最近项目不那么紧张,有时间来研究一下Python,先前断断续续的自学了一段时间,有些浅基础。刚好在码云上看到比较适合的案例,跟着案例再往前走一波。
案例一:爬虫抓图
开发工具:PyCharm 脚本语言:Python 3.7.1 开发环境:Win10 爬取网站:妹子图
# Win下直接装的 python3 pip install bs4、pip install requests # Linux python2 python3 共存 pip3 install bs4、pip3 install requests
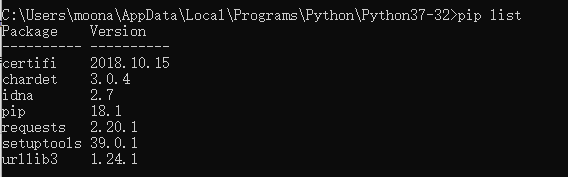
pip list 查看库
导库说明
# 导入requests库 导入目的:负责发送网络请求
import requests
# 导入文件操作库OS 导入目的:读写
import os
# bs4全名BeautifulSoup,是编写python爬虫常用库之一,主要用来解析html标签。 性能据说可能差了点,入门级凑合着用吧。
import bs4
from bs4 import BeautifulSoup
# 基础类库
import sys
# Python 3.x 解决中文编码问题
import importlib
importlib.reload(sys)
先上源代码:
#coding=utf-8 #!/usr/bin/python # 导入requests库 import requests # 导入文件操作库 import os import bs4 from bs4 import BeautifulSoup import sys import importlib importlib.reload(sys) # 给请求指定一个请求头来模拟chrome浏览器 global headers headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36'} # 爬图地址 mziTu = 'http://www.mzitu.com/' # 定义存储位置 global save_path save_path = 'G:\BeautifulPictures' # 创建文件夹 def createFile(file_path): if os.path.exists(file_path) is False: os.makedirs(file_path) # 切换路径至上面创建的文件夹 os.chdir(file_path) # 下载文件 def download(page_no, file_path): global headers res_sub = requests.get(page_no, headers=headers) # 解析html soup_sub = BeautifulSoup(res_sub.text, 'html.parser') # 获取页面的栏目地址 all_a = soup_sub.find('div',class_='postlist').find_all('a',target='_blank') count = 0 for a in all_a: count = count + 1 if (count % 2) == 0: print("内页第几页:" + str(count)) # 提取href href = a.attrs['href'] print("套图地址:" + href) res_sub_1 = requests.get(href, headers=headers) soup_sub_1 = BeautifulSoup(res_sub_1.text, 'html.parser') # ------ 这里最好使用异常处理 ------ try: # 获取套图的最大数量 pic_max = soup_sub_1.find('div',class_='pagenavi').find_all('span')[6].text print("套图数量:" + pic_max) for j in range(1, int(pic_max) + 1): # print("子内页第几页:" + str(j)) # j int类型需要转字符串 href_sub = href + "/" + str(j) print(href_sub) res_sub_2 = requests.get(href_sub, headers=headers) soup_sub_2 = BeautifulSoup(res_sub_2.text, "html.parser") img = soup_sub_2.find('div', class_='main-image').find('img') if isinstance(img, bs4.element.Tag): # 提取src url = img.attrs['src'] array = url.split('/') file_name = array[len(array)-1] # print(file_name) # 防盗链加入Referer headers = {'Referer': href} img = requests.get(url, headers=headers) # print('开始保存图片') f = open(file_name, 'ab') f.write(img.content) # print(file_name, '图片保存成功!') f.close() except Exception as e: print(e) # 主方法 def main(): res = requests.get(mziTu, headers=headers) # 使用自带的html.parser解析 soup = BeautifulSoup(res.text, 'html.parser') # 创建文件夹 createFile(save_path) # 获取首页总页数 img_max = soup.find('div', class_='nav-links').find_all('a')[3].text # print("总页数:"+img_max) for i in range(1, int(img_max) + 1): # 获取每页的URL地址 if i == 1: page = mziTu else: page = mziTu + 'page/' + str(i) file = save_path + '\\' + str(i) createFile(file) # 下载每页的图片 print("套图页码:" + page) download(page, file) if __name__ == '__main__': main()
代码分析:
if __name__ == '__main__': main()
这段代码啥意思呢?
