需求分析
- 初级用户:
- 只有一台开发主机
- 能够通过 Scrapyd-client 打包和部署 Scrapy 爬虫项目,以及通过 Scrapyd JSON API 来控制爬虫,感觉命令行操作太麻烦,希望能够通过浏览器直接部署和运行项目
- 专业用户:
- 有 N 台云主机,通过 Scrapy-Redis 构建分布式爬虫
- 希望集成身份认证
- 希望在页面上直观地查看所有云主机的运行状态
- 希望能够自由选择部分云主机,一键部署和运行爬虫项目,实现集群管理
- 希望自动执行日志分析,以及爬虫进度可视化
- 希望在出现特定类型的异常日志时能够及时通知用户,包括自动停止当前爬虫任务
安装和配置
- 所有主机都已经安装和启动 Scrapyd
- 开发主机或任一台主机安装 ScrapydWeb: pip install scrapydweb
- 运行命令 scrapydweb -h ,将在当前工作目录生成 scrapydweb_settings.py 配置文件
- 启用 HTTP 基本认证
ENABLE_AUTH = True USERNAME = 'username' PASSWORD = 'password'
- 添加 Scrapyd server,支持字符串和元组两种配置格式,支持添加认证信息和分组/标签
SCRAPYD_SERVERS = [ '127.0.0.1', # 'username:password@localhost:6801#group', ('username', 'password', 'localhost', '6801', 'group'), ]
- 通过运行命令 scrapydweb 启动 ScrapydWeb
