自己参考大牛博客及视频写了一些关于并发的感悟,高并发的处理思路,无外乎以下几种
1 代码层面: 锁优化措施(见本文内容)
2 应用层面:缓存 队列 限流 熔断
3数据库层面: 分库分表 读写分离
JDK常见并发包处理工具中,ReentrantLock、countdownlanth、currenthasp、AQS源码一定要多读多看,理解里面的设计精髓。带着问题去思考,去看源码,会更加有效。
一:ReentrantLock源码分析:
阻塞队列是利用ReentrantLock配合condition中的asigl、await方法实现的
读写分离锁:读锁是利用到了共享模式,写锁是用到了独占模式,与synchronize相比,可以避免读读互排斥,降低了锁的范围
1.Java并发库中ReetrantReadWriteLock实现了ReadWriteLock接口并添加了可重入的特性
2.ReetrantReadWriteLock读写锁的效率明显高于synchronized关键字
3.ReetrantReadWriteLock读写锁的实现中,读锁使用共享模式;写锁使用独占模式,换句话说,读锁可以在没有写锁的时候被多个线程同时持有,写锁是独占的
4.ReetrantReadWriteLock读写锁的实现中,需要注意的,当有读锁时,写锁就不能获得;而当有写锁时,除了获得写锁的这个线程可以获得读锁外,其他线程不能获得读锁
设置了这个 State 变量,我们之前分析过 AQS 的源码,这个变量可以说是 AQS 实现的核心,通过控制这个变量,能够实现共享共享锁或者独占锁。
那么,如果让我们来设计这个CountDownLatch ,我们该如何设计呢?
事实上,很简单,我们只需要对 state 变量进行减 1 操作,直到这个变量变成 0,我们就唤醒主线程。
- 将当前线程包装成一个 Node 对象,加入到 AQS 的队列尾部。
- 如果他前面的 node 是 head ,便可以尝试获取锁了。
- 如果不是,则阻塞等待,调用的是 LockSupport.park(this);
CountDown 的 await 方法就是通过 AQS 的锁机制让主线程阻塞等待。而锁的实现就是通过构造器中设置的 state 变量来控制的。当 state 是 0 的时候,就可以获取锁。然后执行后面的逻辑。
总的来说,CountDownLatch 还是比较简单的。说白了就是通过共享锁实现的。在我们的代码中,只有一个线程会阻塞,那就是我们的主线程,其余的线程就是在不停的释放 state 变量,直到为 0。从 AQS 的角度来讲,整个工作流程如下图:

简单的一个流程图,CountDownLatch 就是通过使用 AQS 的机制来实现倒计时门栓的。
作者:莫那一鲁道
链接:https://www.jianshu.com/p/a7bbba29b171
來源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。
二:ReentrantLock源码分析:
- 公平锁与非公平锁是如何实现的?
- 多个线程,只有一个线程获取锁时,其他线程是如何被唤醒的
- 如何线程安全的修改锁状态位?
- 得不到锁的线程,如何排队?
- 与synchronize区别
ReentrantLock继承AQS独占式方法,自旋锁的思想是:假设有1000个线程等待获取锁,是根据CAS及volatile 修改的状态变量进行判断的,当前线程的锁释放后,只会通知队列中的第一个线程去竞争锁,减少了并发冲突。(ZK的分布式锁,为了避免惊群效应,也使用了类似的方式:获取不到锁的线程只监听前一个节点)
为什么说JUC中的实现是基于CLH的“变种”,因为原始CLH队列,一般用于实现自旋锁。而JUC中的实现,获取不到锁的线程,一般会时而阻塞,时而唤醒。阻塞唤醒是通过locksupport中的park、UNpark方法实现的
实现锁的关键在于:
- 通过CAS操作与volatile变量互相配合,线程安全的修改锁标志位
- 基于CLH队列,实现锁的排队策略
public abstract class AbstractQueuedSynchronizer{
//锁状态标志位:volatile变量(多线程间通过此变量判断锁的状态)
private volatile int state;
protected final int getState() {
return state;
}
protected final void setState(int newState) {
state = newState;
}
}
abstract static Sync extends AbstractQueuedSynchronizer {
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
//volatile读,确保了锁状态位的内存可见性
int c = getState();
//锁还没有被其他线程占用
if (c == 0) {
//此时,如果多个线程同时进入,CAS操作会确保,只有一个线程修改成功
if (compareAndSetState(0, acquires)) {
//设置当前线程拥有独占访问权
setExclusiveOwnerThread(current);
return true;
}
}
//当前线程就是拥有独占访问权的线程,即锁重入
else if (current == getExclusiveOwnerThread()) {
//重入锁计数+1
int nextc = c + acquires;
if (nextc < 0) //溢出
throw new Error("Maximum lock count exceeded");
//只有获取锁的线程,才能进入此段代码,因此只需要一个volatile写操作,确保其内存可见性即可
setState(nextc);
return true;
}
return false;
}
//只有获取锁的线程才会执行此方法,因此只需要volatile读写确保内存可见性即可
protected final boolean tryRelease(int releases) {
//锁计数器-1
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
//锁计数器为0,说明锁被释放
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
}
/**
* 非公平锁
*/
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
/**
* Performs lock. Try immediate barge, backing up to normal
* acquire on failure.