if __name__ == '__main__'的意思是:当.py文件被直接运行时,if __name__ == '__main__'之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == '__main__'之下的代码块不被运行。
如果没有这段代码 主方法main()也就无法被直接运行,可以简单先理解为启动主方法的入口。
然后我们再看主方法
# 主方法
def main():
res = requests.get(mziTu, headers=headers)
// 我们可以从这个对象res中获取所有我们想要的信息 下行res.text 就是当前页面的html信息 具体看对应API
# 使用自带的html.parser解析
soup = BeautifulSoup(res.text, 'html.parser')
//html字符串创建BeautifulSoup对象 此处可以soup.title soup.title.name soup.title.string soup.a['href'] soup.p['class'] 不嫌事多,你可以打印出来看看,具体看对应API
# 创建文件夹
createFile(save_path) //创建目标文件夹,作用当然用来存爬到的资源
# 获取首页总页数
img_max = soup.find('div', class_='nav-links').find_all('a')[3].text
# print("总页数:"+img_max)
for i in range(1, int(img_max) + 1):
# 获取每页的URL地址
if i == 1:
page = mziTu
else:
page = mziTu + 'page/' + str(i)
file = save_path + '\\' + str(i)
createFile(file)
# 下载每页的图片
print("套图页码:" + page)
download(page, file)
核心代码
res = requests.get(mziTu, headers=headers) soup = BeautifulSoup(res.text, 'html.parser')以上两段代码我们基本上拿到了以下html信息的全部

# 获取首页总页数 img_max = soup.find('div', class_='nav-links').find_all('a')[3].text
第一步:soup.find('div',class='nav-links')取到class='nav-links'的div
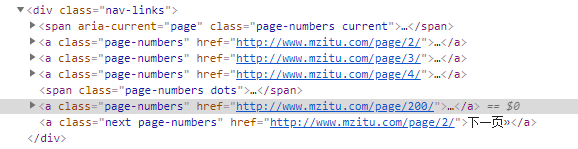
第二步:.find_all('a') 在该div内取全部的<a></a>标签 为一个数组

第三步:.find_all('a')[3] 取第四个<a></a>标签 数组下标从0开始

