Hadoop
MapReduce
split分片
hadoop将mapreduce的输入数据划分成等长的小数据块,称为输入分片。hadoop为每个分片构建一个map任务,并由该任务来运行用户自定义的map函数从而处理分片中的每条记录
分片是并行处理的,分片小,那么整个处理过程将获得更好的负载平衡;然后分片切的太小,那么管理分片的总时间和构建map任务的总时间将决定作业的执行时间。
通常,一个合理的分片大小趋于hdfs的一个块大小,默认128MB。因为它是确保可以存储在单个节点上的最大输入块大小。如果分片跨越两个数据块,那么对于任何一个hdfs节点,基本上不可能同时存储这两个数据块,因此分片中的部分数据需要通过网络传输到map任务运行的节点,使得效率降低
数据本地化
hadoop在存储有输入数据的节点上运行map任务,可以获得最佳性能
Map输出
map的任务将其输出写入本地磁盘,而非hdfs。因为map的输出是中间结果,该中间结果由reduce任务处理后才产生最终输出结果,而且一旦作业完成,map的输出结果就可以删除
Reduce输出
reduce任务并不具备数据本地化优势,单个reduce任务的输入通常来自所有mapper的输出。reduce输出存储在hdfs中,第一个复本存储在本地节点上,其他复本处于可靠性考虑存储在其他机架的节点中
Reduce数量
reduce任务的数量是独立指定的。如果有好多个reduce任务,每个map任务都会针对输出进行分区(partition),如对reduce个数hash,即为每个reduce任务建一个分区
MapReduce工作机制
有如下5个独立实体:
- 客户端,提交MapReduce作业
- YARN资源管理器,负责协调集群上计算机资源的分配
- YARN节点管理器,负责启动和监视集群中机器上的计算容器(container)
- MapReduce的application master,负责协调运行MapReduce作业的任务。它和MapReduce任务在容器中运行,这些容器由资源管理器分配并由节点管理器运行管理
- 分布式文件系统,用来与其他实体间共享作业文件
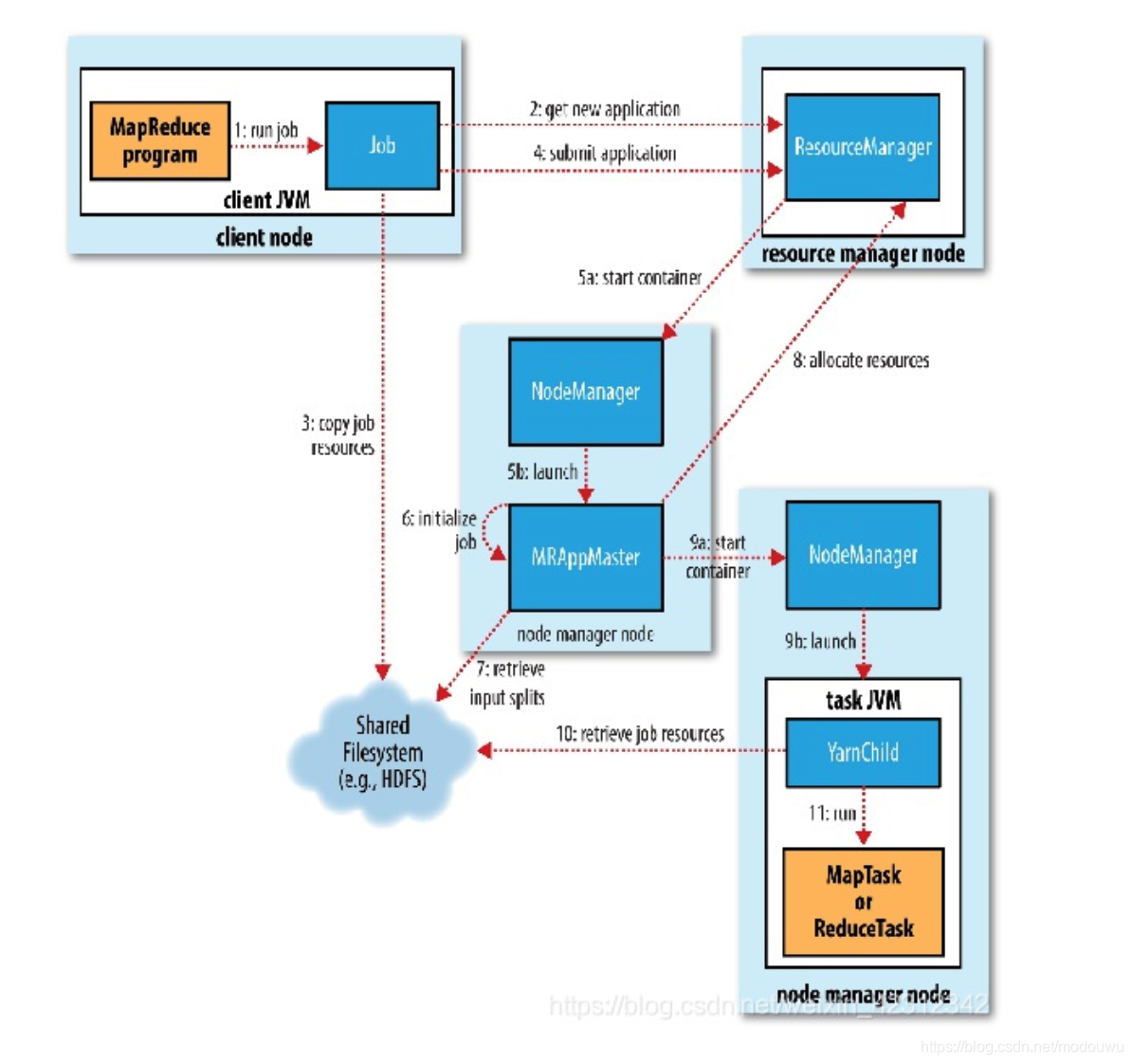
作业的提交
Job的submit()方法创建一个内部的JobSummiter实例,并且调用其submitJobInternal()方法。提交作业后,waitForCompletion()每秒轮询作业的进度,如果发现自上次报告后有改变,便把进度报告到控制台。作业完成后,如果成功,就显示作业计数器;如果失败,则错误回被记录到控制台
JobSummiter所实现的作业提交过程如下:
1⃣️向资源管理器请求一个新应用ID,用于MapReduce作业ID(步骤2)
2⃣️检查作业的输出说明。例如,如果没有指定输出目录或输出目录已存在,作业就不提交,错误抛给MapReduce程序
3⃣️计算作业的输入分片。如果输入分片无法计算,比如因为输入路径不存在,作业就不提交,错误抛给MapReduce程序
4⃣️将运行作业所需要的资源(包括作业JAR文件、配置文件和计算所得的输入分片)复制到一个以作业ID命名的目录下的共享文件系统中(步骤3)。作业JAR的复本较多(默认10),因此在运行作业的任务时,集群中有多个复本可供节点管理器访问
5⃣️通过调用资源管理器的submitApplication()方法提交作业(步骤4)
作业的初始化
1⃣️资源管理器收到调用它的submitApplication()消息后,便将请求传递给YARN调度器(scheduler)。调度器分配一个容器,然后资源管理器
在节点管理器的管理下在容器中启动application master的进程(步骤5a和5b)
2⃣️MapReduce作业的apllication master是一个Java应用程序,它的主类是MRAppMaster。由于将接受来自任务的进度和完成报告(步骤6),因此application master对作业的初始化是通过创建多个标记对象以保持对作业进度的跟踪来完成的。接下来,它接受来自共享文件系统的、在客户端计算的输入分片(步骤7)。然后对每一个分片创建一个map任务对象以及由mapreduce.job.reduces属性确定的多个reduce任务对象。任务ID在此时分配。
3⃣️最后,在任何任务运行之前,application master调用setupJob()方法设置OutputCommitter。FileOutputCommitter为默认值,表示将建立作业的最终输出目录及任务输出的临时工作空间
任务的分配
如果作业不适合作为uber任务(小作业)运行,那么application master就会为该作业中的所有map任务和reduce任务向资源管理器请求容器(步骤8)。首先为Map任务发出请求,该请求优先级要高于reduce任务的请求,因为所有的map任务必须在reduce的排序阶段能够启动前完成。直到有5%的map任务已经完成时,为reduce任务的请求才会发出。
map任务的请求有数据本地化局限,理想情况下,任务在分片驻留的同一节点上运行,可选情况是,任务可能是机架本地化的,即和分片在同一机架而非同一节点上运行。reduce任务能在集群中任意位置运行。
请求也为任务指定内存需求和CPU数。默认,每个map任务和reduce任务都分配1024MB的内存和一个虚拟内核,分别通过4个属性来设置mapreduce.map.memory.mb、mapreduce.reduce.memory.mb、mapreduce.map.cpu.vcores、mapreduce.reduce.cpu.vcoresp.memory.mb
任务的执行
一旦资源管理器的调度器为任务分配了一个特定节点上的容器,application master就通过与节点管理器通信来启动容器(步骤9a和9b)。该任务由主类为YarnChild的一个Java应用程序执行。在它运行任务之前,首先将任务需要的资源本地化,包括作业的配置、jar文件和所有来自分布式缓存的文件(步骤10)。最后,运行map任务或reduce任务(步骤11)
YarnChild在指定的JVM运行,因此用户定义的map或reduce函数(甚至YarnChild)中的任何缺陷不会影响到节点管理器
每个任务都能够执行搭建(setup)和提交(commit)动作,并由作业的OutputCommitter确定。对于基于文件的作业,提交动作将任务输出由临时位置搬移到最终位置。提交协议确保当推测执行被启用时,只有一个任务副本被提交,其他都被取消
进度和状态的更新
对于map任务,任务进度是已处理输入所占的比例
对于reduce任务,整个过程分为三部分,与shuffle的三个阶段相对应。
比如,如果任务已经执行了reducer一半的输入没那么任务的进度便是5/6,这是因为已经完成复制和排序阶段(每个占1/3),并且已经完成reduce阶段的一半(1/6)
当map或reduce任务运行时,子进程每隔3秒钟通过接口通信向application master报告进度和状态,application master会形成一个作业的汇聚视图
而客户端则每秒钟轮询一次application master以接收最新状态
失败
任务运行失败
任务挂起:一旦application master注意到已经有一段时间没有收到进度的更新,便会将任务标记为失败。在此之后,任务JVM进程将被自动杀死。任务被认为失败的超时时间间隔默认为10分钟
application master在一个任务尝试失败后,将重新调度该任务的执行,并且会视图避免在以前失败过的节点管理器上重新调度该任务。此外,如果一个任务失败过4此,将不会再重试
application master运行失败
application master失败最多尝试次数默认为2次。恢复过程如下,application master向资源管理器发送周期性的心跳,当application master失败,资源管理器在一个新的容器中开始一个新的master示例,新的application master将使用作业历史来恢复失败的应用程序所运行任务的状态,使其不必重新运行
客户端向application master轮询进度报告时,在作业初始化期间,客户端向资源管理器询问并缓存application master地址,其后查询时不必重载资源管理器。但如果application master运行失败,客户端就会在发出状态更新请求时超时,这时客户端会折回向资源管理器请求新application master地址
节点管理器运行失败
节点管理器每隔10分钟(yarn.resourcemanager.nm.liveness-monitor.expiry-interval-ms)向资源管理器发送心跳信息
shuffle
系统经过排序、将map输出作为输入传给reducer的过程称为shuffle
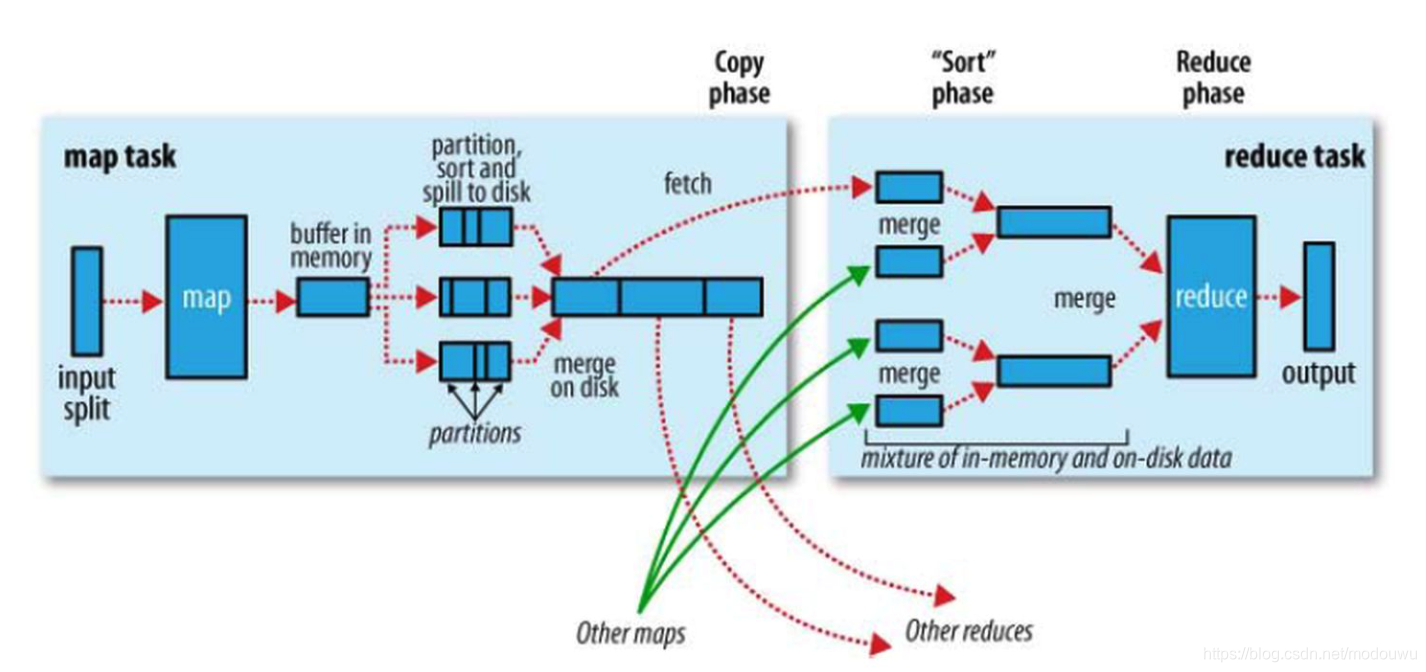
map端
每个map任务都有一个环形内存缓冲区用于存储任务输出,默认大小为100MB,一旦缓冲内容达到阈值(默认80%),一个后台线程便开始把内容溢出(spill)到磁盘,将缓冲区的内容写到mapreduce.cluster.local.dir属性在作业特定子>目录下指定的目录中。在溢出写磁盘过程中,map输出继续写到缓冲区,如果此期间缓冲区被填满,map会被阻塞直到写磁盘过程完成
在写磁盘前,线程首先根据数据要传的reducer把数据划分成相应的分区(partition)。在每个分区中,后台线程按键进行内存中排序,如果有一个conbiner函数,它就在排序后的输出上运行。运行combiner函数使得map输出结果更紧凑,因此减少写到磁盘的数据和传递给reducer的数据
在任务完成之前,溢出文件被合并成一个已分区且已排序的输出文件。默认一次最多合并10个文件。如果至少存在3个溢出文件,则combiner会在输出文件写到磁盘之前再次运行。[我的理解,溢出写到磁盘时第一次combiner,溢出文件已经在磁盘里,等map处理完记录,溢出文件会执行一次合并,生成输出文件再写到磁盘,这里会进行第二次combiner]。通过反复的combiner,使得最终的输出文件只有1或2个
将map输出写到磁盘过程中进行压缩是一个好主意,因为这样会写磁盘的速度更快、节约磁盘空间、并减少传给reducer的数据量
细节:
在map task执行时,它的输入数据来源于HDFS的block,当然在MapReduce概念中,map task只读取split,Split与block的对应关系可能是多对一,默认是一对一
当map task真正完成时,内存缓冲区中的数据也全部溢写到磁盘中形成一个溢写文件
reduce端
每个reduce task不断的通过RPC从JobTracker[书上说的是application master]那里获取map task是否完成的信息
copy阶段:reducer进程启动一些数据copy线程,通过HTTP请求Map task所在的task tracker获取map task的输出文件
merge阶段:Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用,当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是spill的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的spill文件,第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
Reducer的输入文件,不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的,当Reducer的输入文件已定,整个Shuffle才最终结束,然后就是Reducer执行,把结果放到HDFS上
Reducer在拷贝数据的时候只需拷贝与自己对应的partition中的数据
shuffle的map中间结果分发给reducer的策略
shuffle的时候,记录会根据key进行partition,相同的key被分配到一个分区。
map的输出文件溢出到磁盘时,溢出文件时分区的,根据reduce task个数而定,并且溢出文件内部是有序的
将多个溢出文件的每个分区合并(归并排序)后分发给对应的reduce task
默认的,map使用Hash算法、根据reduce的个数,对key值进行Hash计算,这样保证了相同key值的数据能够划分到相同的partition中,也保证了不同partition之间的数据量大致相当
MR计算框架会将不同的数据划分成不同的partition,数据相同的多个partition最后会分到同一个reduce节点上面进行处理,也就是说一类partition对应一个reduce
数据倾斜
就是大量的相同key被partition分配到一个分区里,map /reduce程序执行时,reduce节点大部分执行完毕,但是有一个或者几个reduce节点运行很慢,导致整个程序的处理时间很长,
这是因为某一个key的条数比其他key多很多(有时是百倍或者千倍之多),这条key所在的reduce节点所处理的数据量比其他节点就大很多,从而导致某几个节点迟迟运行不完
调优原则
总的原则是给shuffle尽可能多的提供内存空间。写map函数和reduce函数时尽可能少使用内存,尽量避免在函数中堆积数据
在map端,可以通过避免多次溢出写磁盘来获得最佳性能,一次是最佳情况
在reduce端,中间数据驻留在内存时,是最佳情况
推测执行
当一个任务运行比预期慢的时候,它会尽量检测,并启动一个相同的任务做备份,这就是所谓的“推测执行”。推测执行能减少作业的执行时间,并以集群效率为代价
首先,在中启动所有任务。为那些已经运行了一段时间(至少一分钟)且比作业中其他任务平均进度慢的任务启动推测任务。如果原始任务在推测性任务之前完成,那么推测任务将被终止,相反,如果推测性任务在原始任务之前完成,那么原始任务被终止。一个任务成功完成之后,任何正在运行的重复任务都将被终止
即使开启了,如果没有任务运行时间低于预期,那么可能不会有推测执行任务产生
outputCommitter作业完成时的文件移动
MapReduce使用一个提交协议来确保作业(job)和任务(task)都完全成功或失败。这个通过 OutputCommiter来实现。新版本 MapReduce API中,默认为FileOutputCommitter。它会创建最终的输出目录${mapreduce.output.fileoutputformat.outputdir},并为任务的输出创建一个临时文件夹 _temporary,作为最终输出目录的子目录
如果作业成功,则调用 commitJob() 方法。此方法会做临时文件的清理(cleanupJob()),并在最终输出目录中创建名为_SUCCESS的文件,表示Job成功执行完成。若是Job 执行失败,则被状态对象调用abortJob(),默认会调用 cleanupJob() 的方法,对临时文件进行清理
如果task成功执行,并且有输出,则会调用commitTask() 方法,(默认的实现为)将临时目录下的输出文件移动到最终目录(mapreduce.output.fileoutputformat.outputdir)。若是执行失败,则调用abortTask(),删除任务输出的临时目录及文件
执行框架会保证一个task在有多次尝试的情况下,仅有一个task会被提交
在 Hadoop 2 中,commitTask 会将 task 的输出文件从 task 的临时目录移动到 job 的临时目录下。
在所有 task 任务完成后,commitJob 将生成的数据从 job 的临时目录移动到最终的 job 目录下。这个工作在 spark 中由 driver 完成
mapreduce的类型与格式
默认的partitioner是HashPartitioner,它对每条记录的键进行哈希操作以决定该记录应该属于哪个分区。每个分区由一个reduce任务处理,所以分区数等于作业的reduce任务个数
map任务的数量等于输入文件被划分成的分块数,这取决于输入文件的大小以及输入文件块的大小(如果此文件在HDFS中)
输入分片
一个输入分片就是一个由单个map操作来处理的输入块。客户端先调用方法计算分片,然后将他们发送到application master,application master使用其存储位置信息来调度map任务map任务从而在集群上处理分片数据。map任务处理分片,得到分片的一个迭代器
小文件
FileInputFormat生成的分块是一个文件或该文件的一部分,即一个块不能包含两个文件的数据。如果有很多小文件,那么就会有很多map任务,造成很多额外的开销
Hadoop集群
回收站
hadoop文件系统的文件被删除后,会先转移到回收站中,并保留一段时间。由core-site.xml里的fs.trash.interval设置。默认为0,表示回收站无效
当回收站被启用时,每个用户都有独立的回收站目录,即:home目录下的.Trash目录。恢复文件,只需要在.Trash的子目录中找到文件毛病移出.Trash目录
安全
ldap
LDAP是轻量目录访问协议,协议就是标准,并且是抽象的。使用树状结构,底层是B/B+树数据结构,数据存储在叶子节点上。
AD(Active Directory)是微软出的一套实现,可以把LADP理解成存储数据的数据库。LDAP也是有client端和server端, server端是用来存放资源,client端用来操作增删改查等操作
Kerberos
kerberos 主要是用来做网络通信时候的身份认证。
kerberos存了所有主体(client/TGT/service)的帐号和密码,因此也有一个数据库
相关概念
-
principal
认证的主体,简单来说就是”用户名” -
realm
realm有点像编程语言中的namespace ,realm可以看成是principal的一个”容器”或者”空间”。相对应的,principal的命名规则是”what_name_you_like@realm”。
在kerberos, 大家都约定成俗用大写来命名realm, 比如”EXAMPLE.COM” -
credential
credential是“证明某个人确定是他自己/某一种行为的确可以发生”的凭据。在不同的使用场景下, credential的具体含义也略有不同:
对于某个principal个体而言,他的credential就是他的password。
在kerberos认证的环节中,credential就意味着各种各样的ticket
这个principal的对应物可以是service,可以是host,也可以是user,对于Kerberos来说,都没有区别。
Kdc(Key distribute center)知道所有principal的secret key,但每个principal对应的对象只知道自己的那个secret key。 通过下面的博客可以知道,接入了kerberos的服务也会有服务id-服务密钥,TGS-TGS密钥,而不仅仅是存了client-client密钥
架构
一个kdc server包含
- krb5-admin-server: kdc管理员程序,可以让使用者远程管理kdc数据库。
- krb5-kdc:kdc主程序
- krb5-user: kerberos的一些客户端命令,用来获取、查看、销毁ticket等等
配置包含:
- /etc/krb5.conf:kdc配置
- /etc/krb5.keytab:用户的密钥存放的文件
kinit
kinit -k -t /etc/krb5.keytab test-client/[email protected]
使用kinit工具来进行服务器认证,它会向/etc/krb5.conf中指定的kdc server来发送请求。
如果TGT请求成功,你就可以用klist看到它
原理参考:
https://blog.csdn.net/sky_jiangcheng/article/details/81070240
https://blog.csdn.net/nosqlnotes/article/details/79495978
https://blog.csdn.net/dog250/article/details/5468741
Sentry
Cloudera公司发布的一个Hadoop安全开源组件 ,提供了细粒度级、基于角色的授权.
