + e^{-x_{new}}} = 0.898368\]
第五步,重复步骤2-3直到当前函数值接近0.5
说得如果不够直观,那我们来看看图,
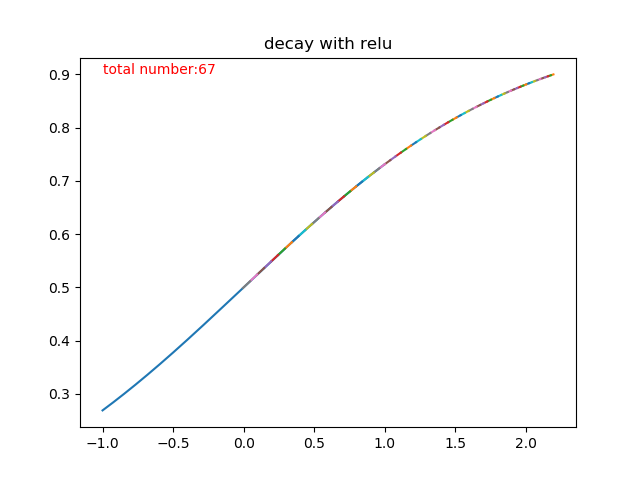
上半部分那条五彩斑斓的曲线就是迭代更新的过程了,一共迭代了多少次呢?根据程序统计,sigmoid迭代了67次才从0.9衰减到了接近0.5的水准。有同学可能会说了,才67次嘛,这个次数也不是很多啊!确实,从1层来看,这个速度还是可以接受的,但是神经网络只有这一层吗?多层叠加之后的sigmoid函数,因为反向传播的链式法则,两层的梯度相乘,每次更新的步长更小,需要的次数更多,也就是速度更加慢。如果还是没有反应过来的同学呢,可以先向下看relu函数的收敛速度。
此外,如果输入数据是(-1, 1)范围内的均匀分布的数据会导致什么样的结果呢?经过sigmoid函数处理之后这些数据的均值就从0变到了0.5,导致了均值的漂移,在很多应用中,这个性质是不好的。
代码思路:
放到代码中应该怎么实现呢?首先,对于一个输入进sigmoid函数的向量来说,函数的输出和反向传播时的导数是和输入的具体数值有关系的,那么为了节省计算量,可以生成一个和输入向量同尺寸的mask,用于记录前向和反向传播的结果,具体代码来说,就是:
示例代码:
class Csigmoid(object):
def __init__(self, inputSize):
self.shape = inputSize
def forward(self, image):
# 记录前向传播结果
self.mask = 1 / (1 + np.exp(-1 * image))
return self.mask
def gradient(self, preError):
# 生成反向传播对应位置的梯度
self.mask = np.multiply(self.mask, 1 - self.mask)
return np.multiply(preError, self.mask)不理解为啥又有前向传播又有梯度计算的小伙伴请戳这里
tanh函数
形式:
\(f(z) = \frac{e^{z} - e^{-z}}{e^{z} + e^{-z}}\)
\(f(z) = 2*sigmoid(2*z) - 1\)
反向传播:
\(f^{'}(z) = (1 + f(z)) * (1 - f(z))\)
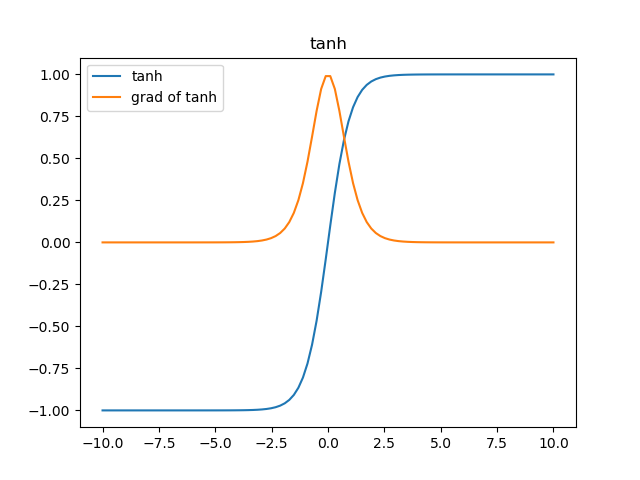
无论从理论公式还是函数图像,这个函数都是一个和sigmoid非常相像的激活函数,他们的性质也确实如此。但是比起sigmoid,tanh减少了一个缺点,就是他本身是零均值的,也就是说,在传递过程中,输入数据的均值并不会发生改变,这就使他在很多应用中能表现出比sigmoid优异一些的效果。
