一、概序
linux内存管理包含内存初始化、页表映射过程、内核内存布局图、伙伴系统、SLAB分配器、vmalloc、malloc、mmap缺页中断等内容。按层分可以分为用户空间、内核空间和硬件层,下面的图可以详细的说明:
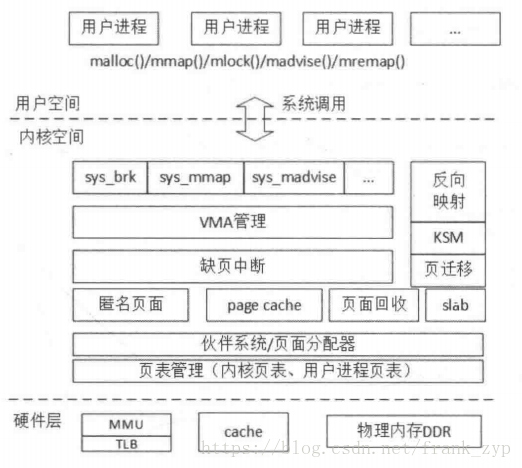
二、内核内存分布
1、物理内存大小:
现在设备的管理方式都是通过设备数来管理,memory的大小也同样在设备树的DTS中定义如下:
memory {
device_type = "memory";
reg = <0 0x80000000 0 0x20000000>;
};
在内核启动start_kernel函数中回去获取对应的memory的起始地址和大小,并加入到memblock中,因为在内核启动的初期,伙伴系统等分配的内存的方式还未初始化好,所以通过memblock的方式来分配管理内存。其调用流程如下:
start_kernel -> setup_arch -> setup_machine_fdt -> early_init_dt_scan_nodes -> early_init_dt_scan_memory
int __init early_init_dt_scan_memory(unsigned long node, const char *uname,
int depth, void *data)
{
/* We are scanning "memory" nodes only */
if (type == NULL) {
if (!IS_ENABLED(CONFIG_PPC32) || depth != 1 || strcmp(uname, "memory@0") != 0)
return 0;
} else if (strcmp(type, "memory") != 0)
return 0;
base = dt_mem_next_cell(dt_root_addr_cells, ®);
size = dt_mem_next_cell(dt_root_size_cells, ®);
early_init_dt_add_memory_arch(base, size); //在这里通过一系列的处理后加入到memblock中
return 0;
}
void __init __weak early_init_dt_add_memory_arch(u64 base, u64 size)
{
memblock_add(base, size);
}
2、内存的管理方式:
在start_kernel ->…-> create_mapping中创建页表后,内核就可以对物理内存进行管理了,管理方式如下:
a、内存被划分为很多node的节点,通过pg_data_t类型的结构体来管理;
b、每一个node又划分为不同簇即zone来管理,一般划分为ZONE_DMA/ZONE_NOMAL/ZONE_HIGHEM ;
通过struct zone_struct的结构体来描叙;
c、页面(page)是页面分配的基本单位,内存中的每个页都会创建一个struct page来管理。
其中zone的类型在如下文件中定义:
enum zone_type {
ZONE_DMA, //0~15MB,此部分簇的内存用来执行DMA操作
ZONE_NORMAL, //16MB~895MB,这个区包含的都是能正常映射的页
ZONE_HIGHMEM, //896MB~物理内存结束,这部分在“高端内存”中使用到,64bit的的kernel一般无此zone
}
zone的初始化在start_kernel( ) -> free_area_init_core中在free_area_init_core函数中会依次创建每一个zone,另外在start_kernel->build_zonelists_node的中会初始化zonelist的结构体伙伴系统会从zonelist中开始分配内存。
3、用户空间和内核空间划分
linux的用户内核空间划分,对于ARM32bit和ARM64bit的内核存在一定的差异,因为32bit的linux的能使用的虚拟地址的空间为4G,当物理内存大于4G时即无法访问,故存在高端内存的概率(后续详细讲解)。但ARM64bit的结构采用48位物理寻址机制,最大可以访问256TB的物理地址空间,对于目前的应用来说,完全已经足够,不需要扩展到64位的物理寻址。虚拟地址同样最大支持48位寻址,所以把虚拟地址空间划分为两个空间,每个空间最大支持256TB。
(1)32bit 内核空间划分:
32bit的内核用户空间和内核空间划分通常按照3:1划分,当然也支持2:2来划分,由以下代码控制,默认会选择VMSPLIT_3G,即用户空间大小为3G,内核空间的大小为1G。PAGE_OFFSET用于计算物理地址无虚拟地址的偏移量。
