链表
1.链表定义
链表是线性表的一种。
线性表的定义为:一种可以在任意位置进行插入和删除数据元素操作的,由n个相同类型数据元素
组成的线性结构。其数据元素满足除第一个元素和最后一个元素外,每个元素只有一个直接前驱和直接后继,第一个元素没有前驱元素,最后一个元素没有后继元素。
链表基于指针实现(Java中为引用,以下称引用),一个数据元素和一个引用称为一个节点。链式存储通过引用将相互直接关联的节点链接起来。链式存储的结构特点是数据元素之间的逻辑关系表现在节点的链接关系上,逻辑上相邻的元素在物理存储地址上不一定相邻。
链表结构根据有无头节点可分为带头结点链表和不带头节点链表,通常来说默认带头节点;根据链接是否构成闭环可分为循环链表和非循环链表;根据引用域的数量分为单链表和双向链表。其中可任意组合,例如单向循环链表。
2.各类链表结构及其特点
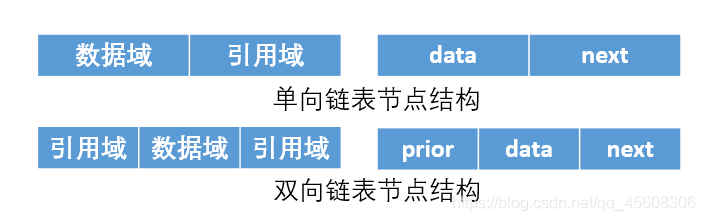
2.1 结点结构图
结点数据域存储结点数据,引用域指向该结点的直接后继结点;对于双链表,还有一个前向引用,指向该节点的直接前驱结点。
2.2 带头节点与不带头节点
首先是带头节点和不带头节点的链表在空表和非空表时的图:
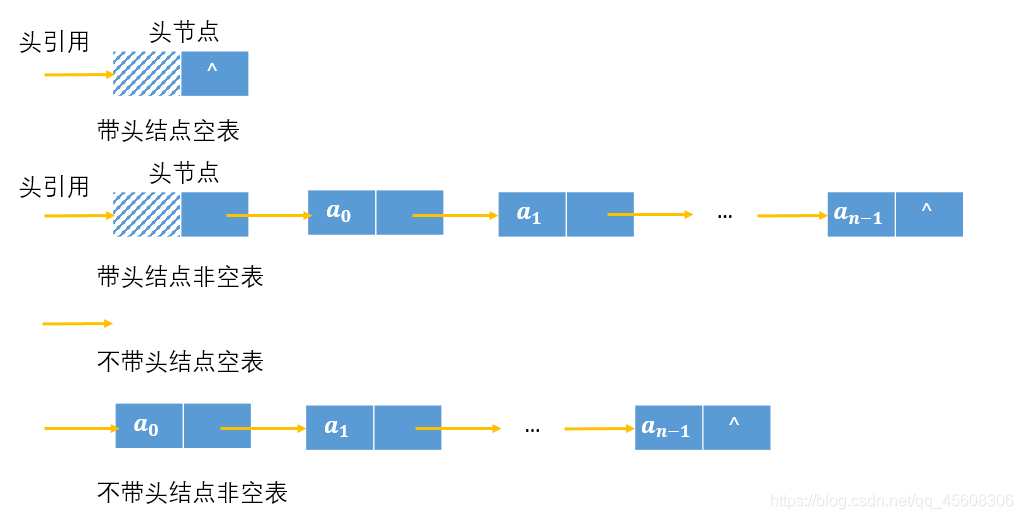
通常来说,实现链表使用带头点的方式,因为当选用带头结点的链表时,插入和删除的操作实现方法比不带头结点实现方法要简单与统一。为何?
