版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_30500113/article/details/83754874
爬取猫眼电影网前100的电影排名
猫眼电影网:http://maoyan.com/board/4
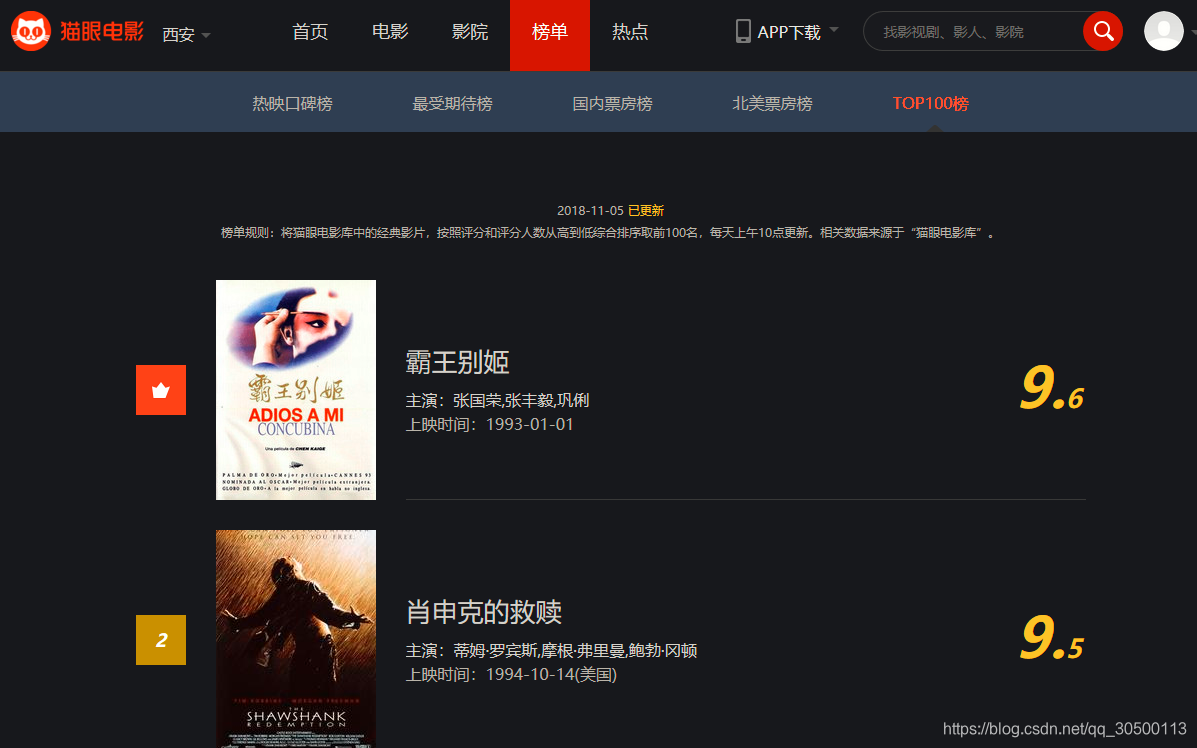
确定要爬取的数据:
1:排名
2:电影名称
3:主演
4:上映舌尖
5:评分
构造下一页url
首页:http://maoyan.com/board/4?offset=0
第二页 http://maoyan.com/board/4?offset=10
第十页 http://maoyan.com/board/4?offset=100
我们发现url中变化的只有数字 那么我们可以通过循环构造出这个url
我们需要的信息全都在这些标签中:
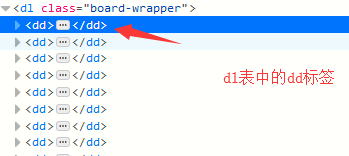
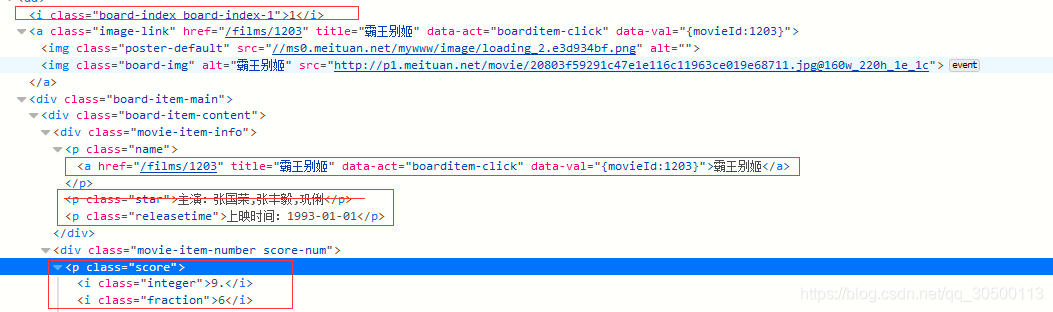
用红色圈起来的地方 就是我们需要的信息 我们一个个找到他们 然后将信息提取出来
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/11/5 18:06
# @Desc : 爬取猫眼电影网前100的电影排名
import requests
import json
from pyquery import PyQuery as pq
headers = {
'proxy': 'https: 219.135.169.85:47315',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36'
' (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
def start_request(url):
"""发起请求 获得页面源码"""
r = requests.get(url, headers=headers)