kernel-3.18/arch/arm/Kconfig
choice
prompt "Memory split"
depends on MMU
default VMSPLIT_3G
config VMSPLIT_3G
bool "3G/1G user/kernel split"
config VMSPLIT_2G
bool "2G/2G user/kernel split"
config VMSPLIT_1G
bool "1G/3G user/kernel split"
endchoice
config PAGE_OFFSET
hex
default PHYS_OFFSET if !MMU
default 0x40000000 if VMSPLIT_1G
default 0x80000000 if VMSPLIT_2G
default 0xC0000000
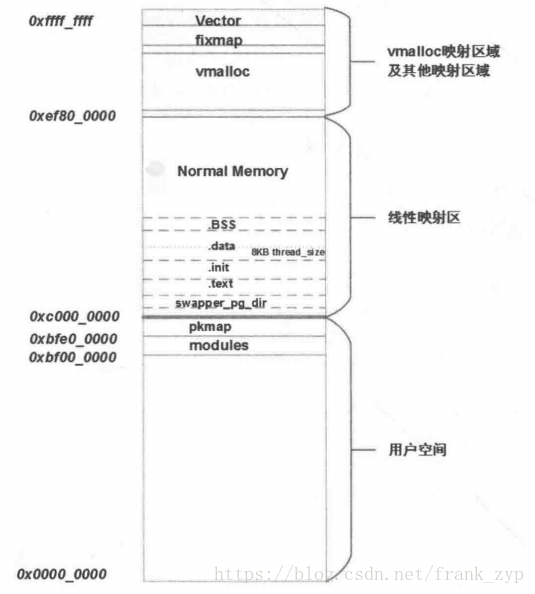
下面看ARM32内核的分布图,在linux内核启动的会打印出对应的内核空间布局图如下:
[ 0.000000] <0>-(0)[0:swapper]Virtual kernel memory layout:
[ 0.000000] <0> vector : 0xffff0000 - 0xffff1000 ( 4 kB)
[ 0.000000] <0> fixmap : 0xffc00000 - 0xfff00000 (3072 kB)
[ 0.000000] <0> vmalloc : 0xe1000000 - 0xff800000 ( 488 MB)
[ 0.000000] <0> lowmem : 0xc0000000 - 0xe0800000 ( 520 MB)
[ 0.000000] <0> pkmap : 0xbfe00000 - 0xc0000000 ( 2 MB)
[ 0.000000] <0> modules : 0xbf000000 - 0xbfe00000 ( 14 MB)
[ 0.000000] <0> .text : 0xc0008000 - 0xc0e00000 (14304 kB)
[ 0.000000] <0> .init : 0xc1200000 - 0xc1400000 (2048 kB)
[ 0.000000] <0> .data : 0xc1400000 - 0xc1526154 (1177 kB)
[ 0.000000] <0> .bss : 0xc1528000 - 0xc1867984 (3327 kB)
其中内核编译出来的Bootimage本身占据了内存空间的_text段到 _end段,分为如下几段,在内核编译出来的System.map文件中可以查询到:
- 代码段:_text和_etext为代码段的起始地址和结束地址,包含了内核编译成的内核代码;
- init段:__init_begin和__init_end中间的部分,包含了模块初始化的数据;
-数据段:_sdata和_edata之间的部分,包含内核的变量;
-BSS段:__bss_start和__bss_stop之间的部分,包含初始化为0的所有静态全局变量;
用户空间和内核空间使用3:1的方式划分,内核空间1GB的空间部分空间可以直接访问物理地址,称为线性映射区,物理地址的[0:760M]的内存被线性映射到[3GB:3GB+760M]的虚拟地址上。线性映射区的物理地址与虚拟地址的相差PAGE_OFFSET(3GB/0xc0000000)的大小,可以通过如下函数实现转换:
//kernel-3.18/arch/arm/include/asm/memory.h
static inline phys_addr_t __virt_to_phys(unsigned long x)
{
return (phys_addr_t)x - PAGE_OFFSET + PHYS_OFFSET;
}
static inline unsigned long __phys_to_virt(phys_addr_t x)
{
return x - PHYS_OFFSET + PAGE_OFFSET;
}
内核把物理内存低于760M的称为线性映射区(Normal memory),高于760M的物理内存称为高端内存(High memory),由于32位系统的寻址能力只有4GB,对于物理内存760M~4GB的情况,保留240MB的虚拟地址空间划分用于动态映射高端内存,这样内核空间就可以访问到全部的4GB的物理内存了。对于物理内存高于4GB的请,可以使用LPE机制来拓展物理内存访问。其中内存布局图如下:
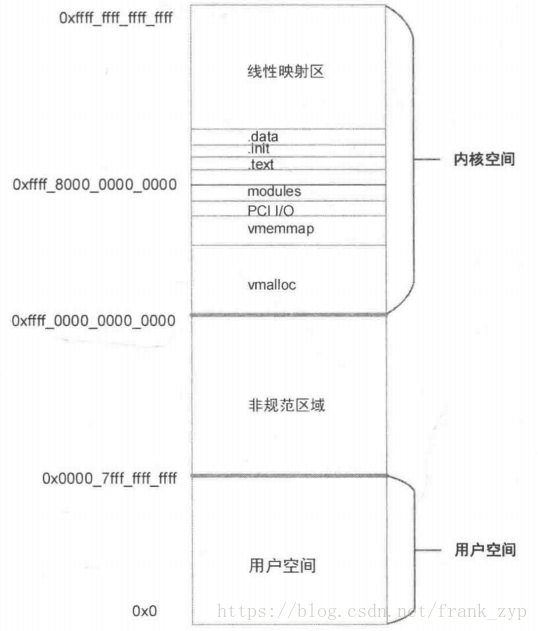
(2)64bit 内核空间划分:
