最近因为项目需要做搜索,安排我对搜索的性能这一方面做调研。本文档调研了simhash和es为代表的搜索方案。用Simhash和ElasticSearch做搜索各有优缺点,综合来看可这么标签:Simhash是偏计算密集型的搜索方案代表,但算法方案复杂;ElasticSearch是IO和硬件消耗大的搜索方案,但易用性更高;因为精力资源有限,不能亲自搭建上述方案进行实际测试对比,后续条件成熟可以根据需要实际搭建测试体验,一些数据参考网络,参考资料来备注在文档末尾。
调研过程:
| 名称 |
具体方案 |
| Simhash + Hbase |
使用效果: 比对5000w条数据相似,可3.6毫秒内实现; 处理过程: 见下图,根据simhash code查找对应的数据即可; 关键算法实现: Java实现: http://www.open-open.com/lib/view/open1375690611500.html Python实现: https://github.com/seomoz/simhash-cluster 优缺点: 方案复杂,查询方便,算法效率高,硬件开销非常小 使用建议: 可根据检索类型,加服务队列,自定义simhash code库,以键值对形式,根据value查Hbase。 注意点: 需根据人工测试比对,来确定海明距离/余弦相似度的阈值。 (对于我司的应用场景,做下排序就好了) 使用案例: 谷歌的网页去重、新浪微博相似度比较等。 |
| ElasticSearch + Hbase |
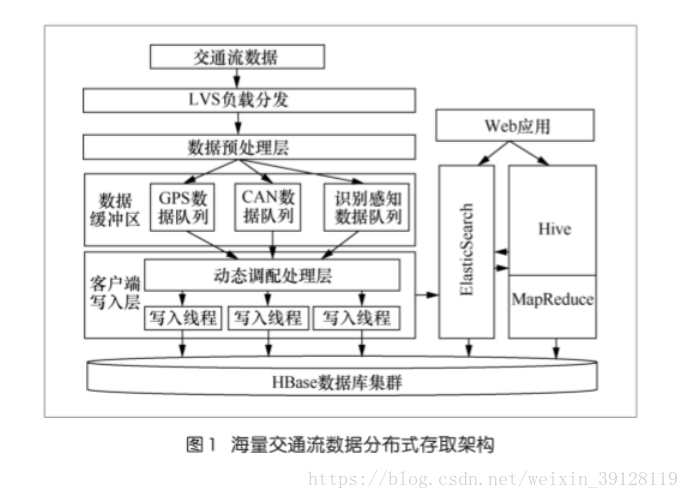
使用效果: 亿万数据查询进行秒回; 处理过程: 根据需要,将数据存储在es索引中,根据索引通查hbase。具体架构图如下。 关键查询算法:
优缺点: 方案简单,查询更灵活,算法效率低,硬件开销大 注意点: 该方案硬件开销大,单纯依赖硬件堆砌增加边界。 700万的数据,消耗了3个节点,各节点硬件配备的4G内存 使用案例: 应用比较多,海量交通数据实时存取等。
|
结论:用Simhash和ElasticSearch做搜索各有优缺点,综合来看可这么标签:
Simhash是偏计算密集型的搜索方案代表,但算法方案复杂;
ElasticSearch是IO和硬件消耗大的搜索方案,但易用性更高;
Simhash的求相似度的过程:
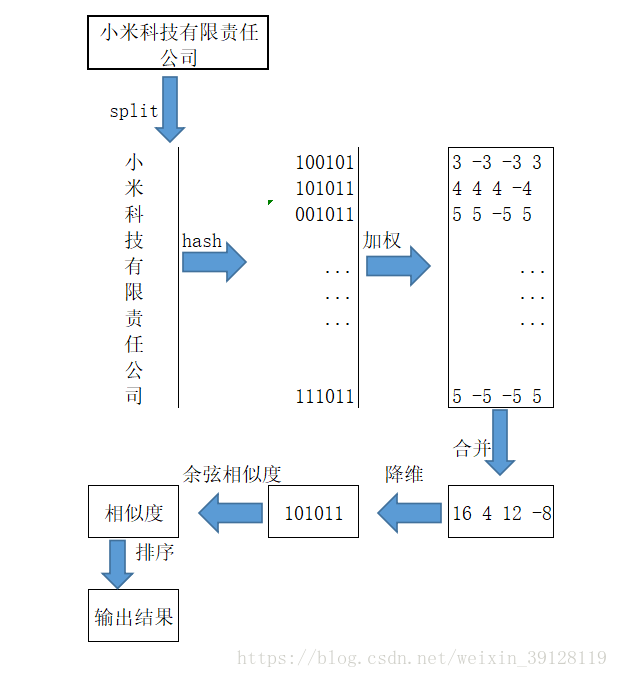
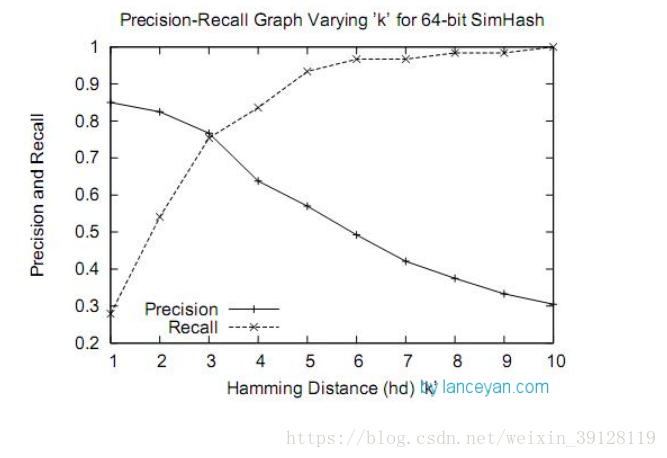
相似度的确认过程:海明距离与相似度。
Hbase + es方案:
参考资料:
- 海量数据相似度计算之simhash短文本查找 http://www.lanceyan.com/tag/simhash ;
- 基于mongodb+simhash集群 https://github.com/seomoz/simhash-cluster ;
- Elasticsearch之四种查询类型和搜索原理 https://blog.csdn.net/wangyunpeng0319/article/details/78218332
- Elasticsearch+Hbase实现海量数据秒回查询 https://blog.csdn.net/sdksdk0/article/details/53966430
- 基于HBase+ ElasticSearch的 海量交通数据实时存取方案设计 http://www.cww.net.cn/issues?id=405629&file=1
- ElasticSearch 与 Solr 的对比测试 http://simonlei.iteye.com/blog/1615600
- Elasticsearch实现原理分析 https://blog.csdn.net/zg_hover/article/details/77171014
- simHash 简介以及 java 实现 http://www.open-open.com/lib/view/open1375690611500.html