用python爬虫scrapy框架爬取虎扑论坛的30支球队新闻
Scrapy 框架
-
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。
-
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
-
Scrapy 使用了 Twisted
['twɪstɪd](其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
制作 Scrapy 爬虫 一共需要4步:
- 新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
- 明确目标 (编写items.py):明确你想要抓取的目标
- 制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
- 存储内容 (pipelines.py):设计管道存储爬取内容
Scrapy的安装介绍
Scrapy框架官方网址:http://doc.scrapy.org/en/latest
Scrapy中文维护站点:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html
Windows 安装方式
- Python 2 / 3
- 升级pip版本:
pip install --upgrade pip - 通过pip 安装 Scrapy 框架
pip install Scrapy
一. 新建项目(scrapy startproject)
- 在开始爬取之前,必须创建一个新的Scrapy项目。进入自定义的项目目录中,运行下列命令:
scrapy startproject HupuSpider- 其中, HupuSpider为项目名称(自定义),可以看到 将会创建一个 HupuSpider文件夹,目录结构大致如下:

下面来简单介绍一下各个主要文件的作用:
scrapy.cfg :项目的配置文件
mySpider/ :项目的Python模块,将会从这里引用代码
扫描二维码关注公众号,回复: 4143152 查看本文章
mySpider/items.py :项目的目标文件
mySpider/pipelines.py :项目的管道文件
mySpider/settings.py :项目的设置文件
mySpider/spiders/ :存储爬虫代码目录
二、明确目标(mySpider/items.py)
我们打算抓取:https://voice.hupu.com/nba 网站里的30支球队新闻内容以及新闻配图。
打开mySpider目录下的items.py
Item 定义结构化数据字段,用来保存爬取到的数据,有点像Python中的dict,但是提供了一些额外的保护减少错误。
可以通过创建一个 scrapy.Item 类, 并且定义类型为 scrapy.Field的类属性来定义一个Item(可以理解成类似于ORM的映射关系)。
接下来,创建一个HupuSpiderItem类,和构建item模型(model)。
class HupuspiderItem(scrapy.Item): # 球队名称 teamname = scrapy.Field() # 球队url teamurl = scrapy.Field() # 新闻标题 newstitle=scrapy.Field() # 新闻链接 newsurl=scrapy.Field() # 新闻内容 content=scrapy.Field() # 新闻配图url imageurl=scrapy.Field()三、制作爬虫 (spiders/itcastSpider.py)
爬虫功能要分两步:
1. 爬数据
- 在当前目录下输入命令,将在
mySpider/spider目录下创建一个名为nba_news的爬虫,并指定爬取域的范围:scrapy genspider nba_news "hupu.com"
- 打开 mySpider/spider目录里的 nba_news.py,默认增加了下列代码:
import scrapy class NbaNewsSpider(scrapy.Spider): name = "nba_news" allowed_domains = ["hupu.com"] start_urls = ( 'https://www.hupu.com/', ) def parse(self, response): pass其实也可以由我们自行创建itcast.py并编写上面的代码,只不过使用命令可以免去编写固定代码的麻烦
要建立一个Spider, 你必须用scrapy.Spider类创建一个子类,并确定了三个强制的属性 和 一个方法。
name = "":这个爬虫的识别名称,必须是唯一的,在不同的爬虫必须定义不同的名字。
allow_domains = []是搜索的域名范围,也就是爬虫的约束区域,规定爬虫只爬取这个域名下的网页,不存在的URL会被忽略。
start_urls = ():爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始。其他子URL将会从这些起始URL中继承性生成。
parse(self, response):解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:
- 负责解析返回的网页数据(response.body),提取结构化数据(生成item)
- 生成需要下一页的URL请求。
将start_urls的值修改为需要爬取的第一个url
start_urls=['https://voice.hupu.com/nba/']修改parse()方法
