目录
二、MapReduce的组成架构类似hdfs,也采用master/slave模式
一、MR概述
- MapReduce是一个分布式运算的框架。
- 优点:易于编程、扩展性良好、容错性高、适合上千台服务器集群并发工作(PB级以上)。
- 缺点:不擅长实时、流式、DAG计算。
- 三类实例进程
- MapTask:Map流程
- ReduceTask:Reduce过程
- MrAppMaster:负责整个程序的过程调度和状态协调。
- MapReduce编程规范
- Mapper阶段:编写Map阶段的map()方法(MapTask进程)
- Reducer阶段:编写Reduce阶段的reduce()方法(ReduceTask进程)
- Driver阶段:相当于Yarn集群的客户端,把我们写好的封装了MapReduce程序相关运行参数的Job打包发送给Yarn集群
二、MapReduce的组成架构
类似hdfs,也采用master/slave模式
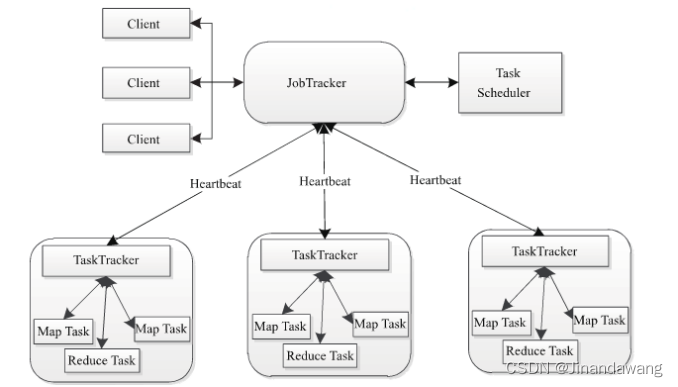
- Client:Job在客户端→通过Client类→打包程序(包含配置)→存到HDFS→存储路径发给JobTracker的master服务→master服务创建两类Task任务→分发给各个TaskTracker;
- JobTracker:负责监控和资源调度。监控整个Job和各个TaskTracker的情况。
- TaskTracker:将本节点的资源划分为slot,将两类slot(计算资源)分给两类Task使用,并定期向JobTracker返回心跳。(通过限定slot数量限定task数量)。
- Task:MapTask & ReduceTask。
三、MapReduce工作过程详解(包含shuffle)
- 第一遍理解:Map(→Shuffle→)Reduce