现做分析,考虑插入一个结点s。
带头结点的插入方式为如图所示:
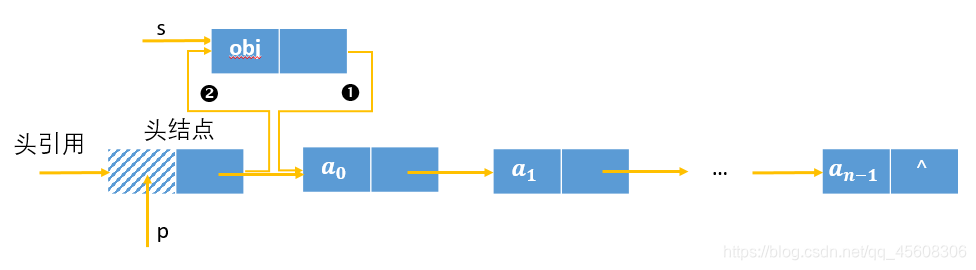
从图中可以明显看出,对于带头结点的链表,无论在链表的哪个位置插入结点,均只需要找到位置,完成图中的步骤1和步骤2即可,没有区别。写成代码形式为:
s.next = p.next;
p.next = s;
而对于不带头结点的链表,在非首位插入类似于带头结链表。然而在首位插入时:
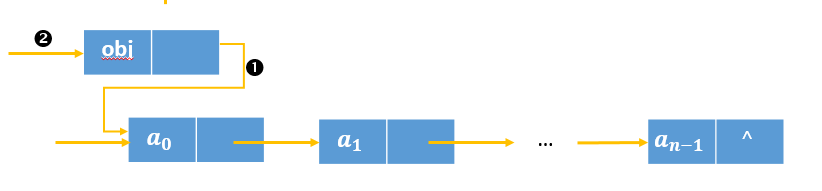
步骤1将待插入结点的引用指向首结点;步骤2改变头结点的引用。
s.next = head;
head = s;
因而,带头结点的链表在最前头插入结点时,需要该变头引用,与在其他位置插入时产生了不一样的情况。也即造成了同一个操作(插入、删除)需要考虑位置来分情况处理,实现起来较为繁琐,故通常采用带头结点的链表。
总结来说,带头结点的优点:1)各类操作无需区分位置,统一简便
2.3 循环链表与非循环链表
循环链表故名思意,就是能构成一个闭环的链表,可以无限寻找下一个结点,尾节点引用域非空,它指向头结点。以单循环链表为例,给出循环链表的图:
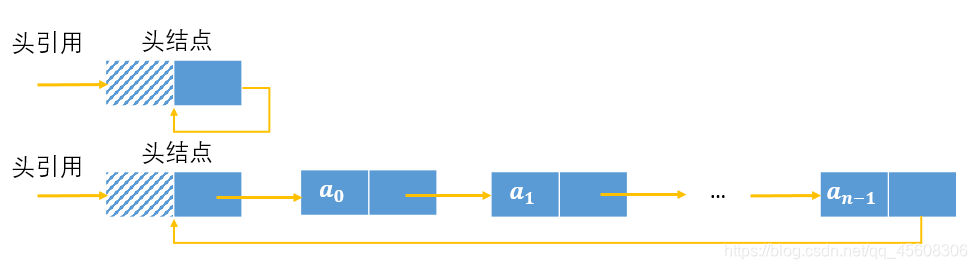
循环链表的优点:1)从任意一点出发均可访问整个链表,使得某些操作便于实现 2)对于遍历操作,无需判别指针是否为空,只需要判别是否等于某个特定结点,处理简单
2.4 单链表与双链表
如图所示为带头结点的双链表:
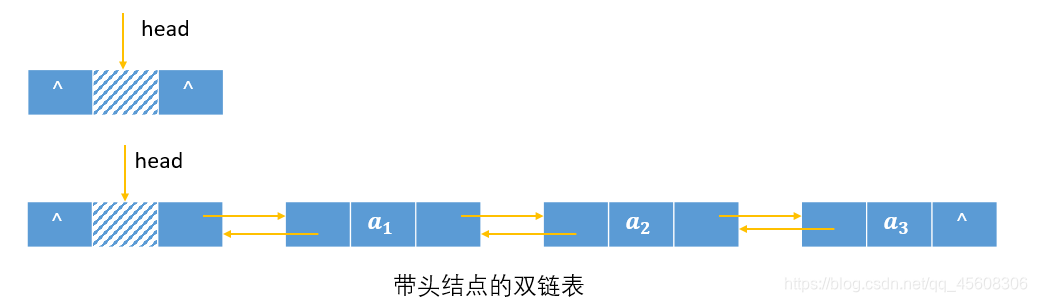
对于双链表,需要注意的是它的插入和删除操作。
插入操作:
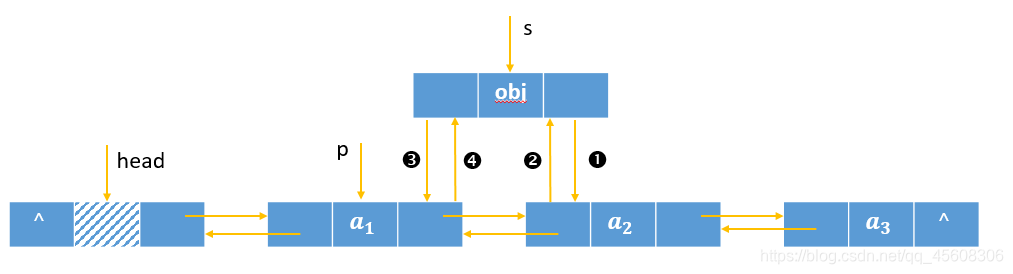
写成代码形式:
s.next = p.next.prior;
s.next.prior = s;
s.prior = p;
p.next = s;
操作顺序可否调换呢,答案是肯定的。最核心的问题就是防止断链,即丢失p的后一个结点的引用,在不出现这个问题的情况下,可调换操作顺序,例如2134,1243。
同样的,删除操作也需要防止出现断链的情况,要十分注意操作的顺序。
双向链表优点:1)从任意结点均可访问整个链表 2)可减少结点的搜索时间 3)可直接查看某个结点的前驱结点和后继结点
双向链表缺点:1)插入和删除操作相比于单链表更复杂 2)消耗更大的空间,需要存储另一个指针域
2.5 带尾结点的链表
以单链表为例,为应付单链表频繁对末尾结点操作的情况,会带尾结点,即有一个指向最后一个结点的引用。这样通过过尾结点可迅速找到终端结点。而通过头结点来查找则需要花费
的时间。
3.单链表基本功能实现
3.1 结点类
根据以上链表结构和特定,可设置一个静态内部类作为链表的结点类,其中有数据域和引用域,构造器通过给出的数据来初始化结点的数据域:
private static class Node{
Object data; //数据域
Node next; //引用域
Node(Object obj){
this.data = obj;
}
}
3.2 成员以及方法
public class myLinkedList {
private Node head; //头结点的引用
private int size; //结点个数
public void insert(int i,Object obj); //插入
public Object delete(int i); //删除
public Object getData(int i); //查询
public void setData(int i, Object obj); //修改
}
3.3 插入操作
首先根据元素个数和欲插入位置
判断插入是否合理;之后创建
作为头结点的引用,将
引用移动到
的位置,其中需要判断
的存在性等问题;最后待插入节点的引用指向
的下一个节点,
的引用指向待插入节点。
public void insert(int i,Object obj) throws Exception{
if (i<0||i>size){ //越界判断
throw new Exception("parameter error");
}
Node p = head; //头结点引用
int j = -1;
while (p.next!=null&&j<i-1){ //将p引用指向第i-1个节点
p = p.next;
j++;
}
Node q = new Node(obj);
q.next = p.next; //步骤1
p.next = q; //步骤2 步骤1与步骤2不能调换,否则产生断链
size++;
}
3.4 删除操作
首先根据元素个数和欲插入位置判断链表是否为空和插入是否合理等问题;之后创建
作为头结点的引用,将
引用移动到
的位置,其中需要判断
的存在性等问题;最后将
的引用指向待删除节点的下一个结点完成删除操作。
public Object delete(int i) throws Exception{
if (size==0){
throw new Exception("empty");
}
if (i<0||i>size -1){
throw new Exception("parameter error");
}
Node p = head;
int j = -1;
while (p.next!=null&&j<i-1){ //将p引用指向第i-1个节点
p = p.next;
j++;
}
Object obj = p.next.data;
p.next = p.next.next; //p的引用指向待删除结点的后一个结点完成删除
size--;
return obj;
}
3.5 查询与修改
同样是参数检查与定位问题。
public Object getData(int i) throws Exception{
if (i<0||i>size-1){
throw new Exception("parameter error");
}
Node p = head;
int j = -1;
while (p.next!=null&&j<i){
p = p.next;
j++;
}
return p.data;
}
public void setData(int i, Object obj) throws Exception{
if (i<0||i>size-1){
throw new Exception("parameter error");
}
Node p = head;
int j = -1;
while (p.next!=null&&j<i){
p = p.next;
j++;
}
p.data = obj;
}
4.效率分析
4.1 链表各个操作时间复杂度
插入0位置需要比较数据元素0次;
插入1位置需要比较数据元素1次;
插入2位置需要比较数据元素2次;
依次类推,有
故插入操作时间复杂度为
删除操作比较次数与插入操作一样。
故删除操作时间复杂度为
修改操作时间复杂度为
查询操作时间复杂度为
4.2 为何说链表插入和删除操作效率优于顺序表,它们的时间复杂度都是
?
事实上,在通常情况下,链表和顺序表插入删除操作都是
,但考虑给定结点的情况下,却有十分大的差别。
给定待插入位置结点的引用时,链表无需从头结点开始搜索,只需要改变待插入结点引用以及那个位置上结点的引用即可,时间复杂度
;但顺序表在给定待插入处的那个结点的情况下,仍然需要移动后面的所有元素,时间复杂度仍然为
。
需要搞清楚,链表插入操作时间的高复杂度实际上是由搜索(移动临时引用)带来的,狭义上的插入操作时间复杂度为
;而顺序表插入操作是由移动元素造成的,它是插入操作不可分割的一部分。
因此,也有人会说链表插入操作时间复杂度为
,这里便是狭义的插入操作;故也认为,链表插入删除操作效率优于顺序表。
考虑另一种情况,双链表,在给定位置执行插入操作时,可根据位置选择临时引用开始的位置和移动的方向,搜索效率大为提升。
LinkedList
1. 什么是LinkedList
1.1 LinkedList简介
