查找是数据库操作中一个非常重要的技术。查询一般就是使用filter、exclude以及get三个方法来实现。我们可以在调用这些方法的时候传递不同的参数来实现查询需求。在ORM层面,这些查询条件都是使用field+__+condition的方式来使用的。以下将那些常用的查询条件来一一解释。
准备工作:
新建一个项目,配置settings文件连接至mysql数据库,
新建一个front的app,将app添加至settings中,然后在article中新建一个模型
from django.db import models
# Create your models here.
class Article(models.Model):
title = models.CharField(max_length=200)
content = models.TextField()
class Meta:
# 自定义数据表名称
db_table = 'article'
然后makemigrations后在migrate,然后我们打开navicat,找到article这个表,我们手动添加几条信息进去,以便后面测试。例如,我手动添加的4条信息
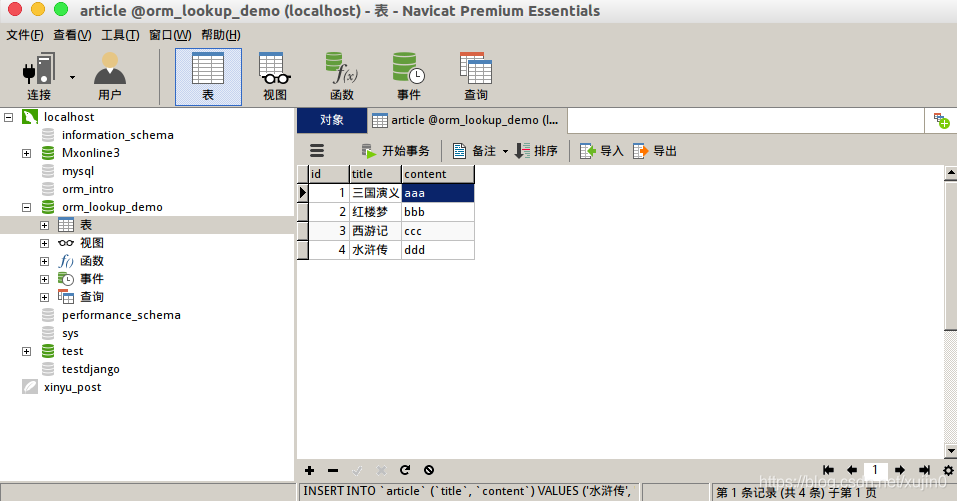
查询条件
1. exact:
使用方法,在属性名后面
在front这个app中的views中添加一个函数:
from django.shortcuts import render
from django.http import HttpResponse
from . import models
# Create your views here.
def index(request):
article1 = models.Article.objects.filter(id__exact = 1)
article2 = models.Article.objects.get(id__exact=1)
print(article1)
print(article2)
return HttpResponse('success')
然后运行项目,我们可以发现打印出来的东西是不一样的,用filter方法返回的是一个QuerySet的对象,get返回的就是一个我们能直接使用的对象,
到这里我们可以发现,以前我们使用这两个方法获取对象的时候,直接使用的时get(id=1)或filter(id=1)就直接得到了对象,为什么还需要加一个__exact呢。
起始__exact是默认的选项,在我们使用get(id=1)就是相当于get(id__exact=1),所以我们以后也不用写__exact,但是我们也需要了解一下。
我们可以通过query这个属性来查看翻译为sql语言的源码
def index(request):
article1 = models.Article.objects.filter(id__exact = 1)
article2 = models.Article.objects.get(id__exact=1)
print(article1.query)
print(article2.query)
return HttpResponse('success')
然后运行项目会发现报错了,是因为我们使用get()返回的对象是没有query这个属性的,filter()返回的才有这个属性,所以我们只需要将print(article2.query)这句代码注释掉就行了。
然后我们就能看到在控制台看到article1 = models.Article.objects.filter(id__exact = 1)这句代码翻译为sql原生语句的代码了
SELECT `article`.`id`, `article`.`title`, `article`.`content` FROM `article` WHERE `article`.`id` = 1
2. iexact:
iexact和exact的功能是差不多一样的,我们可以使用query查看一下sql源码,修改views中的代码
def index(request):
article1 = models.Article.objects.filter(id__exact = 1)
article2 = models.Article.objects.filter(id__iexact = 1)
print(article1.query)
print(article2.query)
return HttpResponse('success')
运行项目查看sql源码

可以看到只是后面的=变成了LIKE了,这就是iexact和exact的区别,所以exact和iexact的区别实际上就是LIKE和=的区别,在大部分collation=utf8_general_ci情况下都是一样的(collation是数据库的排序规则)。所以我们可以默认iexact和exact一样的。
总结:
- LIKE和=:大部分情况下都是等价的,只有少数情况下是不等价的。
- exict和iexact:他们的区别其实就是LIKE和=的区别,因为exact会被翻译成=,而iexact会被翻译成LIKE。
- 因为
