链表
链表也是线性数据结构,与数组相比,在内存分配、内部结构及数据插入和删除的操作上均有不同。 链表用途广泛,适用于许多通用的数据库,也可以取代数组,作为其他存储结构的基础。 在链表中,每个数据项都被包含在链节点中,一个链节点是某个类的对象,这个类叫做Link。因为一个 链表中有许多类似的链节点,所以要用一个不同于链表的类来表达链节点。每个Link对象都包含一个对 下一个链节点引用的字段,即next,但是链表本身的对象中有一个字段指向对第一个链节点的引用。
引用的区别
在java中,Link对象并没有真正包含另外一个Link对象,类型为Link的next字段仅仅是对另外一个Link 对象的引用,而不是一个对象。一个引用是一个对某个对象的参照数值,它是一个计算机内存中的对象 地址,并不需要知道它的具体值,在给定的计算机系统中,所有的引用,不管指向谁,大小都是一样 的,因此对于编译器来说,知道这个字段的大小并由此构造出整个Link对象,是没有问题的。在java 中,这些基本类型的字段不是引用,而是实实在在的数值。
链表的每个节点包含着数据和指向后续节点的指针,还包括一个头指针,它指向链表的第一个元素,但 当链表为空时,它指向Null或无具体内容。 链表一般用于实现文件系统,哈希表和邻接表。
单链表的操作: 在链表头插入一个数据项; 在链表头删除一个数据项; 遍历链表显示它的内容。
双向链表 双向链表新增了一个特性,即对最后一个链节点的引用,就像对第一个链节点的引用一样,对最后一个 链节点的引用允许像在表头一样,在表尾直接插入一个链节点,方法是遍历整个链表直到到达表尾,但 这种方法效率很低。
操作,insertAtEnd,insertAtHead,delete,deleteAtHead,search,isEmpty
链表的效率 :在表头插入和删除速度很快,仅需要改变一两个引用值,花费O(1)的时间。平均起来,查找,删除和在 指定链节点后面插入都需要搜索链表中的一半链节点,和数组一样需要O(N)次比较,但链表仍然要快一 些,当插入和删除链表节点的时候链表不需要移动任何东西。 链表比数组更优的另一点是,链表需要多少内存就可以使用多少内存,并且可以扩展到所有可用内存, 数组的大小在他创建的时候就固定了,数组太大会导致效率低下,数组太小导致空间溢出,向量是一种 可扩展的数组,可以通过可变长度解决这个问题,但是它只允许以固定大小的增量扩展,这个解决方案 在内存使用率上来说还是比链表的低。
实战
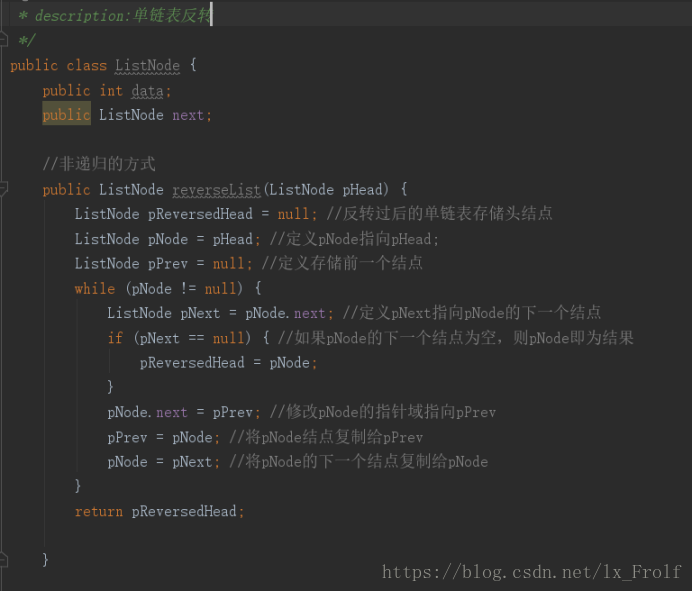
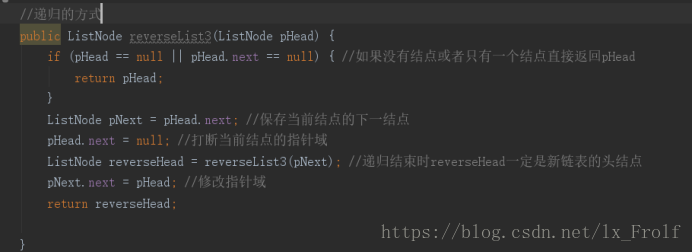
反转链表
非递归的方式代码如下:
递归的方式:
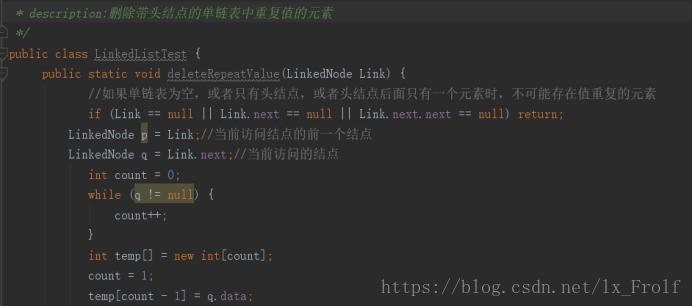
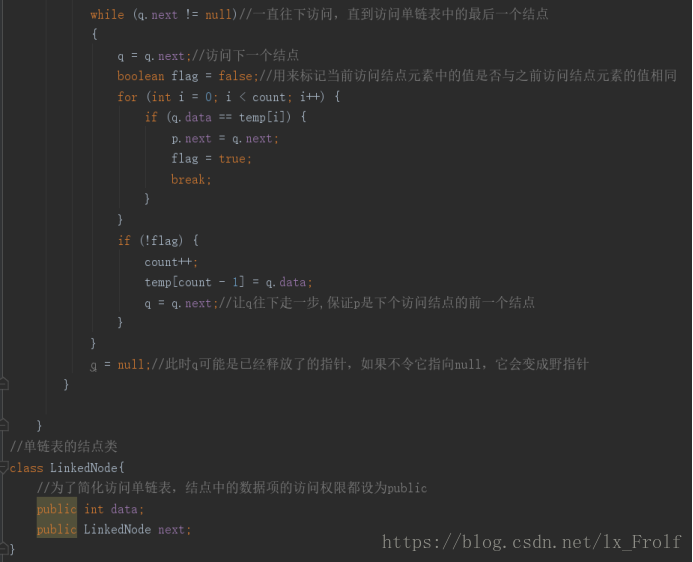
删除链表中的重复项
实现思路:
用一个动态辅助存储数组,每次要向辅助数组中放入元素时,让辅助数组的长度加1,最长时与单链表一样长,设一个指针p,让它指向头结点,从单链表中第一个元素开始,将它的值放入辅助数组中,然后依次访问单链表后面的元素,用该元素的值与数组中所有已经被赋值的元素的值进行比较,如果不等于数组中任何元素的值,那么让p的next指向该结点的next指针,删除该结点元素,否则令p指向p的next指针,并将当前访问的节点元素的值依次放入辅助数组,一直访问到单链表中的最后一个元素。
具体实现: