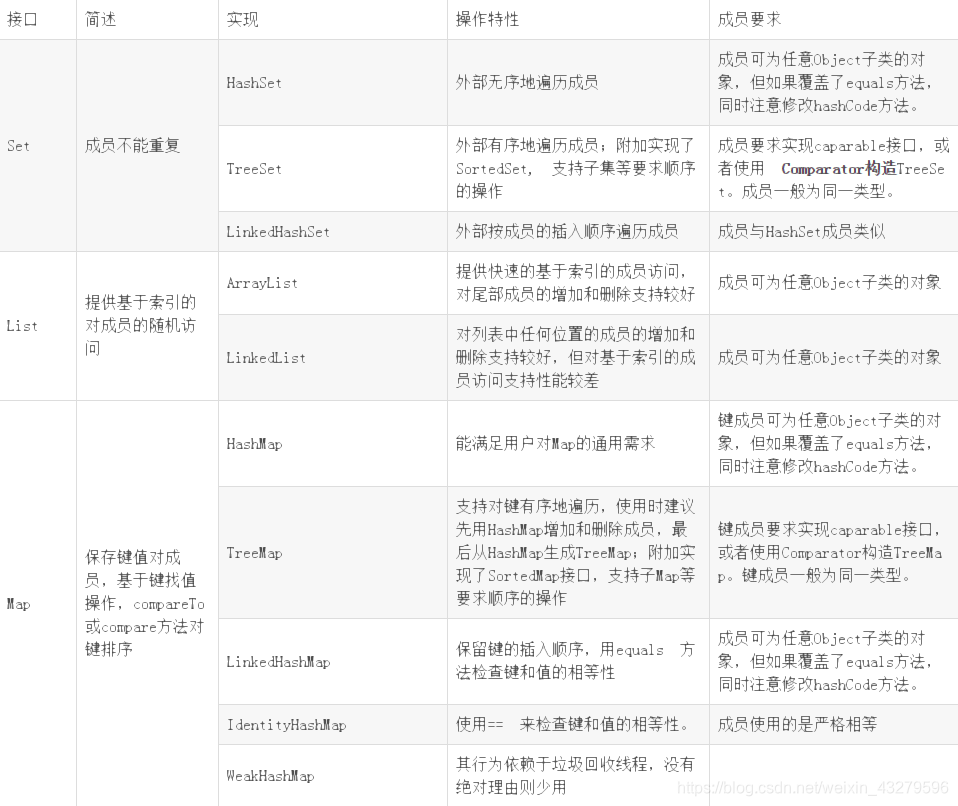
一、集合类
数组的要求功能:
1、我们需要该容器的长度是不确定的。
2、我们需要它能自动排序。
3、我们需要存储以键值对方式存在的数据。
集合类,集合类在Java中有很重要的意义,保存临时数据,管理对象,泛型,Web框架等
常见的集合类有这些种:
实现Collection接口的:Set、List以及他们的实现类。
实现Map接口的:HashMap及其实现类,我们常用的有Map及其实现类HashMap,HashTable,List、Set及其实现类ArrayList、HashSet
实现Collection接口的类,如Set和List,他们都是单值元素(其实Set内部也是采用的是Map来实现的,只是键值一样,从表面理解,就是单值),不像实现Map接口的类一样,里面存放的是key-value(键值对)形式的数据。这方面就造成他们很多的不同点,如遍历方式,前者只能采用迭代或者循环来取出值,但是后者可以使用键来获得值得值。
1、HashMap和HashTable
相同点:二者都实现了Map接口,因此具有一系列Map接口提供的方法。
不同点:
1、HashMap继承了AbstractMap,而HashTable继承了Dictionary。
2、HashMap非线程安全,HashTable线程安全,到处都是synchronized关键字。
3、因为HashMap没有同步,所以处理起来效率较高。
4、HashMap键、值都允许为null,HashTable键、值都不允许有null。
5、HashTable使用Enumeration,HashMap使用Iterator。
2、Set接口和List接口
相同点:都实现了Collection接口
不同点:
1、Set接口不保证维护元素的顺序,而且元素不能重复。List接口维护元素的顺序,而且元素可以重复。
2、关于Set元素如何保证元素不重复,我将在下面的博文中给出。
3、ArrayList和LinkList
相同点:都实现了Collection接口
不同点:ArrayList基于数组,具有较高的查询速度,而LinkedList基于双向循环列表,具有较快的添加或者删除的速度,二者的区别,其实就是数组和列表的区别。上文有详细的分析。
5、TreeMap和HashMap
HashMap具有较高的速度(查询),TreeMap则提供了按照键进行排序的功能。
6、HashSet和LinkedHashSet
HashSet,为快速查找而设计的Set。存入HashSet的对象必须实现hashCode()和equals()。
LinkedHashSet,具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序),于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
7、TreeSet和HashSet
TreeSet: 提供排序功能的Set,底层为树结构 。相比较HashSet其查询速度低,如果只是进行元素的查询,我们一般使用HashSet。
8、ArrayList和Vector
同步性:Vector是线程安全的,也就是说是同步的,而ArrayList是线程序不安全的,不是同步的。
数据增长:当需要增长时,Vector默认增长为原来一培,而ArrayList却是原来的一半
9、Collection和Collections
