文章目录
Schema介绍
Schema:模式,是集合/内核中字段的定义,让solr知道集合/内核包含哪些字段、字段的数据类型、字段该索引存储。
Solr中提供了两种方式来配置schema,两者只能选其一
- 默认方式,通过Schema API 来实时配置,模式信息存储在内核目录的conf/managed-schema.xml文件中,一般使用这种方式,特别是在SolrCloud模式下。
- 传统的手工编辑内核目录的conf/schema.xml的方式,编辑完后需重载集合/内核才会生效。
两种方式之间是可以切换的,比如用于升级操作,从旧版本到新版本的升级,切换方式如下:
- 手动编辑切换到API方式: 只需将solrconfig.xml中的 去掉,或改为ManagedIndexSchemaFactory。Solr重启时,它发现之前存储在schema.xml中但没有存储在 managed-schema.xml中,则它会备份schema.xml,然后改写schema.xml为managed-schema.xml。此后就可以通过Schema API 管理schema了
- API切换到手动编辑方式: 首先将managed-schema.xm重命名为schema.xml;然后将solrconfig.xml中schemaFactory 的ManagedIndexSchemaFactory去掉(如果存在);最后增加
除此之外,Solr还支持无模式的方式,这种情况Solr会猜测该如何索引字段,这种方式不能应用在生产环境,也比较少用。
managed-schema.xml文件详解
Solr启动一个服务器实例后,会内置了很多field字段、唯一ID、fieldType字段类型等,这些信息都是在managed-schema.xml文件中定义的。我们先了解下managed-schema.xml文件的大致结构:
<?xml version="1.0" encoding="UTF-8" ?>
<schema version="1.6">
<field .../>
<dynamicField .../>
<uniqueKey>id</uniqueKey>
<copyField .../>
<fieldType ...>
<analyzer type="index">
<tokenizer .../>
<filter ... />
</analyzer>
<analyzer type="query">
<tokenizer.../>
<filter ... />
</analyzer>
</fieldType>
</schema>
Field详解
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" />
<field name="_version_" type="plong" indexed="false" stored="false"/>
<field name="_root_" type="string" indexed="true" stored="false" docValues="false" />
<field name="_text_" type="text_general" indexed="true" stored="false" multiValued="true"/>
字段属性说明:
- name:字段名,必需。字段名可以由字母、数字、下划线构成,不能以数字开头。以下划线开头和结尾的名字为保留字段名,如 version
- type:字段的fieldType名,必需。为 FieldType标签中定义的name属性值。
- default:默认值,非必须。如果提交的文档中没有该字段的值,则自动会为文档添加这个默认值。相当于传统数据库中的字段默认值。
除此之外,字段还有很多可选属性如下:
|
|
|
|
|
|---|---|---|---|
| indexed | 是否索引 | true、false | true |
| stored | 是否存储 | true、false | true |
| docValues | 是否为该字段创建字段的列式存储(docValues) | true、false | false |
| sortMissingFirst sortMissingLast |
根据该字段排序时,没有该字段值的文档是排在前面还是后面 | true、false | false |
| multiValued | 字段是否是多值的 | true、false | false |
| omitNorms | 是否忽略标准化。对于所有 primitive (non-analyzed) field types, such as int, float, data, bool, and string,默认是true. Only full-text fields or fields need norms | true、false | * |
| omitTermFreqAndPositions | 是否忽略词项的词频和位置 | true、false | * |
| omitPositions | 忽略词项的位置信息 | true、false | * |