field__exact=xxx其实等价于filed=xxx,因此我们直接使用filed=xxx就可以了,并且因为大部分情况exact和iexact又是等价的,因此我们以后直接使用field=xxx就可以了。 query可以用来查看这个ORM查询语句最终被翻译成的SQL语句。但是query只能被用在QuerySet对象上,不能用在普通的ORM模型上。因此如果你的查询语句是通过get来获取数据的,那么就不能使用query,因为get返回的是满足条件的ORM模型,而不是QuerySet。如果你是通过filter等其他返回QuerySet的方法查询的,那么就可以使用query。
3. contains和icontains:
查询某个字符串是否在指定的字段中
这两个的用法99%的情况下都是一样的,区别只在与
contains大小写敏感,而icontains大小写不敏感。
示例代码:修改index中的代码
def index(request):
# article1 = models.Article.objects.filter(id__exact = 1)
# article2 = models.Article.objects.filter(id__iexact = 1)
# print(article1.query)
# print(article2.query)
article1 = models.Article.objects.filter(id__contains=1)
article2 = models.Article.objects.filter(id__icontains = 1)
print(article1.query)
print(article2.query)
return HttpResponse('success')
然后运行我们就能查看到sql语句了

contains:这个判断条件会使用大小写敏感,因此在被翻译成SQL语句的时候,会使用like binary,而like binary就是使用大小写敏感的。
icontains:这个判断条件会使用大小写不敏感,因此在被翻译成SQL的时候,使用的是like,而like在MySQL层面就是不区分大小写的。
我们可以看到在1的左右两边都有%意思就是在1的左右两边都可以与另外的字符,也就是123,213这些都拿呢个被查找出来,所以我们一般不对id这个字段进行contains或icontains的判断,而是对其他字段。
contains和icontains:在被翻译成SQL的时候使用的是%1%,就是只要整个字符串中出现了1都能过够被找到,而iexact没有百分号,那么意味着只有完全相等的时候才会被匹配到。这就是contains与exiact的区别。
4. in:可以直接指定某个字段的是否在某个集合中。
修改index中的代码:
def index(request):
# exact和iexact
# article1 = models.Article.objects.filter(id__exact = 1)
# article2 = models.Article.objects.filter(id__iexact = 1)
# print(article1.query)
# print(article2.query)
# contains和icontains
# article1 = models.Article.objects.filter(id__contains=1)
# article2 = models.Article.objects.filter(id__icontains = 1)
# print(article1.query)
# print(article2.query)
# in
articles = models.Article.objects.filter(id__in=[1,2,3])
for article in articles:
print(article)
return HttpResponse('success')
我们就能够将id为1,2,3的数据查找出来,如果没有的话,就返回一个空的QuerySet列表。
注意: 在这里articles拥有query属性,而article没有。
为了接下来的测试,我们需要在models中新建一个模型,然后时哟个外键。
from django.db import models
# Create your models here.
class category(models.Model):
name = models.CharField(max_length=100)
class Meta:
# 自定义数据表名称
db_table = 'category'
class Article(models.Model):
title = models.CharField(max_length=200)
content = models.TextField()
category = models.ForeignKey('category',on_delete=models.CASCADE,null=True)
class Meta:
# 自定义数据表名称
db_table = 'article'
然后执行makemigrations后再migrate。然后打开navicat,在category中添加一条信息,article中的外键也增加信息。