def parse(self, response): items=[] result=response.xpath('/html/body/div[2]/div/div[3]/div[2]/div[1]/ul') # 球队队名 team=result.xpath('.//li/a/text()').extract() allteam=team[:-1] team=result.xpath('.//li[last()]/div/a/text()').extract() allteam.extend(team) # 球队url teamurl = result.xpath('.//li/a/@href').extract() allteamurl = teamurl[:-1] teamurl = result.xpath('.//li[last()]/div/a/@href').extract() allteamurl.extend(teamurl) # 爬取所有的球队 for i in range(0,len(allteam)): item = HupuspiderItem() # 指定存储目录+球队名字 teamFilename="./虎扑新闻/"+allteam[i] # 如果目录不存在,则创建目录 if (not os.path.exists(teamFilename)): os.makedirs(teamFilename) item['teamname']=allteam[i] item['teamurl']=allteamurl[i] items.append(item) #发送每个球队url的Request请求,得到Response连同包含meta数据 # 一同交给回调函数 second_parse 方法处理 for item in items: for i in range(1,2): tempurl = item['teamurl'].replace('.html','') teamurl = tempurl + '-' + str(i) + '.html' yield scrapy.Request( url = teamurl, meta={'meta_1': item}, callback=self.second_parse) # 对每支球队的url进行爬取 def second_parse(self,response): items=[] # 提取每次Response的meta数据 meta_1 = response.meta['meta_1'] # 提取每支球队的所有新闻url allurl = response.xpath('//html/body/div[3]/div[1]/div/div[@class="list"]/div/div/span/a/@href').extract() # 提取每支球队的所有新闻标题 alltitle = response.xpath('//html/body/div[3]/div[1]/div/div[@class="list"]/div/div/span/a/text()').extract() for i in range(0, len(alltitle)): item=HupuspiderItem() item['teamname'] = meta_1['teamname'] item['teamurl'] = meta_1['teamurl'] item['newstitle'] = alltitle[i] item['newsurl'] = allurl[i] items.append(item) # 指定存储目录+球队名字+新闻标题文件夹 newsFilename = "./虎扑新闻/"+item['teamname']+'/' + alltitle[i] # 如果目录不存在,则创建目录 if (not os.path.exists(newsFilename)): os.makedirs(newsFilename) # 发送每个新闻链接url的Request请求,得到Response后连同包含meta数据 # 一同交给回调函数 detail_parse 方法处理 for item in items: yield scrapy.Request(url=item['newsurl'], meta={'meta_2': item}, callback=self.detail_parse) def detail_parse(self,response): item = response.meta['meta_2'] content = "" # 提取所有p标签里的文本内容 content_list = response.xpath('//html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()').extract() # 提取配图url imageurl = response.xpath('/html/body/div[4]/div[1]/div[2]/div/div[1]/img/@src').extract() # 将p标签里的文本内容合并到一起 for content_one in content_list: content += content_one content +="\n" item['content'] = content item['imageurl'] = imageurl # 将获取的数据交给pipelines yield itemdef parse(self, response): items=[] result=response.xpath('/html/body/div[2]/div/div[3]/div[2]/div[1]/ul') # 球队队名 team=result.xpath('.//li/a/text()').extract() allteam=team[:-1] team=result.xpath('.//li[last()]/div/a/text()').extract() allteam.extend(team) # 球队url teamurl = result.xpath('.//li/a/@href').extract() allteamurl = teamurl[:-1] teamurl = result.xpath('.