第四步:.find_all('a')[3].text 取得页码总数 也就是 200
for i in range(1, int(img_max) + 1): # 获取每页的URL地址 if i == 1: page = mziTu else: page = mziTu + 'page/' + str(i) file = save_path + '\\' + str(i) createFile(file) # 下载每页的图片 print("套图页码:" + page) download(page, file)
这段理解起来很简单
第一步:创建存放文件夹 此处save_path="G:\BeautifulPictures\num" num=[1,200] 程序运行后,此目录有源源不断的图片纷至杳来。
第二步:拼接源文件(每一张图片)路径?目标是此,但此处具体到每一页(路径是:http://www.mzitu.com/page/num num=[1,200]),还没深入到每一个专题。要想具体到每一张只能继续往下爬,此处可移步download(page,file)方法。
例如现在num=4 经过download()方法就可以具体到每一张图片了 下面分析download()方法
# 下载文件 def download(page_no, file_path): global headers res_sub = requests.get(page_no, headers=headers) # 解析html soup_sub = BeautifulSoup(res_sub.text, 'html.parser') # 获取页面的栏目地址 all_a = soup_sub.find('div',class_='postlist').find_all('a',target='_blank') count = 0 for a in all_a: count = count + 1 if (count % 2) == 0: print("内页第几页:" + str(count)) # 提取href href = a.attrs['href'] print("套图地址:" + href) res_sub_1 = requests.get(href, headers=headers) soup_sub_1 = BeautifulSoup(res_sub_1.text, 'html.parser') # ------ 这里最好使用异常处理 ------ try: # 获取套图的最大数量 pic_max = soup_sub_1.find('div',class_='pagenavi').find_all('span')[6].text print("套图数量:" + pic_max) for j in range(1, int(pic_max) + 1): # print("子内页第几页:" + str(j)) # j int类型需要转字符串 