文章目录
基础知识
- 数据库:物理操作系统文件或其他形式文件类型的集合。有些存储引擎是存放于内存之中的文件。
- 数据库实例:由数据库后台线程以及一个共享内存区组成。数据库实例才是真正用于操作数据库文件的。在MySQL数据库中,一个实例对应一个数据库,一个数据库对应一个实例。我们的应用程序是不能直接操作数据库的,只能通过操作数据库实例来间接与数据库交互。
- 数据库启动时,需要去加载配置文件
my.cnf,查找该配置文件的命令是mysql --help|grep 'my.cnf',如果是Windows平台则是.cnf文件或.ini文件。 - 数据库路径:通常在配置文件的
datadir参数,linux操作系统下默认的datadir是/usr/local/mysql/data
innoDB存储引擎
innoDB存储引擎的体系架构图如下:
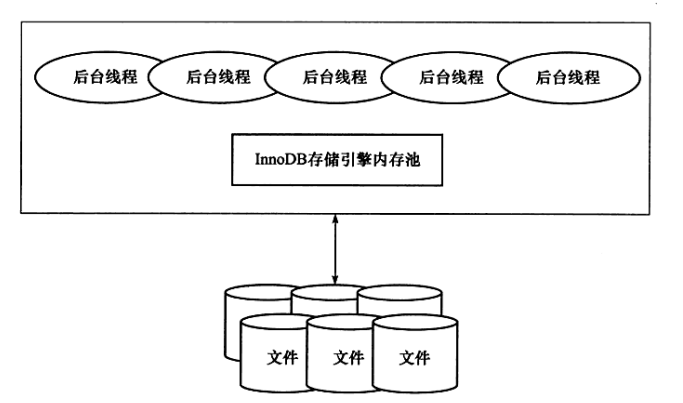
1、后台线程
- 后台线程分为
Master Thread和IO Thread,其中Master是一个核心的后台线程,负责将缓冲池中的数据异步刷新到磁盘,保证数据的一致性,包括脏页的刷新、合并插入缓冲(INSERT BUFFER)、UNDO页的回收。IO Thread主要是用来处理AIO处理请求后的回调。InnoDB共有4个IO Thread,分别是write、read、insert buffer、log IO thread。 - write和read的线程个数可以通过配置文件中的以下两个参数来调整。
innodb-read-io-threads = 8
innodb-write-io-threads = 8 - log IO thread线程通过
show engine innoDB status命令来查看,如果查询结果是一条记录,就说明该线程只有一条。
- Purge Thread:事务被提交后,其所使用的undolog可能不再需要,需要PurgeThread来回收已经使用并分配的undo页。可以通过修改配置文件中的这个配置来修改线程个数。
innodb_purge_threads = 1 - Page Cleaner Thread:在InnoDB 1.2.x版本引入。其作用是将之前版本中脏页的刷新操作都放入到单独的线程中来完成。其目的是为了减轻原来Master Thread的工作对于用户查询线程的阻塞,提高InnoDB的性能。

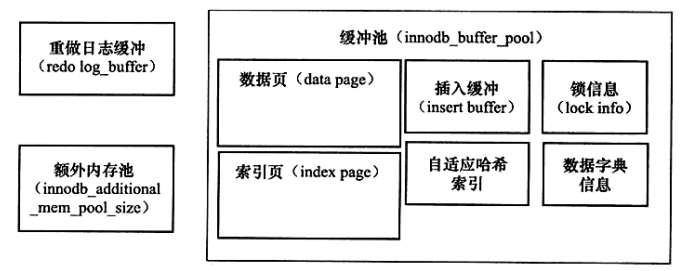
2、内存
2.1 缓冲池简介
缓冲池:缓冲池就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响。在数据库中进行读取页的操作,首先将从磁盘读到的页存放在缓冲池中,这个过程被称为页FIX在缓冲池中。下一次再读相同的页时,首先判断该页是否在缓冲池中,如果在缓冲池中,称该页在缓冲池中被命中,直接读取该页。否则,读取磁盘上的页。
- 对于数据库中页的修改操作,首先是修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上。不过页从缓冲池刷新回磁盘的操作并不是在每次页发生更改时出发。而是通过一种称为Checkpoint的机制刷新回磁盘。
- 可以通过修改配置文件中参数来修改缓冲池的大小
innodb-buffer-pool-size = 2G。 - 缓冲池中内存页的结构如下:缓冲池中的页大小默认未为16K。
- InnoDB1.0.x版本开始,允许有多个缓冲池实例。每个页根据哈希值平均分配到不同缓冲池实例中。这样做的好处是增加数据库并发的处理能力。缓冲池的个数可以通过配置文件中的
innodb-buffer-pool-instances = 8来修改。 - 可以通过下面的查询方式来查看当前内存池的使用状态。

