区分强化学习和其他种类的学习方式最显著的特点是:在强化学习中,训练信息被用于评估动作的好坏,而不是用于指导到底该是什么动作。这也是为何需要主动去做exploration的原因。纯粹的评估性反馈可以表明一个动作的好坏、但并不能知道当前动作是否是最佳选择或者是最差选择。评估性反馈(包括evoluationary method)是方程优化的基础。相对的,纯粹的指导性反馈,表明了当前的最优动作,这个最优动作是独立于实际采取的动作的。这种反馈形式是监督学习的基础,被用于模式识别、人工神经网络等方面。当然了,也有一些交叉案例中,这两种反馈形式同时使用。
这一章主要在一种简单的情境下研究强化学习的这种反馈形式,这种简单情形只包含一个环境状态,这样能避免完整的强化学习问题的很多复杂方面,从而专注于研究evaluative feedback 和instuctive feedback的不同,以及如何对两者进行结合使用。
这个简单的案例叫做多臂赌博机问题。我们用这个案例来学习一些强化学习中的基本学习方法,在这章末尾,我们会讨论一下当环境状态不止一个时,多臂赌博机的学习问题会是什么样子。
2.1 n-armed bandit problem:
这里稍微描述一下多臂赌博机这个概念。赌博机,也可以想象成老虎机,现在我有n台老虎机,每台有一个臂(也就是杠杆)我可以通过拉动这个臂来获得这台老虎机的reward,但是每台赌博机的这个reward是按照一定的概率分布的,因此有上下浮动,不是固定不变的。现在呢,我需要解决的问题就是最大限度地通过杠杆拉动序列,使得获得的奖励最大。这个序列的次数是任意的。
对于每台老虎机的臂,都有一个期望reward,也就是我们之前说的value。当然这个value的数值之前肯定是不知道的,不然这个问题就没有意义了。然而我们可以大概估计这个value值。
如果我们保持我们的这种value估计,那么在每次选择动作之前肯定至少有一个臂的value是最大的。如果我们每次都选这个最大的value值的臂,那么这就是贪婪动作。如果我们每次都采取贪婪选择,那我们就是在exploiting。如果我们每次不这么干,而是有时去选一些非贪婪选择的臂,那么我们就是在exploring(探索),因为这样我们就能改进对其他臂value信息的估计。exploitation当然是正确的,因为它是当前这一步的最优选择,然而exploration也许会帮助我们在长远的序列中得到更大的total reward。比如:假设每次做选择的时候,贪婪选项的value是可以确定的,但是非贪婪选项的value值带有一定的不确定性。这种不确定性的意思是,有可能个别的非贪婪选项的value会好于贪婪选项的value,但是不确定是哪个。这样的情况下,适当的exploration有助于帮我们找到可能存在的比贪婪选项更好的那个选择。可能在短期内reward比较低,然而一旦找到了,我们就可以反复选择(exploit)那个之前被认为非贪婪的选项,从而使得长期reward总和较高。
在特定的情形下,是exploiting还是exploring取决于很多因素。比如value估计值的精确程度、非贪婪值的不确定性或者是剩余的选择机会等等。有很多复杂的方法来平衡这两者的选择,然而大多数这样的方法都有很强的假设前提或者先验知识,而这些前提条件在很多的实际强化学习问题中是不能被保证的。当这些假设前提不被保证时,这些方法的效果也就不那么出色了。
在这一章,我们不必去用复杂的方法把exploiting和exploring之间平衡的那么好,而只是单纯的去平衡就好了。我们会用几种简单的方法去实现两者间的平衡,并表明平衡之后的学习效果要好于一味的exploiting。
2.2 action-value method:
首先,我们先来仔细的做一下value的估计。我们把每个action的真实value定义为,把每个action在第t个时间步下的估计值定义为
。之前我们提到过,每个action的真实value,是当该动作被选择时所获得的期望reward,在这里,我们自然想到用最简洁的历史平均reward来表示当前动作的value估计值。假定某个action在t时间前总共被选择了
次,于是我们的估计值如下式:
这个方法叫做sample-average,因为每个动作的estimated value都是依据过往sample reward的平均值进行计算的。当等于0,我们可以把定义为一个默认的初始值,当
趋近无穷,则最终收敛于
