版权声明:guojawee https://blog.csdn.net/weixin_36750623/article/details/84137102
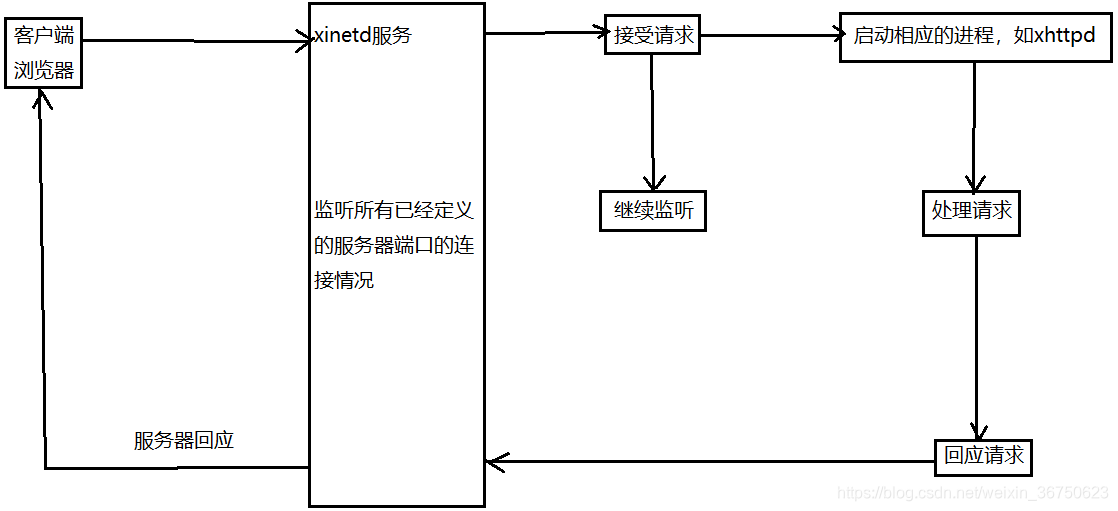
xinetd工作原理
客户端请求服务器数据
| 客户端请求服务器数据内容 |
|---|
| GET /请求的文件或目录 HTTP/1.1 |
| 协议头部分(可选) |
| \r\n(协议头结束标志) |
服务器应答浏览器
| case1:浏览器请求文件不存在 |
|---|
| HTTP/1.1 200 OK |
| content_Type:回写客户端的数据的类型 |
| content-Length:要么干脆不填,要么一定要正确(可选)-fctnl、stat |
| \r\n(协议头结束标志) |
| 数据 |
| case2:浏览器请求文件不存在 |
|---|
| HTTP/1.1 200 OK |
| content_Type:回写客户端的数据的类型 |
| \r\n(协议头结束标志) |
| 回写的数据是—404的错误页面 |
常见的回写客户端的数据的类型
普通文件:text/plain; charset=ios-8859-1
*.html:text/html; charset=ios-8859-1
*.jpg : image/jpeg
*.gif : image/gif
*.png : image/png
*.wav : video/x-msvideo
*.mov : video/quicktime
*.mp3 : audio/mpeg
其中:编码
charset=ios-8859-1 西欧的编码,说明网站采用的编码是英文
charset=gb2312 网站采用的简体中文
charset=utf-8 代表世界通用的语言编码
charset=euc-kr 网站采用的编码是韩文
charset=big5 网站采用的编码是繁体中文
分析xhttpd服务器的实现功能:
xinetd在启动xhttp可执行文件是,会给它的argv[1]传参—>参数是:配置文件server_args的值(/server_args=/var/xhttp/mh_html),该目录下存放在浏览器需要访问的资源
根据之前配置的xinetd配置文件可知,可执行程序的工作目录为server=/usr/local/sbin/httpd/xhttpd—>所以,要获得浏览器需要的资源文件,此处使用拼接绝对路径的方式访问/var/xhttp/mh_html下的资源文件
1.从标准输入逐行读取fget客户端发来的http协议头;解析http协议头,获取客户端请求的文件名
2.判断客户端请求的文件是否存在:
(1)存在:①判断请求的文件是什么类型—>如果是文件,则直接回写文件内容;如果是目录,则返回目录列表。②回写http协议头 ③回写文件内容
(2)不存在:①回写http协议头②回写类型(*.html; charset=iso-8859-1)③回写错误页面(404的html页面)
实现代码
xinetd作用
1.监听浏览器的请求,当请求到达时与浏览器建立好连接
2.将stdin重定向到浏览器的发送端,即:xhttpd程序只需要使用fget从标准输入中读取浏览器的请求数据
3.将stdout重定向到浏览器的接收端,即:把响应数据写入标准输出中
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <ctype.h>
#include <dirent.h>
#define LEN 4096
char* get_filetype(const char* file);
void send_error(int status,char* title);
void send_header(int status,char* title, char* filetype);
void decode(char* to, char* from);
void encode(char* to, char* from);
//xinetd ---> xhttpd argv[1]:浏览器请求的资源所在的目录/server_args=/var/xhttp/mh_html
int main(int argc,const char* argv[])
{
if(argc < 2)
send_error(500,"server error : argc < 2");
if(chdir(argv[1]) < 0)
send_error(500,"server error : chdir error");
char line[LEN],type[LEN],path[LEN],protocol[LEN];
//读取浏览器发来的请求,即:GET /lufei.jpg HTTP/1.1
if(fgets(line,sizeof(line),stdin) == NULL) //标准输入 ---> line
send_error(500,"server error : type path protocol");
if(sscanf(line,"%[^ ] %[^ ] %[^ ]",type,path,protocol) != 3) //line ---> type,path,protocol
send_error(400,"bad request");
if(strcasecmp(type,"GET") != 0) //type = GET
send_error(400,"method not allow");
if(path[0] != '/') // path = /lufei.jpg
send_error(404,"file not found");
while(fgets(line,sizeof(line),stdin) != NULL)
{
if(strcmp(line,"\n") == 0 || strcmp(line,"\r\n") == 0)
break;
}
char file[LEN];
struct stat st;
file[0] = '.';
decode(file+1,path);
//printf("%s\n",&path[1]);
//printf("%s\n",file);
if(stat(file,&st) < 0)
{
printf("file : %s\r\n",file);
send_error(500,"server error : stat");
}
if(S_ISDIR(st.st_mode))
{
send_header(200,"OK","text/html;charset=utf-8");
printf("<html>"
"<head><title>Index of %s</title></head>"
"<body bgcolor=\"#cc99cc\">"
"<h4>Index of %s</h4>"
"<pre>"
,file,file);
struct dirent** dl;