2.2 LRU算法
LRU(Latest Recent Used,最近最少使用),最频繁使用的页再LRU列表的前端,最少使用的页在LRU列表的尾端。当缓冲池不能继续存放新读取到的页时,将首先释放LRU列表中尾端的页。InnoDB对LRU算法做了很多优化:
- midpoint位置:新读取到的页,虽然是最新访问的页,但并不是直接放入到LRU列表的midpoint位置。默认的配置时在LRU长度的5/8的位置。可以通过修改配置文件的这个参数
innodb_old_blocks_pct=37来调整该位置,参数中的37表示的37%,约等于5/8。mid前面的页被称为old页,mid后面的页被称为new页。 - 等待时间:页读取到mid位置后需要等待多久才会被加入带LRU列表的热端。通过修改这个参数
innodb_old_blocks_time=1000来调整。
参数
innodb_old_blocks_pct的作用:如果直接采用朴素的LRU算法,将直接读取到的页直接放入到LRU的首部,那么某些SQL操作可能会使缓冲池中的页被刷新出,从而影响缓冲池的效率。常见的这类操作作为索引或数据的扫描操作。这类操作需要访问表中的许多页,甚至全部的页。而这些页通常不是活跃的热点数据。如果将这些数据放入首部,那么非常有可能将所需要的热点数据页从LRU列表中移除,再下一次需要读取该页时,InnoDB存储引擎需要再次访问磁盘。
参数
innodb_old_blocks_time的作用,如果上面的操作始终将新页放在mid,那么在mid前面的页将始终不会被刷新,这个参数就是用来解决这个问题的。
2.3 查看innodb状态
- Free列表:LRU是用来管理已读读取的页。当数据库刚启动时,LRU列表时空的,没有任何的页。这是页都存放在Free列表中。当需要从缓冲池中分页时,首先从Free列表中查找是否有可用的空闲页,若有,则将该页从Free列表中删除,放入到LRU列表中。
- page made young:LRU列表的old部分加入到new部分时,这时的操作被叫做page made young。
- page not made young:因为
innodb_old_blocks_time的设置而导致页没有从old部分移动到new部分的操作被叫做 page not made young。
1、通过show engine innodb status可以查看LRU和Free列表的状态,该命令展示的并不是当前状态,展示的是过去24s的状态。Per second averages …… 24 seconds,如下图。


Buffer pool size表示共有8197个页,总共有(8197*16k)个G的缓冲池。Free Buffer表示当前Free列表中页的数量。Database pages表示LRU列表中页的数量。Free Buffer和Database pages数量之和不等于Buffer pool size,是因为缓冲池中的页还可能会被分配给自适应哈希索引、Lock信息、Insert Buffer等页。这部分不需要LRU算法来维护,所以不存在与LRU列表中。page made young显示了LRU列表中页移动到前端的次数。Buffer pool hit rate表示缓冲池的命中率,如果该值小于95%,就要考虑是否由于全表稻苗引起的LRU列表污染的问题。
2、InnoDB 1.2版本开始,还可以通过表INNODB_BUFFER_POOL_STATS来观察缓冲池,查询sql如下:
select pool_id,hit_rate,
pages_made_young,
pages_not_made_young
from information_schema.INNODB_BUFFER_POOL_STATS
查询结果如下:

通过INNODB_BUFFER_PAGE_LRU这个表还可以查询每个页的详细信息,查询语句如下:
select TABLE_NAME,SPACE,
PAGE_NUMBER,PAGE_TYPE
from INNODB_BUFFER_PAGE_LRU where space=1;
查询结果如下:

3、压缩页
InnoDB存储引擎从1.0.x版本开始支持压缩页的功能,将原本16K的页压缩为1K、2K、4K和8K。由于页的大小发生了变化,LRU列表也有了些许的改变。对于非16K的页,是通过unzip_LRU列表进行管理的。通过命令show engine innoDB status可以看到如下内容:
unzip_LRU是怎样从缓冲池中分配内存的呢?例如:对需要从缓冲池中申请4KB的大小,过程如下:

- 检查4K的unzip_LRU列表,检查是否有可用的空闲页。
- 若有,则直接使用。
- 否则,检查8KB的unzip_LRU列表。
- 若能够得到空闲页,将页分成2个4KB页,存放到4KB的unzip_LRU。
- 若不能得到空闲页,从LRU列表申请一个16KB的页,将页分为1个8KB的页,2个4KB的页,分别存放到对应的unzip_LRU列表中。
查询unzip_LRU列表中的页。
select TABLE_NAME,SPACE,PAGE_NUMBER,COMPRESSED_SIZE
from INNODB_BUFFER_PAGE_LRU WHERE COMPRESSED_SIZE <> 0;
查询结果如下:下面的查询没有加where条件,是因为测试用的数据库没有被压缩的页。

4、脏页(dirty page)
脏页就是缓冲池里面的数据页和磁盘上的数据页产生了不一致,此时需要使用Checkpoint技术重新将缓冲池中的页的变化写入磁盘上。FLUSH列表中存放的都是脏页,不过要注意的是,脏页在LRU列表和Flush列表中是共存的。LRU列表用来管理页的可用性,FLUSH列表用来将数据刷回磁盘。
查询脏页的sql如下:需要在查询INNODB_BUFFER_PAGE_LRU表时加个where条件OLDEST_MODIFICATION > 0。
select TABLE_NAME,SPACE,PAGE_NUMBER,COMPRESSED_SIZE
from INNODB_BUFFER_PAGE_LRU WHERE OLDEST_MODIFICATION > 0;
注意:所有查询
INNODB_BUFFER_PAGE_LRU的结果如果TABLE_NAME的值是NULL,说明是系统的页。
2.4 重做日志缓冲
InnoDB存储引擎的内存区域除了有缓冲池外,还有重做日志缓冲(redo log buffer)。InnoDB存储引擎先将重做日志信息先放入这个缓冲区,然后按照一定频率将其刷新重做日志文件。重做日志缓冲一般不需要设置的很大,因为一般情况下每一秒钟就会将重做日志缓冲刷新到日志文件,因此在设置日志缓存大小时,只需要考虑每秒的缓存任务量即可。
在my.cnf配置文件中通过修改参数innodb-log-buffer-size = 64M来配置日志缓存的大小。
当出现下面三种情况下会将重做日志缓冲中的内容刷新到外部磁盘的重做日志文件中。
- Master Thread每一秒将重做日志缓冲刷新到重做日志文件。
- 每个事务提交时会将重做日志缓冲刷新到重做日志文件。
- 当重做日志缓冲池剩余空间小于1/2时,重做日志缓冲刷新到重做日志文件。
2.5 额外的内存池
在InnoDB存储引擎中,对内存的管理是通过一种称为内存堆(heap)的方式进行的。在对一些数据结构本身的内存进行分配时,需要从额外的内存池中进行申请,当该区域的内存不够时,会从缓冲池中进行申请。例如:分配了缓冲池(innodb_buffer_pool),但是每个缓冲池中的帧缓冲(frame buffer)还有对应的缓冲控制对象(buffer control block),这些对象记录了一些LRU、锁、等信息,而这个对象的内存需要从额外内存池中申请。所以,如果在配置文件中申请了很大的InnoDB缓冲池时,也考虑相应的增加这个值。
2.6 Checkpoint技术
如果一条DML语句,如Update或Delete改变了页中的记录,那么此时页是脏的,即缓冲池中的页要比磁盘的新,数据库需要将新版本的页从缓冲池舒心到磁盘。倘若每一个页发生变化,就将新页的版本刷新到磁盘,那么这个开销是非常大的。同时,如果在从缓冲池将新版本刷新到磁盘时发生了宕机,那么数据就不能恢复了,为了避免发生数据丢失的问题,当前事务数据库系统普遍都采用了Write Ahead Log策略,即当事务提交时,先写重做日志,再修改页。这样当发生宕机导致数据丢失时,通过重做日志来恢复。
Checkpoint技术就是为了解决上述过程中缓冲池不够用和日志不可用的问题:
- 缓冲池不够用时,将脏页刷新到磁盘。
- 重做日志不可用时,刷新脏页。
这样当数据库发生宕机时,数据库不需要重做所有的日志,因为Checkpoint之前的也都已经刷新回磁盘。所以数据库只需对Checkpoint后的重做日志进行恢复。这样就缩短了恢复时间。除此以外,当缓冲池不够用时,根据LRU算法会溢出最少使用的页,若此页为脏页,那么需要强制执行Checkpoint,将脏页也就是页的新版本刷回磁盘。
重做日志不可用的情况:当前事务数据库系统对重做日志的设计都是循环使用的,并不是让其无限增大的,这从成本及管理上都是比较困难的。如果重做日志的某一部分已经被写到磁盘上,也就是恢复数据时并不需要这部分,那这部分就日志可以覆盖掉。若此时重做日志还需要使用,不能被覆盖,那么必须强制产生Checkpoint,将缓冲池中的页至少刷新到当前重做日志的位置。
同样可以通过show engine INNODB STATUS来查看checkpoint的相关状态。如下:
对于innoDB存储引擎而言,是通过LSN(Log Sequence Number)来标记版本的。而LSN是8字节的数字,单位是字节,每个页都有LSN,重做日志中也有LSN,Checkpoint也有LSN。
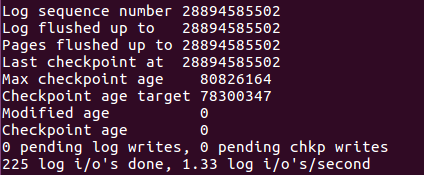
Checkpoint所做的事情其实就是将缓冲池中的脏页刷回到磁盘。不同之处在于每次刷新多少页到磁盘,每次从哪里去脏页,以及什么时间出发Checkpoint。在InnoDB存储引擎内部,有两种Checkpoint,分别是:Sharp Checkpoint和Fuzzy Checkpoint
- Sharp Checkpoint发生在数据库关闭时,将所有的脏页都刷新回磁盘,这是默认的工作方式。
- Fuzzy Checkpoint在数据库运行时使用,只刷新一部分脏页,而不是刷新所有的脏页回磁盘。
2.7 Master Thread工作方式
3、InnoDB关键特性
- 插入缓冲(Insert Buffer)
- 两次写(Double Write)
- 自适应哈希索引(Adaptive Hash Index)
- 异步IO(Async IO)
- 刷新邻接页(Flush Neighbor Page)
4、启动、关闭与恢复
MySQL实例的启动过程中对InnoDB存储引擎可以做相应的处理。
1.参数innodb_fast_shutdown影响着表的存储引擎为InnoDB的行为。该参数可取的值为0、1 、2,默认值为1.
- 0表示在Mysql数据库关闭时,InnoDB需要完成所有的full purge和merge insert buffer,并且将左右的脏页刷新回磁盘。这需要一些时间,有时甚至需要几个小时来完成。如果进行InnoDB升级时,必须将这个参数调为0,然后关闭数据库。
- 1表示不完成full purge和merge insert buffer操作,但是在换充值中的一些数据脏页还是会刷新回磁盘。
- 2表示不完成full purge和merge insert buffer操作,也不将缓冲池中的数据脏页写回磁盘,而是将日志都写入文件,这样不会有任何事物的丢失,但是下次MySQL数据库启动时,会进行恢复操作。
- 参数
innosb_force_recovery影响了整个InnoDB存储引擎恢复的状况。该参数的默认值是0,表示当发生需要恢复时,进行所有的恢复操作,当不能进行有效恢复时,如数据页发生了corruption,MySQL数据库可能发生宕机(crash),并把错误写入错误日志中去。该参数可设置的值如下:- 1(SRV_FORCE_IGNORE_CORRUPT):忽略检查到的corrupt页。
- 2(SRV_FORCE_NO_BACKGROUND):阻止主线程的运行,如主线程需要执行full purge操作,会导致crash。
- 3(SRV_FORCE_NO_TRX_UNDO):不执行事务回滚操作。
- 4(SRV_FORCE_NO_IBUF_MERGE):不执行插入缓冲的合并操作。
- 5(SRV_FORCE_NO_UNDO_LOG_SCAN):不查看重做日志,InnoDB存储引擎会将未提交的事务视为已提交。
- 6(SRV_FORCE_NO_LOG_REDO):不执行前滚的操作。