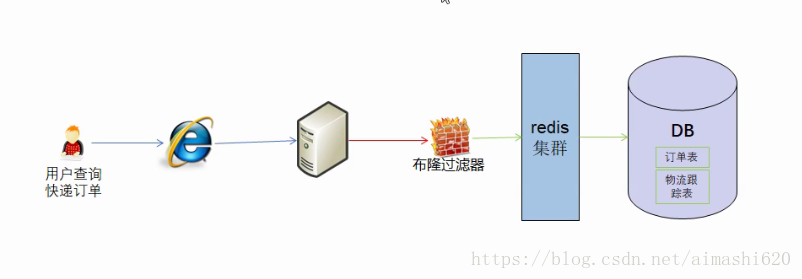
一、问题由来
首先说一下处理场景,圆通2017年全年营收199.82亿,2017年全年业务完成量为50.64亿件,这里的每一件快递都对应了1个快递单号以及详细的物流信息,假如1个快递单号就对应有10条物流信息,那么单单是这物流信息就有500多亿条,这个数据量是巨大的,那么如果从这些海量的数据中查找一条订单信息呢。”
50亿的订单号大概是多少G的数据呢?单单订单号
订单号字符串:889795292077396186—->18个字节 * 10亿 =90G
如果用Map去存储的话就需要 90 * 2 = 180G //因为Map的有效存储空间为50%
二、初步解决方案
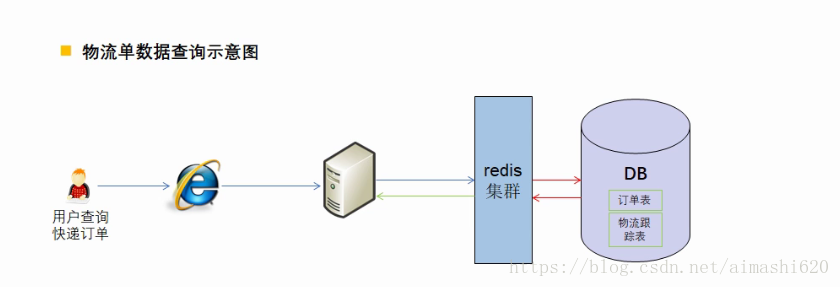
初步解决方案是在我们的应用与数据库之间加上一个redis集群,从原本的应用直接访问数据库去查询数据,到现在的先在缓存中查找,要是在缓存中查找不到再去数据库中查找,这样数据库的吞吐量和并发量将至少提高100倍以上。我们可以把“仍未确定收货”或者“某个时间截点之后(热度高)”的订单信息保存在redis集群中,把那些时间久远的订单存放在数据库中(因为那些时间久远的物流信息用户一般很少会再做查询),而redis的存储是把数据存在内存中的,它的查询是走内存的,查询效率较高,查询数据库是要走io的,所以较慢。因此可以把“仍未确定收货”这类查询的可能性以及频率较高的订单数据存在redis中。当从redis中查找不到再去数据库中查找。
对这种初步解决方案提出的思考(数据库与缓存之间的信息同步这篇文章先不讨论):假如有恶意用户通过我们提供的订单查询接口,查询一些根本就不存在的订单号,因为订单号是不存在的,所以在redis缓存中自然是找不到,那么最终还是到数据库中去查找(这就是所谓的缓存穿透)。当恶意用户通过线程或脚本等方式频繁去访问我们的数据库,而进行的查询有是在这种海量数据中进行查找,那么无疑是会占用大量的数据库连接数,最终导致其他用户访问报错,超过了数据库的最大连接数。
初步解决方案的优化思路: 在redis之前加一层过滤,先在海量订单号中快速判断是否存在该订单号,如果存在再去redis中查找,如果redis中找不到就去数据库中查找
那么怎样快速判断一个数据是否存在于海量数据中呢?

在“布隆过滤器”的简介中最后由一句话“它实际上是一个很长的二进制向量和一系列随机映射函数”,这句话有两个关键词“二进制向量”和“一系列随机函数”,大家先记住这两个词,以下将跟大家从源码的角度分析一下布隆过滤器的实现原理。
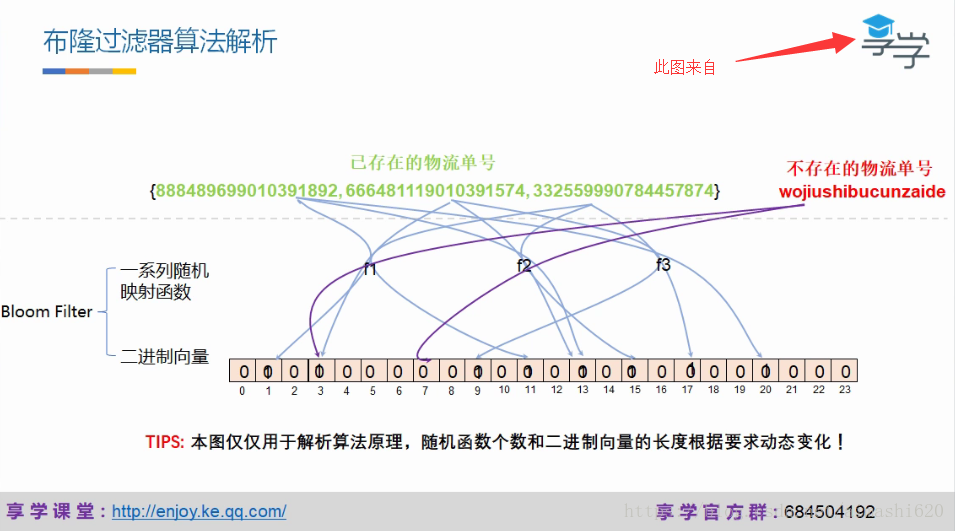
这个图的意思是,使用布隆过滤器,它会把你要存的数据(上图已存在的三个物流单行),每个物流单号分别调用三个随机映射函数,经过随机映射函数中的算法计算从而转化成二进制向量来保存(把0改成1)。查询数据存不存在该布隆过滤器中的原理是:同样依次调用这几个随机映射函数,当调用到其中的某一个函数转化成二进制时,如果发现为0,则为不存在,不一定要把全部映射函数都执行完才能得出结论。
对布隆过滤器的思考:上图的二进制向量的长度位24,那么当数据量不是3个物流单号,而是海量数据时,那么二进制向量上的岂不是全是1?这就是布隆过滤器存在误判的根本原因。
①
<!--guava框架实现了布隆过滤器,注意的是18.0版本以上才提供了布隆过滤器-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>18.0</version>
</dependency>②
③
import java.nio.charset.Charset;
/**
* @auther xiehuaxin
* @create 2018-08-14 18:18
* @todo
*/
public class Test {
public static void main(String[] args) {
int insertions = 1000000;
//建立一个用于存放字符串类型数据的布隆过滤器,初始化大小100w,误判率是0.01
BloomFilter bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charsets.UTF_8),insertions,0.01);
//往布隆过滤器中添加数据
bloomFilter.put("data11111");
//判断布隆过滤器中是否存在字符串“ABC”
if(bloomFilter.mightContain("data11111")) {
System.out.println("The bloomFilter is contain this data.");
}else {
System.out.println("The bloomFilter is not contain 'ABC'");
}
}
}优化后的解决方案
布隆过滤器里查找不到的数据那肯定是不存在的,布隆过滤器存在的数据也不一定存在,因为它有误判率