//li[last()]/div/a/@href').extract() allteamurl.extend(teamurl) # 爬取所有的球队 for i in range(0,len(allteam)): item = HupuspiderItem() # 指定存储目录+球队名字 teamFilename="./虎扑新闻/"+allteam[i] # 如果目录不存在,则创建目录 if (not os.path.exists(teamFilename)): os.makedirs(teamFilename) item['teamname']=allteam[i] item['teamurl']=allteamurl[i] items.append(item) #发送每个球队url的Request请求,得到Response连同包含meta数据 # 一同交给回调函数 second_parse 方法处理 for item in items: for i in range(1,2): tempurl = item['teamurl'].replace('.html','') teamurl = tempurl + '-' + str(i) + '.html' yield scrapy.Request( url = teamurl, meta={'meta_1': item}, callback=self.second_parse) # 对每支球队的url进行爬取 def second_parse(self,response): items=[] # 提取每次Response的meta数据 meta_1 = response.meta['meta_1'] # 提取每支球队的所有新闻url allurl = response.xpath('//html/body/div[3]/div[1]/div/div[@class="list"]/div/div/span/a/@href').extract() # 提取每支球队的所有新闻标题 alltitle = response.xpath('//html/body/div[3]/div[1]/div/div[@class="list"]/div/div/span/a/text()').extract() for i in range(0, len(alltitle)): item=HupuspiderItem() item['teamname'] = meta_1['teamname'] item['teamurl'] = meta_1['teamurl'] item['newstitle'] = alltitle[i] item['newsurl'] = allurl[i] items.append(item) # 指定存储目录+球队名字+新闻标题文件夹 newsFilename = "./虎扑新闻/"+item['teamname']+'/' + alltitle[i] # 如果目录不存在,则创建目录 if (not os.path.exists(newsFilename)): os.makedirs(newsFilename) # 发送每个新闻链接url的Request请求,得到Response后连同包含meta数据 # 一同交给回调函数 detail_parse 方法处理 for item in items: yield scrapy.Request(url=item['newsurl'], meta={'meta_2': item}, callback=self.detail_parse) def detail_parse(self,response): item = response.meta['meta_2'] content = "" # 提取所有p标签里的文本内容 content_list = response.xpath('//html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()').extract() # 提取配图url imageurl = response.xpath('/html/body/div[4]/div[1]/div[2]/div/div[1]/img/@src').extract() # 将p标签里的文本内容合并到一起 for content_one in content_list: content += content_one content +="\n" item['content'] = content item['imageurl'] = imageurl # 将获取的数据交给pipelines yield item2. 取数据
这个项目运用的是XPath提取数据。
result=response.xpath('/html/body/div[2]/div/div[3]/div[2]/div[1]/ul') # 球队队名 team=result.xpath('.//li/a/text()').extract() allteam=team[:-1] team=result.xpath('.//li[last()]/div/a/text()').extract() allteam.extend(team) # 球队url teamurl = result.xpath('.//li/a/@href').extract() allteamurl = teamurl[:-1] teamurl = result.xpath('.//li[last()]/div/a/@href').extract() allteamurl.extend(teamurl)result=response.xpath('/html/body/div[2]/div/div[3]/div[2]/div[1]/ul') # 球队队名 team=result.xpath('.//li/a/text()').extract() allteam=team[:-1] team=result.xpath('.//li[last()]/div/a/text()').extract() allteam.extend(team) # 球队url teamurl = result.xpath('.//li/a/@href').extract() allteamurl = teamurl[:-1] teamurl = result.xpath('.//li[last()]/div/a/@href').extract() allteamurl.extend(teamurl)
