Map和Set
一)HashMap
1.Map接口
interface Map<K,V> { int size();//查看Map中的键值对个数 boolean isEmpty();//是否为空 boolean containsKey(Object key);//是否包含某个键 boolean containsValue(Object value);//是否包含某个值 V get(Object key);//根据键获取值,没找到返回null V put(K key, V value);//保存键值对,如果原来有key,则覆盖并返回原来的值,原来没有这个键返回null V remove(Object key);//根据键删除键值对,返回key原来的值,如果不存在,返回null void putAll(Map<? extends K,? extends V> m);//保存m中所有的键值对到当前map void clear();//清空Map中的所有键值对 Set<K> keySet();//获取Map中所有键的集合 Collection<V> values();//获取Map中所有值的集合 Set<Map.Entry<K, V>> entrySet();//获取Map中所有的键值对 interface Entry<K,V> { //嵌套接口表示一个键值对 K getKey();//获取键 V getValue();//获取值 V setValue(V value);//设置值 boolean equals(Object o); int hashCode(); } boolean equals(Object o); int hashCode(); }
keySet()、values()、entrySet()有一个共同特点,它们返回的都是视图,
不是复制值,基于返回值的修改都会修改Map自身。例如:
map.keySet().clear();//会删除所有键值对
2.HashMap
构造方法:
public HashMap(int initialCapacity) public HashMap(int initialCapacity, float loadFactor) public HashMap(Map<? extends K, ? extends V> m)
主要实例变量:
static final Entry<?,?>[] EMPTY_TABLE = {};
//table是一个Entry类型的数组,称为哈希表或者哈希桶, //其中每个元素指向一个单向链表,链表中的每个节点表示一个键值对 transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE; transient int size; //实际键值对个数 int threshold;//表示阈值,当键值对个数size大等于该值时考虑扩展 threshold = table.length * loadFactor final float loadFactor;
Entry是一个内部类,构造方法:
static class Entry<K,V> implements Map.Entry<K,V> { final K key; V value; Entry<K,V> next; //指向下一个节点 int hash; //key的hash值 Entry(int h, K k, V v, Entry<K,V> n) { value = v; next = n; key = k; hash = h; //存储hash值是为了在比较的时候加快速度 } }
当添加键值对后,table就不是空表了,它会随着键值对的添加进行扩展,扩展的策略类似于ArrayList.
默认构造方法:
public HashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); } //其中DEFAULT_INITIAL_CAPACITY=16,DEFAULT_LOAD_FACTOR=0.75
调用了:
public HashMap(int initialCapacity, float loadFactor) { this.loadFactor = loadFactor; threshold = initialCapacity; }
put方法:
public V put(K key, V value) { if(table == EMPTY_TABLE) { inflateTable(threshold); } if(key == null) return putForNullKey(value); int hash = hash(key); //计算key的hash值 int i = indexFor(hash, table.length); //计算应该将这个键值对放入table中的哪个位置
//注意table是一个单向链表,现在在这个链表中查找是否已经有这个键 for(Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if(e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++;
addEntry(hash, key, value, i); return null; }
final int hash(Object k) { int h = 0 h ^= k.hashCode(); h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }
static int indexFor(int h, int length) { return h & (length-1);//等同于h%length }
如果是第一个保存,先调用inflateTable方法给table分配空间:
private void inflateTable(int toSize) { //Find a power of 2 >= toSize int capacity = roundUpToPowerOf2(toSize); //capacity的默认值为16 threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); //默认为12 table = new Entry[capacity]; }
void addEntry(int hash, K key, V value, int bucketIndex) { if((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length);
hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); }
void createEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<>(hash, key, value, e); size++; }
总结保存键值对过程:
1)计算键的哈希值
2)根据哈希值得到保存位置
3)插到对应位置的链表头部或更新已有值
4)根据需要扩展table大小
例子:
Map<String,Integer> countMap = new HashMap<>(); countMap.put("hello", 1); countMap.put("world", 3); countMap.put("position", 4);

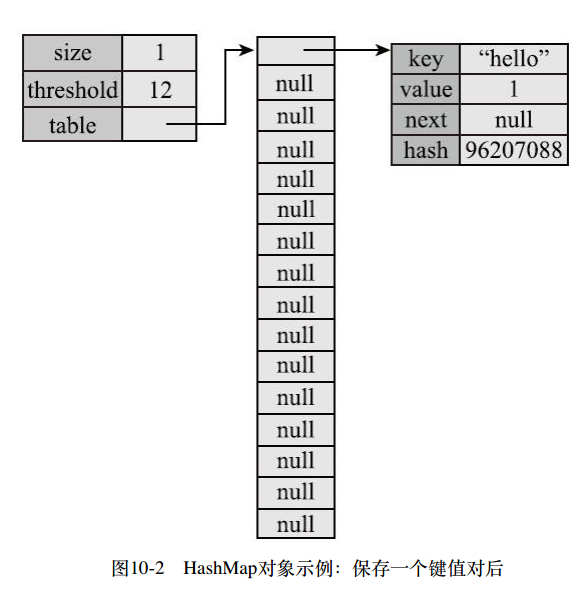


3.查找方法
public V get(Object key) { if(key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }
final Entry<K,V> getEntry(Object key) { if(size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); for(Entry<K,V> e = table[indexFor(hash, table.length)];e != null; e = e.next) { Object k; if(e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }
containsKey()方法逻辑与之类似:
public boolean containsKey(Object key) { return getEntry(key) != null; }
HashMap可以方便高效地按键进行操作,但如果要按值进行操作,就要进行遍历:
public boolean containsValue(Object value) { if(value == null) return containsNullValue(); Entry[] tab = table; for(int i = 0; i < tab.length ; i++) for(Entry e = tab[i] ; e != null ; e = e.next) if(value.equals(e.value)) return true; return false; }
4.按键删除键值对
public V remove(Object key) { Entry<K,V> e = removeEntryForKey(key); return(e == null ? null : e.value); }
final Entry<K,V> removeEntryForKey(Object key) { if(size == 0) { return null; } int hash = (key == null) ? 0 : hash(key); int i = indexFor(hash, table.length); Entry<K,V> prev = table[i]; Entry<K,V> e = prev; while(e != null) { Entry<K,V> next = e.next; Object k; if(e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) { modCount++; size--; if(prev == e) table[i] = next; else prev.next = next; e.recordRemoval(this); return e; } prev = e; e = next; } return e; }
5.实现原理总结
1)根据键获取和保存值的效率都很高,为O(1),单向链表往往只有一个或
少数几个节点,根据hash值就可以快速直接定位;
2)HashMap中的键值对没有顺序,因为hash值是随机的。
注意,HashMap不是线程安全的,Java中还有一个类HashTable,它是Java最早实现的
容器类之一,实现了Map接口,实现原理与HashMap类似,但没有特别优化,它内部通过
synchronized实现了线程安全。另外,在HashMap中键和值都可以为null,而在HashTable
中不可以。在不需要并发安全的场景中推荐使用HashMap。高并发场景中,推荐使用ConcurrentHashMap。
根据哈希值存取对象、比较对象是计算机程序中的一种重要思维方式,它使得存取对象主要依赖于自身
的哈希值,而不是与其他对象进行比较,存取效率也与集合大小无关,高达O(1),即使是进行比较,也能
比较Hash值提高比较效率。
二)HashSet
1.概述
HashSet实现了Set接口。
Set接口表示的是没有重复元素,且不保证顺序的容器的接口,
它扩展自Collection,虽然没有定义任何新方法,不过
对于其中的一些方法,它有自己的规范。
public interface Set<E> extends Collection<E> { int size(); boolean isEmpty(); boolean contains(Object o); //迭代遍历时不强制要求元素之间有特别的顺序 //但某些Set实现可能有顺序,比如ThreeSet Iterator<E> iterator(); Object[] toArray(); <T> T[] toArray(T[] a); //添加元素时,如果集合中已经存在相同元素了,则不会改变集合,直接返回false //只有不存在时才会添加,返回true boolean add(E e); boolean remove(Object o); boolean containsAll(Collection<?> c); //重复的元素不添加,不重复的元素才添加,如果集合有变化,返回true boolean addAll(Collection<? extends E> c); boolean retainAll(Collection<?> c); boolean removeAll(Collection<?> c); void clear(); boolean equals(Object o); int hashCode(); }
构造方法与HashMap类似:
public HashSet() public HashSet(int initialCapacity) public HashSet(int initialCapacity, float loadFactor) public HashSet(Collection<? extends E> c)
与HashMap类似,HashSet要求元素重写hashCode与equals方法,且对于两个对象,
如果equals相同,则hashCode也必须相同。如果元素是自定义类特别要注意这一点。
public class Dog { private String name; private int number; public Dog(String name, int number) { this.name = name; this.number = number; } @Override public String toString() { return "Name: " + name + " Number: " + number; } }
Dog a = new Dog("King", 110); Dog b = new Dog("King", 110); HashSet<Dog> dogs = new HashSet<>(); dogs.add(a); dogs.add(b); System.out.println("The set is " + dogs); //The set is [Name: King Number: 110, Name: King Number: 110]
2.实现原理
HashSet内部是用HashMap实现的,其内部有一个HashMap实例变量:
private transient HashMap<E,Object> map;
Map有键和值,HashSet相当于只有键,值都是相同的固定值,这个值定义为:
private static final Object PRESENT = new Object();
构造方法:
public HashSet() { map = new HashMap<>(); }
public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<>(initialCapacity, loadFactor); }
public HashSet(Collection<? extends E> c) { map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); addAll(c); }
add方法:
public boolean add(E e) { return map.put(e, PRESENT)==null; }
检查是否包含:
public boolean contains(Object o) { return map.containsKey(o); }
删除:
public boolean remove(Object o) { return map.remove(o)==PRESENT; }
迭代器:
public Iterator<E> iterator() { return map.keySet().iterator(); }
3.HashSet特点总结
1)没有重复元素
2)没有顺序
3)可以高效地添加,删除,判断元素是否存在