。当然这个estimate的方法不一定是最好的,但是不要紧。
最简单的选择策略就是每次选择action value最大的那个。也就是使得,这样的策略只是exploiting,不exploring。另一个简单的方法就是大部分时间用来exploiting,然而每隔一段时间,比如说以概率为
的可能性,来exploring。因为这种方法和贪婪方法很像,就叫做
方法。这种做法的好处是随着选择次数的增加,对每个动作的选择次数都会趋向无穷,也就保证了每个动作的estimate value都无限趋近真实值。
为了粗略的评估greedy算法和算法的优劣,我们做了2000次实验,赌博机的个数,每个赌博机的臂拉下的真实value服从高斯分布。在t时间的每个臂被选择时的reward用真实值外加服从高斯标准正太分布(mean = 0 variance = 1)的噪声之和来表示。
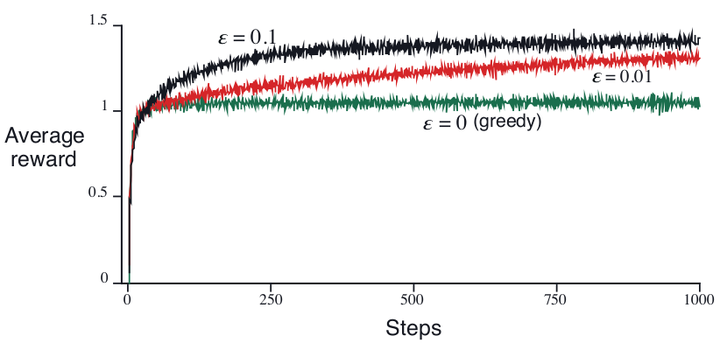
上图表明了经过2000次实验后的10个臂的平均reward水平。可以看出来随着实验次数增加,到了后期,算法的优势开始显现。
当然,算法相对于greedy算法的优势也并非始终。当噪声方差很大时
算法可以通过较多的exploration来找到最优动作,这种情况下其相对于greedy算法的优势很明显。而当噪声方差为0时,这种优势就不尽然了。然而,就算是在deterministic的任务下,exploration想比于none-exploration也有很多优势。比如假设赌博臂是nonstationary的,也就是它的真实value是不确定的(刚才我们讨论的真实value是确定的,而在实际情况下,不确定的value更普遍)。
总之,这一节通过简单的对比实验告诉我们,exploiting和exploration之间的平衡是必须的。
2.3 soft-max action selection
提出softmax action selection的主要目的是因为上一节的算法针对剩下的所有选择都采取同样的概率,这样会导致最坏的选择也会同等机会被选中,这不是我们想要的。一个明显的解决办法是让每个赌博机臂被选中的概率和其estimate value相关联。对于在t时间选中动作a的概率,由下式给出:
越大,则概率分布的越均衡,
越小,那么不同选项被选中的概率差异越大。
softmax-greedy算法和算法都只有一个参数需要人为选择。但是很多人觉得
的参数
很好设置,但是
却不好准确设置,因为有了指数的缘故。因此,近些年来,softmax算法逐渐不太流行,一方面因为参数难以合理设置,另一方面也是因为在不知道实际value的情况下,更不能知道其中的概率和estimate value之间的关系。但是,当我们在后文中涉及policy-based方法时会再回来看这个softmax-selection的。
2.4 Incremental Implementation
这一节主要改进的是计算和内存复杂度。
回顾一下前文中的value estimation公式:
可以发现,为了算在t时间的action a的value estimation,我们需要t时间之前所有时间该动作的reward记录。随着时间增加,这种计算方式涉及的计算复杂度和存储压力都会增加。
其实这是不必要的,我们完全可以用另一种方式来计算。推导如下:
用这个形式的迭代公式,只需要保存和k,再加上一点简单的加减运算,就可以快速得到
。
这个形式的写法贯穿于本书,需要加以注意:
target-oldEstimate是estimate的error,乘以stepsize是不断地减小这个error,逼近target。在这个例子中,target就是第k次选择某动作的的reward。实际上,stepsize也是随着时间而变化的,在本书的其他地方,常用来表征stepsize,或者更精确的
。在这里
。
2.5 Tracking a Nonstationary problem
到目前为止为们讨论的sample-average算法针对stationary environment是适用的,然而当我们面对Nonstationary environment时,就需要加以改变。首先说明一下什么叫stationary,什么叫nonstationary。所谓stationary,在这个例子中就是指赌博机的臂是不随着时间改变的,也就是说我们可以认为其真实的value值是保持不变的。相对应的,nonstationary,就是说赌博机的臂会随着时间改变,也就是其真实value值是随时间变化的。尽管在我们的场景想象中认为赌博机怎么会随时间变化,但是这里讨论的是更广泛的强化学习的问题情形所常见的nonstationary现象。
