groupby:分割,应用和组合。groupby经常只需一行代码,就可以计算每组的和,均值,计数,最小值以及其他累计值。它返回一个DataFrameGroupby对象,你可以将它看成是一个特殊的DataFrame对象,里面隐藏着若干组数据。
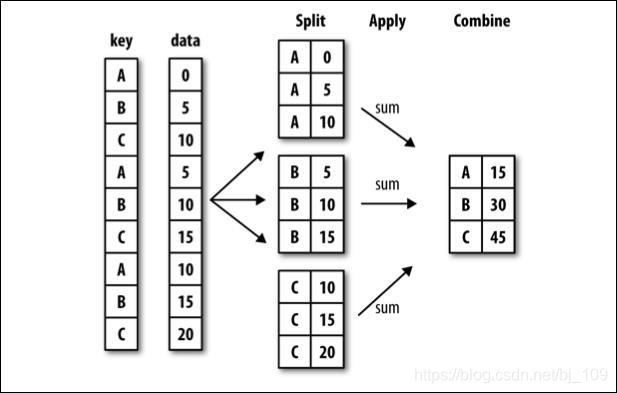
groupby的基本操作方法:
从创建DataFrame开始:
df = pd.DataFrame({'key1': ['a', 'a', 'b', 'b', 'a'],
'key2': ['one', 'two', 'one', 'two', 'one'],
'data1': np.random.randn(5),
'data2': np.random.randn(5)})
1、按列取值:Groupby对象按列取值,并返回一个修改过的Groupby对象。
df.groupby('key1')['data1'].sum()
2、按组迭代:返回的每一组都是Series或FataFrame:
for k1, k2 in df.groupby(['key1', 'key2']):
print(k1, k2)
3、调用方法:直接调用Python的一些方法,例如:
df.groupby(['key1', 'key2']).describe()
groupby最重要的操作可能就是aggregate,filter,transform,apply方法了:
1、累计aggregate。刚刚演示过例如sum的简单累计方法,但是aggregate()其实可以支持更复杂的操作。
df.groupby(['key1']).agg(['min', np.median, max])
也可以通过字典来指定不同列需要的累计函数:
df.groupby(['key1']).agg({'data1': 'min',
'data2': 'max'})
2、过滤filter。过滤的操作可以让你按照分组的属性丢弃若干数据。
def filter_func(x):
return x['data2'].std()>1
df.groupby('key1').filter(filter_func)
最后打印出来的结果是‘key1’列只有’a’了,因为’b’列的标准差小于1,所以就被过滤掉了。
3、转换transform。数据经过转换后,其形状跟原来的输入数据是一样的,例如实现数据标准化,就是将每一组的样本数据减去各组的均值;
df.groupby('key1').transform(lambda x: x - x.mean())
4、apply()方法。它可以让你在每个组上应用任意方法。下面的例子是将第一列数据已第二列的和为基数进行标准化:
def norm_by_data2(x):
x['data1'] /= x['data2'].sum()
return x
df.groupby('key1').apply(norm_by_data2)