href_sub = href + "/" + str(j) print(href_sub) res_sub_2 = requests.get(href_sub, headers=headers) soup_sub_2 = BeautifulSoup(res_sub_2.text, "html.parser") img = soup_sub_2.find('div', class_='main-image').find('img') if isinstance(img, bs4.element.Tag): # 提取src url = img.attrs['src'] array = url.split('/') file_name = array[len(array)-1] # print(file_name) # 防盗链加入Referer headers = {'Referer': href} img = requests.get(url, headers=headers) # print('开始保存图片') f = open(file_name, 'ab') f.write(img.content) # print(file_name, '图片保存成功!') f.close() except Exception as e: print(e)
假设num=4 ,此时
page_no='http://www.mzitu.com/page/4'
经过request.get(),发送get请求,再被BeautifulSoup解析我们就拿到了下面的html代码
res_sub = requests.get(page_no, headers=headers) # 解析html soup_sub = BeautifulSoup(res_sub.text, 'html.parser')
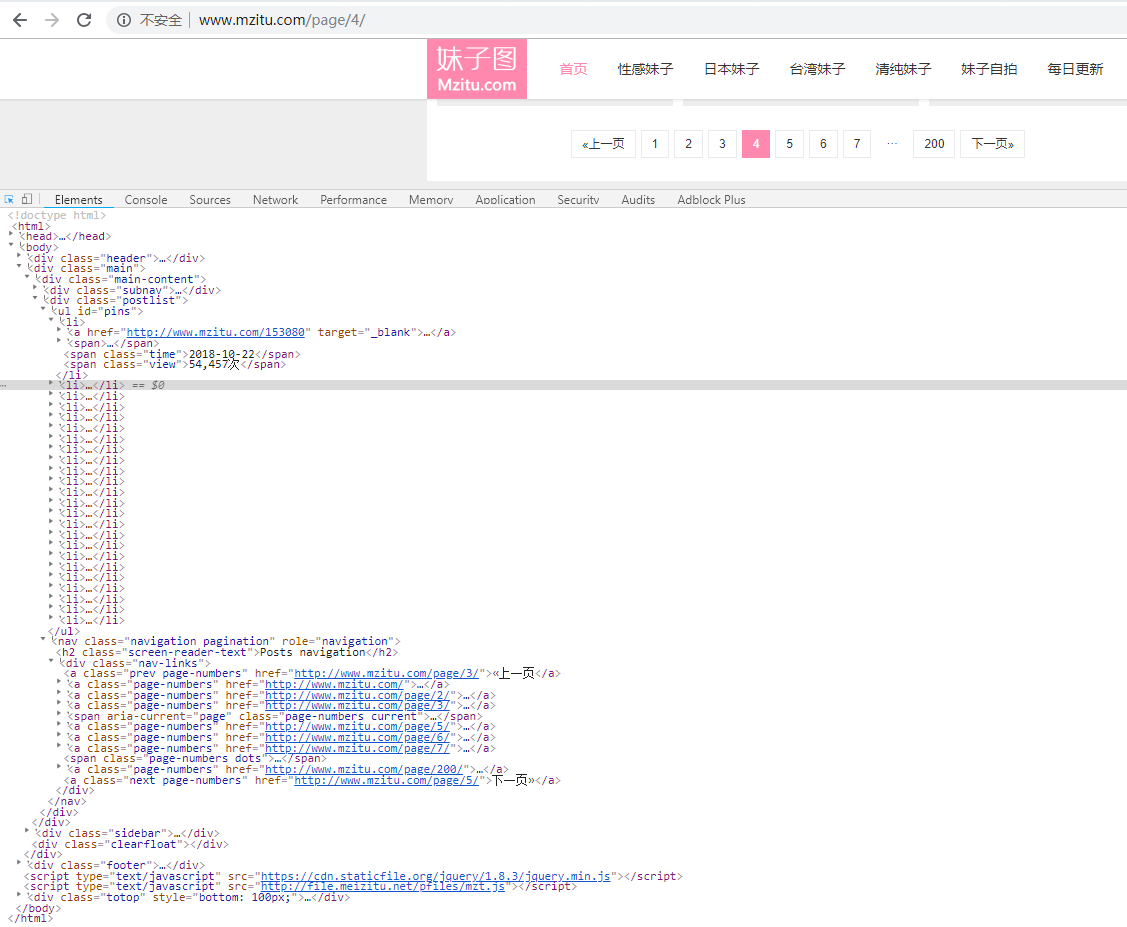
然后我们很容易看到我们的目标文件是,id='pins'下的所有<a></a>标签,如下图。此herf只具体到每一个小姐姐的第一张照片,还不能具体到小姐姐的每一张照片。没关系,点击链接进去,再看看。
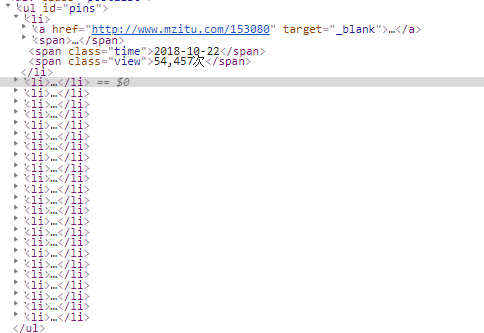
此时我们再看
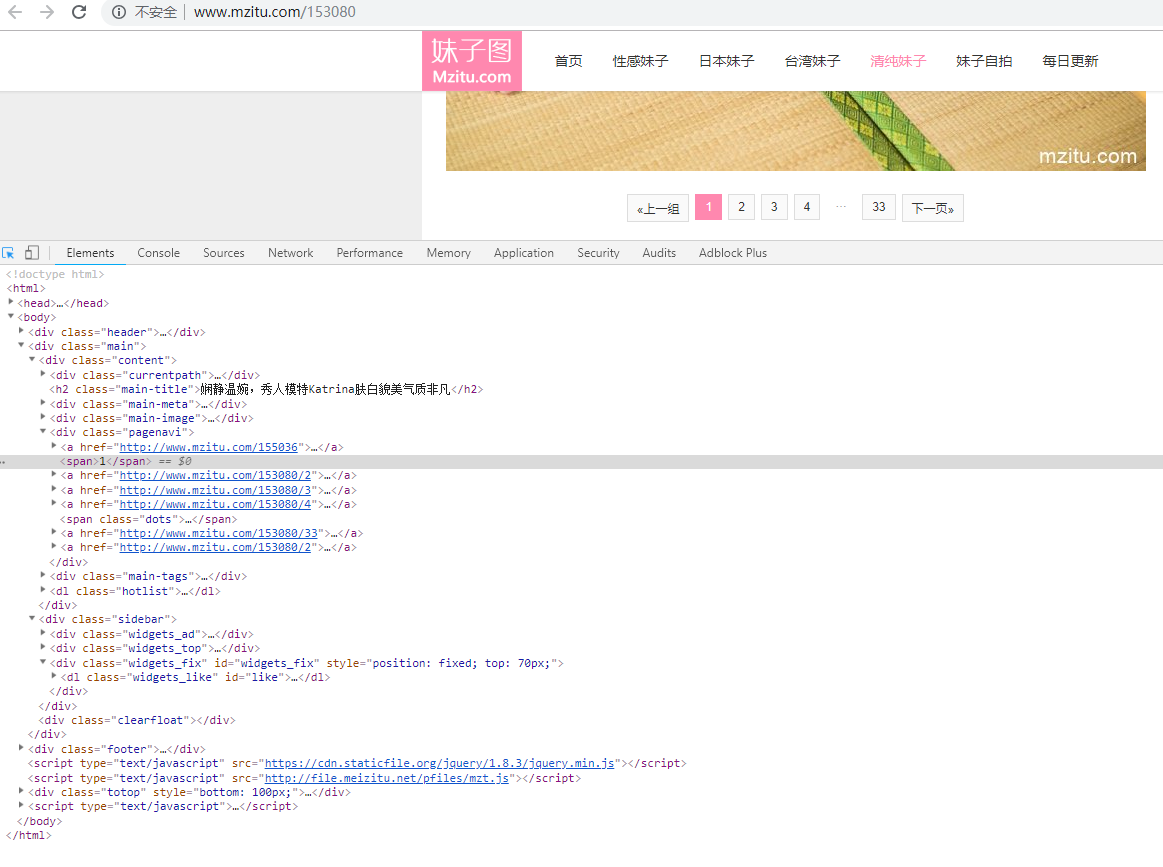
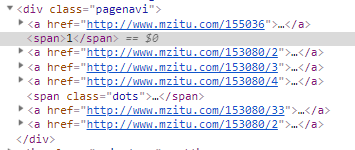
再扒一层就到具体的每一张图片的地址了,读一波,写一波f.write(img.content),一波走起,保存本地,
然后看本地的战利品:请爱惜自己的身体

个人小小的赶脚,爬虫抓包,找到你需要下载的每一个路径,一步步去按标签爬,保存本地。貌似也挺简单的哈。第一次跑Python代码,不好的地方见笑。
源代码码云地址:https://gitee.com/52itstyle/Python 感兴趣的一起学一波,组个队。