回归到nonstationary话题,在这种情况下,我们需要更加依赖近期的reward信息,而不太依赖很远时间前的reward信息,因为赌博机的臂总是变化,近期的更有参考意义。因此,我们可以把stepsize变成固定值,而非之前的。为什么stepsize变成固定值就能起到上述效果呢?看下式:
我们把这种形式叫做weighted average,权重平均,注意看每一个的权重都依赖于它离当前选择的时间长短。有时候,这种形式也被叫做exponential,recency-weighted average。
当stepsize随着时间变化时,比如用表征第k次选择动作
时的stepsize,如果要保证随着实验次数的增加,选择某一个stepsize能使最终estimate value收敛于real value,那么stepsize需要满足一点条件。如下:
这两个条件需要同时被stepsize满足。第一个条件保证了最终stepsize足够大,可以克服任何初始条件或者随机波动;第二个条件保证了最终stepsize变得足够小可以收敛。
注意到我们在之前的sample-average中使用的stepsize--,它同时满足这两个条件,但是后来的这个constant stepsize---
却不满足第二个条件,这表明了在这种stepsize情况下,estimate value永远不会收敛到real value,并且会随着近期的reward信息而不断变化。但是在nonstationary情形下,这种性质是我们需要的,因为我们每个动作的真实value都在变。另外,满足上述两个条件的stepsize收敛通常都非常慢,并且需要大量的调参,才能使得其收敛效果令人满意。尽管这种条件上的限制性在理论上很重要,在实际应用中其实大家都不怎么在意这些限制条件。
2.6 Optimistic initial value
目前为止我们讨论的所有方法都是不依赖初始值的,用统计科学的话说,就是这些方法都有初始值偏差。对于sample-average算法,当所有的十个赌博机的臂都被选择过至少一次后,这种偏差就不存在了(读者可以想想问什么)。但是对于constant stepsize,这种偏差一直存在,虽然随着时间在降低。事实上,这种偏差通常都不是什么问题,反而有时会有帮助。初始值的缺点在于这些参数需要认为设置,优点在于它可以告诉我们一些关于reward水平的先验知识。
初始值有时也可以被用于促进exploration。比如,我们把之前实验中的estimate value的初始值都设置为5,而不是0。由于real value来源于均值为0,方差为1的正态分布(实际选择时会有一定的噪声),那么相对于real value,estiamate value的初始值就偏大了。这样的话,执行机构就会发现第一个动作选项的reward小于estimate value,于是转而尝试第二个选项,很大概率上执行机构会发现几乎所有选项的reward都小于estimate value,结果就是无形中把这些选项都exploration了一遍,就算是greedy算法也是如此。
对比是否使用这种optimistic intial value,做了一组实验。结果如下:

明显可以看出,使用了optimistic intial value的方法,在一开始由于exploration过多,使得效果不太好,但是在后期远远好于初始值为0的算法。我们可以把这个初始化的技巧看成一个小trick,它在stationary的情形下很不错。但是这个技巧在nonstationary的情形下就不适用了。因为它对exploration的促进是暂时性的。事实上,任何集中在初始情形的方法都不可能在广义上的nonstationary情形下有效。因为任务一旦变化,所有的初始值都不可能始终适用。这也给了我们一个教训证明一开始的sample-average算法是不太合理的。因为它把所有时间线上的reward都给予了相同的权重。然而这并不是把这些方法一棍子打死了,因为它们之间的结合使用在实际情况中往往是合适的。
2.7 Associtive search
这一章主要是提前预热完整的多situation的强化学习问题。
