1.理解分类与监督学习、聚类与无监督学习。
有监督学习:
不仅把训练数据丢给计算机,而且还把分类的结果(数据具有的标签)也一并丢给计算机分析。
由于计算机在学习的过程中不仅有训练数据,而且有训练结果(标签),因此训练的效果通常不错。训练结束之后进行测试
计算机进行学习之后,再丢给它新的未知的数据,它也能计算出该数据导致各种结果的概率,给你一个最接近正确的结果。
聚类:
无监督学习的结果。聚类的结果将产生一组集合,集合中的对象与同集合中的对象彼此相似,与其他集合中的对象相异。
无监督学习:
只给计算机训练数据,不给结果(标签),因此计算机无法准确地知道哪些数据具有哪些标签,只能凭借强大的计算能力分析数据的特征,从而得到一定的成果,通常是得到一些集合,集合内的数据在某些特征上相同或相似。
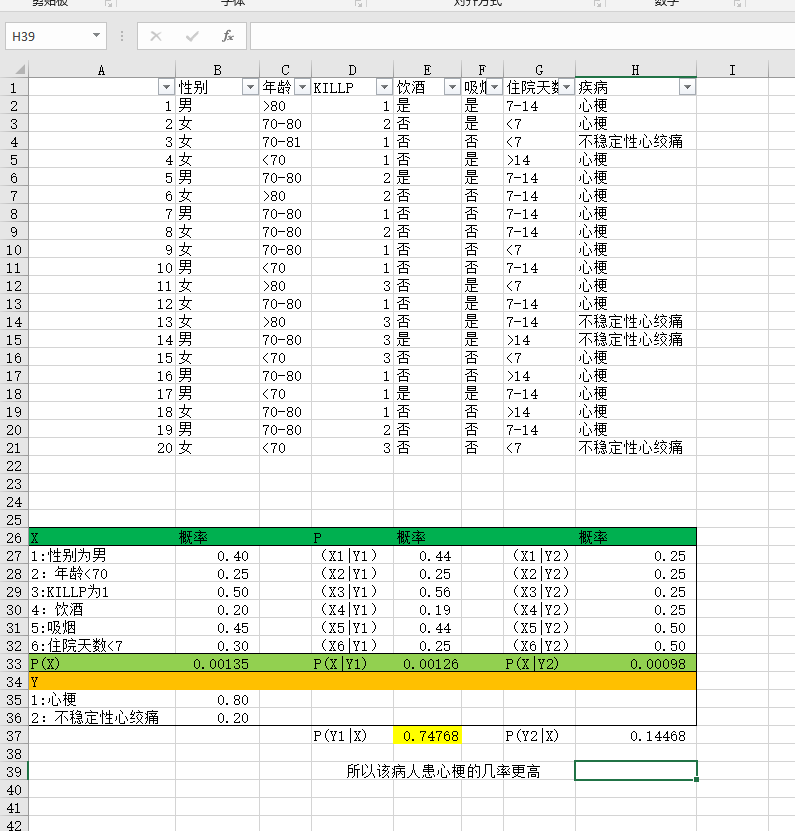
2.朴素贝叶斯分类算法 实例
利用关于心脏情患者的临床数据集,建立朴素贝叶斯分类模型。
有六个分类变量(分类因子):性别,年龄、KILLP评分、饮酒、吸烟、住院天数
目标分类变量疾病:–心梗–不稳定性心绞痛
新的实例:–(性别=‘男’,年龄<70, KILLP=‘I',饮酒=‘是’,吸烟≈‘是”,住院天数<7)
最可能是哪个疾病?
上传演算过程。
如下图所示:
3.编程实现朴素贝叶斯分类算法
利用训练数据集,建立分类模型。
输入待分类项,输出分类结果。
可以心脏情患者的临床数据为例,但要对数据预处理。
from sklearn.datasets import load_iris iris = load_iris() iris.data[55] iris.target[55] from sklearn.naive_bayes import GaussianNB gnb = GaussianNB()#模型 gnb.fit(iris.data,iris.target)#训练 gnb.predict([[5.5,2.0,4.5,1.3]])#分类