论文: Aggregated Residual Transformations for Deep Neural Networks
论文地址: https://arxiv.org/abs/1611.05431
代码地址
- Keras: https://github.com/titu1994/Keras-ResNeXt
- Pytorch: https://github.com/prlz77/ResNeXt.pytorch/tree/R4.0[推荐,用于cifar数据集]
参考博客:
1. 提出背景
作者提出ResNeXt的主要原因在于:
传统的要提高模型的准确率,都是通过 加深 或 加宽 网络,但是随着超参数数量的增加(比如 channels数,filter size等等),网络设计的难度和计算开销也会增加。
因此本文提出的 ResNeXt结构可以在不增加参数复杂度的前提下
- 提高准确率
- 减少超参数数量(得益于子模块的拓扑结构)
2. 核心思想
作者在论文中首先提到VGG,VGG采用 堆叠网络 来实现,之前的 ResNet 也借用了这样的思想。
之后提到了Inception系列网络,简单说就是 split-transform-merge 的策略,但是存在一个问题:
网络的超参数设定的针对性比较强,当应用在别的数据集上需要修改许多参数,因此可扩展性一般.
作者同时采用 VGG 的 堆叠思想 和 Inception 的 split-transform-merge 的思想,但是 可扩展性比较强. 可以认为在增加准确率的同时基本不改变或降低模型的复杂度。
这里提到一个名词
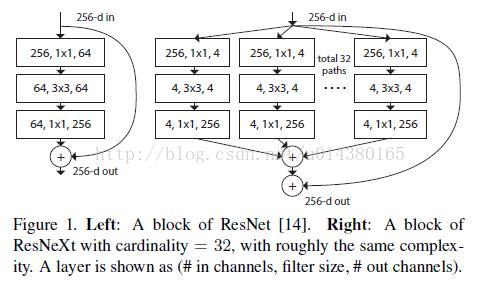
cardinality,原文的解释是 the size of the set of transformations,如下图 Fig1 右边是 cardinality=32 的样子:
参数计算
假设在不使用偏置的情况下:
# A block of ResNet
256x1x64 + 64x3x3x64 + 64x1x256 = 69632
# A block of ResNeXt with cardinality
(256x1x4 + 4x4x3x3 + 4x256) x 32 = 70144两者参数数量差不多,但是后面作者有更加精妙的实现。
注意:
- 每个被聚合的拓扑结构都是一样的(这也是和 Inception 的差别,减轻设计负担)
附上原文比较核心的一句话,点明了增加 cardinality 比增加深度和宽度更有效,这句话的实验结果在后面有展示:

In particular, a 101-layer ResNeXt is able to achieve better accuracy than ResNet-200 but has only 50% complexity.
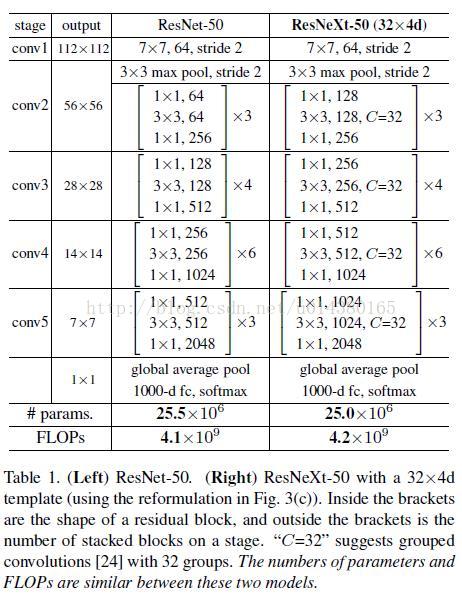
Table1 列举了 ResNet-50 和 ResNeXt-50 的内部结构,另外最后两行说明二者之间的参数复杂度差别不大。
3. 论文核心
作者要开始讲本文提出的新的 block,举全连接层(Inner product)的例子来讲,我们知道全连接层的就是以下这个公式:
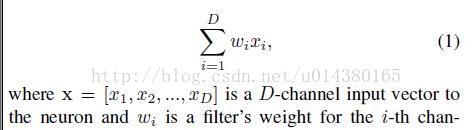
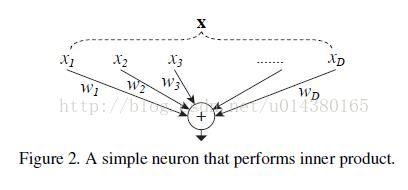
再配上这个图就更容易理解其splitting,transforming和aggregating的过程。
作者将其中的替换乘了更一般的函数,这里用了一个很形象的词:Network in Neuron,式子如下:
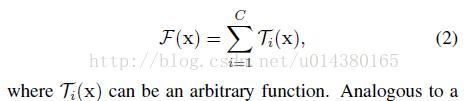
- 其中C就是
cardinality - 有相同的拓扑结构(本文中就是三个卷积层的堆叠)
然后再看fig 3,这里作者展示了3种不同不同的 ResNeXt blocks:
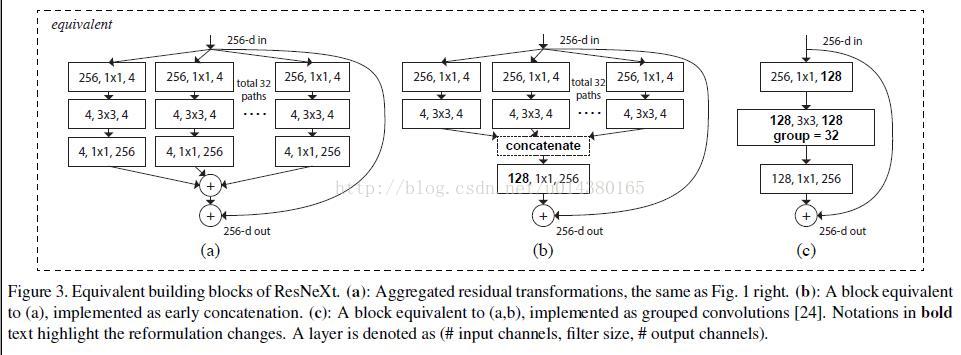
fig3.a
就是前面所说的aggregated residual transformations
fig3.b
则采用两层卷积后 concatenate,再卷积,有点类似 Inception-ResNet,只不过这里的 paths 都是相同的拓扑结构
fig 3.c
采用了一种更加精妙的实现,Group convolution分组卷积
作者在文中明确说明这三种结构是严格等价的,并且用这三个结构做出来的结果一模一样,在本文中展示的是fig3.c的结果,因为fig3.c的结构比较简洁而且速度更快.
4. 组卷积
Group convolution 分组卷积,最早在AlexNet中出现,由于当时的硬件资源有限,训练AlexNet时卷积操作不能全部放在同一个GPU处理,因此作者把feature maps分给多个GPU分别进行处理,最后把多个GPU的结果进行融合。
有趣的是,分组卷积在当时可以说是一种工程上的妥协,因为今天能够简单训练的AlexNet在当时很难训练, 显存不够,Hinton跟他的学生不得不把网络拆分到两张GTX590上面训练了一个礼拜,当然,两张GPU之间如何通信是相当复杂的,幸运的是今天tensorflow这些库帮我们做好了多GPU训练的通信问题。就这样Hinton和他的学生发明了分组卷积. 另他们没想到的是:
分组卷积的思想影响比较深远,当前一些轻量级的SOTA(State Of The Art)网络,都用到了分组卷积的操作,以节省计算量。
疑问
- 如果分组卷积是分在不同GPU上的话,每个GPU的计算量就降低到 1/groups,但如果依然在同一个GPU上计算,最终整体的计算量是否不变?
实际上并不是这样的,Group convolution本身就大大减少了参数,比如当input_channel=256, output_channel=256,kernel size=3x3:
- 不做分组卷积的时候,分组卷积的参数为
256x256x3x3 - 当分组卷积的时候,比如说
group=2,每个group的input_channel、output_channel=128,参数数量为2x128x128x3x3,为原来的1/2.
最后输出的feature maps通过concatenate的方式组合,而不是elementwise add. 如果放到两张GPU上运算,那么速度就提升了4倍.
5. 核心代码
import torch.nn as nn
import torch.nn.functional as F
from torch.nn import init
class ResNeXtBottleneck(nn.Module):
r"""RexNeXt bottleneck type C
https://github.com/facebookresearch/ResNeXt/blob/master/models/resnext.lua
"""
def __init__(self, in_channels, out_channels, stride, cardinality, base_width, widen_factor):
"""
Args:
in_channels (int): input channel dimensionality
out_channels (int): output channel dimensionality
stride: Replaces pooling layer.
cardinality: num of convolution groups.
base_width: base number of channels in each group.
widen_factor: factor to reduce the input dimensionality before convolution.