# 提取每支球队的所有新闻url allurl = response.xpath('//html/body/div[3]/div[1]/div/div[@class="list"]/div/div/span/a/@href').extract() # 提取每支球队的所有新闻标题 alltitle = response.xpath('//html/body/div[3]/div[1]/div/div[@class="list"]/div/div/span/a/text()').extract()# 提取所有p标签里的文本内容 content_list = response.xpath('//html/body/div[4]/div[1]/div[2]/div/div[2]/p/text()').extract() # 提取配图url imageurl = response.xpath('/html/body/div[4]/div[1]/div[2]/div/div[1]/img/@src').extract()
- 我们之前在mySpider/items.py 里定义了一个HupuspiderItem类。 这里引入进来
from HupuSpider.items import HupuspiderItem
- 然后将我们得到的数据封装到一个 HupuspiderItem对象中,可以保存每条新闻的属性:
item = HupuspiderItem()设置setting.py(配置参数):
BOT_NAME = 'HupuSpider' SPIDER_MODULES = ['HupuSpider.spiders'] NEWSPIDER_MODULE = 'HupuSpider.spiders' # 函数的执行顺序,序号越小,优先级越高 ITEM_PIPELINES = { 'HupuSpider.pipelines.HupuspiderPipeline': 1, 'HupuSpider.pipelines.HupuImagesPipeline':2, } LOG_LEVEL='DEBUG' ROBOTSTXT_OBEY = True # Images 的存放位置,之后会在pipelines.py里调用 IMAGES_STORE='E:/学习Python/HupuSpider/HupuSpider/虎扑新闻'Item Pipeline
当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item。
每个Item Pipeline都是实现了简单方法的Python类,比如决定此Item是丢弃而存储。以下是item pipeline的一些典型应用:
- 验证爬取的数据(检查item包含某些字段,比如说name字段)
- 查重(并丢弃)
- 将爬取结果保存到文件或者数据库中
编写pipeline.py
from scrapy.pipelines.images import ImagesPipeline from scrapy.utils.project import get_project_settings import scrapy import os class HupuspiderPipeline(object): def process_item(self, item, spider): # 新闻标题作为文件夹名字 filename = item['newstitle'] filename += ".txt" # 每条新闻放到对应的球队文件夹中 savepath='虎扑新闻'+'/'+item['teamname']+'/'+ item['newstitle'] +'/'+filename fp = open(savepath, 'w',encoding='utf-8') fp.write(item['content']) fp.close() return item class HupuImagesPipeline(ImagesPipeline): IMAGES_STORE = get_project_settings().get("IMAGES_STORE") def get_media_requests(self, item, info): image_url = item["imageurl"] yield scrapy.Request(image_url[0]) def item_completed(self, results, item, info): # 固定写法,获取图片路径,同时判断这个路径是否正确,如果正确, # 就放到 image_path里,ImagesPipeline源码剖析可见 image_path = [x["path"] for ok, x in results if ok] # 每张新闻配图放到对应的球队文件夹中 os.rename(self.IMAGES_STORE + "/" + image_path[0], self.IMAGES_STORE + "/" + item["teamname"] + "/" + item["newstitle"] + "/" + item[ "newstitle"] + ".jpg") return item #get_media_requests的作用就是为每一个图片链接生成一个Request对象, # 这个方法的输出将作为item_completed的输入中的results, # results是一个元组,每个元组包括(success, imageinfoorfailure)。 # 如果success=true,imageinfoor_failure是一个字典, # 包括url/path/checksum三个key。在项目根目录下新建main.py文件,用于调试
from scrapy import cmdline cmdline.execute('scrapy crawl douyu'.split())运行程序后会自动生成一个"虎扑新闻"文件夹
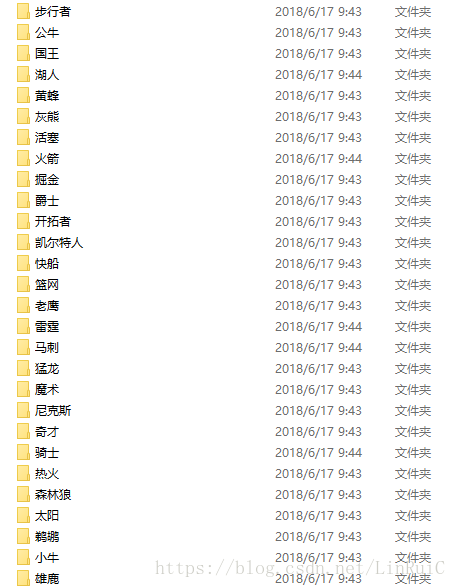
双击打开"虎扑新闻"文件夹,对nba 30支球队进行了分类
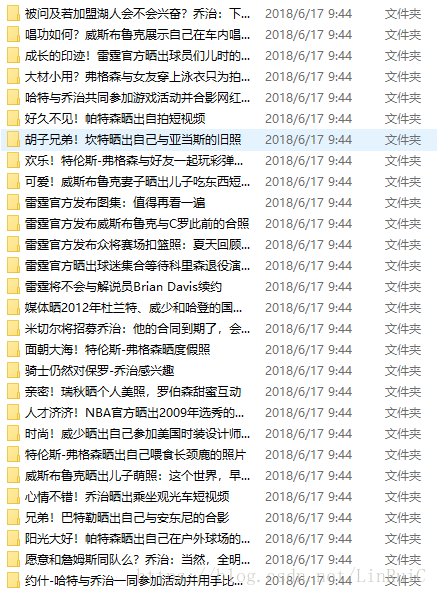
双击打开"雷霆"新闻文件夹
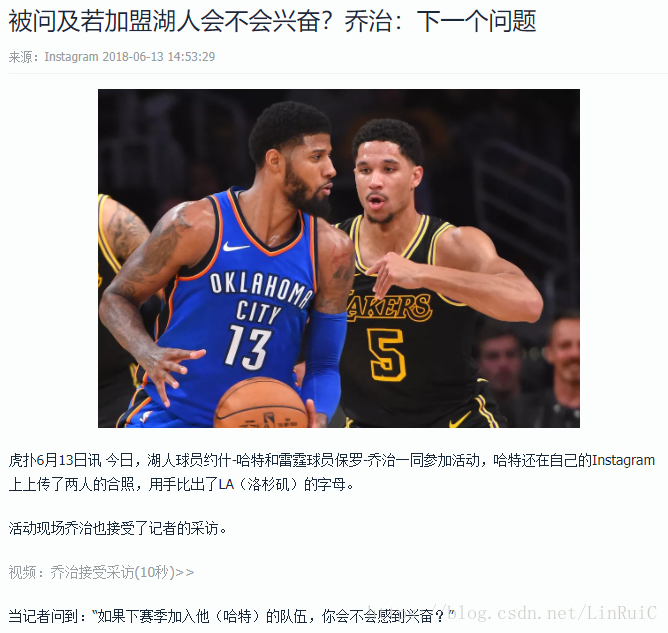
双击打开第一条新闻"被问及若加盟湖人会不会兴奋?乔治:下一个问题",文件夹里面是新闻配图和新闻内容文本
打开文本就是我们所要的新闻内容
这是从虎扑网页截取的相同新闻配图和新闻内容,我们已经完成了需求