| termVectors termPositions termOffsets termPayloads |
词项向量的存储 | true、false | false |
| required | 字段是否必需 | true、false | false |
| useDocValuesAsStored | 如果字段设置了存储docValues,而字段的stored=false,可以设置该属性为true,从而可以在搜索结果中返回该字段的值(从docValues中取值) | true、false | true |
| large | 标识该字段的值是大尺寸的,从而对该字段值进行懒加载,只有值 < 512KB 的才会被缓存。 这个属性要求 stored=“true” and multiValued=“false”. 主要作用就是不在内存中缓存大字段 | true、false | false |
注意:
- 上述属性是Field字段本身就有的
- Field字段中有一个属性type,该属性会指向一个FieldType标签,该标签内部也会有上述描述的那些属性
- 如果Field中某个属性在引用的FieldType中也存在,则以Field中定义的属性为准
- 一般来说,使用FieldType中定义的属性就已经够用了,如果字段比较特殊,可以在字段层面定义属性,用来覆盖掉FieldType中的属性
FieldType详解
作用:定义在索引时该如何分词、索引、存储字段,在查询时该如何对查询串分词
<fieldType name="string" class="solr.StrField" sortMissingLast="true" docValues="true" />
<fieldType name="boolean" class="solr.BoolField" sortMissingLast="true"/>
<fieldType name="text_ws" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.WhitespaceTokenizerFactory"/>
</analyzer>
</fieldType>
字段类型属性说明:
- name:字段类型名称,用于Field定义中的type属性引用
- class:存放该类型的值来进行索引的字段类名(同lucene中Field的子类)。注意,应以 *solr.*为前缀,这样solr就可以很快定位到该到哪个包中去查找类,如 solr.TextField 。如果使用的是第三方包的类,则需要用全限定名。solr.TextField 的全限定名为:org.apache.solr.schema.TextField。
- positionIncrementGap:用于多值字段,定义多值间的间隔,来阻止假的短语匹配
- autoGeneratePhraseQueries:用于文本字段,如果设为true,solr会自动对该字段的查询生成短语查询,即使搜索文本没带“”
- synonymQueryStyle:同义词查询分值计算方式
- enableGraphQueries:是否支持图表查询
- docValuesFormat:docValues字段的存储格式化器:schema-aware codec,配置在solrconfig.xml中的
- postingsFormat:词条格式器:schema-aware codec,配置在solrconfig.xml中的
还有一些属性没有列举出来,这些字段同Field字段的属性是共有的。
Solr中提供的 FieldType 类,在 org.apache.solr.schema 包下
Solr自带的FieldType查看:http://lucene.apache.org/solr/guide/7_5/field-types-included-with-solr.html
FieldType的Analyzer
对于 solr.TextField 或 solr.SortableTextField 字段类型,需要为其定义分析器,有两种方式。
方式一:直接通过class属性指定分析器类,该类必须继承org.apache.lucene.analysis.Analyzer
<fieldType name="nametext" class="solr.TextField">
<analyzer class="org.apache.lucene.analysis.core.WhitespaceAnalyzer"/>
</fieldType>
方式二:可以灵活地组合分词器、过滤器
<fieldType name="nametext" class="solr.TextField">
<analyzer>
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.StandardFilterFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.StopFilterFactory"/>
</analyzer>