"""
super().__init__()
self.widel_ratio = out_channels / (widen_factor * 64.)
self.D = cardinality * int(base_width * self.widel_ratio)
# 缩减的卷积层
self.conv_reduce = nn.Conv2d(in_channels=in_channels,
out_channels=self.D,
kernel_size=1,
stride=1,
padding=0,
bias=False)
self.bn_reduce = nn.BatchNorm2d(self.D)
# 组卷积
self.conv_conv = nn.Conv2d(self.D, self.D, 3, stride, 1, groups=cardinality, bias=False)
self.bn = nn.BatchNorm2d(self.D)
# 增加的卷积层
self.conv_expand = nn.Conv2d(self.D, out_channels, 1, 1, 0, bias=False)
self.bn_expand = nn.BatchNorm2d(out_channels)
# 短接的层
self.shortcut = nn.Sequential()
# 如果是两个模块拼接,则
if in_channels != out_channels:
self.shortcut.add_module(name='shortcut_conv',
module=nn.Conv2d(in_channels,
out_channels,
kernel_size=1,
stride=stride,
padding=0,
bias=False))
self.shortcut.add_module(name='shortcut_bn',
module=nn.BatchNorm2d(out_channels))
def forward(self, x):
bottleneck = self.conv_reduce.forward(x)
bottleneck = F.relu(self.bn_reduce.forward(bottleneck), inplace=True)
bottleneck = self.conv_conv.forward(bottleneck)
bottleneck = F.relu(self.bn.forward(bottleneck), inplace=True)
bottleneck = self.conv_expand.forward(bottleneck)
bottleneck = self.bn_expand.forward(bottleneck)
# 如果输入通道数量和输出通道数量相等,则为直接短接
# 如果不相等,短接之前还要做一个卷积操作,将通道数量扩展
residual = self.shortcut.forward(x)
return F.relu(input=(residual + bottleneck), inplace=True)
class CifarResNeXt(nn.Module):
def __init__(self, cardinality, depth, nlabels, base_width, widen_factor=4):
"""Constructor
Args:
cardinality: number of convolution groups.
depth: number of layers.
nlabels: number of classes
base_width: base number of channels in each group.
widen_factor: factor to adjust the channel dimensionality
"""
super().__init__()
self.cardinality = cardinality
self.depth = depth
self.block_depth = (self.depth - 2) // 9
self.base_width = base_width
self.widen_factor = widen_factor
self.nlabels = nlabels
self.output_size = 64
self.stages = [64, 64*self.widen_factor, 128*self.widen_factor, 256*self.widen_factor]
self.conv_1_3x3 = nn.Conv2d(in_channels=3,
out_channels=64,
kernel_size=3,
stride=1,
padding=1,
bias=False)
self.bn_1 = nn.BatchNorm2d(64)
self.stage_1 = self.block('stage_1',
in_channels=self.stages[0],
out_channels=self.stages[1],
pool_stride=1)
self.stage_2 = self.block('stage_2', self.stages[1], self.stages[2], 2)
self.stage_3 = self.block('stage_3', self.stages[2], self[3], 2)
self.classifier = nn.Linear(in_features=self.stages[3], out_features=nlabels)
self.initialize_weights() # 初始化权重
def initialize_weights(self):
init.kaiming_normal(self.classifier.weight) # 用kaiming初始化classifier
for key in self.state_dict():
if key.split('.')[-1] == 'weight':
if 'conv' in key:
init.kaiming_normal(self.state_dict()[key], mode='fan_out')
if 'bn' in key:
self.state_dict()[key][...] = 1
elif key.split('.')[-1] == 'bias':
self.state_dict()[key][...] = 0
def block(self, name, in_channels, out_channels, pool_stride=2):
"""Stack n bottleneck modules where n is inferred from the depth of the network.
Args:
name: string name of the current block.
in_channels: number of input channels
out_channels: number of output channels
pool_stride: factor to reduce the spatial dimensionality in the first bottleneck of the block.
Returns:
a Module consisting of n sequential bottlenecks.
"""
block = nn.Sequential()
for bottleneck in range(self.block_depth):
name_ = '%s_bottleneck_%d' % (name, bottleneck)
if bottleneck == 0:
block.add_module(name_, module=ResNeXtBottleneck(in_channels,
out_channels,
stride=pool_stride,
cardinality=self.cardinality,
base_width=self.base_width,
widen_factor=self.widen_factor))
else:
block.add_module(name_, module=ResNeXtBottleneck(out_channels,
out_channels,
1,
self.cardinality,
self.base_width,
self.widen_factor))
return block
def forward(self, x):
x = self.conv_1_3x3.forward(x)
x = F.relu(self.bn_1.forward(x), inplace=True)
x = self.stage_1.forward(x)
x = self.stage_2.forward(x)
x = self.stage_3.forward(x)
x = F.avg_pool2d(input=x, kernel_size=8, stride=1)
x = x.view(-1, self.stages[3])
return self.classifier(x)