最近在看唐宇迪机器学习视频,这个视频我觉得很不错,可是我资源有限,有的视频没有配套的资料、数据集或者是代码,但还是可以看视频了解其中的一些知识点。
项目介绍
该项目是通过员工对公司的满意程度、公司对员工的评估、员工薪资水平、员工岗位、员工工作时长等特征来推断员工是否会离职。
知识点
-
通过 df.info( ) 可以看到特征的数据类型,对于int64、float64这样的数据类型来说放入机器学习算法是没有问题的,但是对于object(可理解为str)这样的数据类型是需要进一步处理的。
eg: 在本项目中是利用pd.get_dummies()直接将其转为one-hot编码。部分代码如下:salary_dummy = pd.get_dummies(df['salary']) department_dummy = pd.get_dummies(df['depratment']) X = pd.concat([X, salary_dummy], axis = 1) X = pd.concat([X, department_dummy], axis = 1)ps: 一般来说如果离散的取值之间没有大小的意义,就用one-hot,如果离散的取值之间有大小的意义就直接映射。
-
修改DataFrame中列的名字:
df.rename(columns = {'修改前的名字':'修改后的名字'}, inplace = True) -
特征、标签之间的相关系数:
df.corr() -
柱状图表示属性与标签之间的关系:
部分代码如下:import matplotlib.pyplot as plt import seaborn as sns % matplotlib inline plot = sns.factorplot(x = 'department', y = 'left', kind = 'bar',data = df) plot.set_xticklabels(rotation = 45,horizontalalignment = 'right')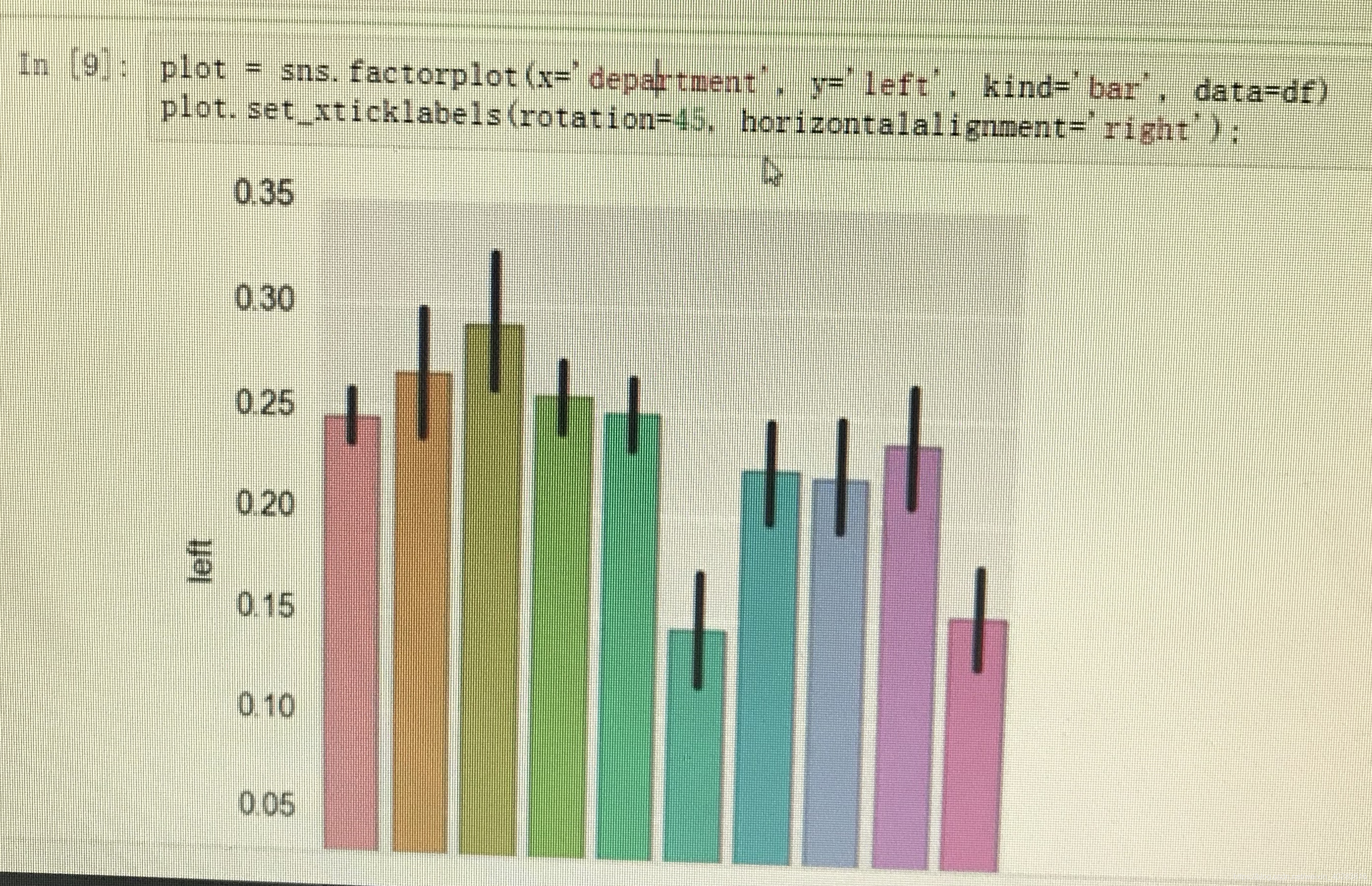
ps: sns.factorplot()默认画的是折线图,通过添加kind参数可以把折线图改柱形图。 -