实际上,Java中的LinkedList类就是数据结构链表的一种实现。
LinkedList继承自AbstractSequentialList,实现了List接口,提供线性表的基本功能,增删改查以及一些基于这些的拓展功能。
LinkedList实现了Deque接口,此接口定义了访问双端队列两端元素的方法。这些方法中的每一种都以两种形式存在:一种在操作失败时抛出异常,另一种返回特殊值。
实现了Cloneable接口,提供了拷贝功能,即clone方法。实现了Serializable接口,提供了序列化功能,能够序列化传输该类对象。
1.2 LinedList结构
LinkedList是一个不带头结点的双向非循环链表。
其结构为:

设置成双链表的好处在于,搜索效率相比于单链表的提升。可根据给出的索引在中点的左侧或右侧来选择从前往后搜索或从后往前搜索,而单链表只能从前往后搜索。
2.LinkedList部分源码
2.1 域
transient int size; //数据元素个数
transient LinkedList.Node<E> first; //头结点
transient LinkedList.Node<E> last; //尾结点
2.2 结点定义
private static class Node<E> {
E item; //数据域
LinkedList.Node<E> next; //后向引用域
LinkedList.Node<E> prev; //前向引用域
Node(LinkedList.Node<E> var1, E var2, LinkedList.Node<E> var3) { //根据给出的参数定义结点的各个域
this.item = var2;
this.next = var3;
this.prev = var1;
}
}
2.3 构造方法
方法一创建一个空链表;方法二创建链表,将集合给出的元素添加至链表中。
public LinkedList() {
this.size = 0;
}
public LinkedList(Collection<? extends E> var1) {
this();
this.addAll(var1);
}
2.4 定位操作
根据上述单链表的基本功能实现可以看到,所有操作均需要定位操作,即获取待操作位置元素的引用。LinkedList将其作为一个单独的方法。LinkedList是一个双向链表,因此根据
和
的比较来选择从前面搜索还是从后面搜索。
LinkedList.Node<E> node(int var1) {
LinkedList.Node var2;
int var3;
if (var1 < this.size >> 1) { //离头结点近
var2 = this.first; //从前面开始搜索
for(var3 = 0; var3 < var1; ++var3) {
var2 = var2.next;
}
return var2;
} else { //离尾结点近
var2 = this.last; //从后面开始搜索
for(var3 = this.size - 1; var3 > var1; --var3) {
var2 = var2.prev;
}
return var2;
}
}
2.4 插入操作
首先看linkFirst,linkLast,linkBefore,所有插入操作均是通过这三个方法间接实现的。
linkFirst,头插。创建一个结点var2,数据域为待插入元素,前向指针为空,后向指针为头结点;将新节点设置为新头结点;若原头结点为空,则设置新结点为尾结点,否则原头结点前向引用设置为新头结点。
linkLast,尾插。类似于头插,即反向操作。
linkBefore,在某结点之前插入节点。
private void linkFirst(E var1) {
LinkedList.Node var2 = this.first; //原头结点,var2
LinkedList.Node var3 = new LinkedList.Node((LinkedList.Node)null, var1, var2); //新结点 null <- var3 -> 原头结点