ARM64架构的内核采用48位物理寻址,最大可以访问256TB的物理地址空间,通常吧虚拟地址空间划分为两个空间,每个空间最大支持256TB,划分如下:
-用户空间:0x0000 0000 0000 0000 - 0x0000 ffff ffff ffff 256TB
-内核空间:0xffff 0000 0000 0000 - 0xffff ffff ffff ffff 256TB
64位的内核没有高端内存的概念,器内存分布图如下:
三、物理内存初始化
内核分配内存的方式大部分都是通过或者间接的通过buddy系统来管理,用户在在申请内存时,伙伴系统会分配一块合适的内存块(2^order page)给用户,在用户释放时回收。order的最大值为MAX_ORDER,即11,故每个内存块链表包含2/4/8/16…1024个连续的页面。物理内存分为不同的zone来管理,不同的zone都通过如下结构体来管理:
struct zone {
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];//zone内存水位相关
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER]; //空闲页面
unsigned long *pageblock_flags; //页面类型
......
}
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
上面可以看出zone的结构体中中有free_area 的数组,数组的大小是MAX_ORDER,free_area的数据结构中有MIGRATE_TYPES个链表,其关系如下图:
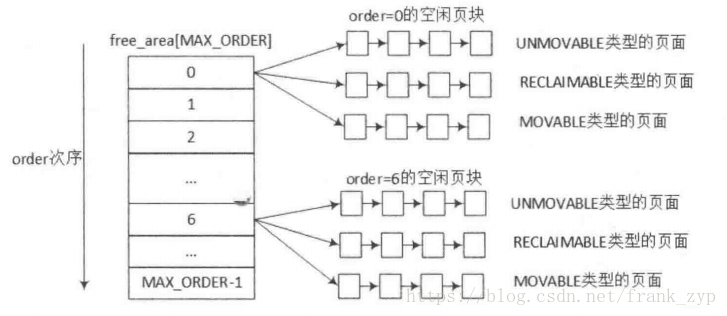
MIGRATE_TYPES的的类型也在mmzone.h的文件中定义:
enum {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
MIGRATE_TYPES
};
在内核初始化的时候,使用的是memblock的方式来管理内存的,当内核准备好的时候,会遍历所有的memblock的内存块,找到内存块的起始地址和结束地址以2^order的方式加入的伙伴系统中。
start_kernel -> mm_init -> mem_init-> free_all_bootmem -> free_low_memory_core_early
static unsigned long __init free_low_memory_core_early(void)
{
unsigned long count = 0;
phys_addr_t start, end;
memblock_clear_hotplug(0, -1);
//遍历所有memblock的起始地址和结束地址
for_each_free_mem_range(i, NUMA_NO_NODE, MEMBLOCK_NONE, &start, &end,NULL)
//开始释放内存到伙伴系统中
count += __free_memory_core(start, end);
return count;
}
__free_memory_core经过一系列处理后会调用到伙伴系统的核心函数__free_pages来释放内存:
__free_memory_core -> __free_pages_memory -> __free_pages_bootmem -> __free_pages_boot_core -> __free_pages
static void __init __free_pages_boot_core(struct page *page,
unsigned long pfn, unsigned int order)
{
unsigned int nr_pages = 1 << order;
struct page *p = page;
unsigned int loop;
prefetchw(p);
for (loop = 0; loop < (nr_pages - 1); loop++, p++) {
prefetchw(p + 1);
__ClearPageReserved(p);
set_page_count(p, 0);
}
__ClearPageReserved(p);
set_page_count(p, 0);
page_zone(page)->managed_pages += nr_pages;
set_page_refcounted(page);
__free_pages(page, order);
}
作者:frank_zyp
您的支持是对博主最大的鼓励,感谢您的认真阅读。
本文无所谓版权,欢迎转载。