C66 代码优化基本介绍
C6000系列处理器的闪光之处就是它可以通过循环提高运行速度。这在以循环为中心的数字信号处理、图像处理和其他数学程序方面有着非常明显的优势。“软件流水”的技术对提高循环代码的性能做出的贡献最大。软件流水只有在使用-o2 或 -o3 编译选项时,才会被启用。
如下图示,如果不使用软件流水,循环就会在循环体 i 完成后再开始循环体 i+1。软件流水技术允许循环体出现重叠。因此,只要能够保持正确性,即可在循环体 i 完成之前开始循环体 i+1。在通常情况下,使用软件流水调度技术与不使用软件流水调度技术相比,使用时计算机资源利用率会高很多。
在软件流水循环中,即便一个循环体可能需要 s 个周期才能完成,但每隔 ii 个指令周期会启动一个新的循环。在一个高效的软件流水循环中,其中 ii<s,ii 被称为“启动间隔”;它是启动循环体 i 和启动循环体 i+1 之间的指令周期数。ii 等于软件流水循环体的指令周期数。s 是第一个循环体完成所需要的指令周期数,也是软件流水循环的“单个已调度的循环体”的长度。
如下图所示,即为进行了 software pipeline 和没有进行 software pipeline软件流水的对比
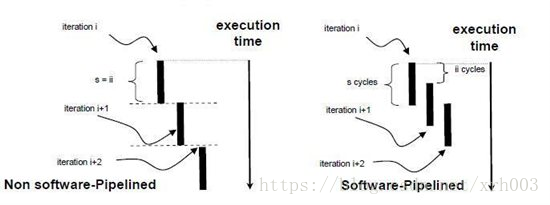
所以我们进行循环优化的目的就是减少ii,进而降低整体循环执行时间。
我们使用建议的选项进行编译:-k-s -mw 。得到汇编文件和软件流水信息
假定有以下函数 BasicLoop() ...
void BasicLoop(int*output,int*input1,int*input2,int n)
{
int i;
for(i=0; i<n; i++)
output[i]= input1[i]+ input2[i];
}
打开汇编文件并查看此循环的软件流水信息:
;* SOFTWARE PIPELINE INFORMATION
;*
;* Loop source line : 5
;* Loop opening brace source line : 5
;* Loop closing brace source line : 6
;* Known Minimum Trip Count : 1
;* Known Max Trip Count Factor : 1
;* Loop Carried Dependency Bound(^) : 7
;* Unpartitioned Resource Bound : 2
;* Partitioned Resource Bound(*) : 2
;* Resource Partition:
;* A-side B-side
;* .L units 0 0
;* .S units 0 1
;* .D units 2* 1
;* .M units 0 0
;* .X cross paths 1 0
;* .T address paths 2* 1
;* Long read paths 0 0
;* Long write paths 0 0
;* Logical ops (.LS) 0 0 (.L or .S unit)
;* Addition ops (.LSD) 1 0 (.L or .S or .D unit)
;* Bound(.L .S .LS) 0 1
;* Bound(.L .S .D .LS .LSD) 1 1
;*
;* Searching for software pipeline scheduleat ...
;* ii = 7 Schedule found with 1 iterations in parallel
...
;* SINGLE SCHEDULED ITERATION
;*
;* C25:
;* 0 LDW .D1T1 *A4++,A3 ; |6| ^
;* || LDW .D2T2 *B4++,B5 ; |6| ^
;* 1 [ B0] BDEC .S2 C24,B0 ; |5|
;* 2 NOP 3
;* 5 ADD .L1X B5,A3,A3 ; |6| ^
;* 6 STW .D1T1 A3,*A5++ ; |6| ^
;* 7 ; BRANCHCC OCCURS {C25} ; |5|
;*----------------------------------------------------------------------------*
L1: ; PD LOOP PROLOG
;** --------------------------------------------------------------------------*
L2: ; PIPED LOOP KERNEL
LDW .D1T1 *A4++,A3 ; |6|<0,0> ^
|| LDW .D2T2 *B4++,B5 ; |6| <0,0> ^
[ B0] BDEC .S2 L2,B0 ; |5| <0,1>
NOP 3
ADD .L1X B5,A3,A3 ; |6|<0,5> ^
STW .D1T1 A3,*A5++ ; |6|<0,6> ^
;**--------------------------------------------------------------------------*
L3: ; PIPED LOOP EPILOG
;**--------------------------------------------------------------------------*
软件流水循环信息包括循环开始的源代码行、对循环资源和延迟要求的描述以及循环是否已展开(还有其他信息)。使用 -mw 编译时,该信息还包含单个已调度循环体的副本。C6000Programmer's Guide(C6000 程序员指南)的第 4 章详细介绍了 -mw注释块。尽管此信息不是最新的,但是在编写本文时它是可以获得的最好信息。
启动间隔 (ii) 为 7。这意味着在稳定状态,每 7 个 CPU 周期计算出一次结果(相当于原始循环)。因此,基准 CPU 性能为 7 个指令周期/结果。
通过分析该软件流水信息我们就可以找到影响ii大小的瓶颈所在
此处为Loop Carried Dependency Bound(^) : 7,即循环体的相关性限制为7