代码思路:
这么相似的函数没有相似的代码说不过去呀!比起sigmoid的代码,实现tanh只需要改变几个微小的地方就可以了,话不多说,直接上代码吧:
示例代码:
class Ctanh(object):
def __init__(self, inputSize):
self.shape = inputSize
def forward(self, image):
# 记录前向传播结果
self.mask = 2 / (1 + np.exp(-2 * image)) - 1
return self.mask
def gradient(self, preError):
# 生成反向传播对应位置的梯度
self.mask = np.multiply(1 + self.mask, 1 - self.mask)
return np.multiply(preError, self.mask)relu函数
形式:
\[f(z) = \begin{cases} z & z \geq 0 \\ 0 & z < 0 \end{cases}\]
反向传播:
\[f(z) = \begin{cases} 1 & z \geq 0 \\ 0 & z < 0 \end{cases}\]
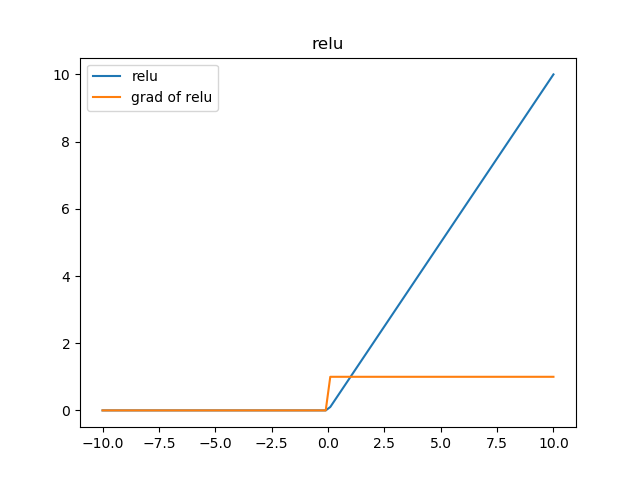
先来说说神经学方面的解释,为什么要使用relu呢?要说模仿神经元,sigmoid不是更好吗?这就要看2001年神经学家模拟出的更精确的神经元模型Deep Sparse Rectifier Neural Networks。简单说来,结论就是这样两幅图:
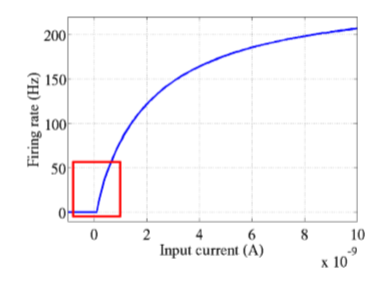
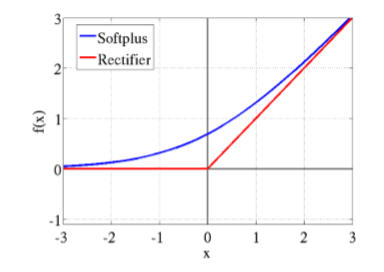
下面来解释函数图像:在输入的信号比0大的情况下,直接将信号输出,否则的话将信号抑制到0,相比较于上面两个激活函数,relu计算方面的开销非常小,避免了指数运算和除法运算。此外,很多实验验证了采用relu函数作为激活函数,网络收敛的速度可以更快。至于收敛更加快的原因,从图上的梯度计算可以看出,relu的反向传播梯度恒定是1,而sigmoid激活函数中大多数时间梯度是比1小的。在叠加很多层之后,由于链式法则的乘法特性,sigmoid作为梯度函数会不断减小反向传播的梯度,而relu可以将比梯度原样传递,也就是说,relu可以使用比较快的速度去进行参数更新。
用和sigmoid函数那里更新相似的算法步骤和参数,来模拟一下relu的梯度下降次数,也就是学习率\(\alpha = 0.2\),希望函数值从0.9衰减到0.5,这样需要多少步呢?