饼状图表示某职位工资分布情况:
部分代码如下:df[df['department'] == 'management']['salary'].value_counts().plot(kind = 'pie', title = 'Management Salary level distribution') -
柱状图表示属性与标签之间的关系:
部分代码如下:bins = np.linspace(0.0001,1.0001,21) plt.hist(df['left'] == 1]['satisfaction_level'],bins = bins,alpha=0.7,label = 'Employees Left') plt.hist(df['left'] == 0]['satisfaction_level'],bins = bins,alpha=0.5,label = 'Employees Stayed') plt.xlabel('satisfaction_level') plt.xlim(0,1.05) plt.legend(loc = 'best')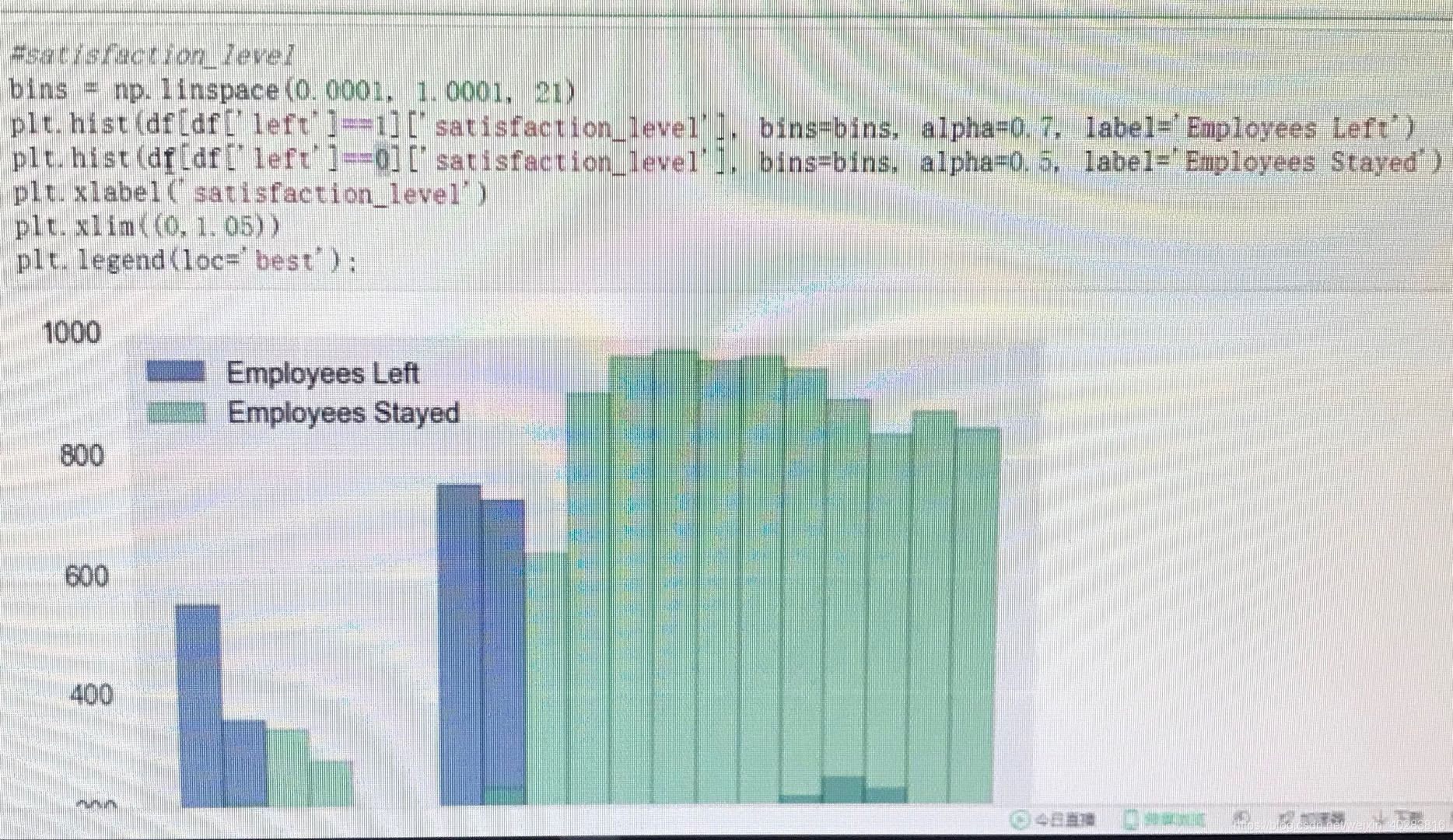
-
将训练数据划分为训练集和测试集:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.3) -
数据标准化:
数据标准化主要是排除数据大小值对分类器的干扰,这对于数据集中特征之间取值范围较大时很有意义。部分代码如下:from sklearn.preprocessing import StandardScaler stdsc = StandardScaler() X_train_std = stdsc.fit_trasform(X_train) X_test_std = stdsc.fit_trasform(X_train)ps: 它是针对每一个特征维度来做的,而不是针对样本。
-
训练集交叉验证:
from sklearn.model_selection import ShuffleSplit cv = ShuffleSplit(n_splits = 20,test_size = 0.3)