访问 Web UI
通过浏览器访问 http://127.0.0.1:5000,输入认证信息登录
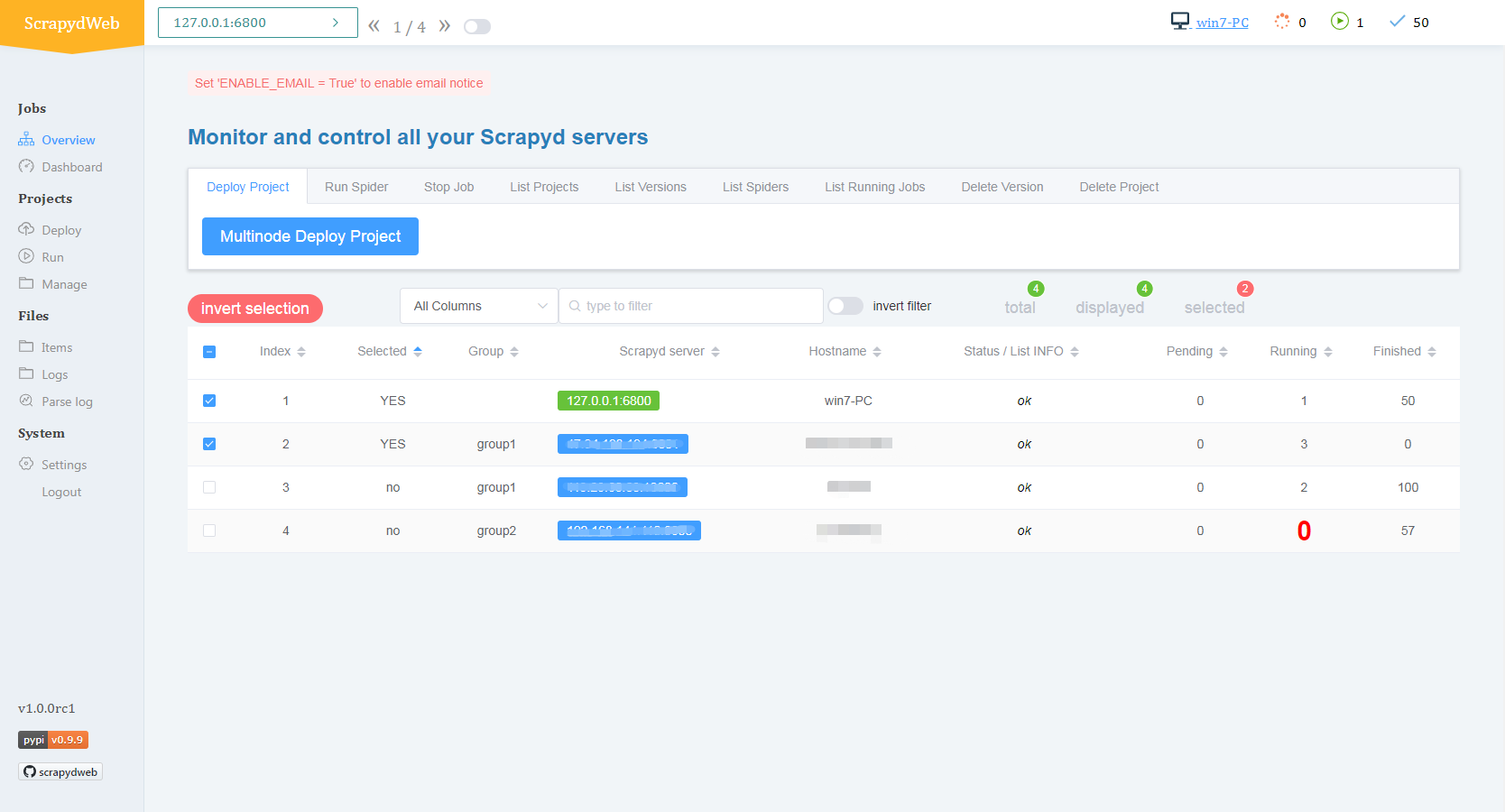
- Overview 页面自动输出所有 Scrapyd server 的运行状态
- 通过分组和过滤可以自由选择若干台 Scrapyd server,调用 Scrapyd 提供的所有 JSON API,实现一次点击,批量执行
部署项目
- 支持指定若干台 Scrapyd server 部署项目
- 通过配置 SCRAPY_PROJECTS_DIR 指定 Scrapy 项目开发目录,ScrapydWeb 将自动列出该路径下的所有项目,自动打包和部署指定项目

- 如果 ScrapydWeb 并非运行于当前开发主机,除了支持上传常规的 egg 文件,也可以将单个项目文件夹添加到 zip/tar/tar.gz 压缩文件后直接上传即可

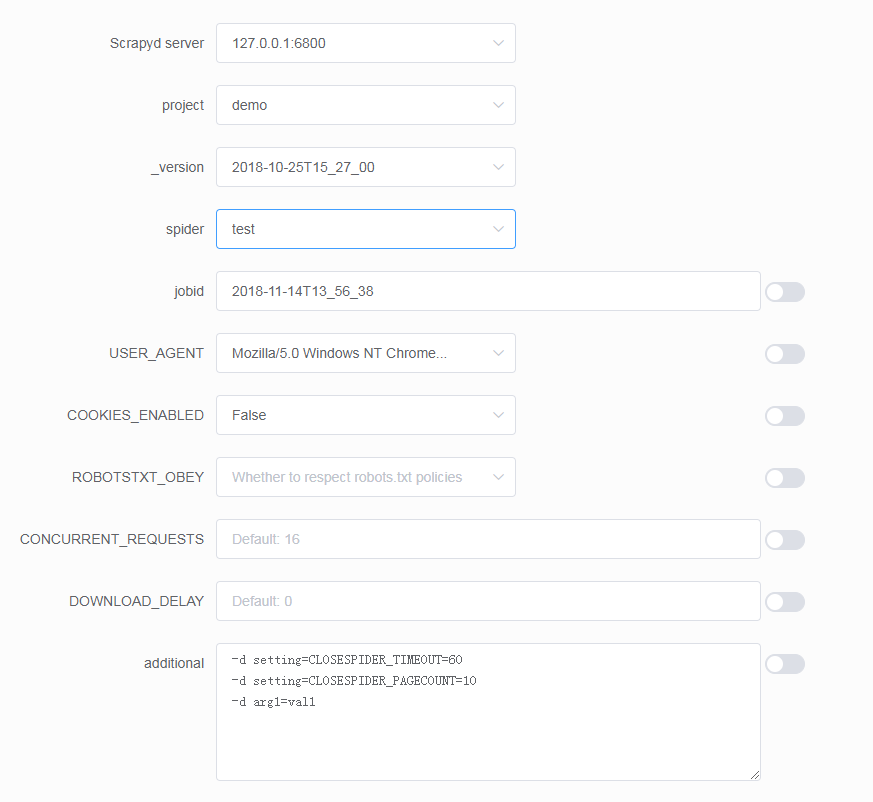
运行爬虫
- 通过下拉框直接选择 project,version 和 spider
- 支持传入 Scrapy settings 和 spider arguments
- 同样支持指定若干台 Scrapyd server 运行爬虫
日志分析和可视化
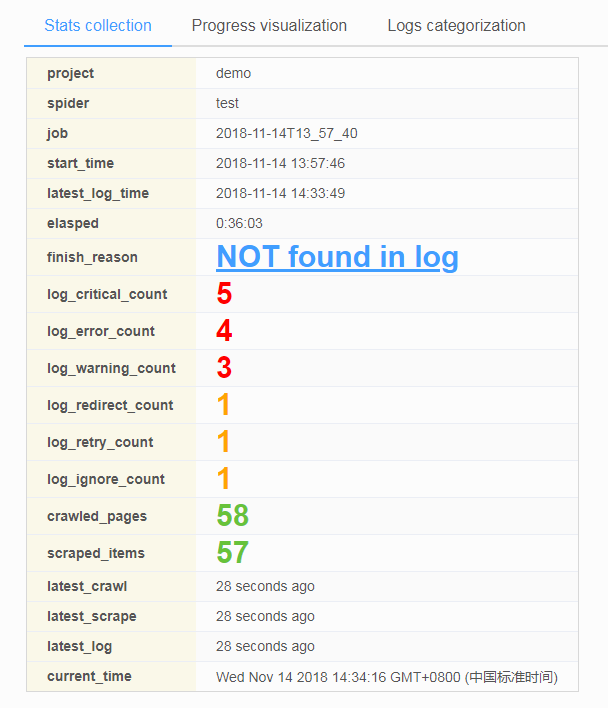
- ScrapydWeb 默认在后台定时自动读取和分析 Scrapy log 文件并生成 Stats 页面
- 爬虫进度可视化

邮件通知
- 配置邮箱认证信息