*/
final void lock() {
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
/**
* 公平锁
*/
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {
acquire(1);
}
/**
* Fair version of tryAcquire. Don't grant access unless
* recursive call or no waiters or is first.
*/
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}公平锁、非公平锁都是静态内部类,区别就在于hasQueuedPredecessors这个方法,
因此公平锁和非公平锁的区别就在于多了hasQueuedPredecessors判断。
public final boolean hasQueuedPredecessors() {
Node t = tail;
Node h = head;
Node s;
return h != t &&
((s = h.next) == null || s.thread != Thread.currentThread());
}
hasQueuedPredecessors中,如果tail和head不同,并且head的next为空或者head的next的线程不是当前线程,则表示队列不为空。有两种情况会导致h的next为空:
1)当前线程进入hasQueuedPredecessors的同时,另一个线程已经更改了tail(在enq中),但还没有将head的next指向自己,这中情况表明队列不为空;
2)当前线程将head赋予h后,head被另一个线程移出队列,导致h的next为空,这种情况说明锁已经被占用。
如果队列不为空(hasQueuedPredecessors返回true),则tryAcquire返回false,线程将进入等待队列(后面的流程和非公平锁一致)。
synchronize 优先使用同步代码块,也不使用同步的方法,原因是同步是会锁所有的对象实例
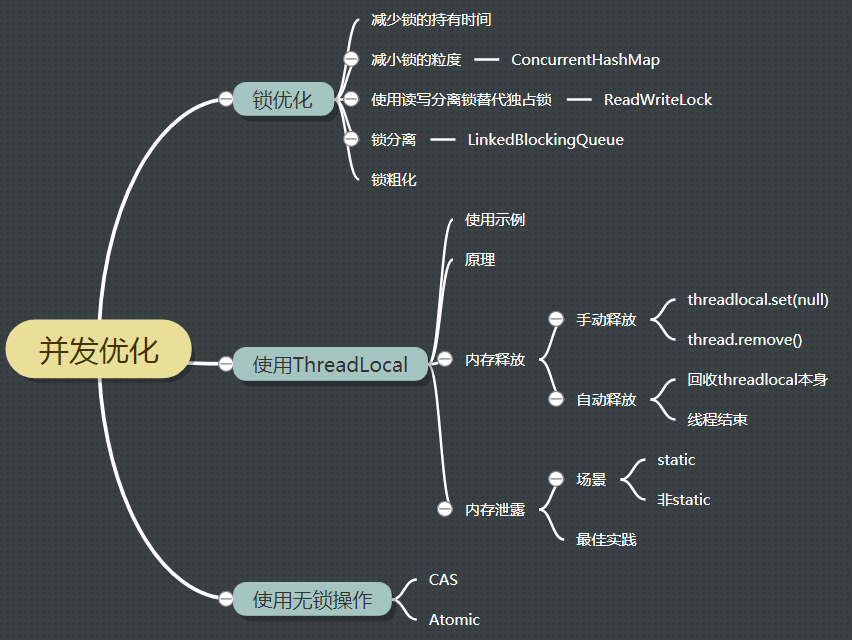
锁优化
减少锁的持有时间
例如避免给整个方法加锁
1 public synchronized void syncMethod(){
2 othercode1();
3 mutextMethod();
4 othercode2();
5 }改进后

1 public void syncMethod2(){
2 othercode1();
3 synchronized(this){
4 mutextMethod();
5 }
6 othercode2();
7 }
减小锁的粒度
将大对象,拆成小对象,大大增加并行度,降低锁竞争. 如此一来偏向锁,轻量级锁成功率提高.
一个简单的例子就是jdk内置的ConcurrentHashMap与SynchronizedMap.
Collections.synchronizedMap
其本质是在读写map操作上都加了锁, 在高并发下性能一般.