this.first = var3; //新头结点,var3
if (var2 == null) { //由于原头结点为空,说明为空链接,故尾结点设置为新结点
this.last = var3;
} else { //原头结点不为空,原头结点前向引用设置为新头结点
var2.prev = var3;
}
++this.size;
++this.modCount;
}
void linkLast(E var1) { //类似于头插,反向操作
LinkedList.Node var2 = this.last;
LinkedList.Node var3 = new LinkedList.Node(var2, var1, (LinkedList.Node)null);
this.last = var3;
if (var2 == null) {
this.first = var3;
} else {
var2.next = var3;
}
++this.size;
++this.modCount;
}
void linkBefore(E var1, LinkedList.Node<E> var2) {
LinkedList.Node var3 = var2.prev; //节点var2的前一个结点的引用
LinkedList.Node var4 = new LinkedList.Node(var3, var1, var2); // 定位结点的前一结点 <- 新结点 -> 定位结点
var2.prev = var4; //定位结点前向引用设置为新结点
if (var3 == null) { //前一个结点为空,则将头结点置为新结点
this.first = var4;
} else { //前一个结点非空,则其后向引用设置为新结点
var3.next = var4;
}
++this.size;
++this.modCount;
}
插入add
首先参数检查;之后若结点在末尾,则调用尾插法,若结点不在末尾,通过node方法定位待插入位置的后一个结点,然后调用linkBefore。
public void add(int var1, E var2) {
this.checkPositionIndex(var1);
if (var1 == this.size) {
this.linkLast(var2); //尾插
} else {
this.linkBefore(var2, this.node(var1)); //定位后插入
}
}
2.5 删除操作
对应用插入操作,也有三个基本删除unlinkFirst,nulinkLast,unlink,供其他方法调用
unlinkFirst,删除头结点。
unlinLast,删除尾结点。
unlink,删除指定节点。
private E unlinkFirst(LinkedList.Node<E> var1) {
Object var2 = var1.item; //获取头结点元素供返回
LinkedList.Node var3 = var1.next; //创建头结点下一个节点的引用
var1.item = null;
var1.next = null; //将链断开
this.first = var3; //头结点置为原头结点的后继节点
if (var3 == null) { //若原头结点后一个节点为空,则删除后为空链,将尾引用置空
this.last = null;
} else { //否则原头结点的后一个节点的前引用置为空
var3.prev = null;
}
--this.size;
++this.modCount;
return var2;
}
private E unlinkLast(LinkedList.Node<E> var1) { //类型于删除头结点,反向操作
Object var2 = var1.item;
LinkedList.Node var3 = var1.prev;