SMTP_SERVER = 'smtp.qq.com' SMTP_PORT = 465 SMTP_OVER_SSL = True SMTP_CONNECTION_TIMEOUT = 10 FROM_ADDR = '[email protected]' EMAIL_PASSWORD = 'password' TO_ADDRS = ['[email protected]']
- 设置邮件工作时间和定时通知间隔,以下示例为:每隔1小时或某一任务完成时,并且当前时间是工作日的9点,12点和17点,ScrapydWeb 将会发送邮件告知当前运行任务的统计信息
EMAIL_WORKING_DAYS = [1, 2, 3, 4, 5] EMAIL_WORKING_HOURS = [9, 12, 17] ON_JOB_RUNNING_INTERVAL = 3600 ON_JOB_FINISHED = True
- 基于后台定时执行日志分析,ScrapydWeb 提供多种 log 类型触发器及其阈值设置,包括 'CRITICAL', 'ERROR', 'WARNING', 'REDIRECT', 'RETRY', 'IGNORE'等。以下示例为:当发现3条或3条以上的 critical 级别的 log 时自动停止当前任务,如果当前时间在邮件工作时间内,则同时发送通知邮件。
LOG_CRITICAL_THRESHOLD = 3 LOG_CRITICAL_TRIGGER_STOP = True LOG_CRITICAL_TRIGGER_FORCESTOP = False ... LOG_IGNORE_TRIGGER_FORCESTOP = False
Github 开源
my8100 / scrapydweb 更多实用功能正在开发中,欢迎 Star 和提交 Issue