# -*- coding: utf-8 -*-
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
from sklearn import tree
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import classification_report
from sklearn.cross_validation import train_test_split
plt.switch_backend('agg')
# 数据读入
data = []
labels = []
with open("file_fac_abe.txt") as ifile:
for line in ifile:
tokens = line.strip().split(',')
#print('tokens:',tokens)
data.append([int(tk) for tk in tokens[:-1]])
labels.append(tokens[-1])
x = np.array(data)
labels = np.array(labels)
y = np.zeros(labels.shape)
print('x:',x)
print(len(x))
print('labels:',labels)
print(len(labels))
print('y:',y)
print(len(y))
#标签转换为0/1
y[labels=='LCS']=1
print('y:',y)
#拆分训练数据与测试数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2,random_state=0)
'''
print('x_train:',x_train)
print(len(x_train))
print('x_test:',x_test)
print(len(x_test))
print('y_train:',y_train)
print(len(y_train))
print('y_test:',y_test)
print(len(y_test))
'''
# 使用信息熵作为划分标准,对决策树进行训练
clf = tree.DecisionTreeClassifier(criterion='entropy')
#print('clf:',clf)
clf.fit(x_train, y_train)
print('clf:',clf)
# 把决策树结构写入文件 '''
with open("DT_fac_abe_tree.dot", 'w') as f:
f = tree.export_graphviz(clf, out_file=f)
# 系数反映每个特征的影响力。越大表示该特征在分类中起到的作用越大 '''
print('clf.feature_importances_:',clf.feature_importances_)
#测试结果的打印
answer = clf.predict(x_test)
print('x_test:',x_test)
print('answer:',answer)
print('y_test:',y_test)
print('np.mean(answer==y_test):',np.mean( answer == y_test))
#准确率与召回率
precision, recall, thresholds = precision_recall_curve(y_test, clf.predict(x_test))
answer = clf.predict_proba(x_test)[:,1]
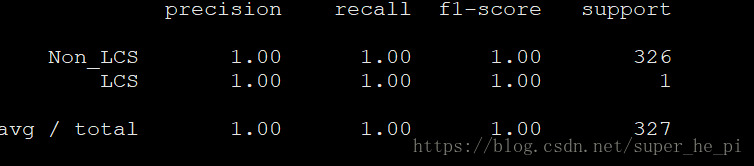
print(classification_report(y_test, answer, target_names = ['Non_LCS','LCS']))
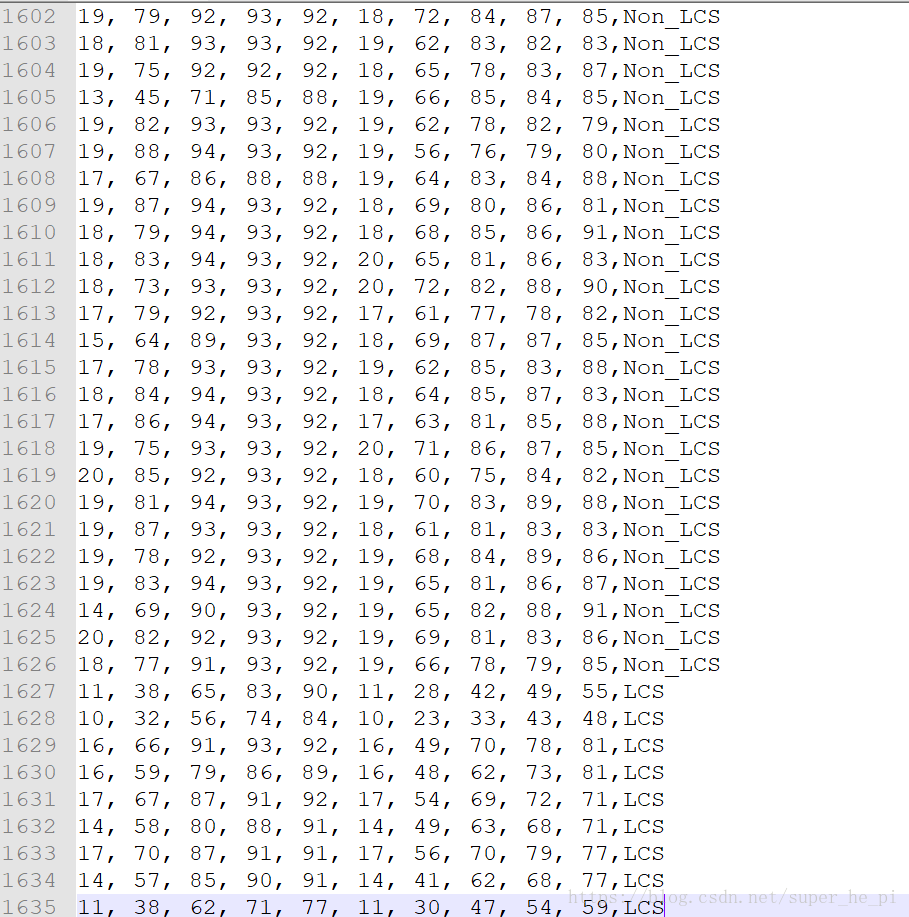
文件为“file_fac_abe.txt”,其格式为:
得到结果如下:
(train_set_model)

(test_results) :