- 第二遍理解:Client提交任务给集群,map函数分片开启多个MapTask,每个map节点尽可能在本节点或本机架上读取数据进行计算(减少数据通信量),全部Map完成计算与整理后将中间结果存储在本地机器上,同时通知主节点并告知中间结果的位置,然后开启Reduce节点的运算,最终计算结果输出到一个结果文件,即总结果文件。
- 第三遍理解:
- Read阶段:Client提交任务给集群,集群开启Map阶段任务,首先划分split分片,并解析出一个个k-v对;
- Map切片(一个split对应于map任务):根据参数进行切片(逻辑切片),默认情况下,切片数等于Block的数量。切片是在针对每一个文件单独切片。
- FileInputFormat(默认切片,一个切片一个Map任务,TextInputFormat是其实现类);
- CombineFileInputFormat(优化,超过两倍的先切一片,切至不够两倍则对半切分,完成切分后不满一片的小片可以进行合并,这时的小片两两合并是绝对不会大于一片的容量的)。
- Map切片(一个split对应于map任务):根据参数进行切片(逻辑切片),默认情况下,切片数等于Block的数量。切片是在针对每一个文件单独切片。
- Map阶段:k-v对经过map()方法统计计算形成新的k-v对;
- Collect阶段(Group阶段):MapTask会收集这些新的k-v对,并调用OutputCollector.collect()输出结果
- Partition阶段:在函数OutputCollector.collect()内部,它会调用Partitioner将生成的k-v进行分区,形成一个个partition分区;
- Spill阶段:这些结果分好区后会“溢出”写入一环形缓冲区;
- Sort阶段(排序):先利用快排按照分区编号Partition对每个分区内的key进行排序(此时同一分区内的数据按key值顺序存放);
- Merge阶段(聚合):如果设置了combiner,在写入磁盘前就要对分区内部的数据进行一次聚合便于后续处理;
