版权声明:本文为博主原创学习笔记,如需转载请注明来源。 https://blog.csdn.net/SHU15121856/article/details/84072885
学习《Python3爬虫、数据清洗与可视化实战》时自己的一些实践。
Series.apply()列数据批量处理
先将该列取出,形成Series对象,再调用apply()方法传入用于处理的函数,这个过程就像map()一样。
import pandas as pd
# 各国人口数据文件
df_pop = pd.read_csv("E:/Data/practice/european_cities.csv")
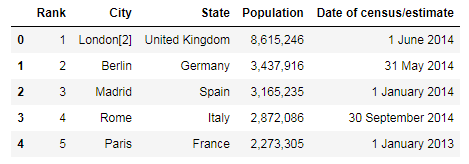
# print(df_pop.head())
# 查看字段的数据类型.用这种方式查看到的object(文本)就是str类型
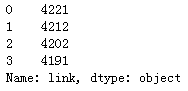
print(df_pop.dtypes)

# 这里表明两种写法是一样的,都返回这一列的Series对象
print(df_pop['Population'] is df_pop.Population) # True
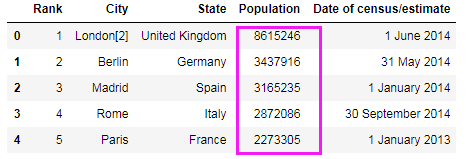
# 对人口字段,删除逗号并转为int:这里apply()函数传入一个函数,将对Series中的每个项调用该函数
df_pop['Population'] = df_pop.Population.apply(lambda x: int(x.replace(",", "")))
# print(df_pop.head())
# 读取State列的前三个数据看一下
ary = df_pop['State'].values[:3]
print(ary) # [' United Kingdom' ' Germany' ' Spain']
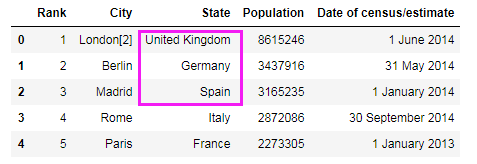
# 去掉State字段中数据两端的空格
df_pop['State'] = df_pop.State.apply(lambda x: x.strip())
# print(df_pop.head())
Series.str.extract()正则匹配
import pandas as pd
# 中国旅游网的文章标题和链接数据
df = pd.read_csv("E:/Data/practice/getlinks.csv")
# print(df.head())
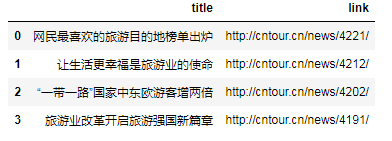
# 这里df.link即获取link这一列形成Series对象
# Series对象的str属性的extract()方法,将对Series对象中的每个项用指定的正则方式匹配并生成匹配后的DataFrame
# 没有匹配到的部分在生成的DF对象中将被设置成NaN
df1 = df.link.str.extract(r'(\d+)') # 匹配数字
# print(df1.head())

# 匹配'.'任意字符'/'数字,因为是两部分所以生成的DF对象有两列
df2 = df.link.str.extract(r'(.*)/(\d)')
# print(df2.head())
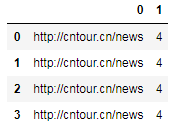
# 在括号内最前面写'?P<列名>'可以为生成的DF对象添加列名
df3 = df.link.str.extract(r'(?P<URL>.*)/(?P<ID>\d+)') # 匹配的内容和df2是一样的
# print(df3.head())
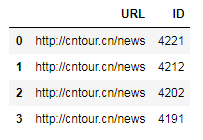
另外书上没有讲expand参数,该参数默认是True,当设置为False时,对于只匹配一个组的模式(如上例中的df1)将返回一个Series对象,而不再是DF对象。
# 这时返回一个Series,而不是单列的DF
s4 = df.link.str.extract(r'(\d+)', expand=False)
# print(s4.head())