HDFS高可用集群原理及搭建
如何实现HDFS高可用?
HDFS的高可用是HDFS持续对客户端提供读、写服务的能力,因为客户端对HDFS的读写操作之前要访问namenode服务器,客户端需要从namenode端获取元数据之后才能继续进行读、写。HDFS的高可用的关键在于nodename元数据持续可用,之前的完全分布式中的secondaryNamenode是把namenode的fsimage和edit log做定期融合,融合后传给namenode, 以确保备份到的元数据是最新的,这一点类似于做了一个元数据的快照。在高可用中存在两个namenode,高可用完全分布主要包括下图所示部分:
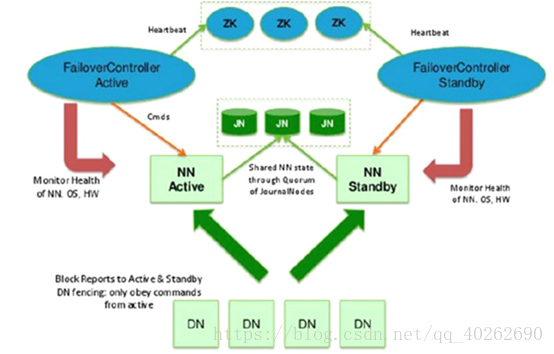
Namenode节点
集群中存在2个namenode,二者之中只能有一个namenode处于活跃状态(active),另一个是待命状态(standby),只有active的NN节点才能对外提供读写HDFS服务,也只有active态的namenode才能向JN写入编辑日志;standby状态的namenode负责从JN小集群中拷贝数据到本地。另外,各个datanode也要同时向两个名称节点报告状态(心跳信息、块信息)。
Journal Node集群(简称JN)
同时在高可用完全分布式配置下,edit log不再存放在名称节点,而是存放在一个共享存储的地方,这个共享存储由奇数个J4组成,一般是3个节点(JN小集群), 每个JN专门用于存放来自namenode的编辑日志,编辑日志由活跃状态的名称节点写入JN小集群。2个namenode与3个JN构成的组保持通信,活跃的名称节点负责往JN集群写入编辑日志,待命的名称节点负责观察JN集群中的编辑日志,并且把日志拉取到待命节点,再加上两个namenode各自的fsimage镜像文件,这样一来就能确保两个namenode的元数据保持同步。
主备切换控制器 (ZKFailoverController 简称ZKFC)
ZKFC作为独立的进程运行,对 NameNode 的主备切换进行总体控制。ZKFC 能及时检测到 NameNode 的健康状况,在主 NameNode 故障时借助 Zookeeper 实现自动的主备选举和切换,当然 NameNode 目前也支持不依赖于 Zookeeper 的手动主备切换。一旦active nodename不可用,提前配置的zookeeper会把standby节点自动变为active状态,继续对外提供读写服务。
Zookeeper 集群(简称ZK)
ZK:为主备切换控制器提供主备选举支持。
共享存储系统:共享存储系统是实现 NameNode 的高可用最为关键的部分,共享存储系统保存了 NameNode 在运行过程中所产生的 HDFS 的元数据。主 NameNode 和
NameNode 通过共享存储系统实现元数据同步。在进行主备切换的时候,新的主 NameNode 在确认元数据完全同步之后才能继续对外提供服务。
高可用完全分布式环境的搭建
分布式集群规划图
| 主机名 | IP地址 | NN-1 | NN-2 | DN | ZK | ZKFC | JNN |
| node01 | 192.168.23.128 | √ | √ | √ | |||
| node02 | 192.168.23.129 | √ | √ | √ | √ | √ | |
| node03 | 192.168.23.130 | √ | √ | √ | |||
| node04 | 192.168.23.131 | √ | √ |
搭建高可用完全分布式
1、配置免密登录
在完全分布式的基础上需要再配置node02–>到node01上的免密
在node02节点执行,将node01的公钥加入到其他节点的白名单中
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node01
2、关闭防火墙
sudo service iptables stop # 关闭防火墙服务。
sudo chkconfig iptables off # 禁止防火墙开机自启。
3、所有节点配置JDK
(1)解压JDK安装包
(2)通过下面代码配置环境变量
#先删除系统自带的1.7版本的JDK
yum remove *openjdk*
#进入用户环境变量配置
vim ~/.bashrc
# 接着需要配置JAVA环境变量.
# 在文件最后添加(注:环境变量要与JDK存放位置对应)
export JAVA_HOME=/opt/software/jdk/jdk1.8.0_151
export PATH=$JAVA_HOME/bin:$PATH
# 接下来需要使用source命令是环境变量生效.
source ~/.bashrc
#验证是否生效
java -version.
4、安装Hadoop
安装Hadoop以及配置环境变量可参考HDFS伪分布式的环境搭建,这里也不再细说。
5、时间同步
#各个节点安装ntp
yum install ntp
#安装完成后每个节点都执行如下命令从而达到时间同步
#ntp1.aliyun.com为阿里的时间服务器
ntpdate ntp1.aliyun.com
6、配置hosts文件
vi /etc/hosts
// 实现主机名映射
192.168.23.128 node01
192.168.23.129 node02
192.168.23.130 node03
192.168.23.131 node04
7、修改hdfs-site.xml配置文件
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/sxt/hadoop/ha/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
8、配置core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
9、修改slaves配置文件
修改为(注:之间用换行,且不能有空格)
node02
node03
node04
10、将配置好的HDFS安装包拷贝到node02 node03 node04
11、搭建zookeeper
将zookeeper解压在自定义目录下
修改conf下的zoo_sample.cfg的名称,改为zoo.cf(方便修改)
mv zoo_sample.cfg zoo.cfg
#修改zo.cfg
vi zoo.cfg
#配置文件信息
dataDir=/var/zfg/zookeeper
server.1=node02:2888:3888
server.2=node03:2888:3888
server.3=node04:2888:3888
在dataDir的目录下创建myid文件,在这个文件中写上当前节点id 与server后数字对应(需自己将上面的目录结构创建出来,路径可以自己自定义)。
将配置好的zookeeper安装包拷贝到node03、node04,并且各节点创建myid号,与上面各节点的数字对应。
启动zookeeper
到zookeeper/bin 目录下
分别在三个节点上启动 ./zkServer.sh start
(注:zookeeper要在集群启动前启动)
12、格式化NameNode
#在node01、node02、node03分别执行如下命令
hadoop-daemon.sh start journalnode
# 随机选择一台NameNode执行:
hdfs namenode -format
hadoop-daemon.sh start namenode
#另外一台NameNode节点执行:
hdfs namenode -bootstrapStandby
#格式化ZKFC
hdfs zkfc -formatZK
13、关闭所有节点,并重新启动
#关闭所有节点上的进程
stop-dfs.sh
#启动HDFS
start-dfs.sh
以上就是高可用环境搭建的全部过程