到目前为止,我们讨论的都是单一situation下的任务,然而更常见的是多situation下的任务。学习的目标是一个policy,就是一张映射表,用来关联某个situation下的某个最优的action。现在我们就适当把当前的多臂赌博机的问题扩展到多situation情形下。
比如,我们现在有多个多臂赌博机问题,我们随机决定玩哪一个。这样的话,游戏场景就随机变化。假定当你被随机分配到一个任务时,会有一些另外的线索提供给你,比如想象一个可以随着其action value的改变而改变颜色的赌博机(不同任务下的机器有不同的但是固定的颜色),这时你就能把当前看到的颜色和当前任务的最好的action关联起来(映射),这样下次当你被随机分配到另一个任务时,看到赌博机的颜色,依据之前的映射,就可以选择一个最优的action。这比你在不知道任何区分不同任务的线索的情况下要好的多。
这个例子是单一situation的多臂赌博机问题和真正的强化学习问题之间的过渡。如果我们的每个action还能影响后续的situation的话,那就是真正的强化学习问题了。我们会在后续章节陆续描述。
2.8 结论
我们在这一章里提出了一些简单的方法,用于平衡强化学习过程中的exploitation和exploration。算法在每经过一段时间后随机选择一个action;softmax-greedy算法根据每个action的estimate value来评估其被选中的概率,进行概率分级,而不是像
那样概率均衡。我们怎么评价这些简单的方法呢?它们在实际的应用中是最好的方法吗?到目前为止来看,答案是:yes。尽管它们看起来很简单,但是它们的确可被认为是state-of-art的。的确是有一些更复杂的方法,然而受限于这些方法的复杂性和强假设前提,他们在实际应用中并没有太大优势。我们在第五篇会讨论一些部分基于本章思想的方法来解决实际的强化学习问题。之后的章节我们会讨论policy-based算法。
尽管我们现在能得到的方法距离真正能完美平衡exploration和exploitation的方法还很远,我们依然需要总结一下当前的思想,尽管不那么实用,但是对以后更好的方法会有启发性作用。
我们目前主要的思路是使用action value的estimate的uncertainty来控制exploration(这句话很绕)。为了更清楚的说明,举例如下:假设有两个action的estimate value均稍稍小于greedy action,但是它们的uncertainty差异较大。假设action 1不确定性较小,或许是因为这个动作的reward信息足够多以至于其estimate value接近确定,其真实value值出现大幅波动以至于超过其estimate value的可能性微乎其微。action 2的情况正相反。很明显,这种情况下explore action 1是更合理的。
顺着这个思路就引出了所谓“区间估计”的方法。这种方法对每个action的estimate value算出置信区间。置信区间的意思是相比于说这个action的value大约是10,区间估计的方法说这个action的estimate value在9和11之间的可能性是95%。最终被选中的action是有着最大的upper limit的那个,也就是区间上限最大的。在一些情况下,我们可以保证最优的action被选中的概率等于置信因子(95%)。然而,区间估计的方法在实际应用中受限于其统计方法的复杂性。另外,这种方法在统计学上的前提假设在实际案例中大多也不满足。
然而,类似区间估计这种,或者其他用于衡量估计值的不确定性的思路是值得研究的。
还有另外一种著名的算法叫做贝叶斯最优化方法。这种方法计算巨复杂,但是有一些很有效的办法去得到近似值。这个方法有个前提就是我们知道每一组可能的true action value的概率。这样的话,整个试验过程所包含的任何event chain的reward和possibility都可以知道,于是就可以选择最好的那个。但是这种可能性的增长速度是惊人的:就算只有两个action和两个reward,经过1000次动作选择,会产生种可能的event chain。
在多臂赌博机问题中的经典解法是计算一个Gittins indices方程。这个方法给出了某些更广义的多臂赌博机问题的最优解,但是也需要知道一些先验分布知识。不幸的是,无论从计算的可行性还是理论的易理解程度来说,这个方法都不适合推广到接下来我们讨论的广义强化学习问题。