一、综述
由于工作中很长一段时间都是在做语义分割系列的工作,所以这篇文章主要对自己用到的一些方法做个简单的总结,包括其优缺点等,以便日后能够及时复习查看。
目前语义分割的方法主要集中在两个大的结构上:1、encode-decode的结构:图像通过encode阶段进行特征抽取,decode则负责将抽取到的信息进行对应的分类复位;2、dialted convolutional结构,这种结构抛弃了pool层而采用了空洞卷积(dilated convolutional layers)进行代替,能够起到增加感受野的作用。
所以本文将会按照时间顺序来分别对FCN、SetNet、U-Net、DeepLab V1 (and V2)、RefineNet、PSPNet、DeepLab V3这几个典型的网络结构作分析。
二、 网络结构
1)FCN
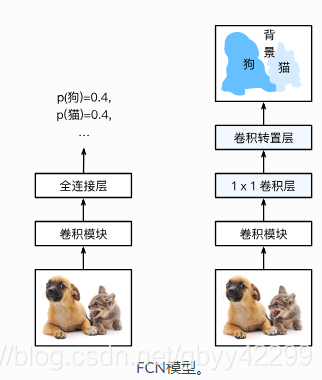
分类网络的分类层通常会在最后连接全连接层,它会将前面层卷积提取到的二维特征的矩阵压缩成一维的,从而丢失了空间信息,最后训练输出一个标量,用来分类。而FCN 的核心思想是将一个卷积网络的最后全连接输出层替换成转置卷积层来获取对每个输入像素的预测。具体来说,它去掉了过于损失空间信息的全局池化层,并将最后的全连接层替换成输出通道是原全连接层输出大小的 1×1 卷积层,最后接上转置卷积层来得到需要形状的输出。
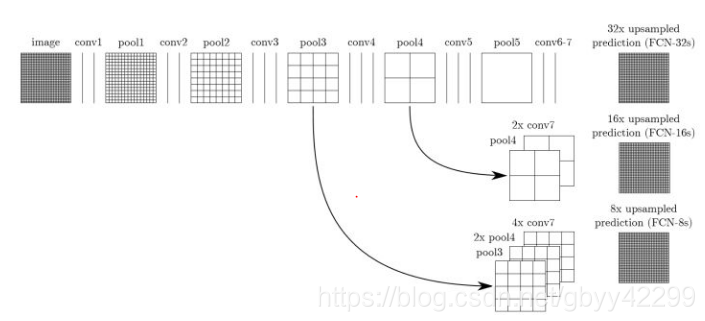
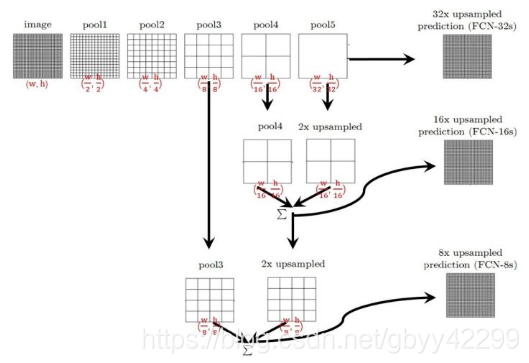
如上图所示,即为FCN的网络结构图,为了便于理解,我在mxnet的网站找了一张比较形象的图来解释一下这个网络结构,如下图:
FCN的结构就是将VGG16中的fc6和fc7都换成卷积,然后经过conv_transpose进行还原扩大,而FCN-8s和FCN-16s则是结合了前面pooling层的输出,然后进行element wise(对应值相加),然后输出。
- FCN-32s:直接对pool5 feature进行32倍上采样获得32x upsampled feature,再对32x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。
- FCN-16s:首先对pool5 feature进行2倍上采样获得2x upsampled feature,再把pool4 feature和2x upsampled feature逐点相加,然后对相加的feature进行16倍上采样,并softmax prediction,获得16x upsampled feature prediction。
- FCN-8s,首先进行pool4+2x upsampled feature逐点相加,然后又进行pool3+2x upsampled逐点相加,即进行更多次特征融合。具体过程与16s类似.