return r.text
def parse(text):
"""解析源码 获得数据"""
doc = pq(text)
# 找到页面源码中的dd标签
infos = doc('dl.board-wrapper dd').items()
for info in infos:
refect = {}
refect['rank'] = info.find('i.board-index').text() # 排名
refect['name'] = info.find('p.name a').text() # 电影名字
refect['actor'] = info.find('p.star').text() # 演员
refect['time'] = info.find('p.releasetime').text() # 上映时间
refect['score'] = info.find('p.score').text() # 评分
result_list.append(refect)
return result_list
def write_json(result):
"""写入json文件"""
s = json.dumps(result, indent=4, ensure_ascii=False)
with open('cateye.json', 'w', encoding='utf8') as f:
f.write(s)
print("写入完成")
def main():
for i in range(10):
"""构造url"""
url = "http://maoyan.com/board/4?offset={}".format(i * 10)
text = start_request(url)
result = parse(text)
write_json(result)
if __name__ == "__main__":
result_list = []
main()
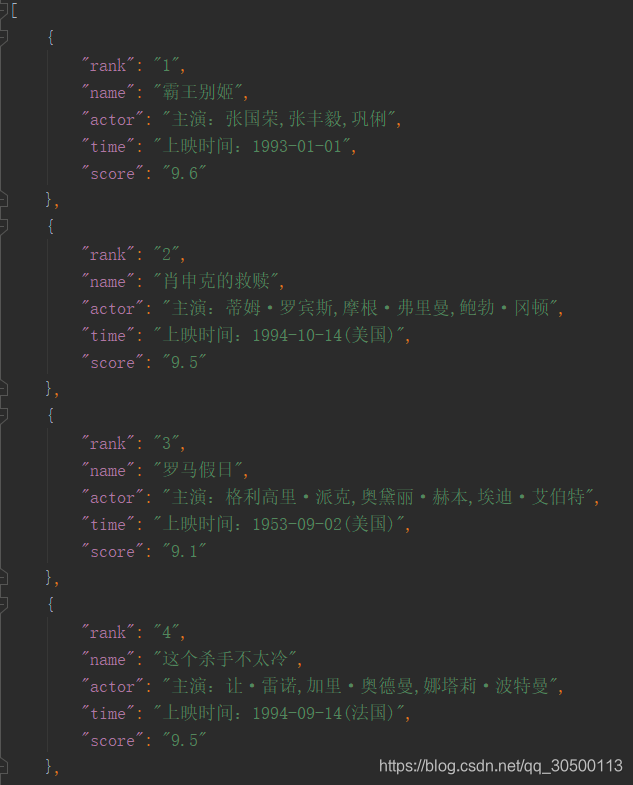
运行程序后来查看json文件:
OK 到此结束!