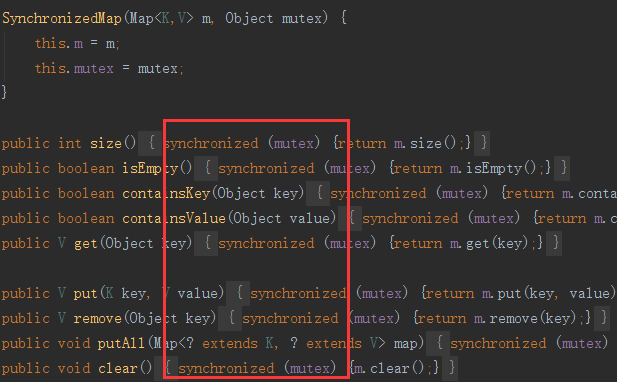
ConcurrentHashMap
内部使用分区Segment来表示不同的部分, 每个分区其实就是一个小的hashtable. 各自有自己的锁.
只要多个修改发生在不同的分区, 他们就可以并发的进行. 把一个整体分成了16个Segment, 最高支持16个线程并发修改.
代码中运用了很多volatile声明共享变量, 第一时间获取修改的内容, 性能较好.
读写分离锁替代独占锁
顾名思义, 用ReadWriteLock将读写的锁分离开来, 尤其在读多写少的场合, 可以有效提升系统的并发能力.
- 读-读不互斥:读读之间不阻塞。
- 读-写互斥:读阻塞写,写也会阻塞读。
- 写-写互斥:写写阻塞。
锁分离
在读写锁的思想上做进一步的延伸, 根据不同的功能拆分不同的锁, 进行有效的锁分离.
一个典型的示例便是LinkedBlockingQueue,在它内部, take和put操作本身是隔离的,
有若干个元素的时候, 一个在queue的头部操作, 一个在queue的尾部操作, 因此分别持有一把独立的锁.
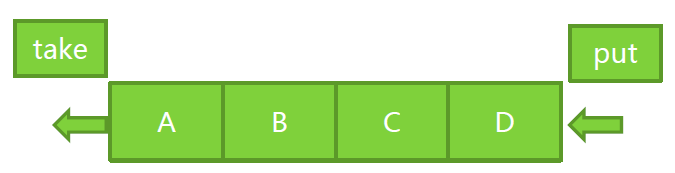
1 /** Lock held by take, poll, etc */
2 private final ReentrantLock takeLock = new ReentrantLock();
3
4 /** Wait queue for waiting takes */
5 private final Condition notEmpty = takeLock.newCondition();
6
7 /** Lock held by put, offer, etc */
8 private final ReentrantLock putLock = new ReentrantLock();
9
10 /** Wait queue for waiting puts */
11 private final Condition notFull = putLock.newCondition();
锁粗化
通常情况下, 为了保证多线程间的有效并发, 会要求每个线程持有锁的时间尽量短,
即在使用完公共资源后, 应该立即释放锁. 只有这样, 等待在这个锁上的其他线程才能尽早的获得资源执行任务.
而凡事都有一个度, 如果对同一个锁不停的进行请求 同步和释放, 其本身也会消耗系统宝贵的资源, 反而不利于性能的优化
一个极端的例子如下, 在一个循环中不停的请求同一个锁.
1 for(int i = 0; i < 1000; i++){
2 synchronized(lock){
3
4 }
5 }
6
7 // 优化后
8 synchronized(lock){
9 for(int i = 0;i < 1000; i++){
10
11 }
12 }
锁粗化与减少锁的持有时间, 两者是截然相反的, 需要在实际应用中根据不同的场合权衡使用.
JDK中各种涉及锁优化的并发类可以看之前的博文: 并发包总结
ThreadLocal
除了控制有限资源访问外, 我们还可以增加资源来保证对象线程安全.
对于一些线程不安全的对象, 例如SimpleDateFormat, 与其加锁让100个线程来竞争获取,
不如准备100个SimpleDateFormat, 每个线程各自为营, 很快的完成format工作.
示例
1 public class ThreadLocalDemo {
2
3 public static ThreadLocal<SimpleDateFormat> threadLocal = new ThreadLocal();
4
5 public static void main(String[] args){
6 ExecutorService service = Executors.newFixedThreadPool(10);
7 for (int i = 0; i < 100; i++) {
8 service.submit(new Runnable() {
9 @Override
10 public void run() {
11 if (threadLocal.get() == null) {
12 threadLocal.set(new SimpleDateFormat("yyyy-MM-dd"));
13 }
14
15 System.out.println(threadLocal.get().format(new Date()));
16 }
17 });
18 }
19 }
20 }
原理
对于set方法, 先获取当前线程对象, 然后getMap()获取线程的ThreadLocalMap, 并将值放入map中.
该map是线程Thread的内部变量, 其key为threadlocal, vaule为我们set进去的值.