根据上面三种不同的connect对比可知:使用多层feature融合有利于提高分割准确性。即:准确率FCN-32s < FCN-16s < FCN-8。
难点:作者开源了代码,但是细细度过后就会发现有几个比较奇怪的难以理解的点,我写出来如下:
1、作者在conv1_1中采用的padding=100,为什么呢?

为什么需要padding=100呢?
因为作者为了保证输出的尺寸不至于太小,所以对第一层进行了padding。当然了还有的做法就是可以减少池化的层,但是这样做会带来的问题就是原先的网络结构不可用了,也就没办法fine-tune了。当然了还有一种比较好的办法就是想deeplab那样,将pooling的stride改为1,padding=1,这样之后池化并没有带来图片尺寸的减少。
2)SegNet
网络结构如下:

segnet是个典型的encode-decode结构,和FCN的思路很像。segnet采用的是vgg16全连接层前面的网络结构。
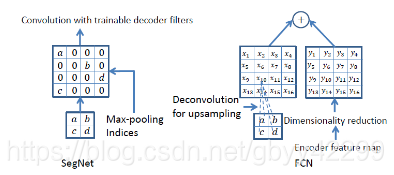
这个网络结构比较特殊的地方在于将池化层结果应用到译码过程。引入了更多的编码信息。使用的是pooling indices而不是直接复制特征,只是将编码过程中 pool 的位置记下来,在 uppooling 是使用该信息进行 pooling 。
Upsamping就是Pooling的逆过程(index在Upsampling过程中发挥作用),Upsamping使得图片变大2倍。我们清楚的知道Pooling之后,每个filter会丢失了3个权重,这些权重是无法复原的,但是在Upsamping层中可以得到在Pooling中相对Pooling filter的位置。所以Upsampling中先对输入的特征图放大两倍,然后把输入特征图的数据根据Pooling indices放入,下图所示,Unpooling对应上述的Upsampling,switch variables对应Pooling indices。
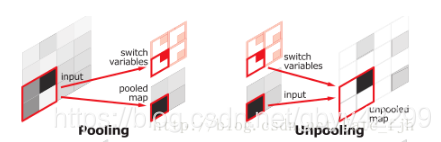
对比FCN可以发现SegNet在Unpooling时用index信息,直接将数据放回对应位置,后面再接Conv训练学习。这个上采样不需要训练学习(只是占用了一些存储空间)。反观FCN则是用transposed convolution策略,即将feature 反卷积后得到upsampling,这一过程需要学习,同时将encoder阶段对应的feature做通道降维,使得通道维度和upsampling相同,这样就能做像素相加得到最终的decoder输出.
对于这个paper中对于类别不平衡的问题也进行了相应的加权,计算方法如下:
f(class) = frequency(class) / (image_count(class) * w * h)
weight(class) = median of f(class)) / f(class)
其中frequency(class)的意思是该类别的training set的总像素的个数;比如在我的数据集合中training set的数量为500张图片,房屋像素的个数总和为30000个像素;
image_count(class)的意思是在training set中含有该类别的像素的图片的数量;比如含有房屋的图片的个数位467张
,w*h为图片的尺寸;median of f(class))为计算出的f(class) 的中位数;
附我实现的代码如下:https://github.com/gbyy422990/segnet_tf/blob/master/median_frequency_balancing.py
另外一种Bayesian SegNet模型我后面再补充。
3)U-Net
这个网络结构由于比较简单,在这里就不再赘述了,结构图如下:
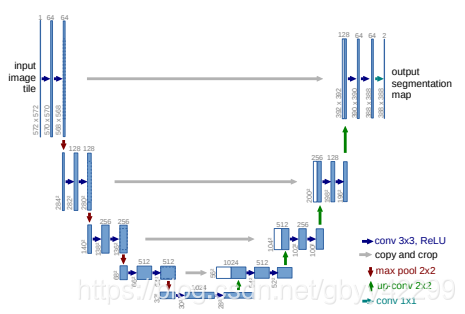
依然使用Vgg16进行特征抽取,然后上采样的时候结合前面的同等大小的采样过程中的特征进行channel维度上的拼接。
U-Net采用了与FCN完全不同的特征融合方式:拼接!即:与FCN的逐点相加不同,Unet采用的是特征在channel维度上拼接在一起,形成更“厚”的特征。
DeepLab V1
TODO
DeepLab V2
TODO
RefineNet
TODO
PSPNet
TODO