消除循环体间的相关性
再看一下汇编文件中的软件流水信息。瓶颈在哪里?要找出瓶颈,必须理解编译器是如何计算循环指令周期数的下限的。此下限是“循环体间的相关性限制”和“资源限制”的最大者。循环体间的相关性的区间值是以汇编指令间的执行顺序为基础的。例如,必须完成两个 load 指令后才能继续执行 add 指令。资源限制则是基于硬件资源,例如需要的每种指定类型的功能单元的数量。实际上,有以下两种资源限制:已划分和未划分。在本例中,这两者相同。
在本例中,已划分资源限制为 2。即使可以不按顺序执行汇编指令,执行循环体中的所有指令也至少需要2个周期。但是,循环体间的相关性限制为 7。
;* Loop Carried DependencyBound(^) : 7
;* Unpartitioned ResourceBound : 2
;* Partitioned ResourceBound(*) : 2
因此,ii ≥ max(2,7)。要减小 ii,进而减少指令周期数/结果,必须减小循环体间相关性限制。
循环体间相关性限制之所以增大,是因为在指令的数据相关图中有一个环。最大环的长度为循环体间相关性限制。为了减少或消除循环体间相关性,必须找到这个环并找出缩短或消除它的方法。
要确定最大循环体间相关性,请参阅单个循环体中的指令。关键环中涉及的指令标有 (^) 号。这些指令包含两个 load 指令以及 add 指令和 store 指令。
;* SINGLE SCHEDULED ITERATION
;*
;* C25:
;* 0 LDW .D1T1 *A4++,A3 ; |6| ^
;* || LDW .D2T2 *B4++,B5 ; |6| ^
;* 1 [ B0] BDEC .S2 C24,B0 ; |5|
;* 2 NOP 3
;* 5 ADD .L1X B5,A3,A3 ; |6| ^
;* 6 STW .D1T1 A3,*A5++ ; |6| ^
;* 7 ; BRANCHCC OCCURS {C25} ; |5|
依靠这些信息以及查看指令间的相互供给关系,可以重新构建循环体间相关性的环。下图中的各节点正好是用 (^) 号表示的指令。各边(即节点对之间的箭头)表示排序约束。边上加注有从源指令和目标指令之间需要的指令周期数。在大多数情况下,结果在执行指令的指令周期末尾写入寄存器,并且可以在下一个指令周期才可使用。少数例外之一是,某些 load 指令需要 5 个周期才能使数据写入目标寄存器以供使用。

{kind=link}
在此图中,有两个关键环,每个的长度都为 7。要减少循环传递相关性限制,必须缩短或消除图中最大的环。这可通过消除环中的一条边来实现。为此,必须了解边的来源。
从 load 指令到 add 指令的边是很好理解的。load 指令的目的寄存器是 add 指令的源寄存器。load 指令需要 5 个指令周期来填充其目的寄存器。因此,只有在执行完两个 load 指令中的最后一个 load 指令并等待 5 个指令周期结束后才能执行 add 指令。
从 add 指令到 store 指令的边也是很好理解的,因为 add 指令的目的寄存器是 store 指令的源寄存器。add 指令的结果在 1 个指令周期后可供使用。因此,add 指令和 store 指令之间的边加注有数字 1。store 指令可以在紧跟着 add 指令的指令周期中执行。
从 store 指令回到 load 指令的边就没有这么明显了。怎样知道要将它们加进来?为什么它们在那里?这些问题的答案可由消除过程来确定。因为没有寄存器相关性,最有可能存在存储器相关性。在本例中,编译器不知道输入数组是否会引用与输出数组相同的内存位置,因此保守起见就假定这是有可能的。从 store 指令到 load 指令的边可确保先执行一个循环体中的 store 指令再执行下一个循环体中的 load 指令,以便当这些 load 指令尝试读取由 store 指令写入的数据时也是正确的。实际上是否发生这种情况取决于运行时“input1”、“input2”和“output”的值。(有关数据相关性和用来表示它们的图形的更多背景知识,请参阅 Memory AliasDisambiguation on the TMS320C6000(TMS320C6000 的内存别名消除歧义)。)
在现实中,有经验的程序员通常这样编写代码,输入参数的数组和输出参数的数组是独立的。原因是,这会使算法更加并行,从而带来更好的性能。假定在所有调用点,“input1”或“input2”都不会访问与“output”相同的内存地址。将此信息告知编译器,从 store 指令到 load 指令的返回边将会消失。这可通过使用 -mt 选项或使用restrict 关键字来实现。
void BasicLoop(int *restrict output,
int *restrict input1,
int *restrict input2,
int n)
{
int i;
#pragma MUST_ITERATE(1)
for (i=0; i<n; i++)
output[i] = input1[i] + input2[i];
}
尽管对于本示例而言使用 restrict 关键字界定两个 load 指令或一个 store 指令就已经足够,仍然建议使用 restrict 关键字界定能够用其界定的所有参数(以及本地指针变量)。首先,这通常比确定哪些参数真的需要用 restrict 关键字来界定更迅速。其次,这可以向将来可能维护或修改此代码库的其他程序员提供信息。但是,在插入 restrict 关键字之前,请确保使用 restrict 关键字界定的指针不能与任何其他指针重叠。当编写库程序并使用 restrict 关键字时,请务必为库用户用文档说明参数限制。
在添加 restrict 关键字之后,重新变异这个函数。请注意,循环传递相关性限制已消失。这意味着每个循环体都是独立的。现在,新的循环在资源许可时立即启动。
;* Loop Carried DependencyBound(^) : 0
需进一步注意,每 2 个周期会启动一个新的循环。因此,在稳定状态下,每 2 个周期(而不是每 7 个周期)就会生成一个新结果。
;* ii = 2 Schedule found with 4 iterations in parallel.