Hadoop是非常流行的大数据框架,Zookeeper提供了高效的协调服务,Hbase高度依赖zk,是基于HDFS系统,具有可伸缩性,非常适合存储复杂的数据结构,这三者作为一个系统整体,Kafka是作为缓存队列弥补Hbase写入性能较差的不足,让我们去走进它。
1、Zookeeper + Hadoop + Hbase大数据服务的架构图
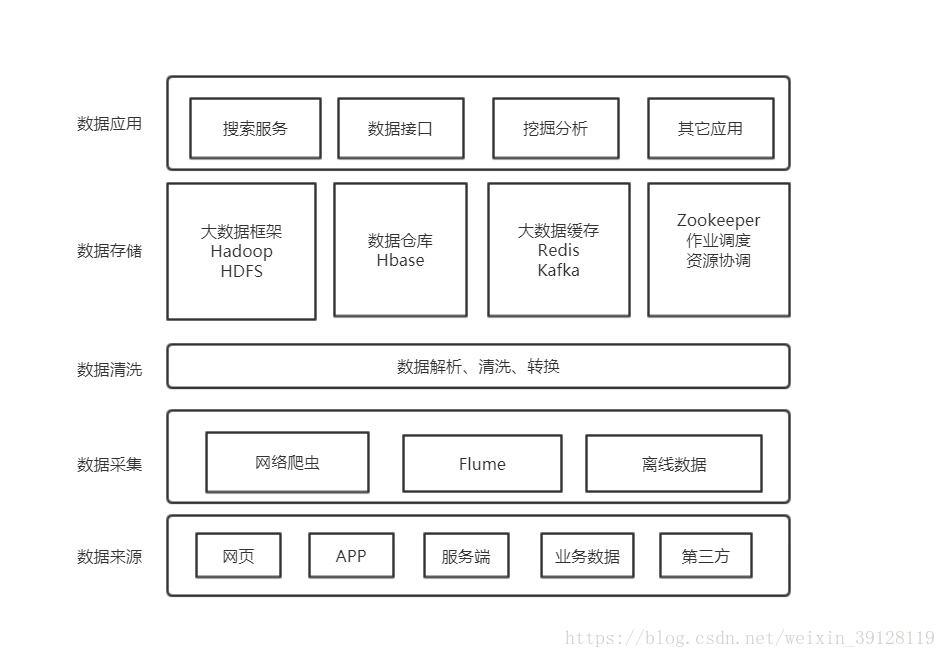
如上图所示,是我根据公司在实际大数据业务中所抽象出来的软件架构,其中比较清晰的描绘了zk、Hadoop和Hbase中的作用概况。
2、启动zk、Hadoop和Hbase服务
因为hbase 依赖 hadoop和zookeeper,所以启动顺序:zookeeper-->hadoop-->hbase
2.1、启动zookeeper
cd到zookeeper的/bin目录下,后台启动zookeeper,指令为:
nohup /application/zookeeper3_1/bin/zkServer.sh start >> ./zookeeper.file 2>&1 &
ps -ax | grep zookeerper如下启动成功:

2.2 启动Hadoop
cd到hmaster的Hadoop的/sbin目录下,启动Hadoop集群:
./start-all.sh
ps -ax| grep hadoop启动成功后:
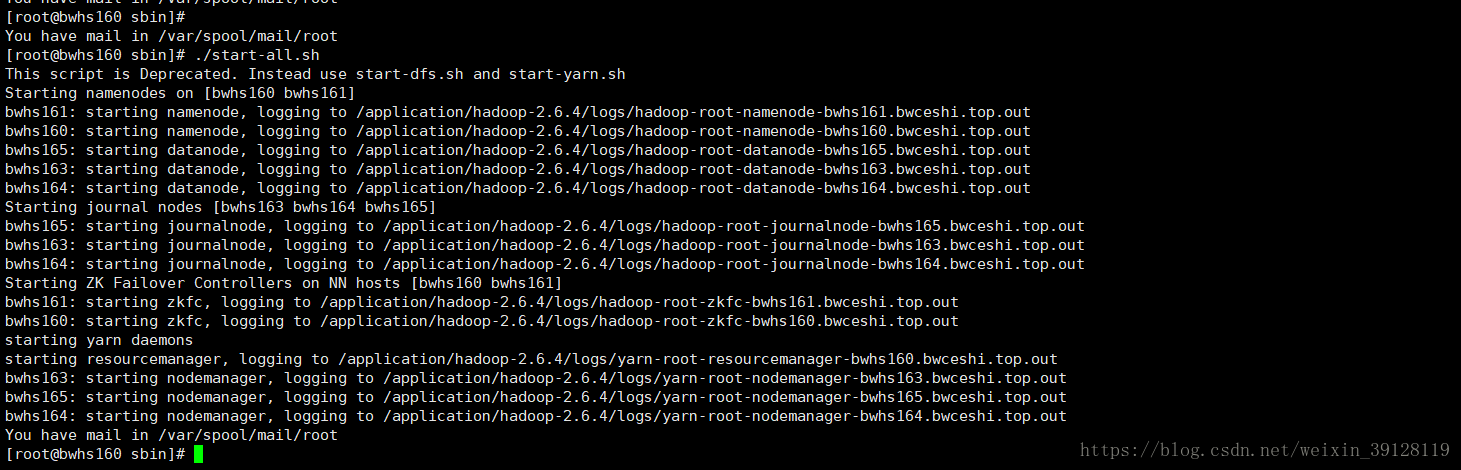
可以检查一下各hadoop节点的hadoop是否都起来了。
2. 3 启动hbase
cd到hbasean安装目录中的/bin目录下,启动Hbase
start-hbase.sh启动成功后,可以发现副节点有hregion 代表启动成功:

2.4 启动Kafka
Kafka集群作为消费模型,这里用作高并发数据的缓存。cd到Kafka的/bin目录下,分别后台启动Kafka集群的各节点:
./kafka-server-start.sh -daemon ../config/server.properties检查,启动成功:
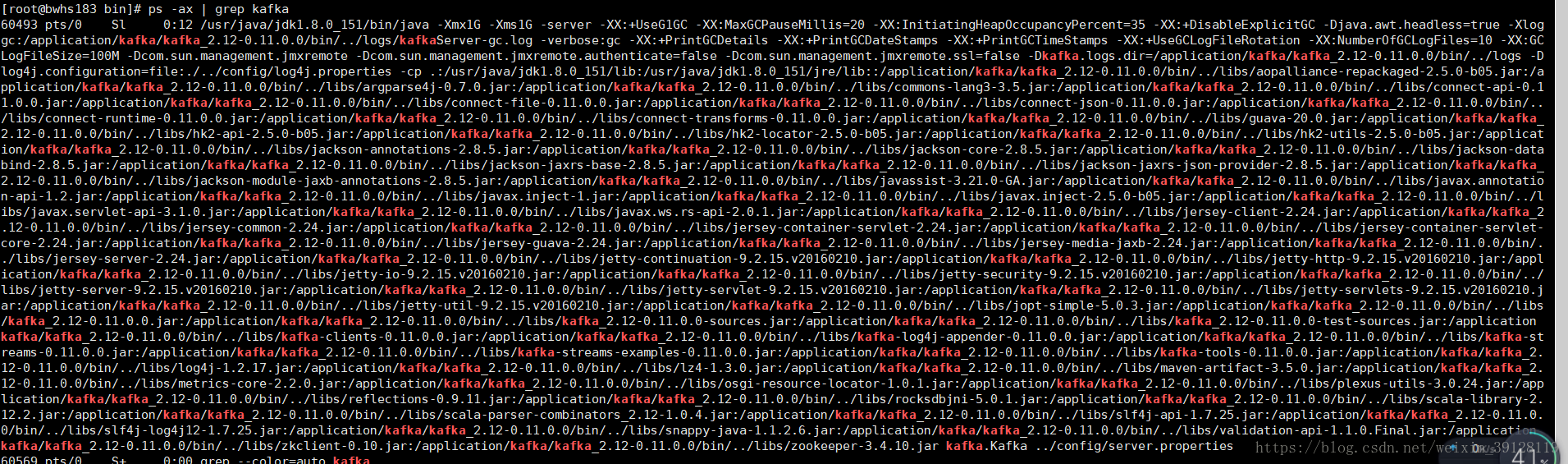
3、综述
在公司的实际业务中,各方面采集到的数据结构非常复杂,使用Hbase存储是一个非常优秀的方案,通过Hive非常方便的接入查询,但是Hbase数据写入性能较差,直接批量写入很容易导致Hbase挂掉,所以我们选用了Kafka集群消费模型作为缓存,最终呈现的软件架构就如上图所示。