优点:
Sentry支持细粒度的hdfs元数据访问控制,对hive支持列级别的访问控制
Sentry通过基于角色的授权简化了管理,将访问同一数据集的不同特权级别授予多个角色
Sentry提供了一个统一平台方便管理
Sentry支持集成Kerberos
Sentry 组件
- Sentry Server
Sentry的RPC服务管理授权元数据。它支持安全检索和操作元数据的接口。在CDH5.13及更高版本中,您可以配置多个Sentry服务以实现高可用性 ,内部含数据库 - Data Engine
这是一个数据处理应用程序,比如Hive或Impala,它们需要授权访问数据或元数据资源。数据引擎(data engine)加载Sentry插件,拦截所有客户端访问资源的请求并将其路由到Sentry插件进行验证 - Sentry Plugin
Sentry plugin在data engine中运行。它提供了操作存储在Sentry Server中的授权元数据的接口,包括授权策略引擎,该引擎使用从服务器检索的授权元数据来评估访问请求
sentry与hadoop集成
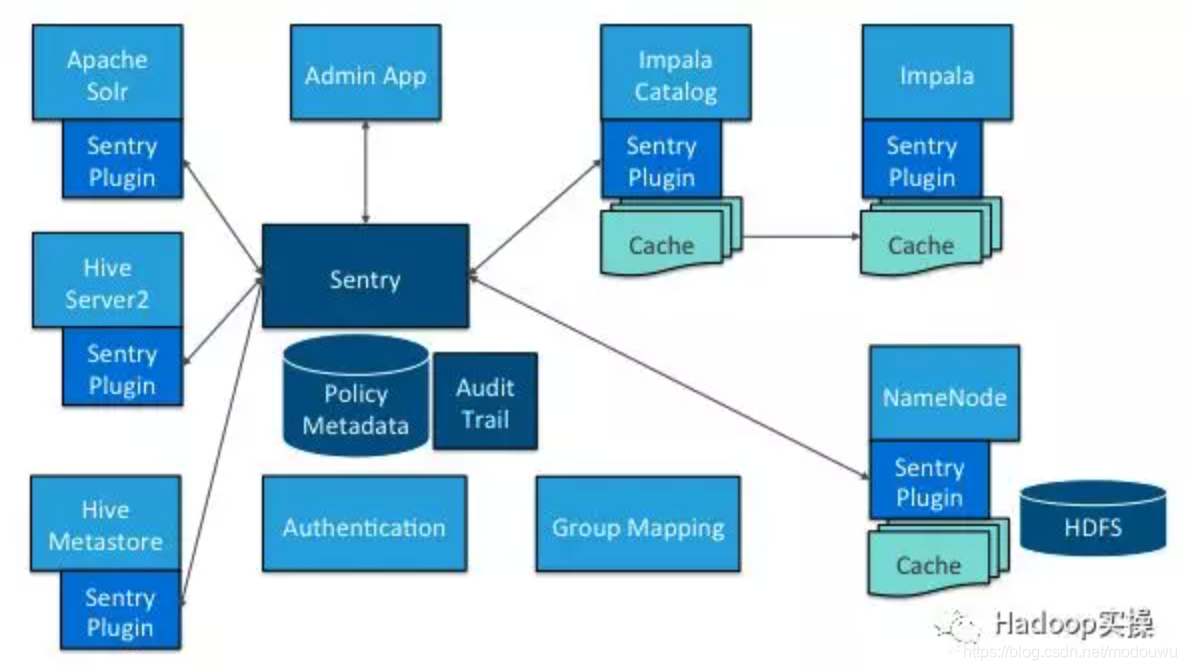
Apache Sentry可以与多个Hadoop组件一起工作。从本质上讲,您拥有存储授权元数据的Sentry Server,并提供API工具以安全地检索和修改此元数据
Sentry Server主要用于管理元数据。实际的授权决策由在Hive或Impala等数据处理应用程序中运行的策略引擎判断。每个组件都加载Sentry插件,其中包括用于处理Sentry服务的客户端和用于验证授权请求的策略引擎
hive和sentry

hdfs和sentry

对于hadoop
hadoop服务器的账户、LDAP的账户、kerberos的账户他们三者应该是同步的,怎么保证呢?
1)用户使用kerberos,会传入用户名即Principal,访问HDFS时,Hadoop 可以通过配置 hadoop.security.auth_to_local,将 Principal 映射为系统中的 OpenLDAP 的用户。用户注册LDAP时,平台会为每一个新注册的用户生成 Principal 以及相对应的 Keytab 文件。这样,用户就会使用Principal对应的keytab文件进行认证
2)hadoop可以使用LdapGroupsMappings 同步 LDAP 创建的用户和用户组,这样当我们在 LDAP 中添加用户和组时,会自动同步到 Hadoop 集群内的所有机器上
之前我们提数做项目帐号的时候,也是先在LDAP创建组,并在组下创建帐号,然后在hue执行命令,给角色授权,并把角色赋给组,这样用户就有了组的权限
Create database risk_control_dw_test;
Create database risk_control_dw;
Create role risk_control_dw_test;
Create role risk_control_dw;
grant role risk_control_dw to group risk_control_dw;
Grant select on database risk_control_dw_test to role risk_control_dw_test
Grant all on database dw_test to role risk_control_dw;
Grant all on database risk_control_dw_test to role risk_control_dw;
Grant all on database risk_control_dw to role risk_control_dw;
LDAP 用来做账号管理,Kerberos作为服务认证。
Kerberos只有账号密码概念,而无帐号管理的概念
hdfs
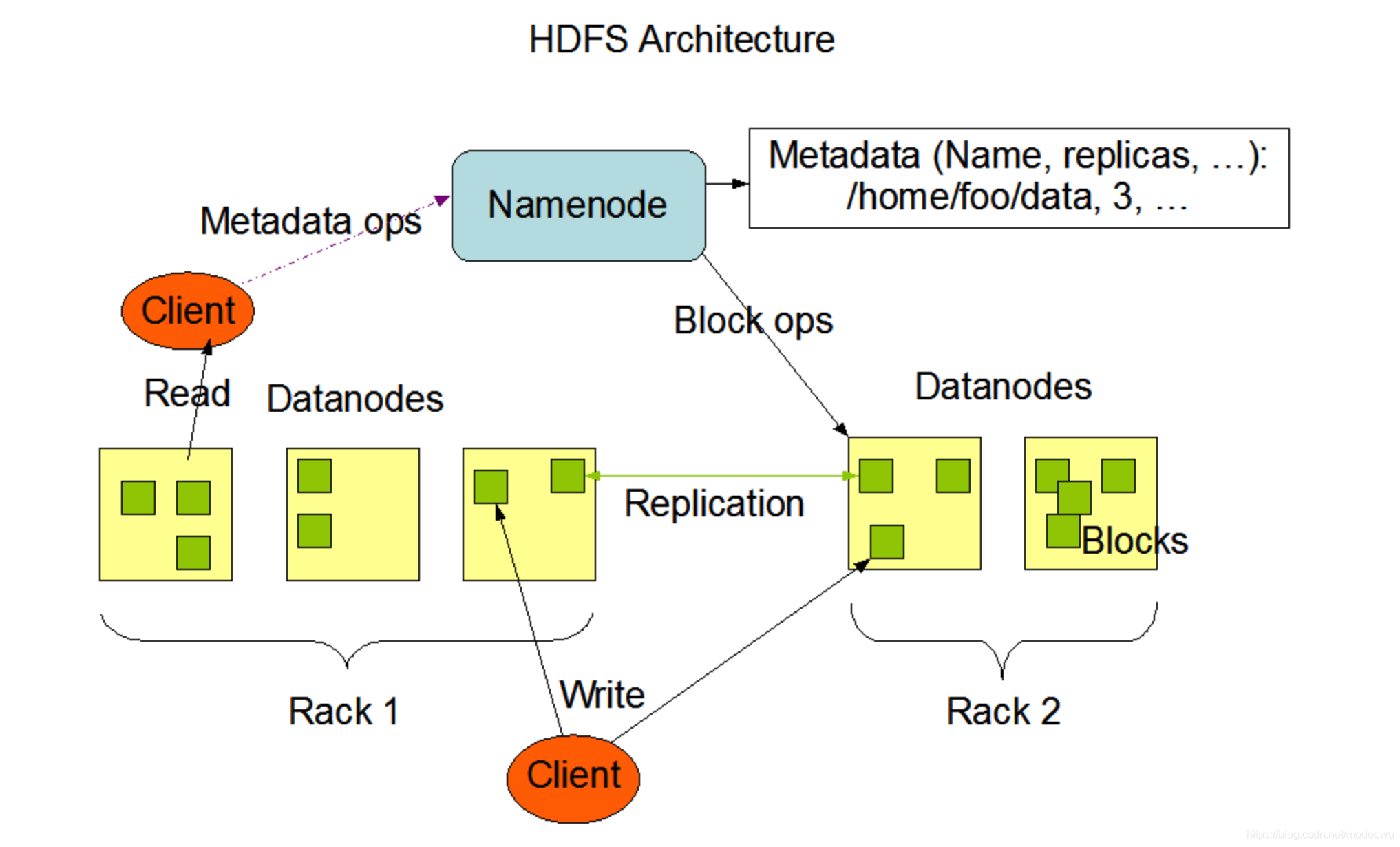
特点
1⃣️由于namenode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于namenode的内存容量
2⃣️hdfs中的文件只支持单个写入者,而且写操作总是以追加的方式写在文件末尾。它不支持多个写入者的操作,也不支持在文件的任意位置进行修改
概念
数据块
磁盘的数据块默认512字节,是磁盘进行数据读写的最小单位
hdfs的数据块默认128MB。hdfs上的文件也被划分为块大小的多个分块,作为独立的存储单元
namenode datanode
hdfs集群有两类节点以管理节点-工作节点模式运行,即一个namenode(管理节点)和多个datanode(工作节点)。
namenode管理文件系统的命名空间。它维护着文件系统树及整棵树内所有的文件和目录。这些信息以两个文件形式永久保存在本地磁盘上:命名空间镜像文件和编辑日志文件。namenode也记录着每个文件中各个块所在的数据节点信息,但它并不永久保存块位置信息,因为这些信息会在系统启动时根据数据节点信息重建
datanode是文件系统的工作节点。他们根据需要存储并检索数据块,并定期向namenode发送他们所存储的块的列表。datanode中的每个文件块都有一个关联的带有.meta后缀的元数据文件。
HDFS的一个数据块,都对应磁盘上的一个真实存储文件么?比如某个文件250MB,块大小为100MB,那么在磁盘上就有三个文件,两个100MB,一个50MB一共三个块?
是的
数据流
文件读取

1)客户端通过调用DisstrbutedFileSystem的open()方法来打开要读取的文件
2)DistributeFileSystem通过远程过程调用rpc来调用namenode,来确定文件起始块的位置。对于每个块,namenode返回存有该块副本的datanode地址。此外,这些datanode根据他们与客户端的距离来排序
3)DistributeFileSystem类返回一个FSDataInputStream对象给客户端以便读取数据。FSDataInputStream类转而封装DFSInputStream对象,该对象管理着datanode和namenode的I/O
4)客户端对这个输入流调用read()方法,存储着文件起始几个块的datanode地址的dfsInputStream随即连接距离最近的文件中第一个块所在的datanode。通过对数据流反复调用read()方法,可以将数据从datanode传输到客户端
5)到达末端时,DFSInputStream关闭与该datanode的连接,然后寻找下一个块的最佳datanode。所有这些对于客户端都是透明的,在客户看来它一直在读取一个连续的流
6)客户端从流中读取数据时,块是按照打开DFSInputStream与datanode新建连接的顺序读取的。它也会根据需要询问namenode来检索下一批数据块的datanode位置。一旦客户端完成读取,就对FSDataInputStream低矮用close()方法
7)在读取时,如果DFSInputStream与datanode通信时遇到错误,会尝试从这个块另一个最邻近的datanode读取数据。同时会记住故障datanode,保证以后不会读取该节点上后续的块。DFSInputStream也会通过校验和确认从datanode发来的数据是否完整。如果发现有损坏的块,DFSInputStream会试图从其他datanode读取复本,也会将笋块的块通知给namenode
文件写入
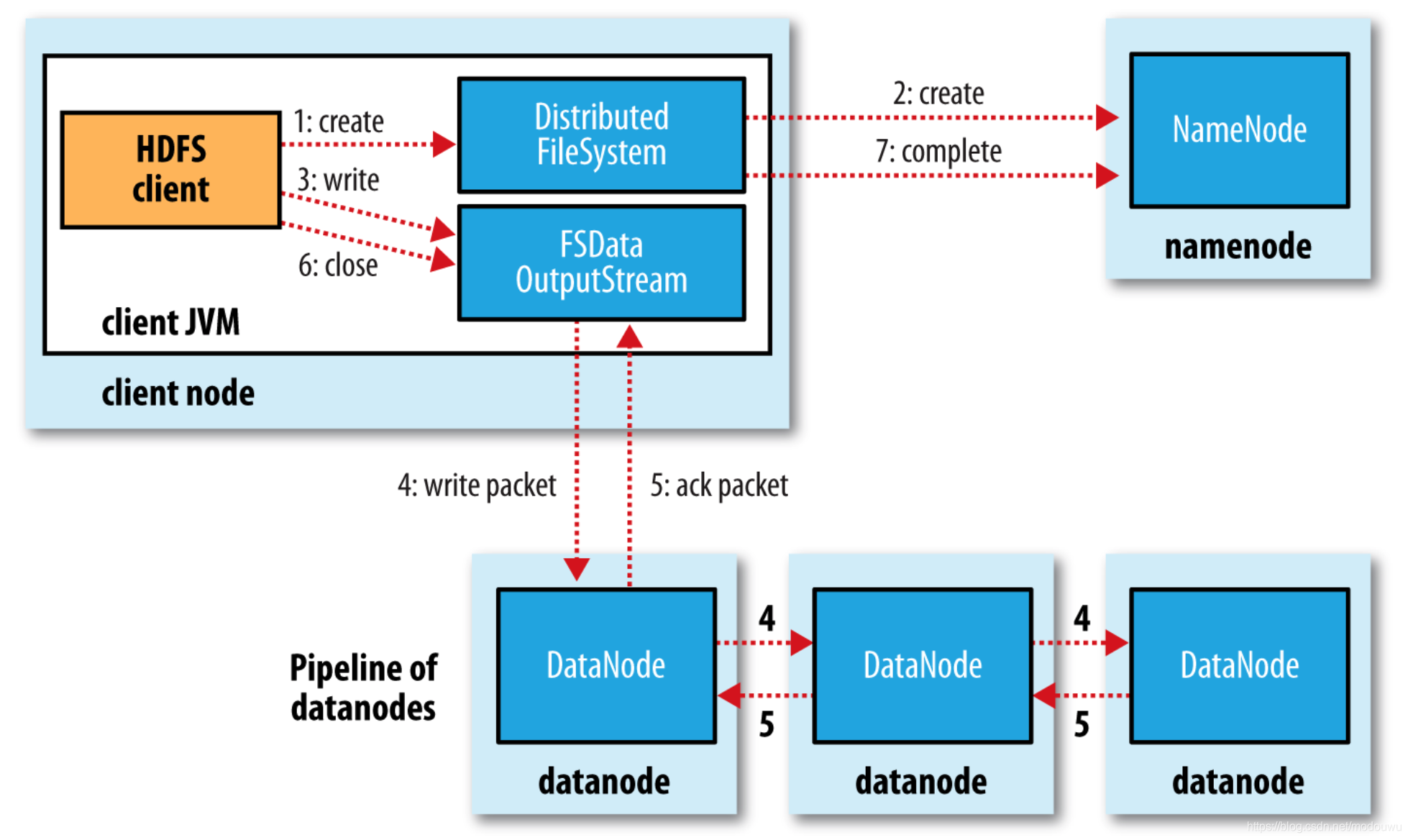
1)客户端通过对DistributedFilesystem对象调用create()来新建文件
2)DistributedFileSystem对namenode创建一个RPC调用,在文件系统的命名空间中新建一个文件,此时该文件中还没有相应的数据块。这里会进行重复性校验、权限校验。DistributedFileSystem向客户端返回一个FSDataOutputStream对象,FSDataOutputStream封装一个DFSOutputStream对象,该对象负责处理datanode和namenode之间的通信
3)写入数据时,DFSOutputStream将它分成一个个的数据包,并写入内部队列,称为数据队列。DataStreamer处理数据队列,它挑选出合适的一组datanode,并据此要求namenode分配新的数据块。这一组datanode构成一个管线
4)DataStreamer将数据包流式传输到管线中第一个datanode,该datanode存储数据包并将它发送到管线中的第二个datanode,以此类推
5)DFSOutputStream也维护着一个内部数据包队列来等待datanode收到确认回执,称为确认队列。收到管道中所有datanode确认信息后,该数据包才会从确认队列删除
6)如果任何datanode发生故障,则首先关闭管线,为存储在另一个正常datanode的当前数据块执行一个新的标识,并将标识传给naoenode,以便故障datanode在恢复后可以删除存储的部分数据块。从管线中删除故障datanode,基于两个正常datanode构建一条新的管线。余下数据块写入管线中正常的datanode。namenode注意到复本量不足时,会在另一个节点上创建一个新复本。通常只要写入一个datanode成功,写操作就成功,这个块可以在集群中异步复制,直到达到目标复本数量
7)namenode的complete是为了异步复制复本
yarn
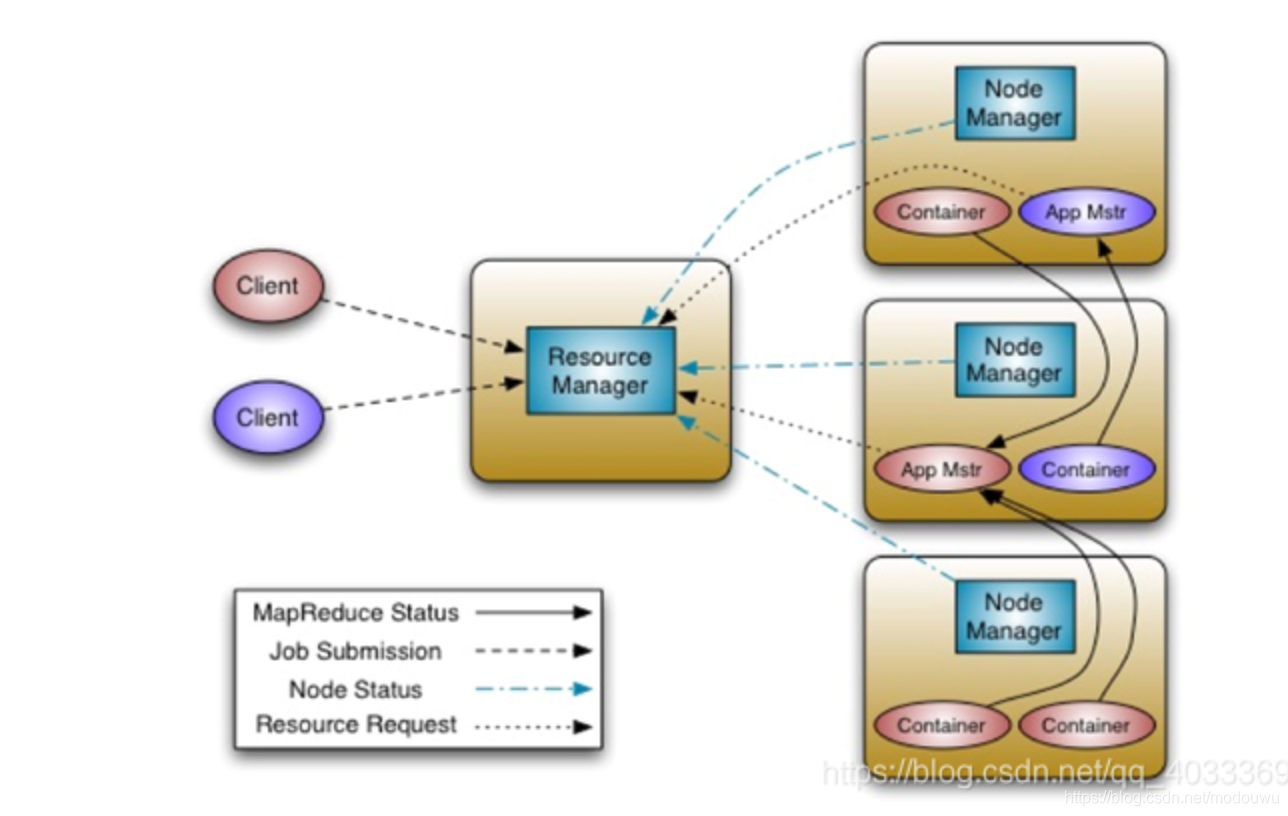
yarn应用运行机制
角色
1.资源管理器:管理集群资源使用
2.节点管理器:运行在集群中所有节点上且能够启动和监控容器
3.容器:用于执行特定应用程序的进程,每个容器都有资源限制(cpu、内存等)
应用运行流程
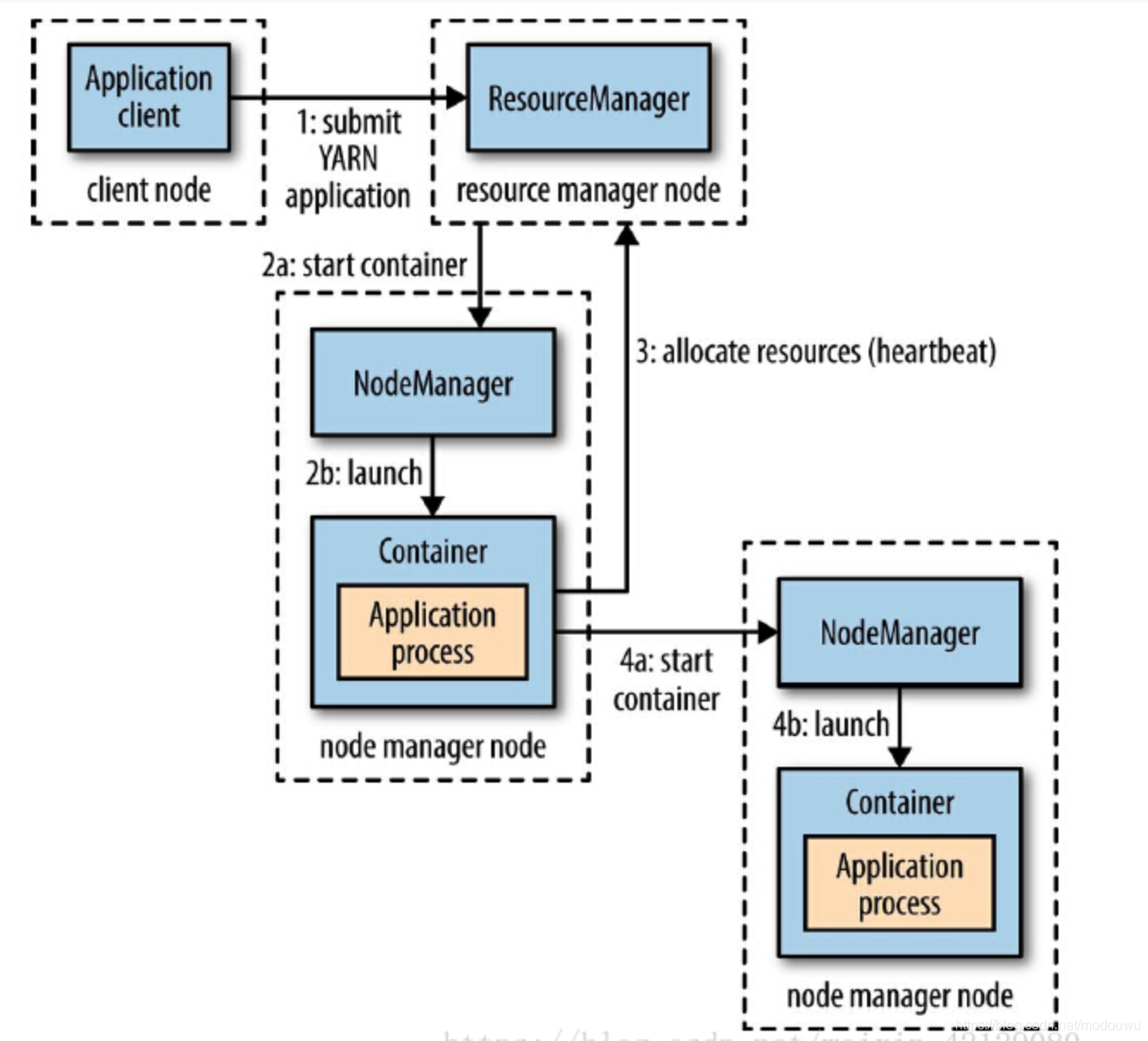
1.客户端联系资源管理器、要求它运行一个application master进程
2.资源管理器找到一个合适的节点管理器,启动application master
3.application master运行依赖于应用自身。有可能简单运行一个计算,并将结果返回给客户端,也有可能向资源管理器请求更多的容器,以便运行分布式计算
本地化资源请求
本地化对于确保分布式数据处理算法高效使用集群带宽非常重要。通常,当启动一个容器用于处理HDFS数据块时,应用会向这样的节点申请容器:存储该数据块三个复本的节点,或是存储这些复本的机架中的一个节点。如果都申请失败,则申请集群中任意节点
yarn中的调度
三种调度器:FIFO调度器、容量调度器、公平调度器
容量调度器
容量调度器允许多个组织共享一个hadoop集群,每个组织可以分配到全部集群资源的一部分。每个组织被配置一个专门的队列,每个队列被配置为可以使用一定的集群资源。队列可以进一步按层次划分,这样每个组织内的不同用户能够共享该队列所分配的资源。一个队列内,使用FIFO调度策略进行调度
公平调度器
两个用户A和B,分别拥有自己的队列。A启动一个作业,在B没有需求时,A会分配到全部可用的资源;当A的作业仍在运行时,B启动一个作业,一段时间后,每个作业都用到了一半的集群资源。这时。如果B启动第二个作业且其他作业仍在运行,那么第二个作业将和B的其他作业共享资源,因此B的每个作业将占用四分之一的集群资源,而A仍继续占用一半的集群资源。最终结果就是资源在用户之间实现了公平共享
hadoop I/O
压缩和输入分片
以一个存储在HDFS文件系统中且压缩前大小为1GB的文件为例,如果HDFS的块大小设置为128MB,那么该文件将被存储在8个块中,把这个文件作为输入数据的MapReduce作业,将创建8个输入分片,其中每个分片作为单独的map任务的输入被独立处理
假设文件经过gzip压缩,且压缩后大小仍为1GB。与之前一样,HDFS将这个文件保存为8个数据块。gzip的压缩算法将数据存储在一系列连续的压缩块中,问题在于每个块的起始位置并没有以任何形式标记,所以读取时无法从数据流的任意当前位置前进到下一个块的起始位置读取下一个块,从而与整个数据流同步。因此,gzip不支持文件切分
此时mapreduce会这样处理:只启用一个map任务处理8个HDFS块,启动大多数块并没有存储在该map节点上。而且map任务数越少,作业粒度就越大,运行时间会更长。因此对于大文件,最好使用支持切分的压缩格式
如何选择压缩格式
效率从高到低:
1⃣️使用容器文件格式,如avro orc parquet等
2⃣️使用支持切分的压缩格式,如bzip2 通过索引实现切分的LZO
MapReduce开发
作业、任务和任务尝试ID
应用ID:应用ID=资源管理器开始时间+唯一标识此应用的由资源管理器维护的增量计数器。例如:application_1410450250506_0003表示是资源管理器运行的第三个应用(0003,应用ID从1开始计数),资源管理器开始时间戳为1410450250506
作业ID:将应用ID的application前缀替换为job即可得到相应的作业id
任务ID:任务属于作业,将作业ID的job前缀替换为task前缀,然后加上一个后缀表示是作业里的哪个任务。例如:task_1410450250506_0003_m_00003表示ID为job_1410450250506_0003的作业的第4个map任务。作业的任务ID在作业初始化时产生,因此,任务ID的顺序不必是任务执行的顺序
任务尝试ID:由于失败或推测执行,任务可以执行多次,任务尝试ID用来标识任务执行的不同实例。例如:attempt_1410450250506_0003_m_00003_0表示正好在运行的task_1410450250506_0003_m_00003任务的第一个尝试。任务尝试在作业运行时根据需要分配,所以,它们的顺序代表被创建运行的先后顺序
运行
每个reducer产生一个输出文件,因此,在max-temp目录中会有30个部分文件,命名为part-00000到part-00029
列式存储格式
Parquet
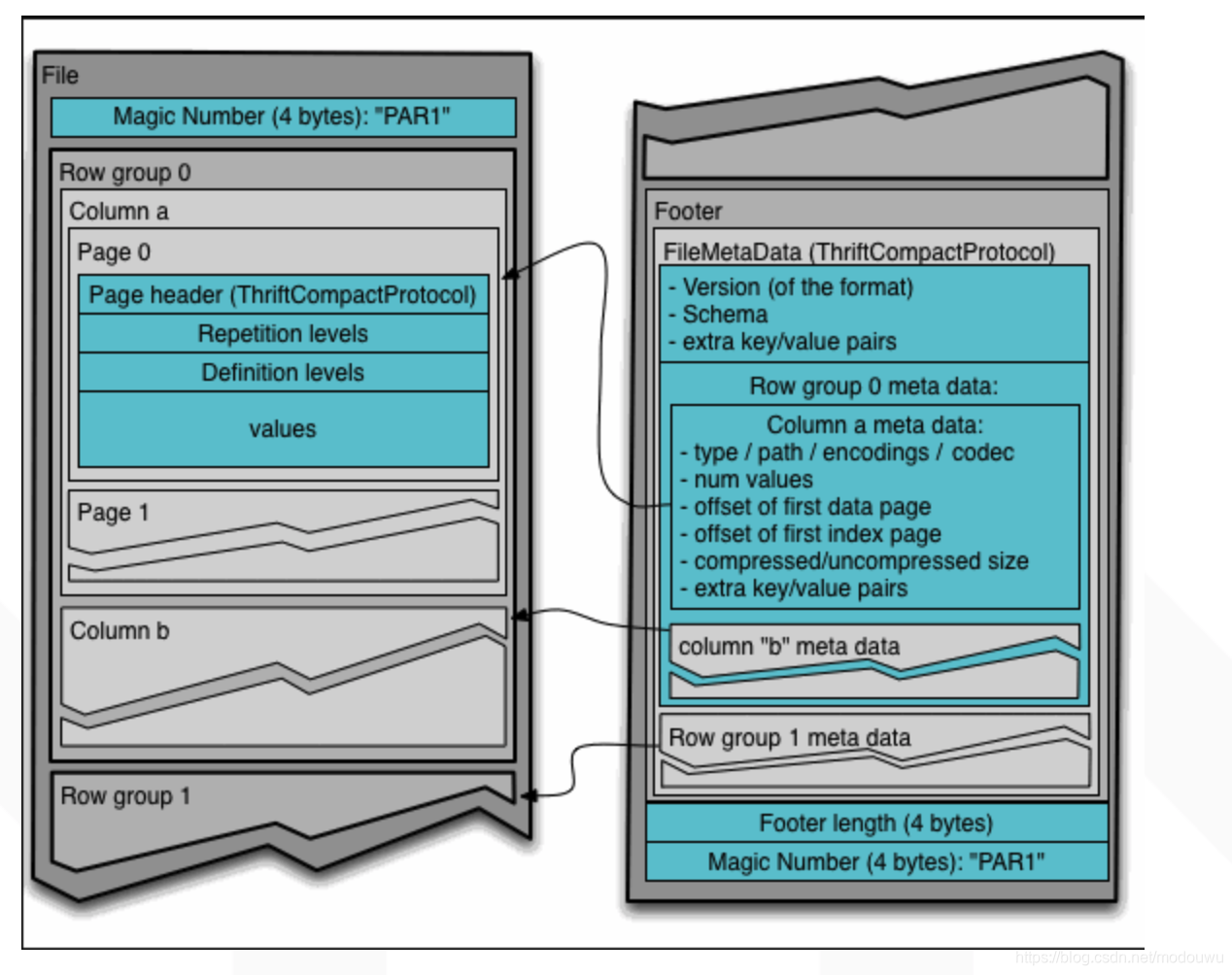
文件结构
Parquet文件是以二进制方式存储的,是不可以直接读取和修改的,也就是不支持update
1⃣️行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,Parquet读写的时候会将整个行组缓存在内存中。通常按照HDFS的Block大小设置行组的大小
2⃣️列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。不同的列块可能使用不同的算法进行压缩
3⃣️页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式
上图展示了一个Parquet文件的结构,一个文件中可以存储多个行组,文件的首位都是该文件的Magic Code,用于校验它是否是一个Parquet文件,Footer length存储了文件元数据的大小,通过该值和文件长度可以计算出元数据的偏移量,文件的元数据中包括每一个行组的元数据信息和当前文件的Schema信息。除了文件中每一个行组的元数据,每一页的开始都会存储该页的元数据
数据访问
Parquet每次会扫描一个Row Group的数据,然后一次性得将该Row Group里所有需要的列的Cloumn Chunk都读取到内存中,每次读取一个Row Group的数据能够大大降低随机读的次数,除此之外,Parquet在读取的时候会考虑列是否连续,如果某些需要的列是存储位置是连续的,那么一次读操作就可以把多个列的数据读取到内存
在数据访问的过程中,Parquet还可以利用每一个row group生成的统计信息进行谓词下推,这部分信息包括该Column Chunk的最大值、最小值和空值个数。通过这些统计值和该列的过滤条件可以判断该Row Group是否需要扫描。另外Parquet未来还会增加诸如Bloom Filter和Index等优化数据,更加有效的完成谓词下推
可以被impala查询
ORC
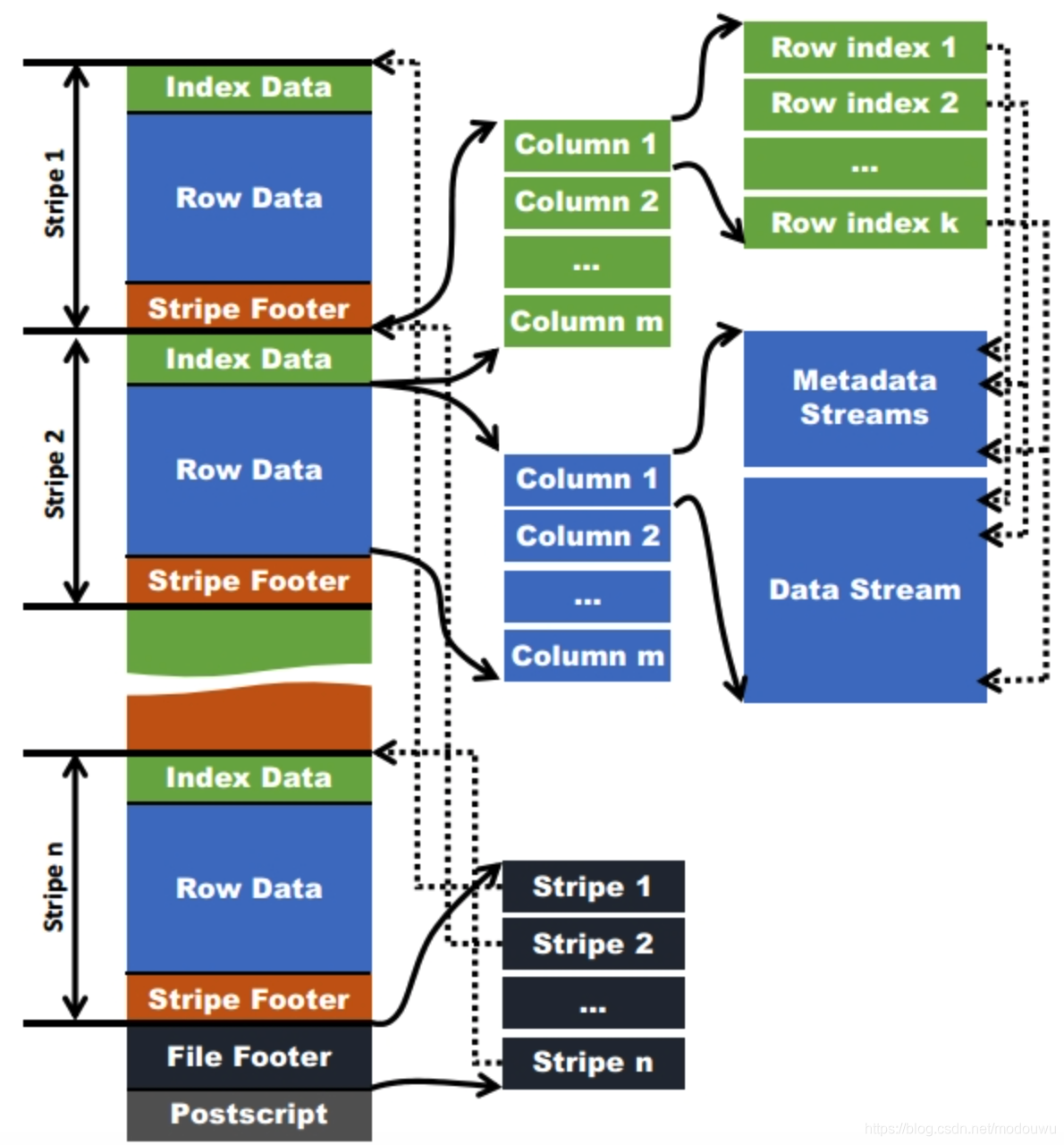
文件结构
1⃣️stripe:stripe是ORC文件的主体,在ORC格式的hive表中,记录首先会被横向的切分为多个stripes,然后在每一个stripe内数据以列为单位进行存储,所有列的内容都保存在同一个文件中。还记的上文提到RCfile之中的Row Group的大小为4MB,而stripe的大小膨胀到了250MB。(果真还是越大越好么)至于为什么选择250MB这个大小的用意也很明显,是为了与底层HDFS的块大小契合,来减少MapReduce处理时可能会带来的通信损耗。 stripe也分为具体三个部分:
(1)Index Data:存储每行的统计数据,默认是10000行的大小。它也是按字段来列式存储的,即先存column1的该stripe的所有行的索引信息,然后存column2的…
(2)Index Data在Strip的最前面,因它们只在使用谓词向下推或读者寻找特定行时加载。(这里主要利用的是统计信息与布隆过滤器实现的)
(3)Row Data:实际存储数据的单元,利用列存原理,对不同列可以实现不同压缩方案,所有的列数据可以组成行数据。当字段类型都被解析后,会由这些字段类型组成一个字段树,只有树的叶子节点才会保存表数据,这些叶子节点中的数据形成一个数据流,如上图中的Data Stream。为了使ORC文件的reader更加高效的读取数据,字段的metadata会保存在Meta Stream中
2⃣️File Footer:部分包含Row data的布局、类型信息、行数和每个列的统计信息。通过这块可以筛选出需要读取列的数据
3⃣️PostScript:这块保存的内容就是ORCFile的元数据了,包括了使用的压缩类型,各个数据的长度等。由于HDFS只支持Append的操作,所以,元数据放在文件的末尾是便于修改的
在ORC文件中保存了三个层级的统计信息,分别为文件级别、stripe级别和row group级别的,他们都可以用来根据Search ARGuments(谓词下推条件)判断是否可以跳过某些数据,在统计信息中都包含成员数和是否有null值,并且对于不同类型的数据设置一些特定的统计信息
使用ORC文件格式时,用户可以使用HDFS的每一个block存储ORC文件的一个stripe。对于一个ORC文件来说,stripe的大小一般需要设置得比HDFS的block小,如果不这样的话,一个stripe就会分别在HDFS的多个block上,当读取这种数据时就会发生远程读数据的行为。如果设置stripe的只保存在一个block上的话,如果当前block上的剩余空间不足以存储下一个strpie,ORC的writer接下来会将数据打散保存在block剩余的空间上,直到这个block存满为止。这样,下一个stripe又会从下一个block开始存储
数据访问
读取ORC文件是从尾部开始的,第一次读取16KB的大小,尽可能的将Postscript和Footer数据都读入内存。文件的最后一个字节保存着PostScript的长度,它的长度不会超过256字节,PostScript中保存着整个文件的元数据信息,它包括文件的压缩格式、文件内部每一个压缩块的最大长度(每次分配内存的大小)、Footer长度,以及一些版本信息。在Postscript和Footer之间存储着整个文件的统计信息(上图中未画出),这部分的统计信息包括每一个stripe中每一列的信息,主要统计成员数、最大值、最小值、是否有空值等。
接下来读取文件的Footer信息,它包含了每一个stripe的长度和偏移量,该文件的schema信息(将schema树按照schema中的编号保存在数组中)、整个文件的统计信息以及每一个row group的行数
问题:
如果改字段名,此时需要级联更新历史分区,为的是更改HDFS上namenode的历史分区元数据信息。然而更新完后,parq文件select的新字段名为null,因为历史数据文件本身的元数据还是旧的,而orc则可以直接使用新字段名。如果原来是parq就是有改字段名的需求,那么备份数据,然后删表重建,然后再导到新表即可
加字段名,两者都可以【存疑】
Flume
flume代理是由持续运行的source(数据来源)、sink(数据目标)以及channel(用于连接source和sink)构成的java进程,宗旨是向hadoop批量导入基于事件的海量数据
例如:监视新增文本文件所在的本地目录,将新增文件的每一行都发往控制台
Sqoop
允许用户将数据从结构化存储器抽取到hadoop中,用于进一步处理
原理
sqoop是通过一个MapReduce作业从数据库中导入一个表,这个作业从表中抽取一行行记录,然后将记录写入HDFS
在导入之前,Sqoop使用JDBC来检查要导入的表。它检索出表中所有的列以及列的sql数据类型。这些sql类型(VARCHAR,INTEGER等)被映射为Java数据类型(String,Integer等),在Mapreduce应用中将使用这些对应的Java类型来保存字段的值。Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录
可以设置一个划分列(splitting column),将对mysql的查询划分到多个节点上执行。根据表的元数据,Sqoop会选择一个合适的列作为划分列(如果主键存在,通常是主键)。主键列中的最小值和最大值会被读出,与目标任务数一起用来确定每个map任务要执行的查询
例如表widgets有100000条记录,其id列的值为0~99999.启动Mapreduce作业时,DataDrivenDBInputFormat会发出一条蕾丝于select min(id),max(id) from widgets的查询语句,检索出的数据将用于对整个数据集进行划分。假设执行并行运行5个map(-m 5),这样便确定每个map任务要执行的查询分别为:select id,widget_name,… from widgets where id>=0 and id < 20000,select … from widgets where id>=20000 and id < 40000以此类推
划分列的选择影响并行执行的效率,必须选择均匀分布的字段作为划分列
导出
Sqoop也可以执行导出,将HDFS数据导出到mysql
导出时可以先将导出结果存到一个临时表中,等导出操作结束了再转移到目标表中,防止导出一半的时候,即对目标表进行操作
hive
hive把SQL查询转换成一系列在Hadoop集群上运行的作业。Hive把数据组织为表,为存储在HDFS上的数据赋予结构,元数据存储在metastore数据库中
锁机制
分为表级锁和分区级锁。有了锁就可以防止一个进程删除正在被另一个进程读取的表。锁由ZooKeeper透明管理,因此用户不必执行获得和释放锁的操作
1)查询操作使用共享锁,共享锁是可以多重、并发使用的
2)修改表操作使用独占锁,它会阻止其他的查询、修改操作
3)可以对分区使用锁
表被锁问题处理
show locks < table_name > [partition(dt=20200202)] extended查询锁详情
例如,INSERT OVERWRITE table dw.dwd_bhv_playback partition(dt=’20201014’,hour=’13’) SELECT …
show locks dw.dwd_bhv_playback partition(dt=’20201014’,hour=’13’) extended;
show locks dw.dwd_bhv_playback extended;
都可以查出表dw.dwd_bhv_playback被锁了。后面加上extended展示被锁的详细信息,会展示是被哪个sql锁的
unlock table < table_name > 解锁一张表
unlock table < table_name > partition(dt=20200909) 解锁一张表的分区
表锁和分区锁是两个不同的锁,对表解锁,对分区无效,分区需要单独解锁
动态分区
可以在select语句中通过分区值来动态指明分区
insert overwrite table target_table partition(dt) select col1,col2,dt from source;
insert overwrite table dw_test.lss_test_day_copy partition(dt)
select id,name,description,dt from dw_test.lss_test_day;
注意,分区字段需要放在最后面,因为它是根据顺序来的,所以两个表的分区字段名可以不同,只要顺序正确
使用,insert…select 往表中导入数据时,查询的字段个数必须和目标的字段个数相同,不能多,也不能少,否则会报错。但是如果字段的类型不一致的话,则会使用null值填充,不会报错。而使用load data形式往hive表中装载数据时,则不会检查。如果字段多了则会丢弃,少了则会null值填充。同样如果字段类型不一致,也是使用null值填充
多个分区字段时,可以半自动分区
insert overwrite table ds_parttion
partition(state=’china’,ct) #state分区为静态,ct为动态分区,以查询的city字段为分区名
select id ,city from mytest_tmp2_p
表的修改
表名重命名
alter table source rename to target
对表重命名除了更新表的元数据之外,还会把表目录移动到新名称所对应的目录下;对于外部表,则只更新元数据,不移动目录
修改列
比如我们新增列,但如果数据表tb已经有旧的分区,则该旧分区中的col1将为空且无法更新,即便insert overwrite该分区也不会生效
alter table tb add columns(col1 string);
解决方法:使用级联更新,增加cascade,不仅更新新分区的表结构,同时也变更旧分区的表结构
alter table tb add columns(col1 string) cascade
排序和聚集
order by
对输入做全局排序,只有一个reducer,当输入规则较大时,需要较长的计算时间;
当为严格模式时,必须指定limit n,如果为分区表,还必须指定分区;
如果limit n,那就只有n * map number条记录进入reducer,大大减小处理数据量
sort by
指定数据进入reducer前完成排序,因此只保证每个reducer的输出有序;
使用sort by可以指定reducer个数,(set mapred.reduce.tasks=x),对输出的数据再执行归并排序即可得到全部结果[谁来归并排序?]