Collection是一系列单值集合类的父接口,提供了基本的一些方法,而Collections则是一系列算法的集合。里面的属性和方法基本都是static的,不需要实例化,直接可以使用类名来调用。
2 集合类排序问题
一种情况是集合类本身自带排序功能,如前面说过的TreeSet、SortedSet、SortedMap等,另一种就是本身不带排序功能,我们通过为需要排序的类实现Comparable或者Comparator接口来实现。
相同点:
1、二者都可以实现对象的排序,不论用Arrays的方法还是用Collections的sort()方法。
不同点:
1、实现Comparable接口的类,似乎是预先知道该类将要进行排序,需要排序的类实现Comparable接口,是一种“静态绑定排序”。
2、实现Comparator的类不需要,设计者无需事先为需要排序的类实现任何接口。
3、Comparator接口里有两个抽象方法compare()和equals(),而Comparable接口里只有一个方法:compareTo()。
4、Comparator接口无需改变排序类的内部,也就是说实现算法和数据分离,是一个良好的设计,是一种“动态绑定排序”。
5、Comparator接口可以使用多种排序标准,比如升序、降序等。
异常处理:
A:异常的概述: 异常就是Java程序在运行过程中出现的错误。
B:异常的分类: 举例:张三骑自行车旅游
C:异常的继承体系
异常的基类: Throwable
严重问题: Error 不予处理,因为这种问题一般是很严重的问题,比如: 内存溢出
非严重问题: Exception
编译时异常: 非RuntimeException
运行时异常: RuntimeException
1:异常处理的两种方式
a:try…catch…finally
b:throws
注意事项:
a: try中的代码越少越好
b: catch中要做处理,哪怕是一条输出语句也可以.(不能将异常信息隐藏)
c:能明确的尽量明确,不要用大的来处理。
d:平级关系的异常谁前谁后无所谓,如果出现了子父关系,父必须在后面。
JDK1.7中对多个catch的变形格式
-
try { -
可能出现问题的代码 ; -
}catch(异常名1 | 异常名2 | .... 变量名){ -
对异常的处理方案 ; -
} - 好处: 就是简化了代码
- 弊端: 对多个异常的处理方式是一致的
- 注意事项:
-
多个异常之间只能是平级的关系,不能出现子父类的继承关系
throws和throw的区别
a:throws
用在方法声明后面,跟的是异常类名
可以跟多个异常类名,用逗号隔开
表示抛出异常,由该方法的调用者来处理
throws表示出现异常的一种可能性,并不一定会发生这些异常
b:throw
用在方法体内,跟的是异常对象名
只能抛出一个异常对象名
这个异常对象可以是编译期异常对象,可以是运行期异常对象
表示抛出异常,由方法体内的语句处理
throw则是抛出了异常,执行throw则一定抛出了某种异常
final,finally和finalize的区别
* final: 是一个状态修饰符, 可以用来修饰类 , 变量 , 成员方法.
被修饰的类不能被子类继承, 修饰的变量其实是一个常量不能被再次赋值
* 修饰的方法不能被子类重写
* finally:用在try...catch...语句中 , 作用: 释放资源 . 特点: 始终被执行(JVM不能退出)
* finalize: Obejct类中的一个方法,用来回收垃圾