int nf = scandir(file,&dl,NULL,alphasort);
if(nf < 0)
perror("scandir");
else
{
struct stat fst;
char stfile[LEN];
for(int i=0;i<nf; ++i)
{
strcpy(stfile,file);
strcat(stfile,"/");
strcat(stfile,dl[i]->d_name);
if(lstat(stfile,&fst) < 0)
printf("<a href=\"%s%s/\">%-32.32s/</a>",file+1,dl[i]->d_name,dl[i]->d_name);
else if(S_ISDIR(fst.st_mode))
printf("<a href=\"%s%s/\">%-32.32s/</a> \t\t%14lld",file+1,dl[i]->d_name,dl[i]->d_name,(long long)fst.st_size);
else
printf("<a href=\"%s%s\">%-32.32s</a> \t\t%14lld",file+1,dl[i]->d_name,dl[i]->d_name,(long long)fst.st_size);
printf("<br/>");
}
}
printf("</pre>"
"</body>"
"</html>");
}
else
{
//普通文件
FILE* fp = fopen(file,"r");
if(fp == NULL)
send_error(500,"server error : open file");
send_header(200,"send header",get_filetype(file));
int ch;//这里必须用int判断EOF,我真是菜鸡。
while((ch = getc(fp)) != EOF)
{
putchar(ch);
}
fflush(stdout);
fclose(fp);
fp = NULL;
}
// printf("test success !\n");
return 0;
}
int hex2d(char hex)
{
if(hex >= '0' && hex <= '9')
return hex-'0';
else if(hex >= 'a' && hex <= 'f')
return hex-'a'+10;
else if(hex >= 'A' && hex <= 'F')
return hex-'A'+10;
else
return hex;
}
void decode(char* to, char* from)
{
if(to == NULL || from == NULL)
return;
while(*from != '\0')
{
if(from[0] == '%' && isxdigit(from[1]) && isxdigit(from[2]))
{
*to = hex2d(from[1])*16 + hex2d(from[2]);
from += 3;
}
else
{
*to = *from;
++from;
}
++to;
}
*to = '\0';
}
void encode(char* to, char* from)
{
if(to == NULL && from == NULL)
return;
while(*from != '\0')
{
if(isalnum(*from) || strchr("/._-~",*from) != NULL)
{
*to = *from;
++to;
++from;
}
else
{
sprintf(to,"%%%02x",*from);
to += 3;
from += 3;
}
}
*to = '\0';
}
char* get_filetype(const char* file)
{
if(file == NULL)
return NULL;
char* dot = strrchr(file,'.');
if(*dot == '\0')
return "text/plain; charset=utf-8";
else if(strcmp(dot,".html") == 0)
return "text/html; charset=utf-8";
else if(strcmp(dot, ".jpg") == 0)
return "image/jpeg";
else if(strcmp(dot, ".gif") == 0)
return "image/gif";
else if(strcmp(dot, ".png") == 0)
return "image/png";
else if(strcmp(dot, ".wav") == 0)
return "audio/wav";
else if(strcmp(dot, ".avi") == 0)
return "video/x-msvideo";
else if(strcmp(dot, ".mov") == 0)
return "video/quicktime";
else if(strcmp(dot, ".mp3") == 0)
return "audio/mpeg";
else
return "text/plain; charset=utf-8";
}
void send_header(int status, char* title, char* filetype)
{
if(title == NULL || filetype == NULL)
{
title = "ERROR";
filetype = "text/plain; charset=utf-8";
}
printf("HTTP/1.1 %d %s\r\n",status,title);
printf("Content-Type:%s\r\n",filetype);
printf("\r\n");
}
void send_error(int status,char* title)
{
if(title == NULL)
title = "ERROR";
send_header(status,title,"text/html; charset=utf-8");
//将html的内容直接printf,就是回复给浏览器
printf("<html>\n"
"<head><title>%d %s</title></head>\n"
"<body bgcolor=\"#cc99cc\">\n"
"<h4>error!</h4>\n"
"<hr>\n"
"<address>\n"
"<a href=\"http://blog.csdn.net/gongluck93/\">gongluck</a>\n"
"</address>\n"
"</body>\n"
"</html>",
status,title);
fflush(stdout); //刷新标准输出缓冲区,让浏览器显示页面
exit(1);
}