我这里使用的是python中的requests.get(url,headers,cookies).
其中headers和cookies都是字典形式。headers作用是模拟浏览器,告诉服务器我不是爬虫。cookies作用是模拟用户,告诉服务器我不是机器人,我是某某用户。
以知乎为例,headers可以用模板:
headers = {
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding': 'gzip, deflate',
'Referer': 'http://www.baidu.com',
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
}
然后就是cookies,cookies我是先在浏览器中登录,然后去找cookie,并把内容复制到txt中,到时候爬虫直接去读取txt,并转换成字典。具体过程如下(以google浏览器为例):
1、登录知乎:http://www.zhihu.com
2、打开浏览器设置--->高级--->隐私设置和安全性-->内容设置-->cookie-->查看所有cookie和网站数据
3、搜索zhihu,得到下图
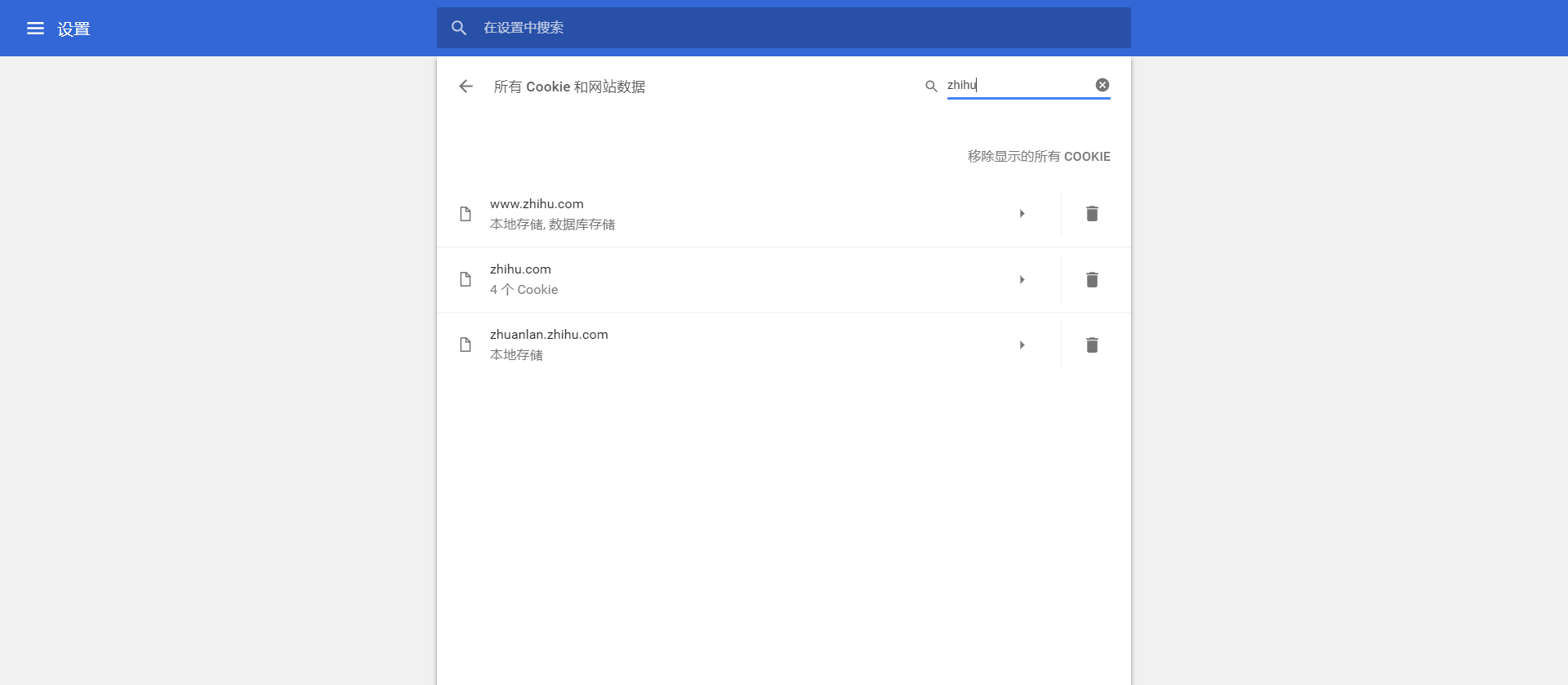
打开zhihu.com那个,如下图
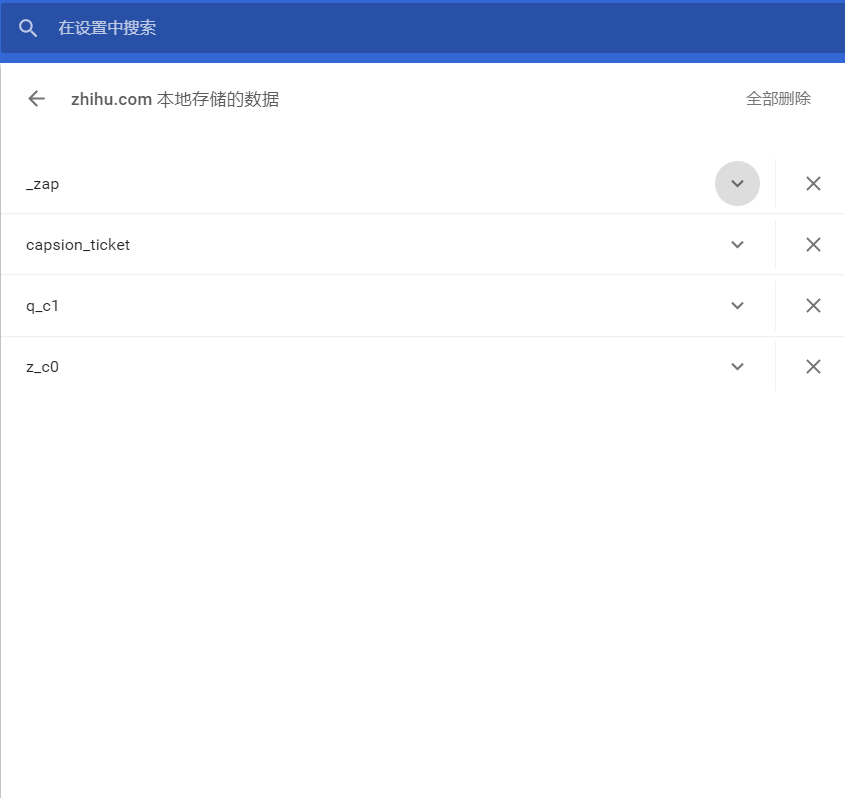
这四个就是cookie的键,打开向下的箭头里面有值,根据这个建立字典即可。(注意:有的值包含着双引号,不能搞丢了)
访问时,html=requests.get("https://www.zhihu,com",headers=headers,cookies=cookies)
content=html.text