</fieldType>
如果该类型字段索引、查询时需要使用不同的分析器,则需区分配置analyzer
<fieldType name="nametext" class="solr.TextField">
<analyzer type="index">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
<filter class="solr.KeepWordFilterFactory" words="keepwords.txt"/>
<filter class="solr.SynonymFilterFactory" synonyms="syns.txt"/>
</analyzer>
<analyzer type="query">
<tokenizer class="solr.StandardTokenizerFactory"/>
<filter class="solr.LowerCaseFilterFactory"/>
</analyzer>
</fieldType>
Solr中提供的分词器tokenizer:http://lucene.apache.org/solr/guide/7_5/tokenizers.html
Solr中提供的过滤器filter:http://lucene.apache.org/solr/guide/7_5/filter-descriptions.html
常用的Filter
- StopFilter:停用过滤器
<analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" words="stopwords.txt"/> </analyzer>- words属性指定停用词文件的绝对路径或相对solr主目录下conf/目录的相对路径
- 停用词定义语法:一行一个
- SynonymGraphFilter:同义词过滤器
<analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/> <filter class="solr.FlattenGraphFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.SynonymGraphFilterFactory" synonyms="mysynonyms.txt"/> </analyzer>- synonyms属性指定同义词文件的绝对路径或相对solr主目录下conf/目录的相对路径
- 同义词定义语法:一类一行,如下表示,=>表示查询时标准化为后面的内容
couch,sofa,divan
teh => the
huge,ginormous,humungous => large
small => tiny,teeny,weeny
停用词和同义词练习
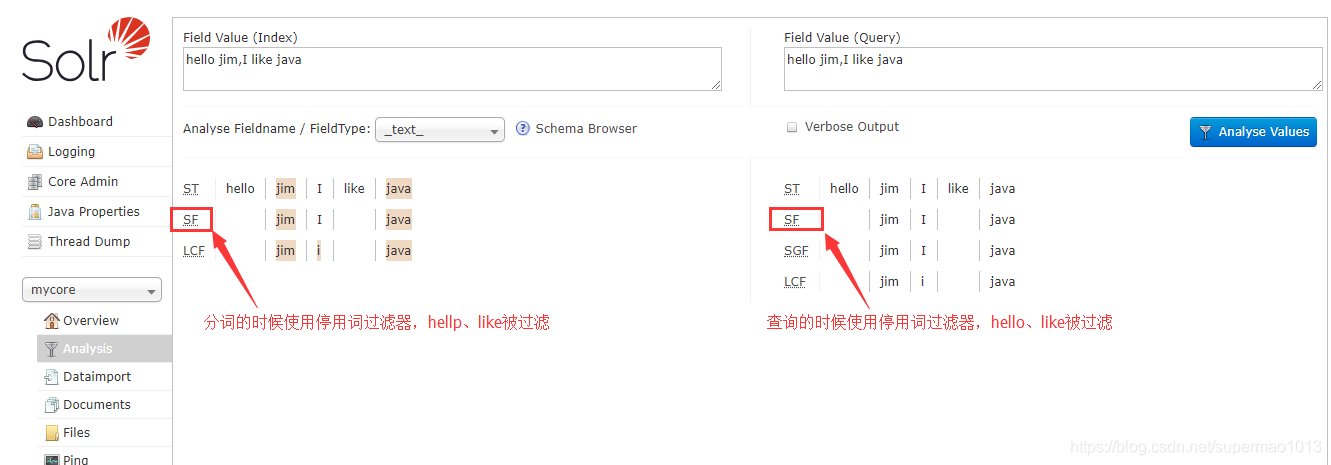
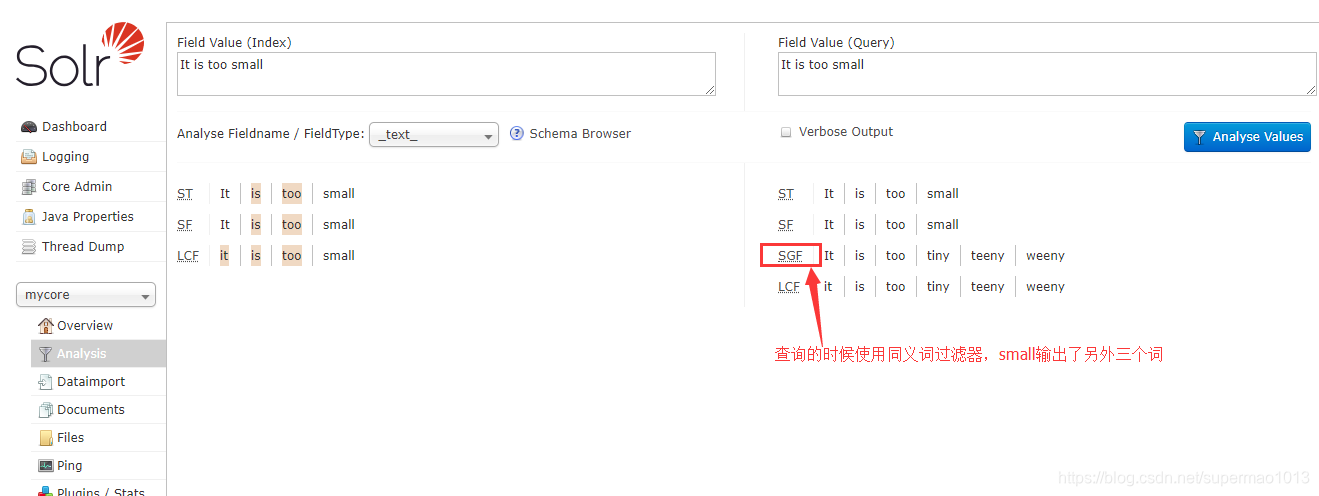
按照Solr搜索引擎第三篇-两种部署模式详解创建一个单机模式下的内核mycore。
手动编辑该mycore主目录/conf/下的停用词stopwords.txt文件,加入如下内容:
hello
like
手动编辑该mycore主目录/conf/下的同义词synonyms.txt文件,加入如下内容:
couch,sofa,divan
teh => the
huge,ginormous,humungous => large
small => tiny,teeny,weeny
然后重载mycore,登陆web界面进行停用词和同义词的测试:
时间字段
Solr中提供的时间字段类型( DatePointField, DateRangeField,废除的TrieDateField )是以时间毫秒数来存储时间的。要求字段值以ISO-8601标准格式来表示时间:YYYY-MM-DDThh:mm:ssZ。Z表示是UTC时间,如1999-05-20T17:33:18Z
- 秒上可以带小数来表示毫秒,超出精度部分会被忽略,如:1972-05-20T17:33:18.772Z、1972-05-20T17:33:18.77Z、1972-05-20T17:33:18.7Z
- 公元前:在前面加减号-
- 9999后:在前面加加号+
注意:查询时如果是直接的时间串,需要用转义字符进行转义:
datefield:1972-05-20T17\:33\:18.772Z
#用字符串表示的则不需要转义
datefield:"1972-05-20T17:33:18.772Z"
#用中括号表示的也不需要转义
datefield:[1972-05-20T17:33:18.772Z TO *]
DateRangeField用来支持对时间段数据的索引,它遵守上述讲到的时间格式,支持两种时间段表示方式:
- 方式一:截断日期,它表示整个日期跨度的精确指示。
- 方式二:时间范围,语法 [t1 TO t2] {t1 TO t2},中括号表示包含边界,大括号表示不包含边界
例子:
2000-11 #表示2000年11月整个月.