如果limit n,那就只有n * map number条记录进入reducer,大大减小处理数据量
distribute by
按照指定的字段对数据进行划分到不同的输出reduce/文件中
insert overwrite local directory ‘/home/hadoop/out’ select * from test order by name distribute by length(name);
此方法会根据name的长度划分到不同的reduce中,最终输出到不同的文件中
From table
select year, temperature
distribute by year
sort by year asc, temperature desc
根据年份和气温进行排序,并确保相同年份的行最终都再一个reducer分区中(文件下),可以看出distribute by和sort by经常一起使用,hive要求distribute by要写在sort by之前
cluster by
custer by 兼具distribute by 和sort by的功能,但是排序只能是倒序排序,不能指定排序规则
From table select year, temperature cluster by year;等价于
From table select year, temperature distribute by year sort by year
连接
内连接
select sales.,things. from sales,things where sales.id=things.id;
两个表都存在的才会出现在最终结果里。可以在查询中使用多个JOIN…ON…子句来连接多个表,hive会智能地以最少mapreduce作业数来执行连接。如果多个连接的连接条件中使用了相同的列,那么平均每个连接可以少用一个mapreduce作业来实现 [有待验证,原理流程是啥]
select a.val,b.val,c.val from a join b on (a.key=b.key1) join c on (c.key=b.key1)
如果join多个表时,join key是同一个,则join会被转化为单个map/reduce任务,reducer端会缓存a表和b表的记录,然后每取得一次c表记录就计算一次join结果
select a.val,b.val,c.val from a join b on (a.key=b.key1) join c on (c.key=b.key2)
如果join key非同一个,则join会被转化为多个map/reduce任务
join被转化为2个map/reduce任务.因为b.key1用于第一次join条件,b.key2用于第二次join,第一次缓存a表用b表序列化,第二次缓存第一次map/reducer任务结果,然后用c表序列化
注意:reducer会缓存join序列中除最后一个表所有表的记录,再通过最后一个表将结果序列化到文件系统(有助于在reducer端减少内存使用量,实践中应该把最大那个表放在最后)
JOIN子句中表的顺序很重要,一般将对大的表放到最后
外连接
1⃣️左外连接
A LEFT OUTER JOIN B ON
A中的行如果在B中没有对应的数据,也会返回
2⃣️右外连接
A RIGHT OUTER JOIN B ON
B中的行如果在A中没有对应的数据,也会返回
3⃣️全外连接
A FULL OUTER JOIN B ON
A和B中的所有行在输出中都有对应的行
join发生在where子句之前(以左外连接为例)
select a.,b. from dw_test.join_test1 a left outer join dw_test.join_test2 b on a.age=b.age where b.age=’a02’;
因为join在where之前,所以是先左连接得到结果,再对结果进行筛选,结果只有一条
select a.,b. from dw_test.join_test1 a left outer join dw_test.join_test2 b on a.age=b.age and b.age=’a02’;
左连接结果为,a表的全量数据,而b只有age=’a02’这条有数据,其他全为null
过滤条件写在on上面会让基表所有数据都能显示,不满足条件的右表以null填充,当过滤条件写在where上只会让符合筛选条件的数据显示
这里是经常导致sql执行慢的原因之一
hive的三种join方式
reduce join
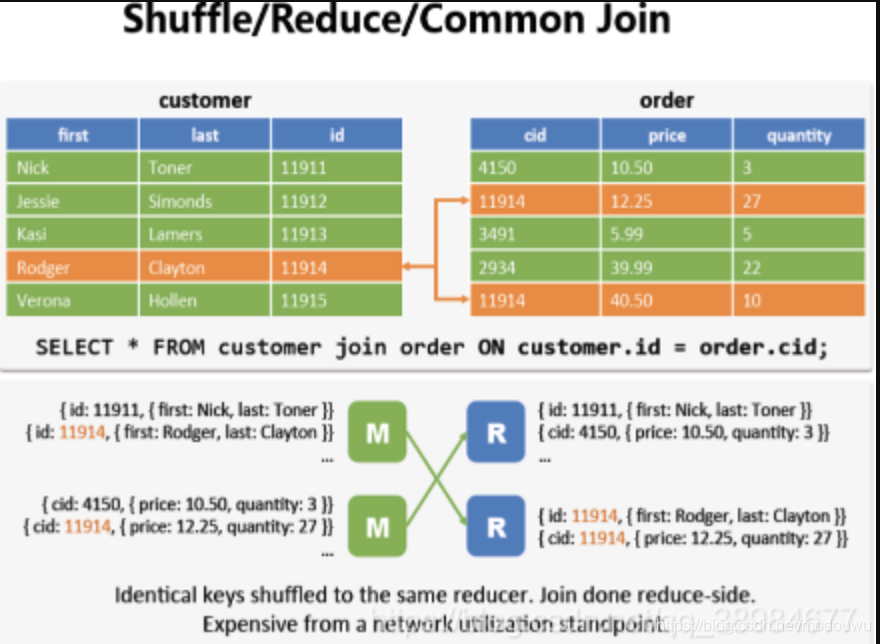
也称为common join或shuffle join,适合两边数据量都较大的join,map阶段会把相同key的value合在一起(相同的key被拖拽到同一个reducer),然后再去组合(在reducer端join)
map join
适合一张表数据量很大另一张表很少(通常<=1000行),那么将数据量少的表放到内存中,在map端做join,省去reduce运行效率会高很多
在实际应用中我们这样设置:set hive.auto.convert.join=true;这样hive就会自动识别比较小的表,继而使用mapJoin来实现两个表的联合
SMBJoin
smb是sort merge bucket操作,首先进行排序,继而合并,然后放到所对应的bucket中去,bucket是hive中和分区表类似的技术,就是按照key进行hash,相同的hash值都放到相同的buck中去。在进行两个表联合的时候。我们首先进行分桶,在join会大幅度的对性能进行优化。也就是说,在进行联合的时候,是table1中的一小部分和table1中的一小部分进行联合,table联合都是等值连接,相同的key都放到了同一个bucket中去了,那么在联合的时候就会大幅度的减小无关项的扫描
join 优化
join的特点
1⃣️底层会将写的HQL语句转换成MapReduce,并且reduce会将join语句中除最后一个表外都缓存起来
2⃣️当三个或多个以上的表进行join操作时,每个on使用相同字段连接时,只产生一个mapreduce
优化建议
1⃣️尽量使用left semi join替代in,not in,exists
2⃣️因为left semi join在执行时,对于左表中指定的一条记录,一旦在右表中找到立即停止扫描,效率更高
3⃣️当多个表进行查询时,从左到右表的大小顺序应该是从小到大。原因:hive在对每行记录操作时会把其他表先缓存起来,直到扫描最后的表进行计算
4⃣️对于经常join的表,针对join字段进行分桶,这样在join时不必全表扫描
分桶字段可以大于1
5⃣️小表进行mapjoin如果在join的表中,有一张表数据量较小,可以存于内存中,这样该表在和其他表join时可以直接在map端进行,省掉reduce过程,效率高
reduce个数确定
不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下两个设定:
hive.exec.reducers.bytes.per.reducer; – 每个reduce任务处理的数据量,默认是1G
hive.exec.reducers.max; – 每个任务最大的reduce数,默认是999
计算公式:N = min(每个任务最大的reduce数, 总输入数据量/每个reduce任务的数据量),即:如果reduce的输入总大小不超过1G,那么只有一个reduce任务。比如总大小是9.2G,则会有10个reduce数
调整reduce数
set hive.exec.reducers.bytes.per.reducer=500000000; (500M) – 方法1: 调整每个reduce任务处理数据量是500M
set mapred.reduce.tasks = 15; – 方法2 手动调整
什么情况下reduce只有一个
很多时候你会发现任务中不管数据量多大,不管你有没有设置调整reduce个数的参数,任务中一直都只有一个reduce任务; 其实只有一个reduce任务的情况,除了数据量小于hive.exec.reducers.bytes.per.reducer参数值的情况外,还有以下原因
- 没有group by的汇总 select count(1) from a
- 用了order by
- 用了笛卡尔积
亲测,对于语句,dw_test.join_test1表的hdfs文件都是小文件,小文件有多少个就有多少个map。
而reduce个数,始终只有一个,并且产生了一个输出文件,与group by的key分成多少份没任何关联,应该是数据量小于1G的原因。
而我set mapreduce.job.reduces=2;之后,则reduce个数就变为2了,并且hdfs上也产生了两个输出文件,这个也验证了一个reduce对应一个输出文件