1 public void set(T value) {
2 Thread t = Thread.currentThread();
3 ThreadLocalMap map = getMap(t);
4 if (map != null)
5 map.set(this, value);
6 else
7 createMap(t, value);
8 }
对于get方法, 自然是先拿到map, 然后从map中获取数据.
1 public T get() {
2 Thread t = Thread.currentThread();
3 ThreadLocalMap map = getMap(t);
4 if (map != null) {
5 ThreadLocalMap.Entry e = map.getEntry(this);
6 if (e != null)
7 return (T)e.value;
8 }
9 return setInitialValue();
10 }
内存释放
- 手动释放: 调用threadlocal.set(null)或者threadlocal.remove()即可
- 自动释放: 关闭线程池, 线程结束后, 自动释放threadlocalmap.
1 public class StaticThreadLocalTest {
2
3 private static ThreadLocal tt = new ThreadLocal();
4 public static void main(String[] args) throws InterruptedException {
5 ExecutorService service = Executors.newFixedThreadPool(1);
6 for (int i = 0; i < 3; i++) {
7 service.submit(new Runnable() {
8 @Override
9 public void run() {
10 BigMemoryObject oo = new BigMemoryObject();
11 tt.set(oo);
12 // 做些其他事情
13 // 释放方式一: 手动置null
14 // tt.set(null);
15 // 释放方式二: 手动remove
16 // tt.remove();
17 }
18 });
19 }
24 // 释放方式三: 关闭线程或者线程池
25 // 直接new Thread().start()的场景, 会在run结束后自动销毁线程
26 // service.shutdown();
27
28 while (true) {
29 Thread.sleep(24 * 3600 * 1000);
30 }
31 }
32
33 }
34 // 构建一个大内存对象, 便于观察内存波动.
35 class BigMemoryObject{
36
37 List<Integer> list = new ArrayList<>();
38
39 BigMemoryObject() {
40 for (int i = 0; i < 10000000; i++) {
41 list.add(i);
42 }
43 }
44 }
内存泄露
内存泄露主要出现在无法关闭的线程中, 例如web容器提供的并发线程池, 线程都是复用的.
由于ThreadLocalMap生命周期和线程生命周期一样长. 对于一些被强引用持有的ThreadLocal, 如定义为static.
如果在使用结束后, 没有手动释放ThreadLocal, 由于线程会被重复使用, 那么会出现之前的线程对象残留问题,
造成内存泄露, 甚至业务逻辑紊乱.
对于没有强引用持有的ThreadLocal, 如方法内变量, 是不是就万事大吉了呢? 答案是否定的.
虽然ThreadLocalMap会在get和set等操作里删除key 为 null的对象, 但是这个方法并不是100%会执行到.
看ThreadLocalMap源码即可发现, 只有调用了getEntryAfterMiss后才会执行清除操作,
如果后续线程没满足条件或者都没执行get set操作, 那么依然存在内存残留问题.
1 private ThreadLocal.ThreadLocalMap.Entry getEntry(ThreadLocal key) {
2 int i = key.threadLocalHashCode & (table.length - 1);
3 ThreadLocal.ThreadLocalMap.Entry e = table[i];
4 if (e != null && e.get() == key)
5 return e;
6 else
7 // 并不是一定会执行
8 return getEntryAfterMiss(key, i, e);
9 }
10
11 private ThreadLocal.ThreadLocalMap.Entry getEntryAfterMiss(ThreadLocal key, int i, ThreadLocal.ThreadLocalMap.Entry e) {
12 ThreadLocal.ThreadLocalMap.Entry[] tab = table;
13 int len = tab.length;
14
15 while (e != null) {
16 ThreadLocal k = e.get();
17 if (k == key)
18 return e;
19 // 删除key为null的value
20 if (k == null)
21 expungeStaleEntry(i);
22 else
23 i = nextIndex(i, len);
24 e = tab[i];
25 }
26 return null;
27 }
最佳实践
不管threadlocal是static还是非static的, 都要像加锁解锁一样, 每次用完后, 手动清理, 释放对象.
无锁
与锁相比, 使用CAS操作, 由于其非阻塞性, 因此不存在死锁问题, 同时线程之间的相互影响,
也远小于锁的方式. 使用无锁的方案, 可以减少锁竞争以及线程频繁调度带来的系统开销.
例如生产消费者模型中, 可以使用BlockingQueue来作为内存缓冲区, 但他是基于锁和阻塞实现的线程同步.
如果想要在高并发场合下获取更好的性能, 则可以使用基于CAS的ConcurrentLinkedQueue.
同理, 如果可以使用CAS方式实现整个生产消费者模型, 那么也将获得可观的性能提升, 如Disruptor框架.
关于无锁, 这边不再赘述, 之前博文已经有所介绍, 具体见: Java高并发之无锁与Atomic源码分析