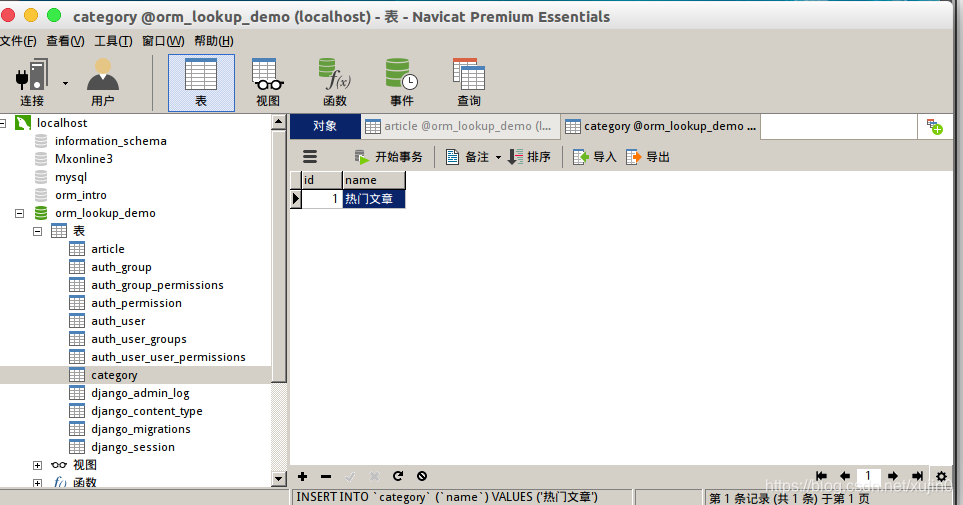
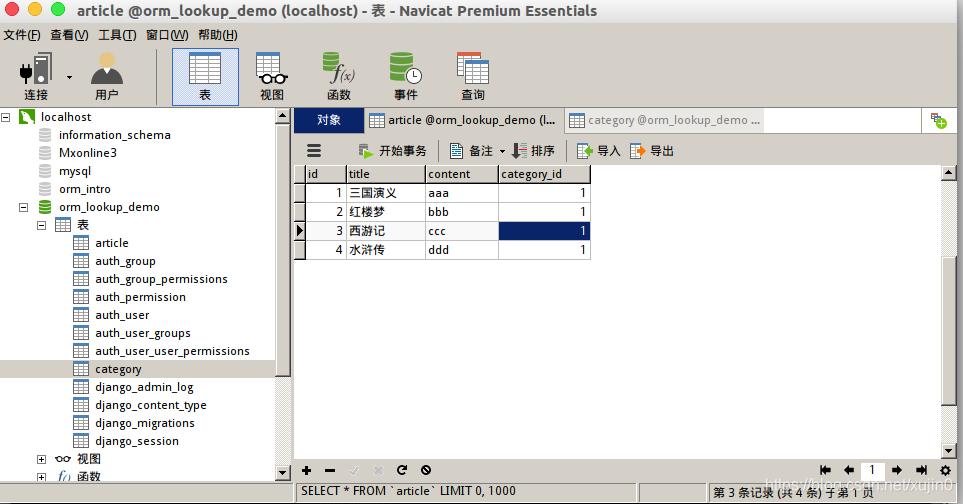
接下来我们要根据已经知道的文章id来查找所属分类。
修改views中的代码
def index(request):
# exact和iexact
# article1 = models.Article.objects.filter(id__exact = 1)
# article2 = models.Article.objects.filter(id__iexact = 1)
# print(article1.query)
# print(article2.query)
# contains和icontains
# article1 = models.Article.objects.filter(id__contains=1)
# article2 = models.Article.objects.filter(id__icontains = 1)
# print(article1.query)
# print(article2.query)
# in
# articles = models.Article.objects.filter(id__in=[1,2,3])
# print(articles.query)
# for article in articles:
# print(article)
# 查找id为1,2,3的文章的分类
categories = models.category.objects.filter(article__id__in = [1,2,3])
print(categories)
return HttpResponse('success')
这样我们就将article的id为[1,2,3]的种类查找了出来,当然,在这个地方article__id我们也是可以使用related_query_name来另外取一个名字的。这里就不做演示了。
注意:
反向查询是将模型名字小写化。比如article__in。可以通过related_query_name来指定自己的方式,而不使用默认的方式。反向引用是将模型名字小写化,然后再加上_set,比如article_set,可以通过related_name来指定自己的方式,而不是用默认的方式。
我们也可以将article__id__in中的__id去掉,然后就会默认使用__id来查找。
in不仅仅可以指定列表/元组,还可以为QuerySet。
5. gt、gte、lt、lte:
代表的是大于、大于等于、小于、小于等于的条件。
示例代码:
修改views中的函数代码:
def index(request):
# exact和iexact
# article1 = models.Article.objects.filter(id__exact = 1)
# article2 = models.Article.objects.filter(id__iexact = 1)
# print(article1.query)
# print(article2.query)
# contains和icontains
# article1 = models.Article.objects.filter(id__contains=1)
# article2 = models.Article.objects.filter(id__icontains = 1)
# print(article1.query)
# print(article2.query)
# in
# articles = models.Article.objects.filter(id__in=[1,2,3])
# print(articles.query)
# for article in articles:
# print(article)
# 查找id为1,2,3的文章的分类
# categories = models.category.objects.filter(articles__in = [1,2,3])
# print(categories)
articles = models.Article.objects.filter(id__gt=2)
print(articles)
return HttpResponse('success')
这样我们就能取的article中id>2的文章了
其它几个可自行尝试。
6. startswith、istartswith、endswith、iendswith:
表示以某个值开始,不区分大小写的以某个值开始、以某个值结束、不区分大小写的以某个值结束。
例如:
articles = Article.objects.filter(title__startwith="hello")
articles = Article.objects.filter(title__iendswith="hello")
articles = Article.objects.filter(title__endswith="hello")
articles = Article.objects.filter(title__iendswith="hello")