小文件
小文件是指文件大小远远小于HDFS块大小的文件。Hadoop2.0中,HDFS默认的块大小是128MB。
如果一个任务有很多小文件(远远小于128MB),则每个小文件也会被当成一个块,用一个map任务来完成。一个map任务的启动和初始化的时间远远大于逻辑处理时间,就会造成资源浪费
小文件合并
输入合并 map
首先要在map执行之前合并小文件,减少map数 :
set mapred.max.split.size = 100000000; –1
set mapred.min.split.size.per.node = 100000000; –2
set mapred.min.split.size.per.rack = 100000000; –3
set hive.input.format = org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;–4
第四个设置是执行前进行小文件的合并,1、2、3三个参数确定合并文件块的大小,>128M:按照128分割;100M< size < 128M:按照100M分割;< 100M:进行合并 。4-执行 Map 前进行小文件合并 ,即使用java的输入输出流来合并
输出合并 reduce
我们可以通过一些配置项来使Hive在执行结束后对结果文件进行合并:
hive.merge.mapfiles 在map-only job后合并文件,默认true
hive.merge.mapredfiles 在map-reduce job后合并文件,默认false
hive.merge.size.per.task 合并后每个文件的大小,默认256000000
hive.merge.smallfiles.avgsize 平均文件大小,是决定是否执行合并操作的阈值,默认16000000
Hive在对结果文件进行合并时会执行一个额外的map-only脚本,mapper的数量是文件总大小除以size.per.task参数所得的值,触发合并的条件是:
根据查询类型不同,相应的mapfiles/mapredfiles参数需要打开;
结果文件的平均大小需要大于avgsize参数的值
Hbase
简介
列式存储数据库
以列为单位聚合数据,然后将列值顺序的存入磁盘

列式存储的出现主要是基于这样一种假设:对于特定的查询,不是所有的值都是必须的。尤其是在分析型数据库里,这种情形很常见
在这种新型的设计中,减少I/O是众多主要因素之一,,它还有其他优点:因为列的数据类型天生相似,比按行存储聚集的数据更利于压缩,更好的压缩比有利于在返回结果时降低带宽的消耗
GFS+MapReduce
缺陷一是缺乏实时随机存储数据的能力,二是它适合存储少许非常大的文件,而不适合存储成千上万的小文件,因为文件的元数据信息最终要存储在主节点的内存中,文件越多主节点压力越大
hbase的结构
表、行、列、单元格
所有的行按照行键的字典序进行排序的,例如
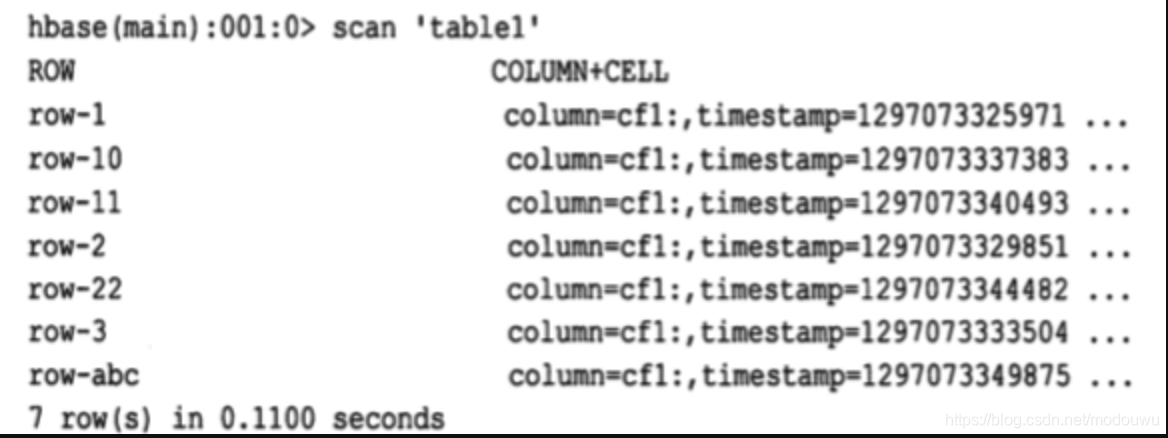
按照行键排序可以获得dbms的主键索引一样的特性,即行键是唯一的,并且只出现一次,否则你就是在更新同一行
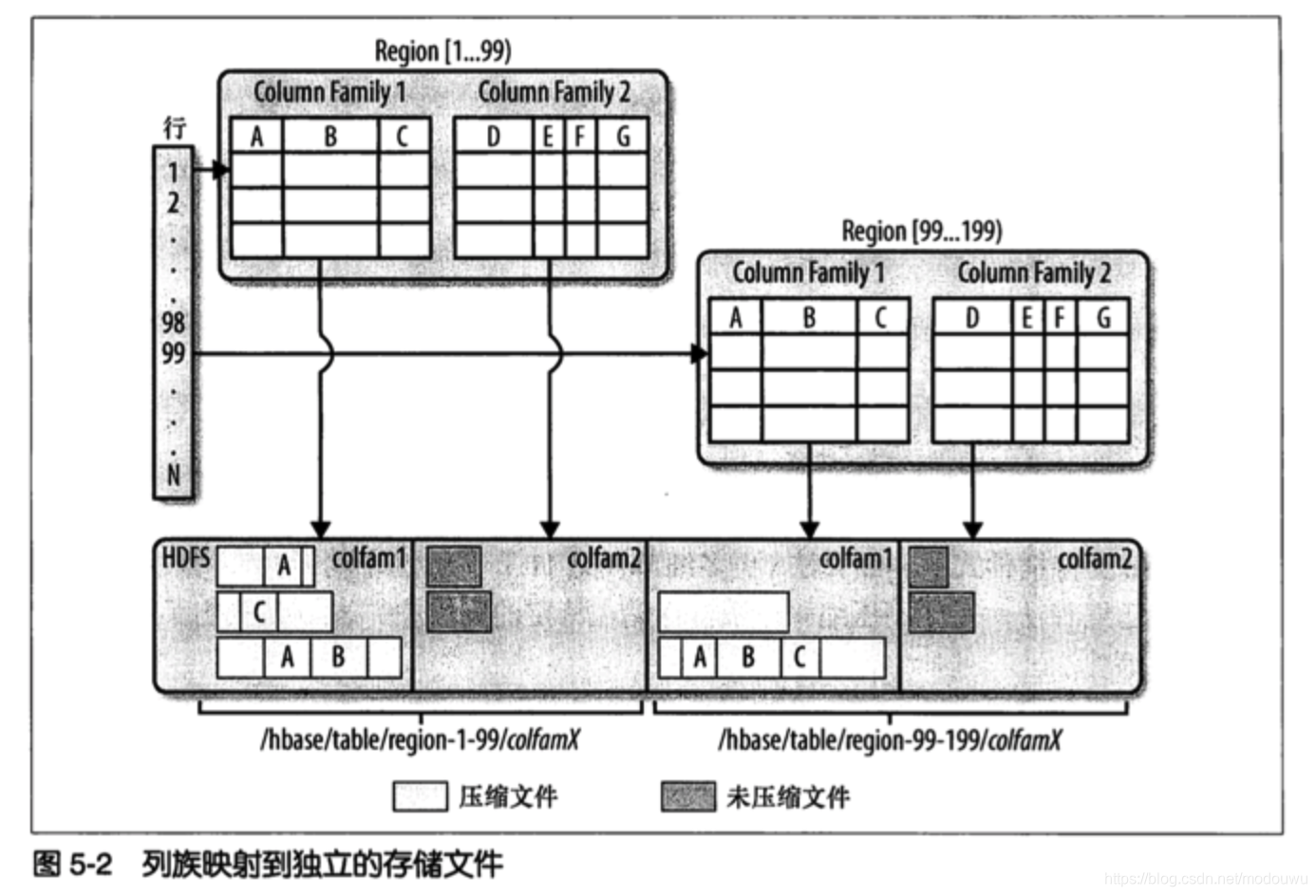
列族由若干列构成,存储在同一个底层的存储文件里,这个存储文件叫HFile。列族需要在表创建时就定义好,数量不能太多。列的数量没有限制,一个列族里可以由数百万个列
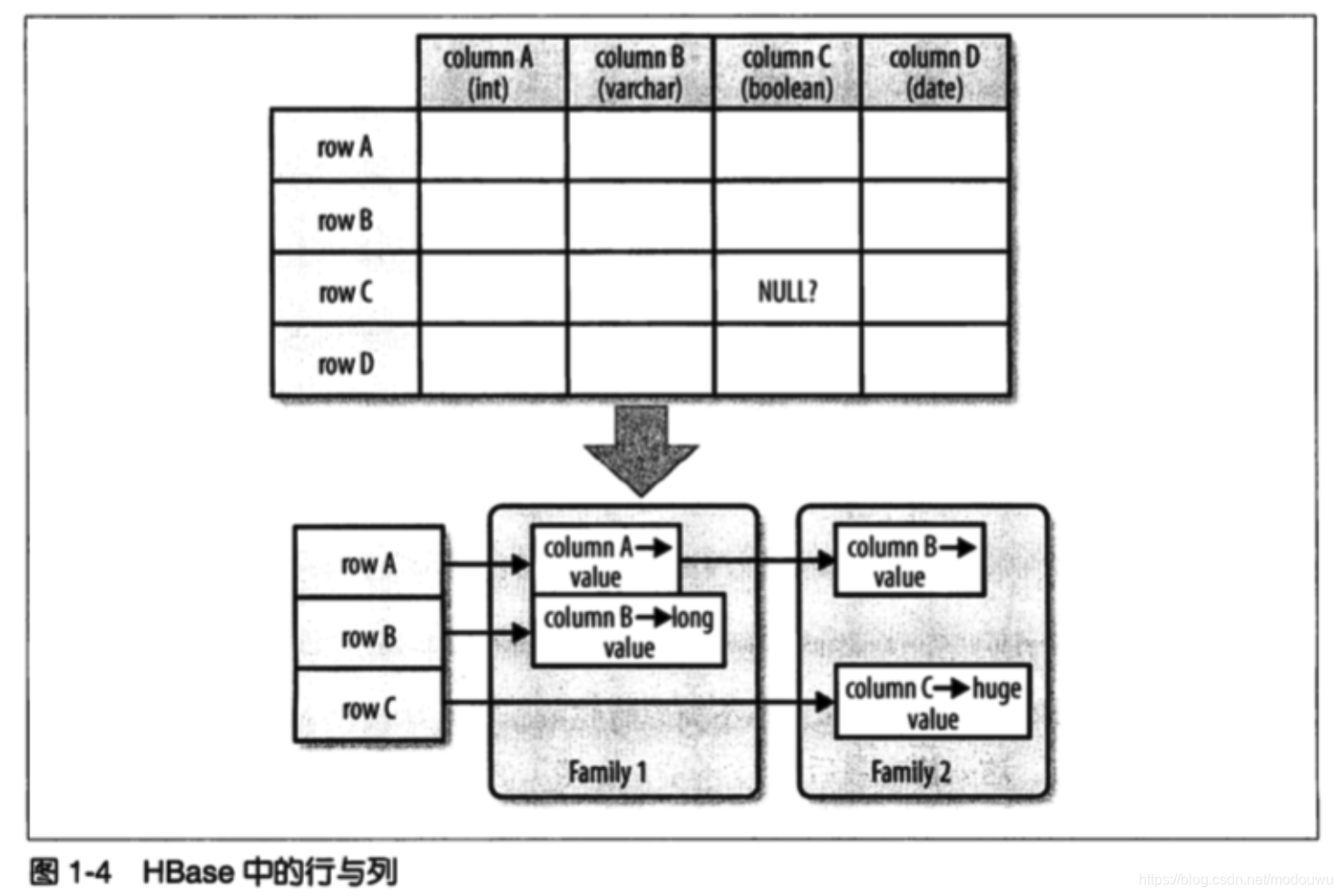
每个列的值都具有时间戳,默认由系统指定,也可以由用户显式设置。一个单元格的不同版本的值按照降序排列,访问时优先读取最新值
数据存取模式:
(Table,RowKey,Family,Column,Timestamp)->Value
用一行表述 SortedMap < RowKey,List< SortedMap< Column,List< Value,Timestamp>>>>
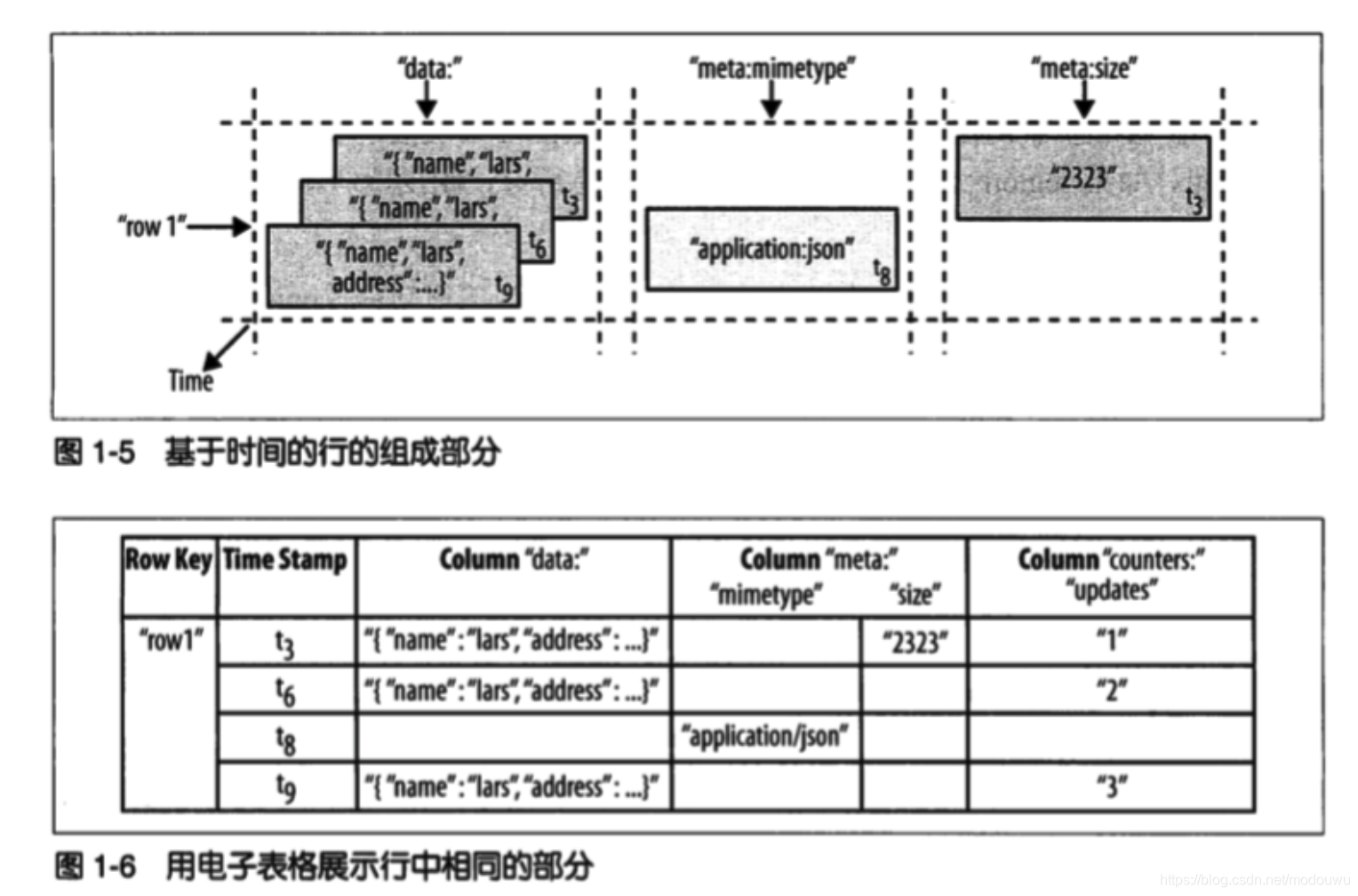
行看作是所有列以及这些列的最新版本的组合
region自动分区
hbase中扩展和负载均衡的基本单元成为region。region本质上是以行键排序的连续存储空间,等同于数据库分区中用的范围划分,由系统自动的拆分合并
每一个region只能由一台region服务器加载,每台region服务器可以同时加载多个region
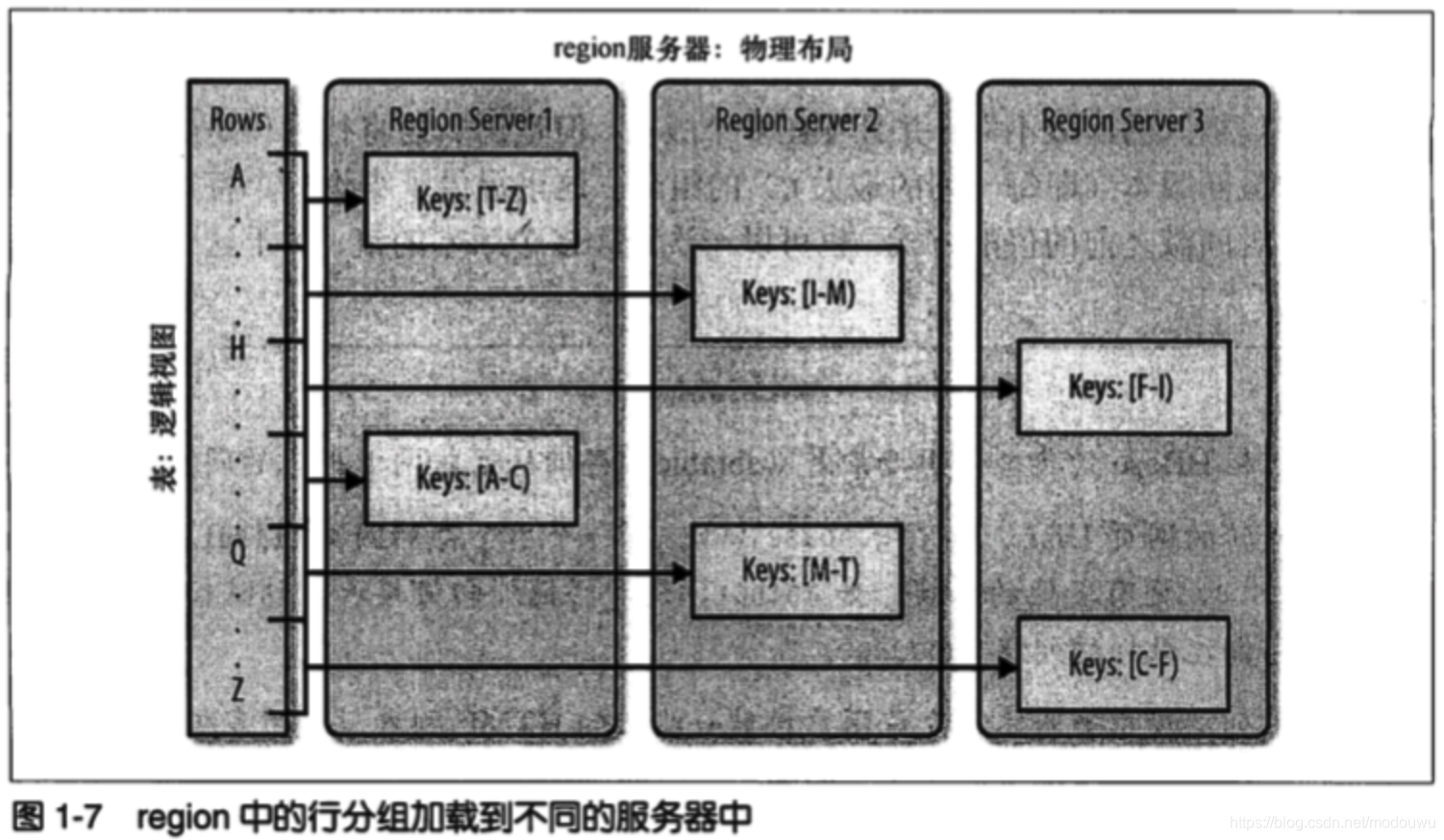
当一个服务器出现故障后,系统会将该region转移到其他服务器上,并获得细粒度的负载均衡
region拆分非常快,因为拆分之后的region读取的仍然是原存储文件
架构
数据存储文件Hfile
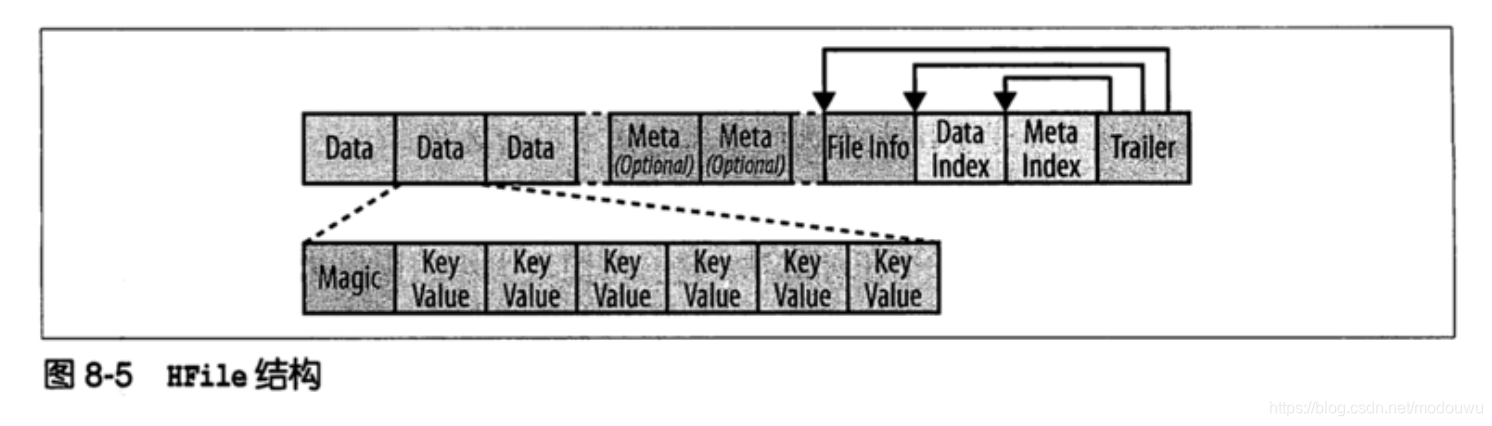
- 存储的是经过排序的键值映射结构。文件内部由连续的块组成,块的索引信息存储在文件的尾部,块的默认大小是64KB,可以配置。当把Hfile打开并加载到内存中时,索引信息会优先加载到内存。存储文件提供了一个设定起始和终止行键返回的API用于扫描特定的值
- 存储文件通常存储在HDFS中
- 更新数据时,先记录预写日志(WAL),然后写入内存中的memstore。一旦memstore累计大小超过给定最大值,则移出内存作为Hfile文件写到磁盘,并丢弃对应的日志。
- 删除键值对:做个删除标记(墓碑标记),在检索时删除标记会掩盖实际值。
- 读取的数据是两部分数据合并的结果,memstore的数据和磁盘上的存储文件。
- 随着memstore不断写入产生Hfile,有两种合并:minor合并和major压缩合并。minor合并,将多个小文件重写为大文件(不会删除过期数据、也不会处理删除标记);major合并,将一个region中的一个列族的所有Hfile重写为新Hfile,并能扫描所有键值对,顺序重写全部数据,并略过删除标记的数据
组成
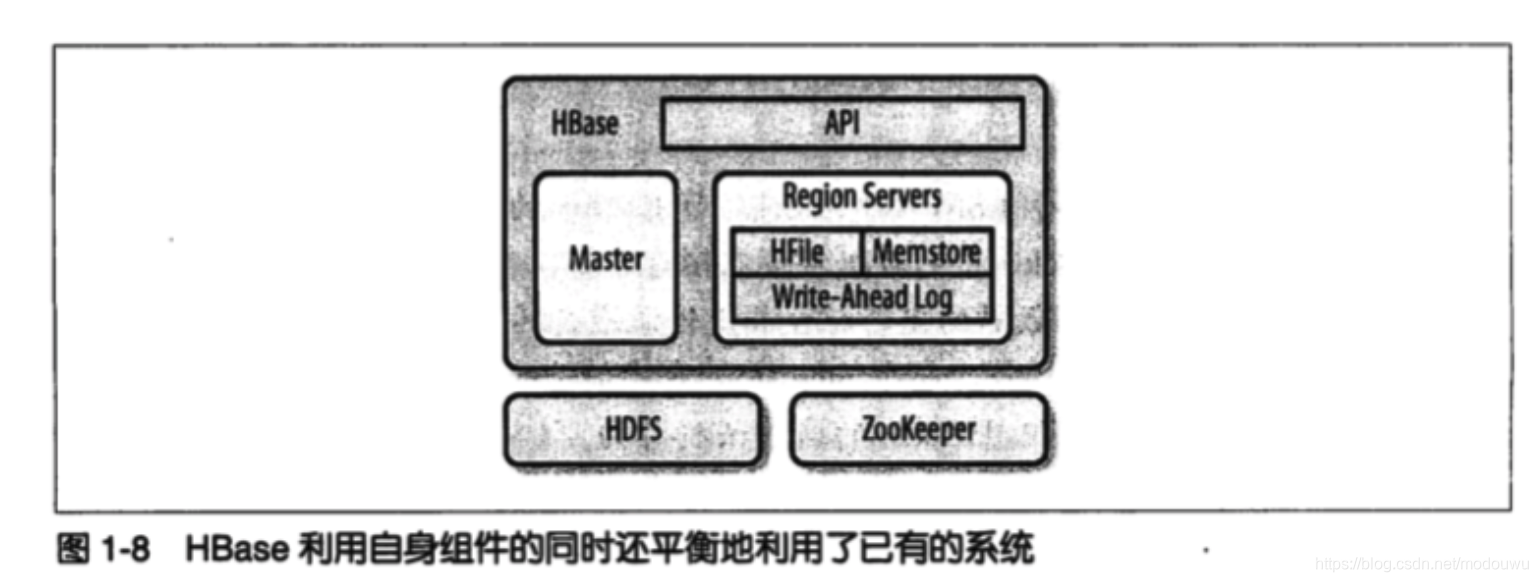
Hbase有三个主要组件:客户端、一台主服务器、多台region服务器
主服务器负责利用zk为region服务器分配region,负责跨region 服务器的全局的region的负载均衡,它不提供存储和检索,仅提供负载均衡和集群管理,它还提供元数据的管理操作如建表建列
region 服务器负责为他们服务的reigon提供读写请求,也提供拆分region的接口,客户端直接与region服务器通信
安装
命令
建表:create ‘testtable’,’colfam1’
查看表是否存在:list ‘testtable’
存放数据:put ‘testtable’,’myrow-1’,’colfam1:q1’,’value-1’
查看所有数据:scan ‘testtable’
查看单行数据:get ‘testtable’,’myrow-1’
删除单元格:delete ‘testtable’,’myrow-2’,’colfam1:q2’
禁用并删除表:disable ‘testtable’;drop ‘testtable’
安装
hbase大多是与hadoop安装在一起的,这样能很大程度减少网络I/O
hbase只能依赖特定的hadoop版本,主要原因之一是hbase和hadoop之间的rpc api,rpc协议是版本化的,细微差异就可能导致通信失败。它要求hadoop的jar必须部署在hbase的lib目录下。
机器是通过脚本来管理hadoop和hbase进程的,使用必须安装ssh
集群中节点的时间必须一致
文件句柄:操作系统参数的文件描述符的数量上限默认1024,需要设置为超过10000的数字
进程数:进程数太小可能导致oom
机器最好不要交换区或者设置很小的交换区
客户端api编程
配置文件
创建configuration时,应用程序会加载classpath下的hbase-site.xml、hbase-default.xml文件来生成hbase配置
hbase可以通过缓冲区批量写
问题
hbase的region、hfile、文件大小限制是什么关系
拆分、合并是咋回事
刷写大小设置有什么问题
表
表名会作为存储系统中存储路径的一部分来使用
文件大小限制(region大小限制)
这个参数限制了表中region大小。含义是每个存储单元的大小限制,即一个列族有若干个存储单元,而其中每个存储单元会包括若干个文件。如果一个列族的存储单元已使用的存储空间超过了大小限制,region将拆分。默认是256MB
memstore刷写大小
hbase在内存中预留了写缓冲区,写操作会写入到写缓冲区中,然后按照合适的条件顺序写入到磁盘的一个新存储文件中,这个过程称为刷写(flush)。默认是64MB
刷写时会导致请求被阻塞,region服务器不能持续接收新增加的数据。此外一旦服务器崩溃,系统通过wal预写日志恢复数据,且更新的内存丢失 既然有预写日志,怎么还会丢失?