- 分区数据元数据记录。(记录中间文件的位置,开启Reduce阶段)。
- (缓冲区大小由参数buffer.size决定)这个环形缓冲区每用满80%(buffer.size),就会锁定这80%的数据,并溢写至磁盘(锁定时,继续往没有用完的20%写入,由此可以知道为什么要使用环形缓冲区,并设置spill.percent=0.8)生成一个临时文件;
- Reduce阶段(每个ReduceTask会不断询问JobTracker的Map任务是否已经完成)
- Copy:将上述Combine阶段形成的文件Copy到Reduce端,不同的分区会被领取到不同的ReduceTask进行并行计算;
- Sort&Merge:多个溢写文件不断归并排序溢写形成一个大的文件;
- Reduce:执行reduce函数中定义的各种映射生成最终文件,并保存到HDFS上。
- Read阶段:Client提交任务给集群,集群开启Map阶段任务,首先划分split分片,并解析出一个个k-v对;
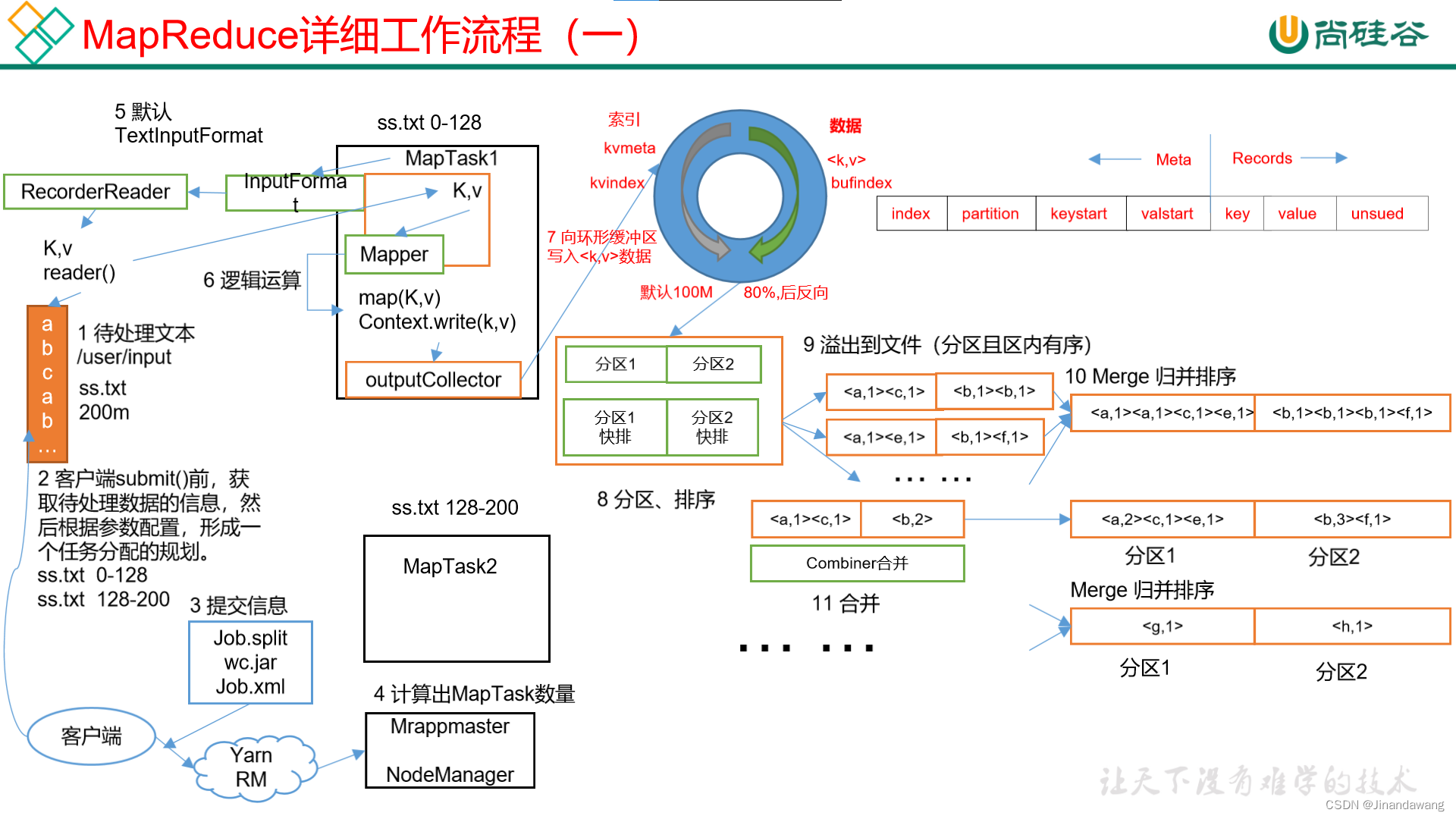
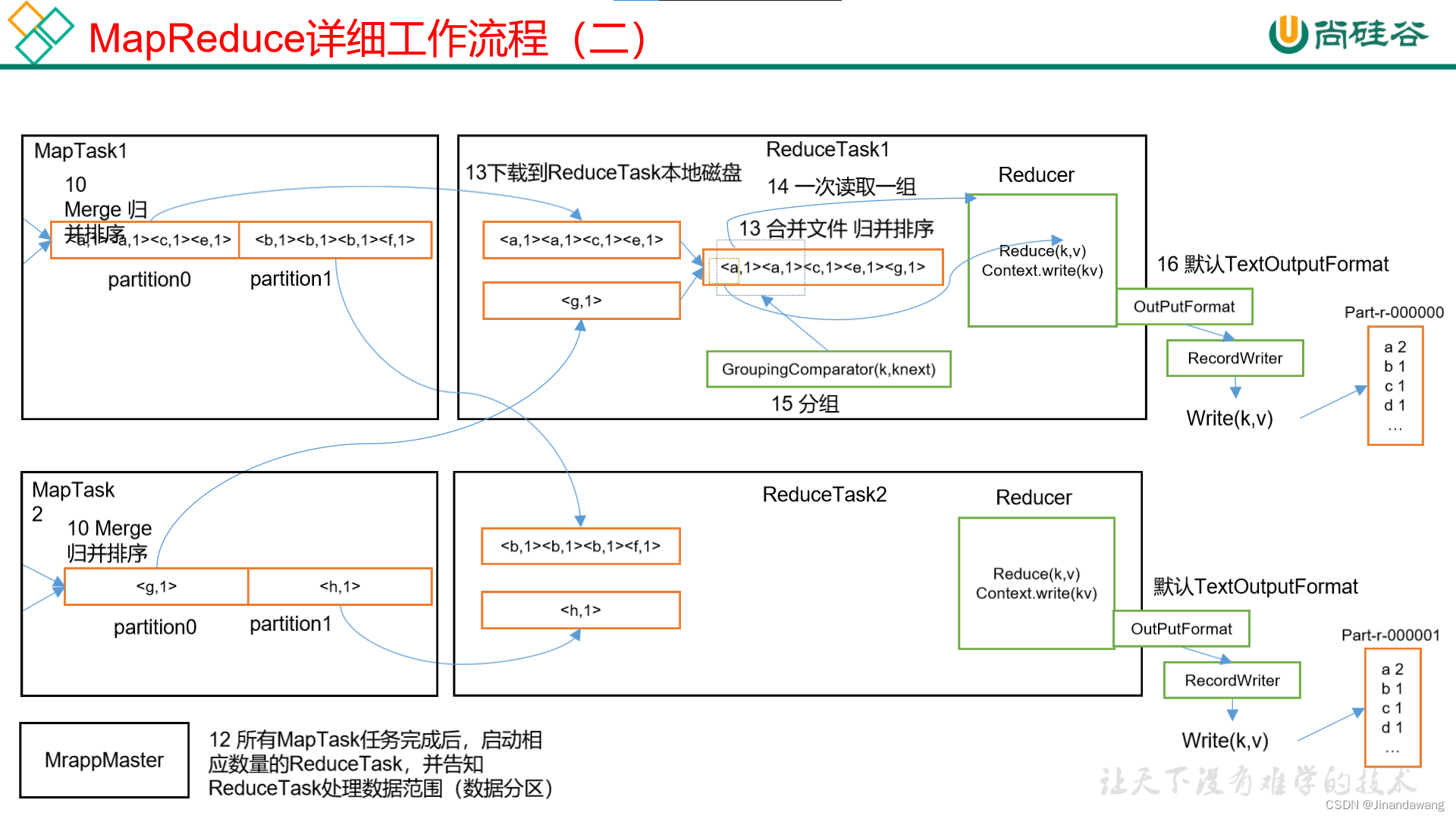
- Shuffle阶段包括图示的第7步-第16步。(其实差不多就是绝大部分的Map阶段和整个Reduce阶段了)。
四、MapReduce常用压缩
- 选用压缩需要考虑的主要因素:压缩/解压速率、压缩率、压缩后是否支持split切片。
- MapReduce的任意阶段都可以用使用压缩。
- Gzip:速度较快、压缩率较高、不支持split(压缩完大小小于一个Block的可以考虑);
- Bzip2:速度慢、压缩率很高、支持split;
- Lzo:速度较快、压缩率合理、支持split;(hadoop中最流行的压缩方式,适合单个文件特别大的,单个文件越大Lzo优点越明显);
- Snappy:速度快、压缩率合理、不支持split;(Map输出数据比较大可以用这种压缩)