接下来时对时间的查询相关操作,所以首先我们应该先去修改一下我们的models,添加一个create_time
from django.db import models
# Create your models here.
class category(models.Model):
name = models.CharField(max_length=100)
class Meta:
# 自定义数据表名称
db_table = 'category'
class Article(models.Model):
title = models.CharField(max_length=200)
content = models.TextField()
category = models.ForeignKey('category',on_delete=models.CASCADE,null=True,related_query_name='articles')
create_time = models.DateTimeField(auto_now_add=True,null=True)
class Meta:
# 自定义数据表名称
db_table = 'article'
然后在makemigratios后在migrate,如果遇到报错就将数据库中的所有表都删除了,然后再将app下的migrations下除了__init__.py以外 的文件全部删除了,然后重新运行makemigrations后在migrate。
然后我们在views中新定义一个函数index1(),然后添加映射。
from datetime import datetime
def index1(request):
start_time = datetime(year=2018,month=11,day=2,hour=16,minute=0,second=0)
end_time = datetime(year=2018,month=11,day=2,hour=17,minute=0,second=0)
articles = models.Article.objects.filter(create_time__range=(start_time,end_time))
print(articles)
print(articles.query)
return HttpResponse('sucess')
这样,我们就是用range条件查找到了所需要的信息。
但是,我们也收到了一个警告,它说我们的时间是一个navie类型的时间,所以我们需要将它转化为aware的时间。
所以修改代码:
from django.utils.timezone import make_aware
def index1(request):
start_time = make_aware(datetime(year=2018,month=11,day=2,hour=16,minute=0,second=0))
end_time = make_aware(datetime(year=2018,month=11,day=2,hour=17,minute=0,second=0))
articles = models.Article.objects.filter(create_time__range=(start_time,end_time))
print(articles)
print(articles.query)
return HttpResponse('sucess')
这样,就不会有警告生成了。
7. date:
用年月日来进行过滤。
示例代码,添加一个index2的函数:
def index2(request):
articles = models.Article.objects.filter(create_time__date = datetime(year=2018,month=11,day=2))
print(articles.query)
print(articles)
return HttpResponse('success')
然后添加映射,然后我们发现并没有查找出结果出来,但是我们是刚才添加的信息,时间也是设置为刚才的,为什么没有信息呢。
原因是因为MySQL默认是没有储存时区相关的信息,但是在执行sql语句时我们发现对时区进行了装换,所以时不会得到我们想要的结果的。因此我们需要下载一些时区表的文件,然后添加到mysql的配置路径中。
windows中
在http://dev.mysql.com/downloads/timezones.html下载timezone_2018d_posix.zip - POSIX standard。然后将下载下来的所有文件拷贝到C:\ProgramData\MySQL\MySQL Server 5.7\Data\mysql中,如果提示文件名重复,那么选择覆盖即可。
linux或者mac系统
在命令行中执行以下命令:mysql_tzinfo_to_sql /usr/share/zoneinfo | mysql -D mysql -u root -p,然后输入密码,从系统中加载时区文件更新到mysql中。
然后对上面的代码不需要进行改动,也能执行成功了
8. year/month/day:表示根据年/月/日进行查找。
示例代码:
articles = models.Article.objects.filter(create_time__year=2018)
我们还可以对年进行更复杂的操作,例如
articles = models.Article.objects.filter(pub_date__year__gte=2017)
9. week_day:
根据星期来进行查找。1表示星期天,7表示星期六,2-6代表的是星期一到星期五。比如要查找星期三的所有文章,那么可以通过以下代码来实现:
articles = models.Article.objects.filter(create_time__week_day=4)
10.time:
根据时间进行查找。
如果要具体到秒,一般比较难匹配到,因为数据库中秒后面还有小数。可以使用区间的方式来进行查找。区间使用range条件。比如想要获取17时/10分/27-28秒之间的文章,那么可以通过以下代码来实现:
from datetime import datetime,time
start_time = time(hour=17,minute=10,second=27)
end_time = time(hour=17,minute=10,second=28)
articles = models.Article.objects.filter(create_time__time__range=(start_time,end_time))
更多的关于时间的过滤,请参考Django官方文档:https://docs.djangoproject.com/en/2.1/ref/models/querysets/#range
11.isnull:
根据值是否为空进行查找。
示例代码:
# 查询title为空的
articles = models.Article.objects.filter(create_time__isnull=True)
# 查询title不为空的
articles = models.Article.objects.filter(create_time__isnull=False)
12.regex和iregex:
大小写敏感和大小写不敏感的正则表达式。示例代码如下
articles = models.Article.objects.filter(title__regex=r"^三国")
当然,我们还可以进行复杂的正则表达式,这里就不细说了。