腾讯正式开源一个大规模、高质量的中文词向量数据集。数据集中有800多万中文词汇,相比现有搜狗实验室,清华和哈工大公布的语料库,覆盖率、新鲜度及准确性上有大幅的提高。
1、介绍
该语语料库给超过800万个中文单词和短语提供了200维矢量,有了这些词向量我们可以轻松的用于计算余弦相似度,海明距离,词向量距离等,可以广泛应用与具体的NLP处理、人工智能方向的应用。
与现有的汉语嵌入语料库相比,语料库的优越性主要在于覆盖率,新鲜度和准确性。
(1)覆盖率。语料库包含大量特定领域的词汇或词汇俚语,如“喀拉喀什河”,“皇帝菜”,“不念僧面念佛面”,“冰火两重天”,“煮酒论”英雄“,大多数现有的嵌入语料库都没有涵盖。
(2)新鲜度。语料库包含最近出现或流行的新词,如“恋与制作人”,“三生三世十里桃花”,“打电话”,“十动然拒”,“因吹斯汀”等。
(3)准确性。可以更好地嵌入中文单词或短语的语义,这都归因于大规模数据和精心设计的训练算法。
2、train
(1)数据来源。训练的数据包含从新闻,网页和小说收集的大型文本。来自不同域的文本数据使得能够覆盖各种类型的单词和短语。此外,最近收集的网页和新闻数据能够学习最新的语义表示。
(2)词汇建设。为了丰富的词汇,我们涉及维基百科和百度百科优质的短语。用这些语料进行充分发掘中,使用的分布式集群进行训练,极大的增加了AI训练的算力,最大限度的增强了新新短语的覆盖范围。
(3)训练算法。我们的语料库使用Directional Skip-Gram算法进行训练:明确区分用于单词嵌入的左右上下文,其基于单词共现和单词对的方向,即在上下文窗口中哪个单词在左侧。
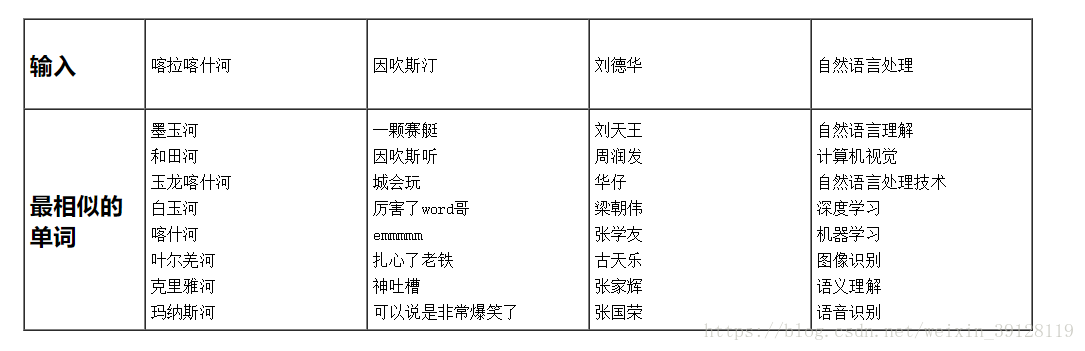
3、使用效果
用词向量计算余弦相似度求解词语的相似度,看看效果:
4、感谢
当前中文语料是十分匮乏的,搜狗实验室分享了批新闻语料,但获取难度和整理成本实在太大。清华和哈工大也分享了批语料但太少,以至于我有时需要把英文语料翻译成中文使用,感谢腾讯开源了如此大规模的中文分词数据集,我相信这对工业界还是学术界将启动良好的促进作用。
5、传送门
获取数据集地址:https://item.taobao.com/item.htm?spm=a1z10.1-c.w4004-20016008650.12.77d41edeF3D9kg&id=580138201544
请多多支持,谢谢!