var1.item = null;
var1.prev = null;
this.last = var3;
if (var3 == null) {
this.first = null;
} else {
var3.next = null;
}
--this.size;
++this.modCount;
return var2;
}
E unlink(LinkedList.Node<E> var1) { //删除指定节点
Object var2 = var1.item; //获取数据域供返回
LinkedList.Node var3 = var1.next; //新引用:后继节点
LinkedList.Node var4 = var1.prev; //新引用:前驱节点
if (var4 == null) { //前驱为空,后继节点设置为头结点
this.first = var3;
} else { //否则,前驱的后向引用指向后继节点,指定节点前向引用断开
var4.next = var3;
var1.prev = null;
}
if (var3 == null) { //后继为空,前驱节点设置为尾结点
this.last = var4;
} else { //否则,后继的前向引用指向前驱节点,指定节点后向引用断开
var3.prev = var4;
var1.next = null;
}
var1.item = null;
--this.size;
++this.modCount;
return var2;
}
删除remove
参数检查后直接 调用unlink,unlink参数为node方法定位的节点。
public E remove(int var1) {
this.checkElementIndex(var1);
return this.unlink(this.node(var1));
}
2.7 修改
参数检查,定位结点,修改数据域
public E set(int var1, E var2) {
this.checkElementIndex(var1);
LinkedList.Node var3 = this.node(var1);
Object var4 = var3.item;
var3.item = var2;
return var4;
}
2.8 查找
参数检查,定位结点,获取数据域
public E get(int var1) {
this.checkElementIndex(var1);
return this.node(var1).item;
}
3.关于Deuqe接口
LinedList继承了此接口,此接口定义了访问双端队列两端元素的方法,扩展了Queue接口,也可以用作LIFO(后进先出)堆栈。故有各式各样的插入删除方法.
双端队列相关的12种增删查方法,
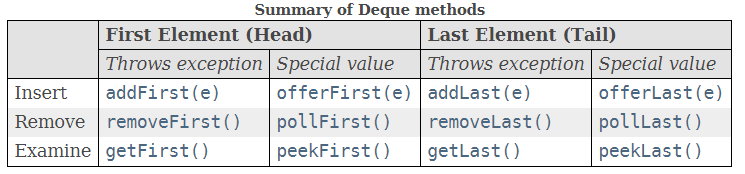
队列相关方法与双端队列相关方法:
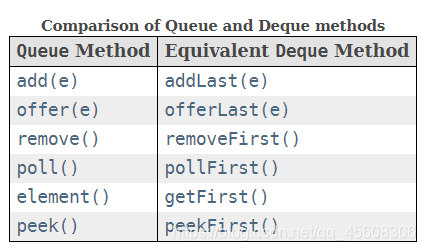
堆栈相关方法:
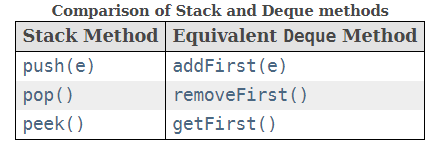
总结
1.通常可以说链表在插入删除操作上效率高于顺序表,但查找修改操作效率低于顺序表。因此,频繁插入删除应选用链表作为数据结构。
2.未明确给出结点的情况下,不可说链表插入删除时间复杂度为 ,因为搜索时间也要算进插入里面,故为 。但狭义上的插入删除操作,时间复杂度为
3.可根据应用场景适度选择链表的结构,例如:
频繁地在尾部进行插入查找修改操作, 可选用双向链表或带尾结点的单链表;
希望在任意节点出发都可以访问整个链表,可选用双向链表或单向循环链表;
4.链表在空间利用的灵活性上优于顺序表,链表可利用零碎空间,而顺序表需要开辟一整块连续的内存;链表在空间利用率上不如顺序表,链表需要额外空间来存放引用(指针域)。
5.链表插入删除操作时应注意引用修改的顺序,避免断链。
6.LinkedList线程不安全;链表不支持随机访问;与ArrayList一样,它的迭代器有"快速失败"机制。