列族
列族也会作为存储路径的一部分
列族默认版本数为3
列族也可以设置压缩。默认不压缩
块大小
habse中的存储文件都被划分为若干个小存储块,主要用于高效加载和缓存数据,这些小存储块在get或scan操作时会加载到内存,因此它也指定了hbase在一次读取过程中顺序读取多少数据到内存缓冲区。默认大小64KB
缓存块
hbase顺序的读取一个数据块到内存缓存中,在读取相邻的数据时就可以在内存中读取而不需要从磁盘中再次读取,有效的减少了磁盘I/O的次数,提高了I/O的效率。默认是true。但是如果要顺序读取某个列族,则最好禁止
在内存中
除了使用缓存块来提高连续访问的效率,还有一个在内存中标志,默认false
设置为true,则在正常的数据读取过程中,块数据被加载到缓存区中并长期驻留在内存中,除非堆压力过大,这个时候才会强制从内存中卸载这部分数据
那么,如果为false,块缓存难道在内存里最多只能缓存一个?
架构
存储

从中可以看出,hbase主要处理两种文件,一种是预写日志(WAL),另一种是实际的数据文件。这两种文件主要由HRegionServer管理。基本流程是客户端首先联系Zookeeper子集群(quorum)(一个由zookeeper节点组成的单独集群)来查找行键。上述过程是通过zookeeper获取含有-ROOT的region服务器名(主机名)来完成的。通过含有-ROOT的region服务器可以查询到含有.META表中对应的region服务器名,其中包含所请求的行键信息。这两处的内容都被缓存并只查询一次。最终通过查询.META服务器来获取客户端查询的行键的数据所在的region的服务器名,定位到数据位置,hbase会缓存这次查询的信息。所以之后客户端可以通过缓存信息定位数据位置,而不用再次查询META表
HRegionServer负责打开region,并创建对应的HRegion实例。当HRegion被打开后,它会为每个表的HColumnFamily创建一个Store实例,这些列族是用户之前创建表时定义的。每个store实例包含一个或多个storeFile实例,他们是实际数据存储文件HFile的轻量级封装。每个store还有一个对应的MemStore,一个HRegionServer分享了一个HLog实例
写流程
当发起HTable.put(Put)时,会将请求交给对应的HRegion实例来处理。第一步是决定数据是否需要写到由HLog类实现的预写日志中。一旦数据写入WAL中,数据就会被放入memStore中,同时检查memStore是否已满,如果满了,会刷写到磁盘中。刷写请求由另一个线程处理,它会把数据写成hdfs中一个新的HFile,同时也会保存最后写入的序号,系统就知道哪些数据现在被持久化了
分片
分片id目前只能是用来区分数据条数的,比如自增id,可以有一个比较合理的split的partition个数,这个任务挂了是因为,用了user_id作为分片字段会导致,user_id本身其实是个固定位数的id,相当于string,不适合作为数据条数比如100000000和800000000,系统就会认为这个表有7亿条数据,导致产生1400个分区
这个任务是分区生成过多,看了下有20w左右,导致driver在分配task的时候超时,程序直接挂掉了
HFile结构

WAL
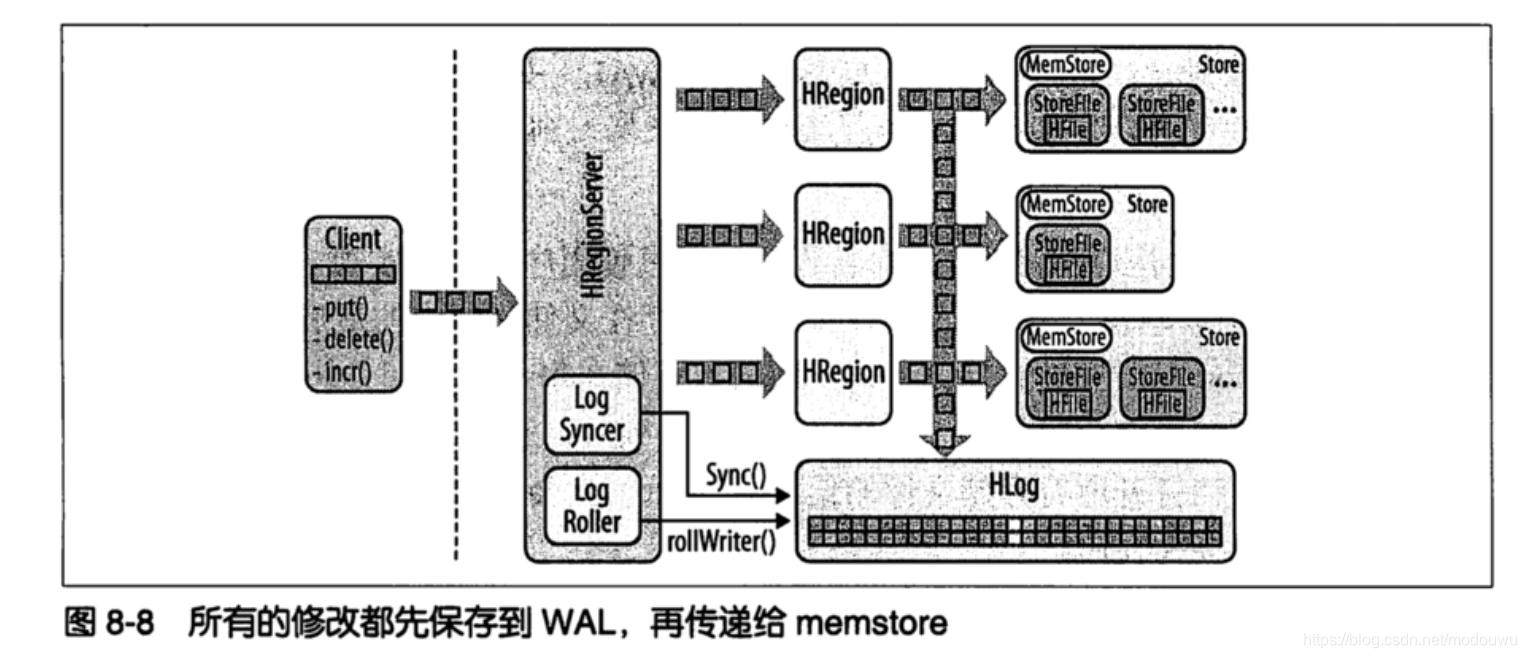
处理过程如下:客户端发送修改数据的请求,每个请求都会封装到一个keyValue对象实例中,用通过RPC调用发送出去。这些调用成批的发送给含有匹配region的HRegionServer。
然后它们会被发送到管理相应行的HRegion实例。数据被写入到WAl,然后被放入到实际拥有记录的存储文件的Memstore。这就是HBase大体的写路径。
最后,当memstore达到一定大小或经理一个特定的时间之后,数据就会异步地连续写到文件系统中。在写入的过程中,数据是以不稳定的状态存放在内存中的(memstore)。即使服务器崩溃,WAL也能保证数据不丢失,因为WAL实际存储在HDFS上。其他服务器可以打开日志文件回放这些修改–恢复操作并不在崩溃的服务器上进行
HLog
实现WAL的类叫HLog。当HRegion实例化时,HLog实例会被当作一个参数传入HRegion的构造器中,各个Hregion共享一个HLog。当region收到跟新操作时,它可以通过HLog把数据保存到WAL中。
为了提高性能,在Put、Delete、Increment时可以使用额外的参数:setWriteToWAL(false),但是这样可能导致数据丢失
回放
通过WAL使系统恢复到一致性状态的过程
日志拆分
Hregion server崩溃后,则系统恢复时,需要把多个region公用的WAL日志按照region进行拆分,拆分完毕后才能把region server上的region部署到其他服务器上
为什么GET都是SCAN
hbase的get方法在内部完全被scanAPI所使用的代码替代了。因为hbase中没有可以使我们直接访问特定行或者列的索引文件。Hfile的最小单元是块,并且为了找到所需要的数据,regionServer代码和它的底层实现的store实例必须载入整个可能存储着所需数据的块并且扫描这个块
读取数据的流程
hbase是按照列族来划分文件的,并且有多个版本,那么执行get命令时怎么识别出一行数据的呢?
作为客户端,我们希望所有列都被返回,就好像它们被存储在同一个实体中一样。但是实际上,数据存储在分离的KeyValue实例中,横跨任意个数据存储文件。
如果删除了值,那么会给值一个墓碑标记,但是标记可能存储在所需删除数据的很远的地方
region查找
两张特殊的目录表:-ROOT-和.META. 都对应了region
三层查找结构:第一层是zk中包含root region位置信息的节点;第二层是从-ROOT表中查找对应meta region的位置;第三层是从.META.表中查找用户表对应的region位置
简单的说,第一步从zk获取root表的位置信息,而root表中存的是表的元数据meta信息的位置,行键是meta+表名+时间戳,值是表元数据信息所存的位置在哪个meta表里,注意root表只有一个,meta由多个;第三部定位到表元数据信息的位置之后,定位用户要查找的表在具体哪个region,这里meta的行键是由region表名、起始行、ID(通常是当前时间的时间戳)连接而成,通过起始行、时间戳等信息定位region。
用户region的映射从空缓存开始,客户端需要进行3次查询
客户端会缓存region的地址,如果发现region失效,则会一层一层向上查找
zookeeper
作用:跟踪region服务器、保存root region地址等
/hbase/rs 存的是所有hbase的region服务器
高级用法
行键设计
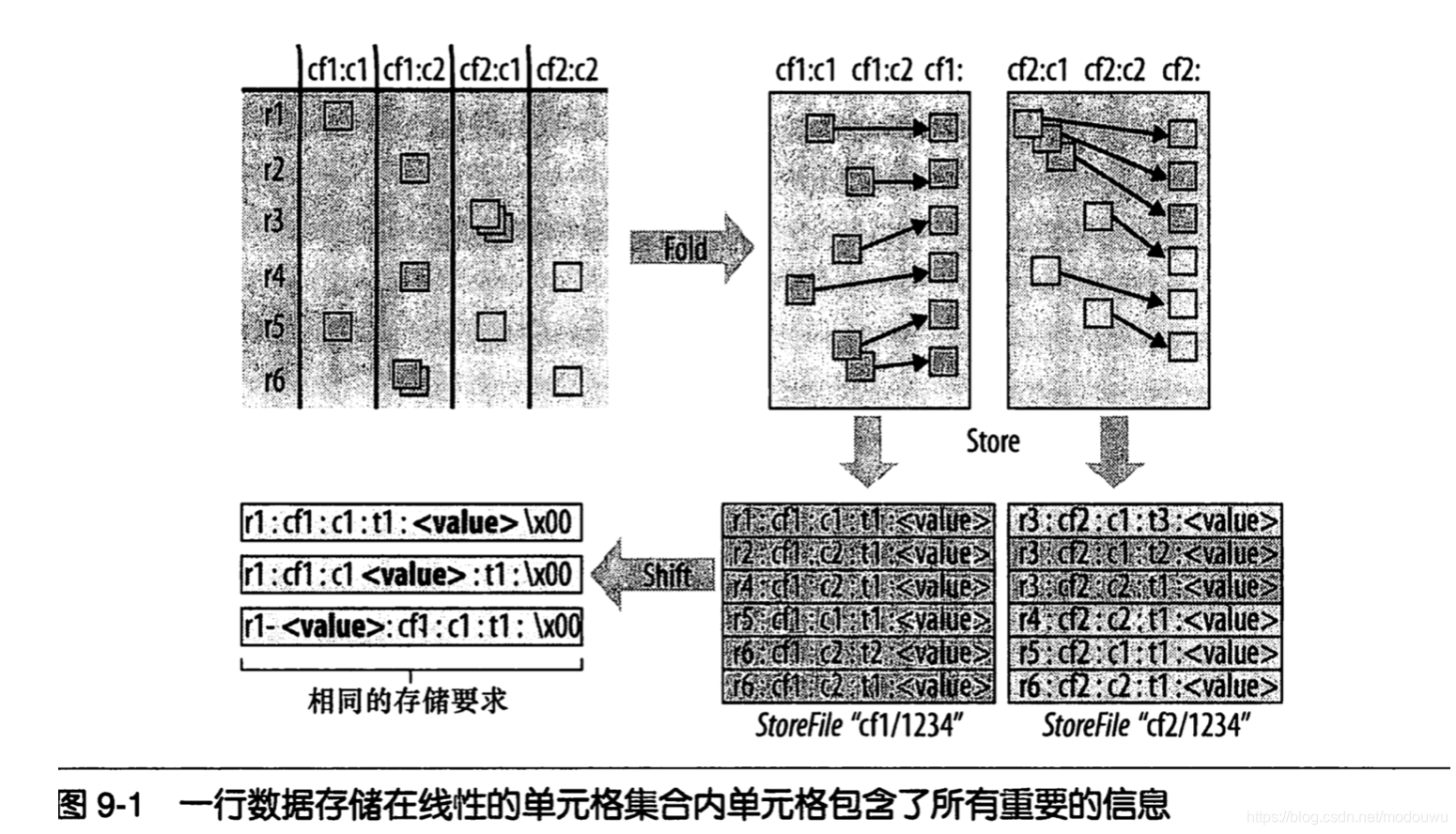
同一个单元格的多个版本被单独存储为连续的单元格,当单元格被存储时还需要添加必要的时间戳。单元格按照时间戳降序排列,所以hfile的reader读取数据时,最新的值先被读取
含有结构信息的整个单元格在Hbase中叫做KeyValue,其中不仅包含用户生成时设定的列和对应的值,也包含行键和时间戳。KeyValue存储时先按照行键排序,当一行有多个单元格时内部再按照列键排序
高表与宽表
高表指列少而行多;宽表相反
用户应当尽量把需要查询的纬度或信息存储在行键中,因为用它筛选数据的效率最高,此外Hbase只能按行分片,因此高表更有优势
部分键扫描
比如行键为 userId+messageId
那么可以将扫描操作中键的开始和结束键设置为用户的Id,结束键设置为userId+1.
通过包含部分键的扫描机制设计出有效的左对其索引
性能优化
这里主要说的是region服务器。主要原因是region服务器在处理特定负载时,特别是写入大量负载时,memstore在不同时期创建并释放着各种不同大小的对象。因为数据是被存储在内存缓冲区内的,他们会被保留直到超过用户配置的最小刷写大小,用户可以在配置文件中使用hbase.hregion.memstore.flush.size来设置region的memstore刷写大小,此外在定义表是也可以但对指定表的这个属性。
一旦memstore大于这个值,数据就会被刷写到磁盘,并创建一个新的存储文件。因为写入磁盘的数据是由客户端在不同时间写入的,那么他们占据的java堆空间很可能是不连续的,所以java虚拟机的堆内存会出现孔洞。
数据会根据自身在内存中停留的事件被保存在java堆中分代结构的不同位置。如果数据在内存中停留的时间过长,例如,向一个列族中插入数据速度较慢,很长时间都没达到刷写大小时,对应的数据就可能被提升为老年代。年轻代和老年代不同点在于空间大小:年轻代占用的空间在128M到512M之间,而老年代几乎占用了所有可以占用的堆空间,通常是好几G的内存。
注意一般年轻代默认大小都需要调大,如果不这样做的话,用户可能会发现服务器cpu的使用量会急剧上升,因为从年轻代中收集对象会消耗大量的cpu。
推荐的jvm参数是:
-XX:+UserParNewGC 和 -XX:+UseConcMarkSweeoGC
第一个选项是设置年轻代使用Parallel New Collector垃圾回收策略:这将停止运行java进程而去清空年轻代堆。与老年代相比,新生代很小,所以这个过程话费时间很短,通常只需要几百毫秒。
以上策略对于较小的年轻代是可以接受的,但不适合老年代:在最差的情况下,以上回收策略会造成数秒钟甚至几分钟的进程停顿。一旦停顿时间达到了zookeeper会话超时时间,这个服务器将被master认为已经崩溃并随之抛弃。一旦region服务器从垃圾回收暂停中恢复,它会获知自己被抛弃,然后它会自行关闭。
这种情况可以通过使用并行标记回收器(CMS-concurrent mark-sweep collector)来缓解。该回收器在工作时试图在不停止运行java进程的情况下尽可能异步并行的进行垃圾回收。这种策略会增加cpu的负担,但可以避免重写老年代堆碎片时的停顿——除非发生提升失败,这种错误会迫使垃圾回收暂停运行java进程并进行内存整理
压缩
hbase支持列族级别的数据压缩。通常都推荐使用压缩,压缩通常会带来较好的性能,因为cpu压缩和解压消耗的时间比丛磁盘中读取和写入更多数据消耗的时间更短
主要考虑压缩率和压缩速, 选择snappy
在建表时即可指定压缩方式,还可以先disable表,然后alter来更改压缩方式,最后enable表
优化拆分和合并
通常hbase的region是自动拆分和合并的。
但是如果region都以相同的速度增长,那么可能会发生“拆分\合并风暴”,这会引起磁盘I\O上升。此时通过手工命令来拆分合并更好
region热点:如果存在这种情况,则用户需要采用盐析主键或者使用随机的行键把数据负载均衡到所有的机器。
疑问:如果表很多,那么一个表有热点,和其他表热点相互中和,那还需要拆热点region吗?
此时可以手工把热点region按照需要拆分成多个子region。
预拆分:用户可以在建表时即指定需要的region数目来达到预拆分的目的
负载均衡
master有一个内置的负载均衡。默认每5分钟运行一次,通过hbase,balancer.period属性设置
region合并
某些情况下,用户可能需要合并region,例如,用户删除大量数据并且想要减少每个服务器管理的region数目
配置
zk的超时
默认region服务器和zk集群的超时时间是3分钟,使用zookeeper.session.timeout来设置。即如果服务器崩溃,master将在3分钟后发现这个崩溃现象,并开始恢复数据。注意这个时间,要长于服务器上jvm的垃圾回收的运行时间。
当服务器写入大量的数据时,会对region服务器产生很大的压力,更可能导致垃圾回收暂停的问题
处理线程数
hbase.regionserver.handler.count属性定义了响应外部用户访问数据表请求的线程数,默认值为10,偏小,适合单词请求涉及的数据量达到MB级别(如较大的写入和使用大缓存的扫描)的场景,而当单次请求开销较小时(如get、较小的put、increment和delete等操作)可以将工作线程设的高一些。
将这个值设置的高也可能产生问题,因为并发的写请求涉及到的数据累加起来只会很可能会对一个region服务器的内存造成巨大压力(因为内存无法通过垃圾回收释放掉),这甚至会导致服务器端抛出oom异常。
问题:为什么会压力大呢?如果内存的文件过多,不是会写入到磁盘吗?
region服务器运行在可用内存过低的情况下时,其将会使jvm的垃圾回收器运行的更加频繁,同时随之发生的停顿也会更加明显(原因是内存都被写请求占用,无论垃圾回收器怎么尝试它们都不能被回收)。一段时间瘦,集群的吞吐量就会收到影响,因为命中这个服务器的请求都会变慢,这样会使其内存紧张的情况更加严重
增加region的大小
更大的region可以减少集群总的region数目。一般,管理较少的region可以让集群运行更加平稳。默认的region大小是256MB。但要注意,更大的region意味着高负载的情况下合并的停顿时间更长
块缓存
如果用户负载多为读请求,则应该增加块缓存大小,帮助用户缓存更多的数据。
块缓存于memstore的上限不能超过100%,默认它们占用的堆空间量是60%
memstore限制
默认占用堆大小是40%。当用户主要用于处理读请求,可以考虑同时减少memstore的上下限来增加块缓存的空间
阻塞时存储文件数目
hbase.hstore.blockingStoreFiles来设置,当存储文件数目达到阈值时,更新操作将会阻塞,并以此来给合并操作留出时间来减少存储文件的数目。默认值是7
最大日志文件限制
hbase.regionserver.maxlogs属性可以控制基于磁盘的WAl文件数目,进而控制刷写频率。默认是32,对于写压力较大的应用应该降低这个值,强迫服务器更频繁的将数据刷写到磁盘,这样其对应的WAL日志就可以丢弃
疑问总结
region
- region是行为单位的表的子集,每个region有三个要素,属于哪张表、首行、末行
- region 是Hbase集群分布数据的最小单位
- region比较少的时候,导致region分配不均,总是分派到少数的节点上,读写并发效果不显著,这就是hbase 读写效率比较低的原因
- 一个region,按照column family分多个memstroe-hfile结构
- region数量设计
设计的本意是每个Server运行小数量(2-200)个大容量(5-20Gb)的Region,理由如下:
· 每个MemStore需要2MB的堆内存,2MB是配置的,假如有1000拥有两个列族的Region,那么就需要3.9GB的堆内存,还是没有存储任何数据的情况下
· HMaster要花大量的时间来分配和移动Region
· 过多Region会增加ZooKeeper的负担
· 每个Region会对应一个MapReduce任务,过多Region会产生太多任务
元数据表-ROOT- .META.
hbase的两张元数据信息表,是内置表,从存储结构和操作方法的角度来说,它们和其他HBase的其他表没有任何区别,对于普通表的操作对它们都适用。
它们存储的是Region的分布情况以及每个Region的详细信息
.META.