2000-11T13 #表示200年11月每天的13点这一个小时
-0009 #公元前10年,0000是公元前1年。
[2000-11-01 TO 2014-12-01] #日到日
[2014 TO 2014-12-01] #2014年开始到2014-12-01止.
[* TO 2014-12-01] #2014-12-01(含)前.
Solr中还支持用 【NOW ±/ 时间】的数学表达式来灵活表示时间。
NOW表示当前时间,±表示加上或减去时间,/表示截断
NOW+1MONTH #当前时间加上1个月
NOW+2MONTHS #当前时间加上两个月,复数要机上S
NOW-1DAY
NOW-2DAYS
NOW/HOUR #对HOUR进行截断,表示这1小时
NOW+6MONTHS+3DAYS/DAY
1972-05-20T17:33:18.772Z+6MONTHS+3DAYS/DAY
NOW在查询中使用时,可为NOW指定值:
q=solr&fq=start_date:[* TO NOW]&NOW=1384387200000
EnumFieldType 枚举
EnumFieldType 用于字段值是一个枚举集,且排序顺序可预定的情况,如新闻分类这样的字段。定义非常简单:
<fieldType name="priorityLevel" class="solr.EnumFieldType"
docValues="true" enumsConfig="enumsConfig.xml" enumName="priority"/>
- enumsConfig:指定枚举值的配置文件,绝对路径或相对内核conf/的相对路径
- enumName:指定配置文件的枚举名。排序顺序是按配置的顺序。
- docValues :枚举类型字段必须设置 true
enumsConfig.xml配置示例(若没有该文件则新建)如下:
<?xml version="1.0" ?>
<enumsConfig>
<enum name="priority">
<value>Not Available</value>
<value>Low</value>
<value>Medium</value>
<value>High</value>
<value>Urgent</value>
</enum>
<enum name="new_cat">
<value>实事</value>
<value>体育</value>
<value>科技</value>
<value>时尚</value>
</enum>
</enumsConfig>
DynamicField 动态字段
如果模式中有近百个字段需要定义,其中有很多字段的定义是相同,重复地定义就十分的麻烦,因此可以定一个规则,字段名以某前缀开头或结尾的是相同的定义配置,那这些重复字段就只需要配置一个,保证提交的字段名称遵守这个前缀、后缀即可。这就是动态字段。
如:整型字段都是一样的定义,则可以定义一个动态字段如下
<dynamicField name="*_i" type=“my_int" indexed="true" stored="true"/>
注意:动态字段只能用符号*通配符进行表示,且只有前缀和后缀两种方式
CopyField 复制字段
复制字段允许将一个或多个字段的值填充到一个字段中。它的用途有两种:
- 将多个字段内容填充到一个字段,来进行搜索
- 对同一个字段内容进行不同的分词过滤,创建一个新的可搜索字段
定义方式:
1.先定义一个普通字段
<field name="cc_all" type="zh_CN_text" indexed="true"
stored="false" multiValued="false" />
2.定义复制字段
<!--也可以将source定义为动态字段-->
<copyField source="cat" dest="cc_all"/>
<copyField source="name" dest="cc_all"/>
UniqueKey 唯一键
指定用作唯一键的字段,非必须。这里的唯一键是指业务主键,并不是document的主键。
<!--指定商品ID为唯一键,类似于传统数据库的主键ID-->
<uniqueKey>productId<uniqueKey>
唯一键字段不可以是保留字段、复制字段,且不能分词。