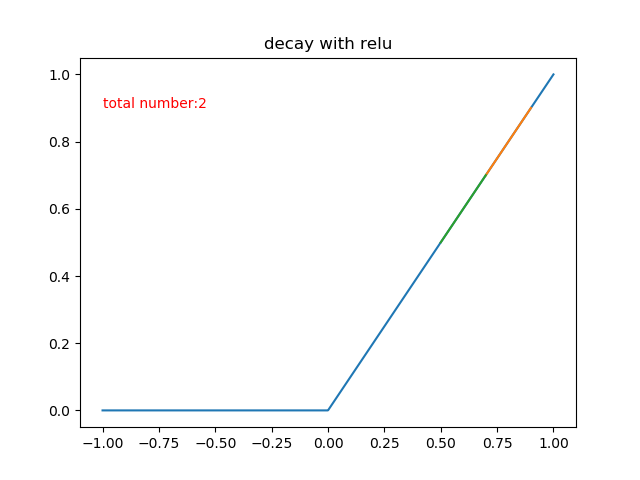
也就是说,同样的学习速率,relu函数只需要两步就可以做到sigmoid需要67步才能衰减到的程度!
但是如果回传了一个很大的梯度导致网络更新之后输入信号小于0了呢?那么这个神经元之后接受到的数据是零,对应新的回传的梯度也是零,这个神经元将不被更新,下一次输入的信号依旧小于零,不停重复这个过程。也就是说,这个神经元不会继续更新了,这个神经元“死”掉了。在学习率设置不恰当的情况下,很有可能网络中大部分神经元“死”掉,也就是说不起作用了,而这是不可取的。
代码实现:
与sigmoid类似,relu函数的前向传播和反向传播与输入的大小有关系,小于0的输入可以被简单的置成0,不小于0的可以继续向下传播,也就是将输入和0中较大的值继续传播,对输入向量逐元素做比较即可。考虑到反向传播时梯度计算也和输入有关,使用一个mask对数据或者根据数据推出的反向传播结果做一个记录也是一个比较好的选择。
示例代码:
class Crelu(object):
def __init__(self, inputSize):
self.shape = inputSize
def forward(self, image):
# 用于记录传递的结果
self.mask = np.zeros(self.shape)
self.mask[image > 0] = 1
# 将小于0的项截止到0
return np.maximum(image, 0)
def gradient(self, preError):
# 将上一层传递的误差函数和该层各位置的导数相乘
return np.multiply(preError, self.mask)想想看,relu函数的缺点是什么呢?是梯度很大的时候可能导致的神经元“死”掉。而这个死掉的原因是什么呢?是因为很大的梯度导致更新之后的网络传递过来的输入是小于零的,从而导致relu的输出是0,计算所得的梯度是零,然后对应的神经元不更新,从而使relu输出恒为零,对应的神经元恒定不更新,等于这个relu失去了作为一个激活函数的梦想。问题的关键点就在于输入小于零时,relu回传的梯度是零,从而导致了后面的不更新。
那么最简单粗暴的做法是什么?在输入函数值小于零的时候给他一个梯度不就好了!这就是leaky relu函数的表现形式了!
leaky relu函数
形式:
\[f(z) = \begin{cases} z & z \geq 0 \\ \alpha * z & z < 0 \end{cases}\]
反向传播:
\[f(z) = \begin{cases} z & 1 \geq 0 \\ \alpha & z < 0 \end{cases}\]
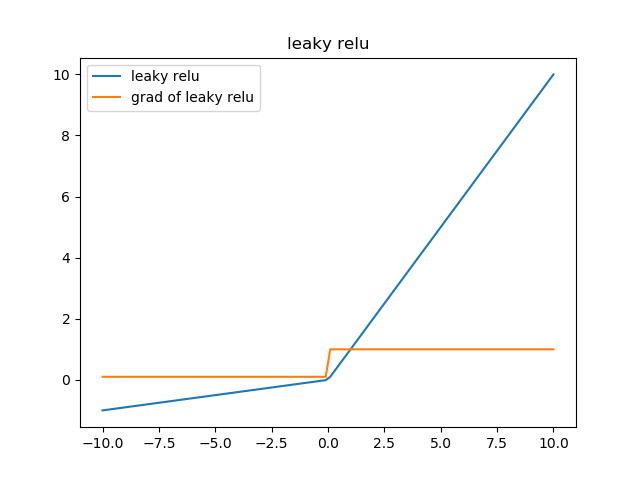
相比较于relu函数,leaky relu同样有收敛快速和运算复杂度低的优点,而且由于给了\(x<0\)时一个比较小的梯度\(\alpha\),使得\(x<0\)时依旧可以进行梯度传递和更新,可以在一定程度上避免神经元“死”掉的问题。
示例代码:
class CleakyRelu(object):
def __init__(self, inputSize, alpha):
self.shape = inputSize
self.alpha = alpha
def forward(self, image):
# 用于记录传递的结果,按照传递公式生成对应的值
self.mask = np.zeros(self.shape)
