版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Nicht_sehen/article/details/80713002
数据处理
去均值
将数据的特征都减去全部数据的特征均值,将输入数据各个维度的数据中性化到0,可用
X-=np.mean(X,axis=0)实现
归一化
将数据所有维度都归一化,使其数值范围近似相等,有两种方法:
1.用数据除以这个维度上的标准差(X /= np.std(X,axis=0))
2.除以数据绝对值最大值,保证数据在[-1,1]之间
PCA和白化(whitening)
先对数据进行零中心化处理,然后计算协方差矩阵
python代码实现
X-=np.mean(X,axis=0)
cov=np.dot(X.T,X)/X.shape[0]
U,S,V=np,linalg.svd(cov)# 奇异值分解
Xrot=np.dot(X,U)
Xrot_reduced=np.dot(X,U[:,:100])
Xwhite=Xrot / np.sqrt(S+1e-5)# 白化
权重初始化
1.如果将参数全部初始化为0会发生什么?
所有神经元计算的结果一样
2.用很小的随机数初始化
W=0.001*np.random.randn(D,H)
适用于小型网络,打破了W的对称问题,但不适用于层数多的深度网络
3.方差归一化初始化
W=np.random(n)/sqrt(n)
监视训练
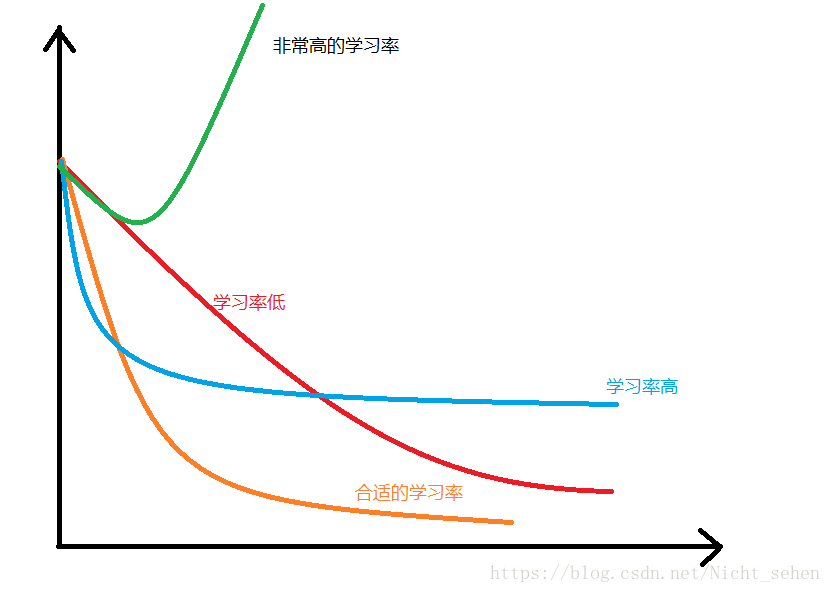
纵坐标为loss,横坐标为epoch
参数更新
因为SGD容易卡在局部最小值,所以对梯度更新采取了一些优化
Momentum
核心思想是加入一部分“速度”
v=mu*v-learning_rate*dx
x+=vNesterov Momentum
这是Momentum的变体,但是这种方法的收敛效果略优
v_prev=v
v=mu*v_learning_rate*dx
x+=-mu*v_pred+(1+mu)*vAdoGrad
cache+=dx**2
x+=-learning_rate*dx/np.sqrt(cache+1e-8)用cache持续累加梯度的平方,然后被用到W更新的归一化,高梯度,学习率降低,低梯度,学习率升高
RMSProp(AdoGrad的改进)
对比之下,这个方法比较高效
cache=decay_rate*cache+(1-decay_rate)*dx**2
x+=-learning_rate*dx/(np.sqrt(cache)+eps)Adam(看起来像RMSProp的动量版)
m=beta1*m+(1-beta1)*dx
v=beta2*v+(1-beta2)*(dx**2)
x+=-learning_rate*m/(np.sqrt(v)+eps)正则化
L1,L2
非常常见,不解释
dropout(常用,但是耗时长)
将一部分神经元置零(实际上是置零激活函数),置零多数在全连接层,少数在卷积层
Data Augmention
在不改变label的情况下对图片做出一些改变(如翻转,平移等)生成新的训练集
drop connect
dropout的一般化,将网络架构权重的一个随机选择子集置零(对权重引入稀疏性)
Fractional Max Pooling
不均匀方格最大池化