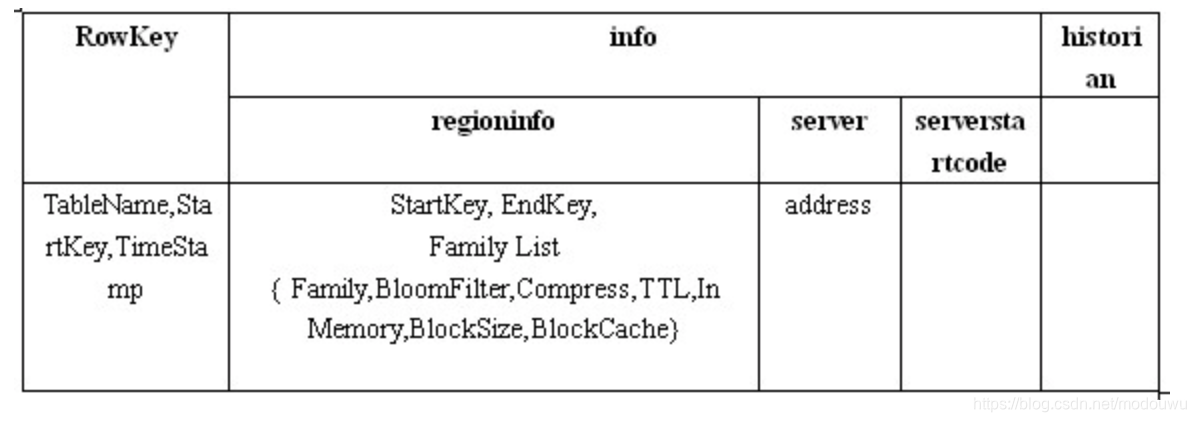
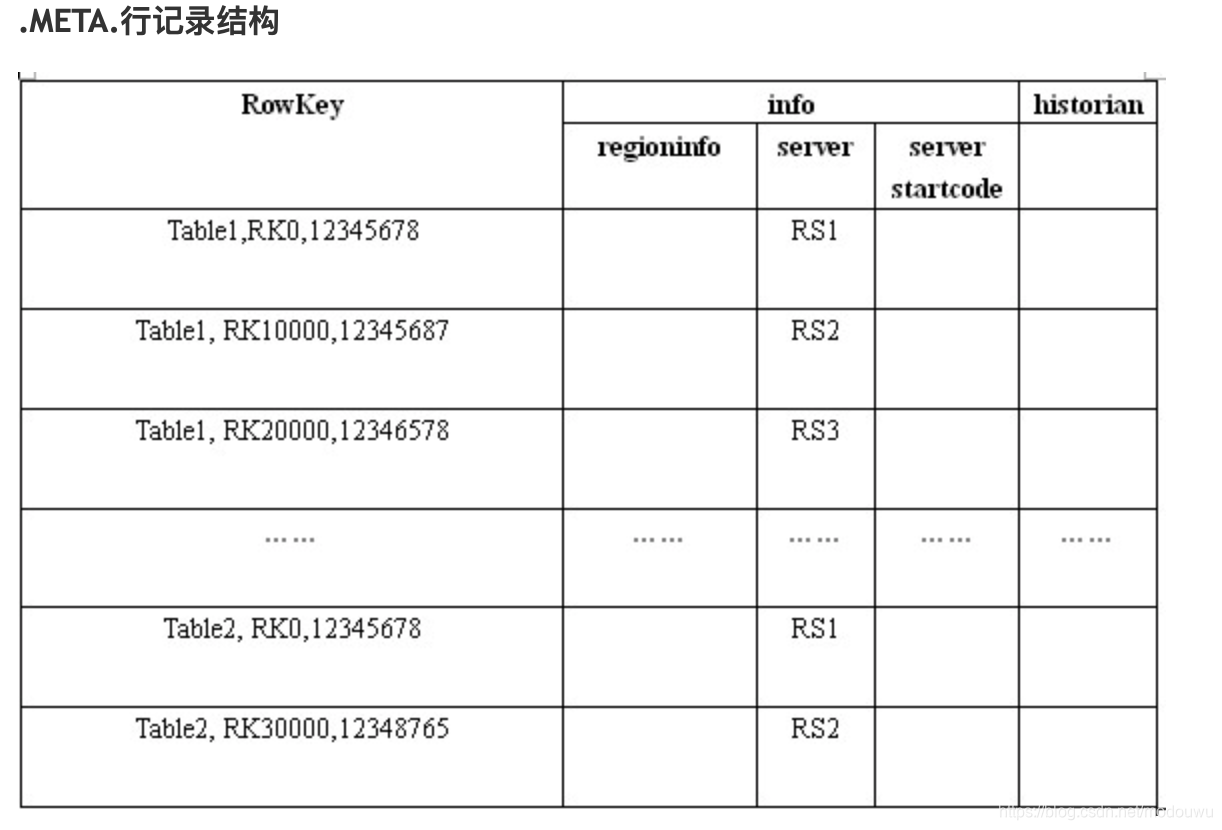
.META.表的每一行记录了一个Region的信息.注意如上截图,一个region有四行,他们的rowkey一样,共同组成表的一行。
前一个rowkey里的info:regioninfo里的的endKey的值,是后一个rowKey的startKey的值。
一张表的首region的第一个rowkey的startKey是空,最后一个region的最后一个rowKey的endKey是空。如果一张表同一个region的第一个rowKey的startKey是空,最后一个rowKey的endKey也是空,表明这张表只有唯一的region
为了加快访问,.META.表的全部region都保存在内存中
rowkey
RowKey就是Region Name,它的命名形式是TableName,StartKey,TimeStamp.Encoded.,其中 Encoded 是TableName,StartKey,TimeStamp的md5值
.META.表的rowkey也是有序的,并且rowkey第一个部分是表名,因此在.META.表中相同表的region是在一起的,也便于寻址
-ROOT-
如果表切分的region很多,那么.META.会很大,它也会划分成很多region,那么如何定位到所查的.META.呢
HBase的做法是用另外一个表来记录.META.的Region信息,就和.META.记录用户表的Region信息一模一样。这个表就是-ROOT-表。这也解释了为什么-ROOT-和.META.拥有相同的表结构,因为他们的原理是一模一样的

可以看出,除了没有historian列族之外,-ROOT-表的结构与.META.表的结构是一样的。另外,-ROOT-表的 RowKey 没有采用时间戳,也没有Encoded值,而是直接指定一个数字
-ROOT-表永远只有一个Region,也就只会存放在一台RegionServer上。—— 在进行数据访问时,需要知道管理-ROOT-表的RegionServer的地址。这个地址被存在 ZooKeeper 中
注意因为-ROOT-表是单region,所以它的startKey和endKey是空
寻址region
三层定位:通过zookeeper找到-ROOT-,根据排序性定位到.META.的region,连接.META.的regionserver,再查到目标表的region,连接目标表的regionserver即可定位到。
还有一个疑问:新版本没有root表了 采用两层寻址机制
region合并
region拆分
总结一下拆分合并流程:
刚建立时,默认只有一个region,随着数据增多,region的数据越来越大,此时会进行region拆分,分成两个大小差不多的region,这就是region拆分。当region大小的个数增加到region个数阈值时,就会发起region合并。比如设置region大小阈值为30G,那么我们可以对小于10G的所有region进行合并。
问题:region合并应该不会发生才对?region合并跟hfile的合并没有任何关系?
hfile合并:在region内部,每个列族都对应一个store,每个store内部是由memstore、若干个hfile组成。memstore默认大小64MB,超过即刷到hdfs上形成一个hfile。满足一定条件,会进行minor合并,多个小hfile合并为一个大的hfile,这就是minor 合并。major合并一般手工进行,因为会对集群性能产生影响,一般一周一次,并在夜间负载较低时通过脚本定时运行
Region定位流程
参考
Zookeeper:记录了.META.表的位置。(1.X之后的版本废除了-ROOT-表)
.META.:根据给定的key找到RegionServer。.META.记录所有的用户空间region列表,以及RegionServer的服务器地址
写流程
向zookeeper发起请求,从ROOT表中获得META所在的region,再根据table,namespace,rowkey,去meta表中找到目标数据对应的region信息以及regionserver
把数据分别写到HLog和MemStore上一份 MemStore达到一个阈值后则把数据刷成一个StoreFile文件。若MemStore中的数据有丢失,则可以总HLog上恢复 当多个StoreFile文件达到一定的大小后,会触发Compact合并操作,合并为一个StoreFile,这里同时进行版本的合并和数据删除。 当Compact后,逐步形成越来越大的StoreFIle后,会触发Split操作,把当前的StoreFile分成两个,这里相当于把一个大的region分割成两个region
读流程
从zookeeper获得root表所在region位置
根据table,namespace,rowkey去root表中获得meta表所在region位置
根据table,namespace,rowkey去meta表中获得这条记录所在regionserver
首先检查请求的数据是否在Memstore,写缓存未命中的话再到读缓存(blockCache)中查找,读缓存还未命中才会到HFile文件中查找,最终返回merged的一个结果给用户
client端会对数据块缓存
数据flush过程
当memstore数据达到阈值(默认是64M),将数据刷到硬盘,将内存中的数据删除同时删除Hlog中的历史数据(也就是说Hlog只保存还没落盘的日志,落盘的日志都会删除掉)。
并将数据存储到hdfs中。
在hlog中做标记点
数据合并过程
当数据块达到4块,hmaster将数据块加载到本地,进行合并
如何有序
各个storefile里的数据是分别有序的,合并的时候需要将各个有序的storefile合并成一个大的有序的storefile
首先将各个需要合并的storefile封装成StoreFileScanner最后形成一个List加载到内存,然后再封装成StoreScanner对象,这个对象初始化的时候会对各个StoreFileScanner进行排序放到内部的队列里,排序是按照各个StoreFileScanner最小的rowkey进行排序的。然后通过StoreScanner的next()方法可以拿到各个StoreFileScanner最小rowkey中的最小rowkey对应的KV对。然后就把取出的KV对追加写入合并后的storefile。因为每次取出的都是各个storefile里最小的数据,所以追加写入合并后的storefile里的数据就是按从小到大排序的有序数据。
当合并的数据超过256M,进行拆分,将拆分后的region分配给不同的hregionserver管理
当hregionser宕机后,将hregionserver上的hlog拆分,然后分配给不同的hregionserver加载,修改.META.
regionServer的内存结构
每台regionServer中的内存由BlockCache和MemStore组成。每台region server只有一个blockCache,可以有多个memStore。
客户端查询数据的顺序是 memStore –> blockCache –> HFile,先在metStore找,找不到就到blockCache,再找不到就读取HFile文件到内存中。从HFile中读到的数据保存在blockCache,每个列族都有自己的blockCache(block是建立索引的最小数据单元,block大小可调整,默认64kb)。hbase的block使用的是LRU策略,当BlockCache的大小达到上限后,会触发缓存淘汰机制,将最老的一批数据淘汰掉
注意:hlog会同步到hdfs
列族设计
列族不能太多,通常情况下只设计成一个。原因:
1.flush会产生大量IO
Flush 的最小单元是 region ,也就是说如果region有多个列族,其中一个列族做flush操作,其他列族也会flush。每次flush都会产生StoreFile ,频繁flush会产生更多StoreFile ,StoreFile 数量增多又会产生更多的 Compact 操作,Flush 和 Compact 都是很 重的 IO 操作
2.Split 操作可能会导致数据访问性能低下
Split 的最小单元是 region, 如果这个 region 有两个列族 A、B,列族 A 有 100 亿条记录,列族 B 有 100 条记录,如果最终 Split 成 20 个 region, 那么列族 B 的 100 条记录会分 布到 20 个 region 上, 扫描列族 B 的性能低下
3.在多列族的情况下,要注意各列族的数量级要保持一致
rowkey设计
1.越高频的字段越靠左
hbase在进行查询的时候,根据RowKey从前向后匹配,所以设计rowkey时,越高频的查询字段排列越靠左。无论应用的负载特点是什么样,RowKey字段都应该参考最高频的查询场景
2.长度原则
以byte[]形式保存,一般设计成定长。建议越短越好,不要超过16个字节,原因:
1)hfile和memstore都会存储key,key过长会占用存储空间
2)目前操作系统都是64位系统,内存8字节对齐,控制在16字节,8字节的整数倍利用了操作系统的最佳特性
3.散列原则
避免热点问题
避免热点的方法
1⃣️Reversing:翻转key的某部分或者把随机性好的部分提到最左边
2⃣️salting:在原RowKey的前面添加固定长度的随机数。1~n,n为分区数
3⃣️Hashing:基于 RowKey 的完整或部分数据进行 Hash,而后将Hashing后的值完整替换或部分替换原RowKey的前缀部分
默认建表时,只有一个region,上下无边界。随着数据增多,一个reigon分裂为两个region。如果我们的rowkey还是顺序增大,那么写操作总是被定位到无上界的那个region,而另一个region永远不会被写数据。
而将rowkey散列化就是避免rowkey自增,这样也能解决上面所说的缺点
Zookeeper
zookeeper是一个开源的分布式协调服务 。换句话讲,zk是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于它实现数据的发布/订阅、负载均衡、名称服务、分布式协调/通知、集群管理、Master选举、分布式锁和分布式队列
什么是分布式系统?
- 很多台计算机组成的一个整体,一个整体一致对外并且处理同一个请求
- 是一个硬件或软件组件分布在网络中的不同的计算机之上,彼此间仅通过消息传递进行通信和协作的系统。
- 内部的每一台计算机都可以相互之间通信(rest/rpc)
- 客户端到服务器的一次请求到响应结束会经历很多台计算机的处理
zookeeper的作用
- master节点选举,主节点挂了以后,从节点就会接手工作,并且保证这个节点是唯一的,这也是所谓首脑模式,从而保证我们的集群式高可用的
- 统一配置文件管理,只需要部署一台服务器,则可以把相同的配置文件同步更新到其他的所有服务器,云计算中使用较多(修改了就统一配置文件)
- 发布与订阅,类似信息消息队列MQ(amq,rmq),dubbo发布者把数据存在node上,订阅会读取这个数据
- 提供分布式锁,分布式环境中不同进程之间争夺资源,类似于多个线程中的锁
- 集群管理,集群中保证数据的强一致性
zk文件系统
Zookeeper为了保证高吞吐和低延迟,在内存中维护了这个树状的目录结构,这种特性使得Zookeeper不能用于存放大量的数据,每个节点的存放数据上限为1M
zk的角色
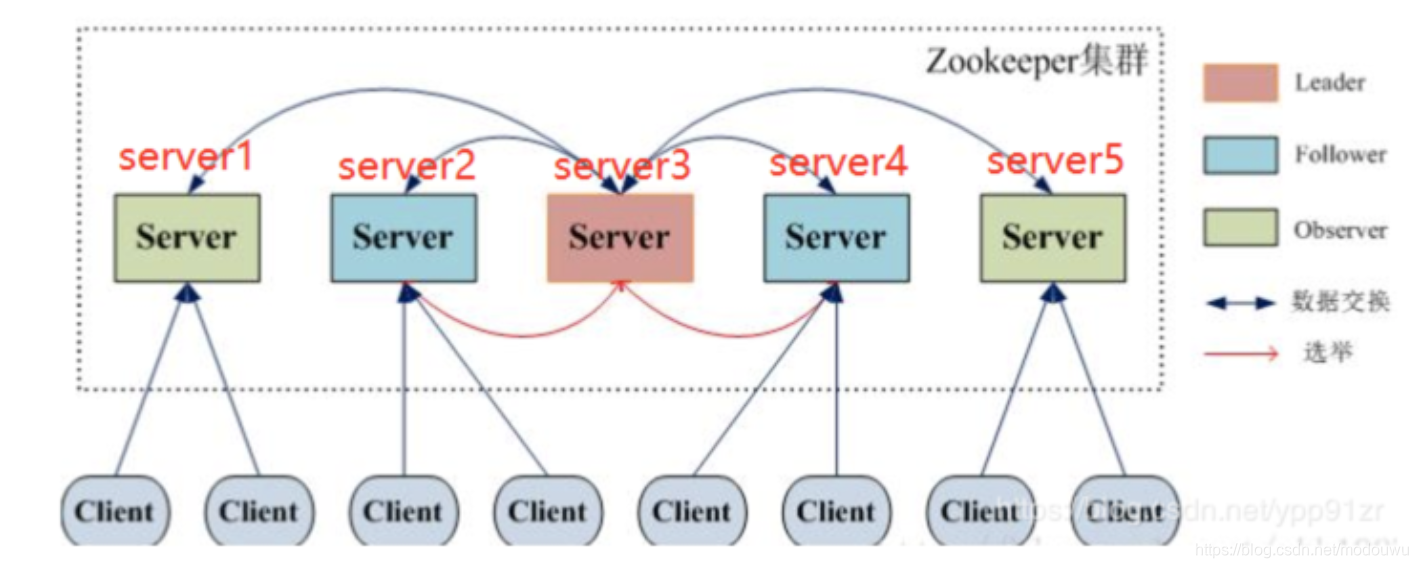
leader:
事务请求的唯一调度和处理者,保证集群事务处理的顺序性;
集群内各服务的协调者
follower:
处理客户端非事务性请求(读取数据),转发事务请求给Leader服务器;
参与事务请求Proposal的投票
参与Leader选举投票
observer:
同步最新状态,处理读请求,转发写请求;observer的目的是为了扩展系统,提高读取速度
leader选举机制
什么时候会发生选举
- 集群初始化的时候
- 运行期间leader出现故障
节点的四种状态
LEADING
LOOKING :选举中,正在寻找leader,即将进入leader选举流程中
FOLLOWING
OBSERVING
选举过程
半数通过:必须有大于一半的机器投票一致才能选出leader,因此通常集群的个数为奇数
在leader选举的时候会有30s-120s的过程,在这期间也是无法提供服务的
zxid:ZooKeeper Transaction Id,每次请求对应一个唯一的事务id
myid:zk服务器的唯一标识
初始化
假设机器是一台台启动,
1)(myid, ZXID)来表示,server1的初始投票为(1,0),server2的投票为(2,0),然后各自把投票发给其他机器
2)处理投票并pk,然后变更投票,此时server1变更投票为(2,0)
PK规则如下
· 优先检查ZXID。ZXID比较大的服务器优先作为Leader。
· 如果ZXID相同,那么就比较myid。myid较大的服务器作为Leader服务器
3)再次统计投票,此时选出了server02作为leader
4)如果此时server03,server04,server05才启动,由于leader已经选出来了,所以直接成为follower
运行期间
差不多,也是pk
数据同步
zookeeper的数据同步是为了保证各节点中数据的一致性。同步涉及两个流程:
1.正常的客户端数据提交
2.集群中某个节点宕机后的数据恢复
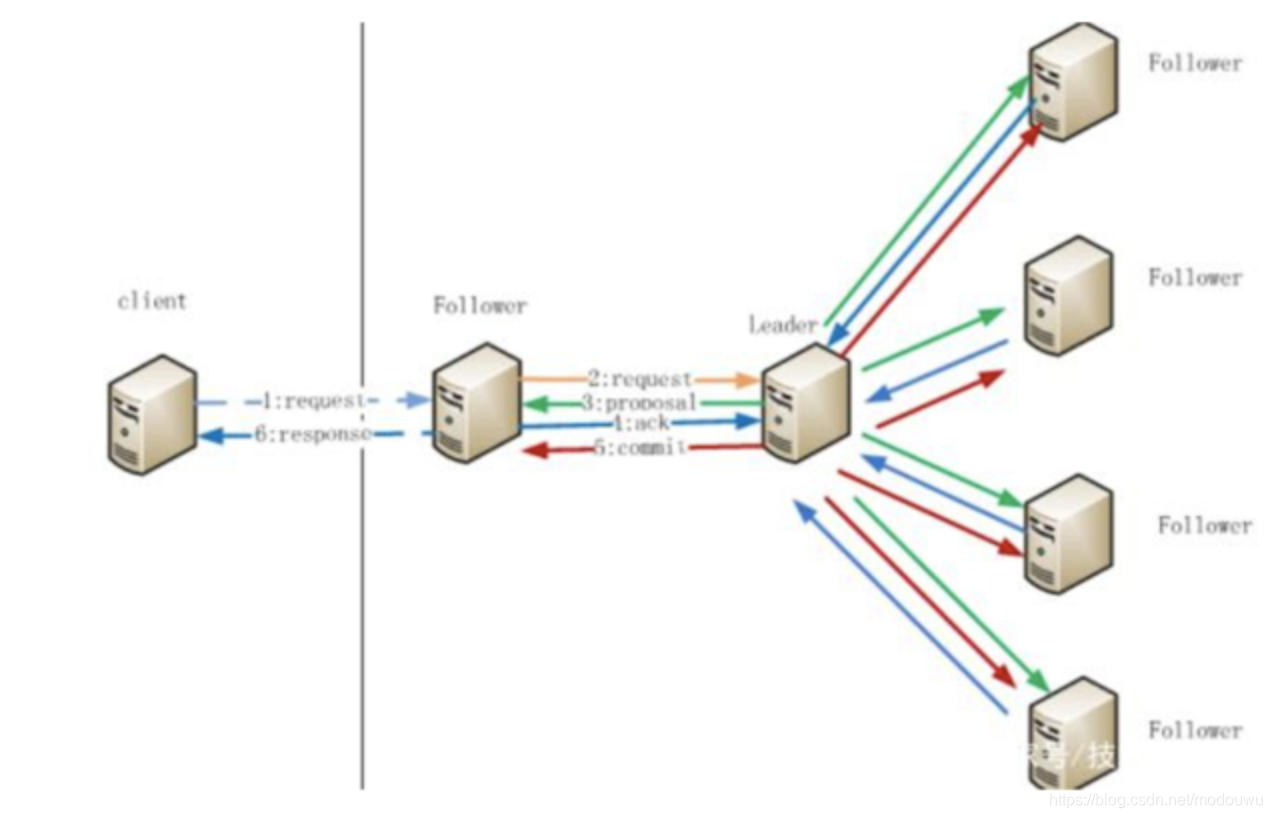
- 客户端写入流程
(1)client向zk中的server发送写请求,如果该节点不是leader,则把写请求转发给leader。
(2)leader将请求事务以proposal的形式分发给每个server
(3)follower接收到proposal的请求后,按照接收的先后顺序处理proposal,处理完(写完)ack
(4)leader收到该proposal过半的ack后,则发起事务提交(此时节点写完未提交),重新发起一个 commit的proposal
(5)follower收到commit的proposal后,记录事务提交,并将数据更新到内存数据库
(6)follower1写入成功后,通知client
注意:follower和observer都可接收写请求,只是接收完需要转发leader - 服务节点宕机同步
集群中某个节点宕机后,集群继续服务,宕机节点恢复,数据会不一致。因此,节点恢复启动时,
(1)寻找leader,对比数据是否一致
(2)一致,则可以直接对外服务;不一致,则需要数据同步
如何对比数据一致:ZXID(事物ID)来确认。比Leader小就需要同步
zxid说明:ZXID是一个长度64位的数字,其中低32位是按照数字递增,任何数据的变更都会导致,低32位的数字简单加1。高32位是leader周期编号,每当选举出一个新的leader时,新的leader就从本地事物日志中取出ZXID,然后解析出高32位的周期编号,进行加1,再将低32位的全部设置为0。这样就保证了每次新选举的leader后,保证了ZXID的唯一性而且是保证递增的
session会话
使用客户端来创建一个和zk服务端连接的句柄,这就是一个会话(session)。
创建session时,zk客户端会随意选择一个zk服务端来尝试连接。如果这个连接失败了,或者因为某种原因断开连接了,客户端会自动尝试下一个服务端,直到连接被成功建立。
如果zk客户端和zk服务端集群断开连接之后,在session超时时间之内,重新连接上了,那么session状态重新变为connected,如果在session超时时间之内没有连接上,那么session状态会变成expired
为什么zookeeper集群的数目,一般为奇数个?