self.mask[image > 0] = 1
self.mask[image <= 0] = self.alpha
# 将该值对应到输入中
return np.multiply(image, self.mask)
def gradient(self, preError):
# 将上一层传递的误差函数和该层各位置的导数相乘
return np.multiply(preError, self.mask)softmax 函数
softmax函数,是大名鼎鼎的在计算多分类问题时常使用的一个函数,他长成这个样子:
\[ \phi(z_j) = \frac{e^{z_j}}{\sum\limits_ie^{z_i}} \]
也就是说把接收到的输入归一化成一个每个分量都在\((0,1)\)之间并且总和为一的一个概率函数。
用一张图来形象说明这个过程
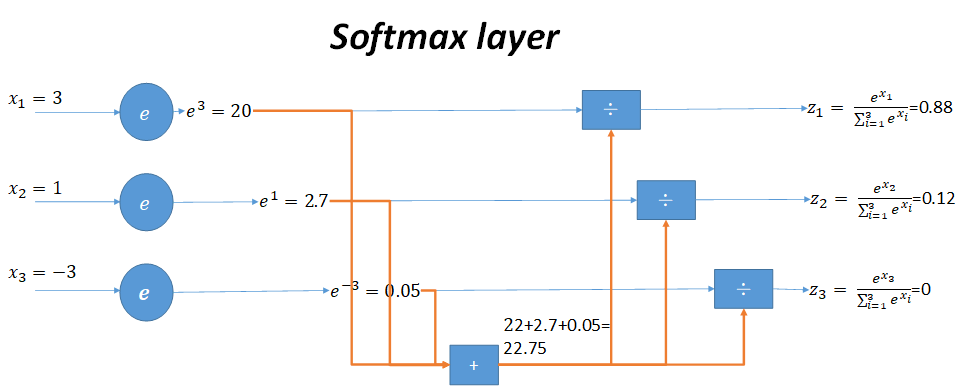
当输入的数据是3,1,-3时,按照图示过程进行计算,可以得出输出的概率分布是0.88,0.12,0。
试想如果我们并没有这样一个softmax的过程而是直接根据3,1,-3这样的输出,而我们期望得结果是1,0,0这样的概率分布结果,那传递给网络的信息是什么呢?我们要抑制正样本的输出,同时要抑制负样本的输出。正样本的输出和期望的差距是2,负样本1和期望的差距是0,所以网络要更加抑制正样本的结果!所以,在输出结果相对而言已经比较理想的情况下,我们给了网络一个相对错误的更新方向:更多的抑制正样本的输出结果。这显然是不可取的呀!
从继承关系的角度来说,softmax函数可以视作sigmoid的一个扩展,比如我们来看一个二分类问题,
\[ \phi(z_1) = \frac{e^{z_1}}{e^{z_1} + e^{z_2}} = \frac{1}{1 + e^{z_2 - z_1}} = \frac{1}{1 + e^{z_2} e^{- z_1}} \]
是不是和sigmoid的函数形式非常像?比起原始的sigmoid函数,softmax的一个优势是可以用在多分类的问题中。另一个好处是在计算概率的时候更符合一般意义上我们认知的概率分布,体现出物体属于各个类别相对的概率大小。
既然采用了这个函数,那么怎么计算它的反向传播呢?
这里为了方便起见,将\(\sum\limits_{i \neq j}e^{z_i}\)记作\(k\),那么,
\[ \phi(z_j) = \frac{e^{z_j}}{\sum\limits_ie^{z_i}} = \frac{e^{z_j}}{k + e^{z_j}} \]
\[ \therefore \frac{\partial\phi(z_j)}{\partial z_j} = \frac{e^{z_j}(k + e^{z_j}) - e^{z_j} * e^{z_j}}{{(k + e^{z_j})}^2} = \frac{e^{z_j}}{k + e^{z_j}}\frac{k}{k + e^{z_j}} = softmax(z_j)(1 - softmax(z_j)) \]
也就是说,softmax的梯度就是\(softmax(z_j)(1 - softmax(z_j))\),之后将这个梯度进行反向传播就可以大功告成啦~
本系列博客链接:
- 神经网络的基本工作原理
- 神经网络中反向传播与梯度下降的基本概念
- 损失函数
- 激活函数
- 线性回归来理解神经网络训练过程
- 徒手搭建神经网络
- 徒手搭建CNN网络
- 徒手搭建RNN网络
- 模型内部
- 附录:基本数学导数公式