- 2n和2n-1个服务器的容灾能力一样,所以为了节省服务器资源,一般我们采用奇数个数,作为服务器部署个数
- Paxos核心思想:当多数Server写成功,则任务数据写成功如果有3个Server,则两个写成功即可;如果有4或5个Server,则三个写成功即可
- Leader选举算法采用了Paxos协议
常见应用
1)数据发布与订阅
比如配置信息放在zk,各个服务启动时从zk获取最新配置,并且通过watcher模式动态更新
2)命名服务
有些名称要保持唯一性,通过在zk上create node来实现
3)分布式锁
一种通过create node来实现,一种控制时序
4)大数据
Hadoop,使用Zookeeper的事件处理确保整个集群只有一个NameNode,存储配置信息等.
HBase,使用Zookeeper的事件处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等
常见问题
1)如果leader节点宕机,在恢复后它还能被选为leader吗
不能,因为会重新选举(选举期间暂停对外服务,直到新的leader产生)
2)现在有三个节点, zk1,zk2,zk3, zk2是leader,zk2挂了的同时在zk1进行了delete操作,现在把zk1 和 zk3也挂掉,再把三个节点全部起来,那么现在zk2还是leader吗?
把zk1和zk3挂掉,再重启zk1,zk2,zk3,此时的选举,不再是一开始根据myid谁大谁就是leader,而是基于zxid(节点的事物ID)谁大谁就是leader,因为zk1更新了数据,此时它的zxid是最大的,所以启动后zk1是leader
特点
- ZK有1MB 的传输限制
- 如果有很多节点,ZK启动时相当的慢
- ZNode很大的时候很难清理
- 当很大量的包含成千上万的子节点的ZNode时, ZK的性能变得不好
- ZK的数据库完全放在内存中
Kafka
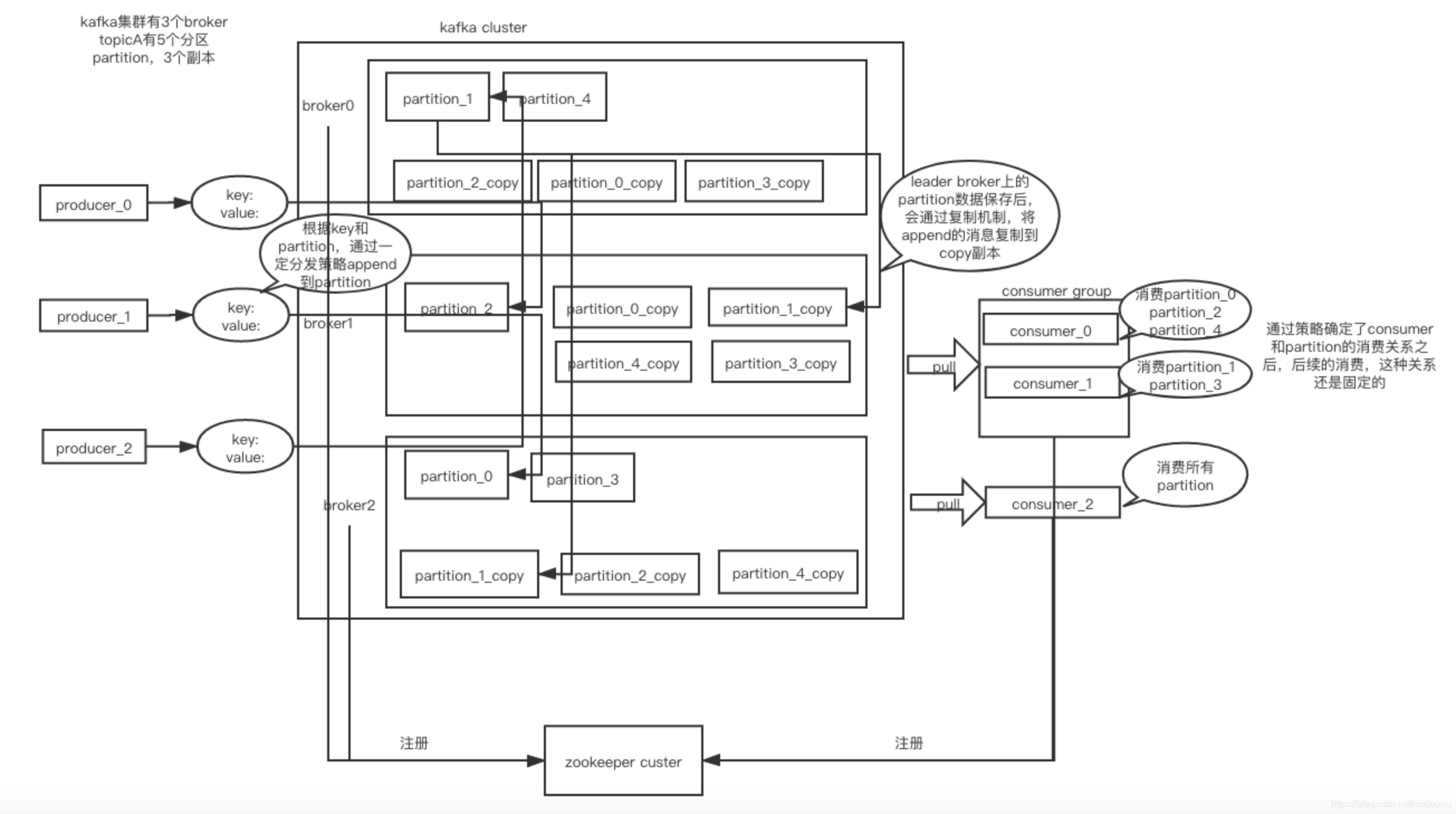
上图讲解:
安装及命令行使用
安装:brew install kafka
安装完成之后,kafka安装目录为
/usr/local/Cellar/kafka/2.1.0
配置文件目录
/usr/local/etc/kafka/
启动:
kafka基于zookkper的,先启动zk
/usr/local/Cellar/kafka/2.4.0/bin/zookeeper-server-start /usr/local/etc/kafka/zookeeper.properties
然后启动kafka
/usr/local/Cellar/kafka/2.1.0/bin/kafka-server-start /usr/local/etc/kafka/server.properties
如果想启动多个broker,则复制多份server.properties,更改broker.id、listeners和log.dirs即可
kafka-server-start –daemon server1.properties
创建一个topic
kafka-topics –create –zookeeper localhost:2181 –replication-factor 1 –partitions 1 –topic sunday
查看topic列表
kafka-topics –list –zookeeper localhost:2181
查看topic详情配置
kafka-topics –zookeeper localhost:2181 –describe –topic sunday
创建一个生产者
kafka-console-producer –broker-list localhost:9092 –topic sunday
生产数据:

创建一个消费者
kafka-console-consumer –bootstrap-server localhost:9092 –topic sunday –from-beginning
–from-beginning指定从第一条语句开始消费,可不要
消费数据:

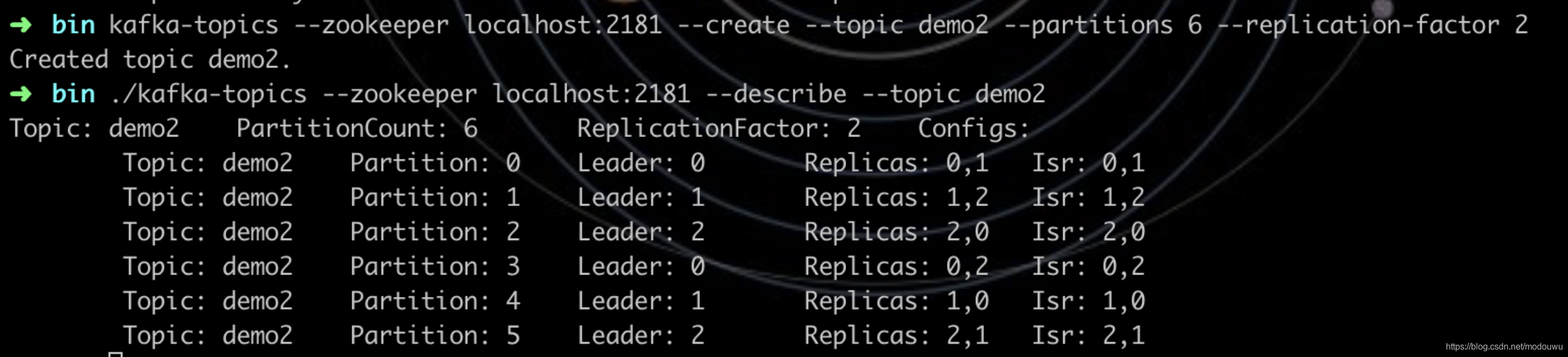
配置多个kafka的broker组成集群,然后配置多个分区partition多个副本replication,查看分区分配及副本分配情况:
此前先启动3个broker:

创建一个topic,并指定分区数为10,副本数为3
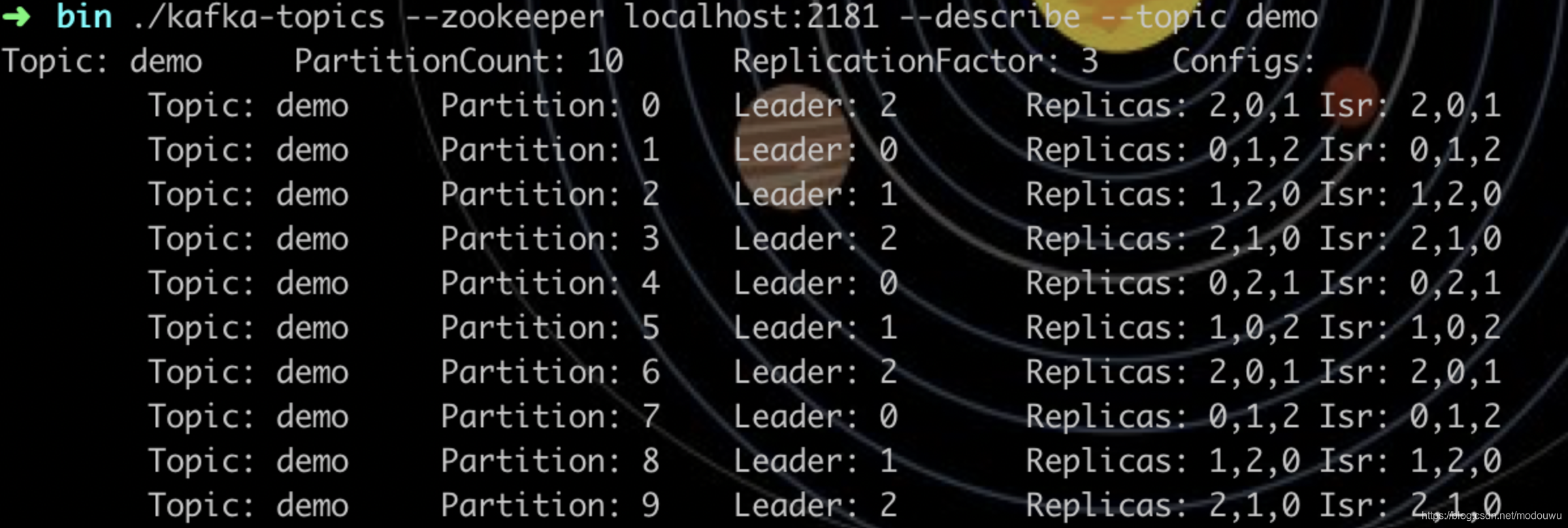
查看topic详情,第一行显示总体配置,分区数10,副本数3;第二行开始,显示各分区情况,共5列,分别为:topic名称、partition编号,此partions的leader broker编号,副本存放的broker编号,同步broker编号.上图中由于我们设置了10各分区,3个副本,并且开启了3个broker
基本概念和组件
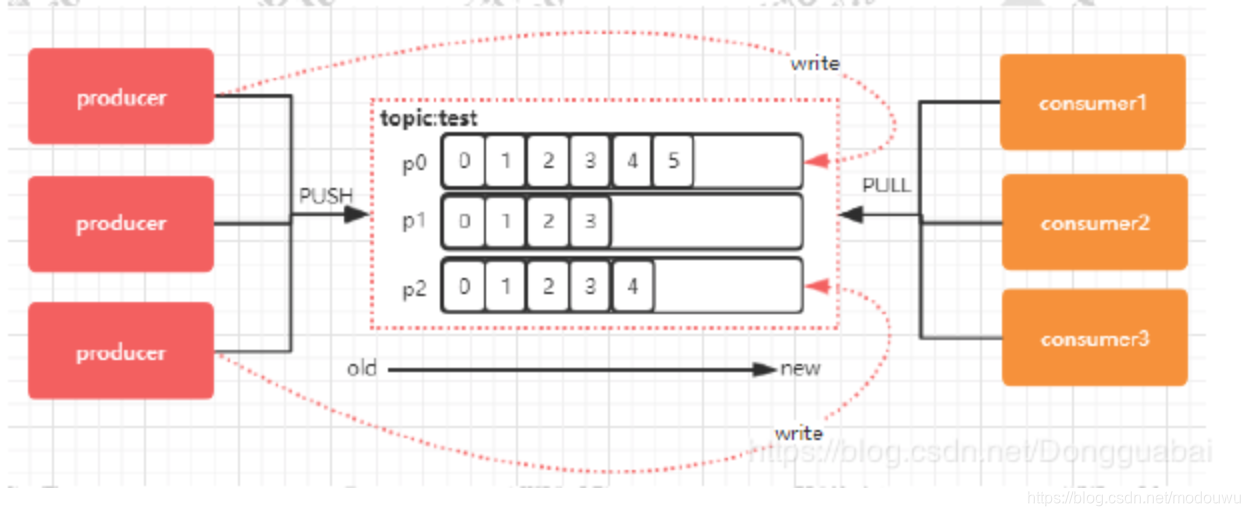
topic:每个topic可以划分多个分区,每个topic至少一个分区;同一个topic下的不同分区的数据是不同的,它们共同组成完整的topic消息
partition:消息在被添加到分区时,会分配一个offset,它是消息在此分区的唯一编号;通过这个offset,保证了消息在这个分区内的顺序;offset的顺序不跨分区,即kafka只保证消息在同一个分区的有序性
producer:
comsumer:一个consumer可以绑定监听多个topic
broker:缓存代理,Kafka集群中的一台或多台服务器统称broker
Segment:partition物理上由多个segment组成,每个Segment存着message信息
消息分发流程
消息到了broker之后,append到对应的partition
消息如何定位partition
kafka中的一条消息其实是由 Key + Value 组成的(Key 是可选项,可传空值,Value 也可以传空值),
在发送一条消息时,我们可以指定这个 Key,那么 Producer 会根据 Key 和 partition 机制来判断当前这条消息应该发送并存储到哪个 partition 中(这个就跟分片机制类似)。我们可以根据需要进行扩展 Producer 的 partition 机制(默认算法是 hash 取 %)。如果 Key 为 null,则会随机分配一个分区。这个随机是在这个参数“metadata.max.age.ms“的时间范围内随机选择一个。对于这个时间段内,如果 Key 为 null,则只会发送到唯一的分区。这个值默认情况下是 10 分钟更新一次(因为 partition 状态可能会发生变化)
java中实现Partitioner 接口扩展partition
消费者消费定位partition
- 一般每个 Topic 都会有多个 partition(主要是用于数据分片,减少消息的容量,从而提升 I/O 性能)。如果 Consumer1、Consumer2 和 Consumer3 都属于 group.id 为 1 的消费组。那么 Consumer1 就会消费 p0,Consumer2 就会消费 p1,Consumer3 就会消费 p2(这里是 Consumer 数量和 partition 数量一致,均匀分配)。
- 要注意的是如果 Consumer 数量比 partition 数量多,会有的 Consumer 闲置无法消费,这样是一个浪费。如果 Consumer 数量小于 partition 数量会有一个 Consumer 消费多个 partition。Kafka 在 partition 上是不允许并发的。
- Consuemr 数量建议最好是 partition 的整数倍。
- 还有一点,如果 Consumer 从多个 partiton 上读取数据,是不保证顺序性的,Kafka 只保证一个 partition 的顺序性,跨 partition 是不保证顺序性的。增减 Consumer、broker、partition 会导致 Rebalance。
多个partition在多个broker集群的分配策略
- 将所有 N 个Broker 和 i 个 Partition 排序(本例中 N = 3,i = 3)
- 将第 i 个 Partition 分配到 ( i % n)个 Broker 上。(这样 test-1 就分配到第一台了,以此类推)
kafka删除策略
- N天前的删除
- 保留最近的MGB数据
partition的复制
1)怎样传送消息:producer先把message发送到partition leader,再由leader发送给其他partition follower。(如果让producer发送给每个replica那就太慢了)
2)在向Producer发送ACK前需要保证有多少个Replica已经收到该消息:根据ack配的个数而定
3)怎样处理某个Replica不工作的情况:如果这个部工作的partition replica不在ack列表中,就是producer在发送消息到partition leader上,partition leader向partition follower发送message没有响应而已,这个不会影响整个系统,也不会有什么问题。如果这个不工作的partition replica在ack列表中的话,producer发送的message的时候会等待这个不工作的partition replca写message成功,但是会等到time out,然后返回失败因为某个ack列表中的partition replica没有响应,此时kafka会自动的把这个部工作的partition replica从ack列表中移除,以后的producer发送message的时候就不会有这个ack列表下的这个部工作的partition replica了。
(4)怎样处理Failed Replica恢复回来的情况:如果这个partition replica之前不在ack列表中,那么启动后重新受Zookeeper管理即可,之后producer发送message的时候,partition leader会继续发送message到这个partition follower上。如果这个partition replica之前在ack列表中,此时重启后,需要把这个partition replica再手动加到ack列表中。(ack列表是手动添加的,出现某个部工作的partition replica的时候自动从ack列表中移除的)
zookeeper协调控制
- 管理broker与consumer的动态加入与离开
- 触发负载均衡,当broker或consumer加入或离开时会触发负载均衡算法,使得一个consumer group内的多个consumer的订阅负载平衡
- 维护消费关系及每个partition的消费信息
消息持久化
Kafka中会把消息持久化到本地文件系统中,并且保持o(1)极高的效率。我们众所周知IO读取是非常耗资源的性能也是最慢的,这就是为了数据库的瓶颈经常在IO上,需要换SSD硬盘的原因。但是Kafka作为吞吐量极高的MQ,却可以非常高效的message持久化到文件。这是因为Kafka是顺序写入o(1)的时间复杂度,速度非常快。也是高吞吐量的原因。由于message的写入持久化是顺序写入的,因此message在被消费的时候也是按顺序被消费的,保证partition的message是顺序消费的。一般的机器,单机每秒100k条数据
建议
- consumer group下的consumer thread的数量等于partition数量,这样效率是最高的
- 如果producer的流量增大,当前的topic的parition数量=consumer数量,这时候的应对方式就是横向扩展:增加topic下的partition,同时增加这个consumer group下的consumer
- replica副本数目不能大于kafka broker节点的数目,否则报错。这里的replica数其实就是partition的副本总数,其中包括一个leader,其他的就是copy副本
kafka常见问题
kafka生产者写入单条记录过长
There are some messages at [Partition=Offset]: {default-0=177} whose size is larger than the fetch size 1048576 and hence cannot be ever returned. Increase the fetch size on the client (using max.partition.fetch.bytes), or decrease the maximum message size the broker will allow (using message.max.bytes).
设置kafka消费拉取字节数为512,服务启动消费线程即退出
消费时,拉取的记录大小比最大拉取字节数大,导致不能拉取完整记录返回,增大拉取字节数后即可修复
props.put(ConsumerConfig.MAX_PARTITION_FETCH_BYTES_CONFIG, 2048)