消息中间件(RabbitMq、Kafka)分析比较
一、前言
最近在使用公司消息中间件的时候,对不同版本的选型:RabbitMq和Kafka,有点困惑,具体使用哪一种跟能满足自身业务需求,特查阅相关资料进行对比。
消息中间件指利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息排队模型,它可以在分布式环境下扩展进程间的通信。
目前开源的消息中间件可谓是琳琅满目,能让大家耳熟能详的就有很多,比如ActiveMQ、RabbitMQ、Kafka、RocketMQ、ZeroMQ等。不管是哪一款,都会存在与自身不匹配或者使用不趁手的地方,毕竟不是为自己量身定制的。不管是直接采用市场上,或者进行二次开发的,都会存在一个选项的过程。下来我们对目前主流的消息中间件(RabbitMq和Kafka)
进行一个对比分析。
二、中间件介绍
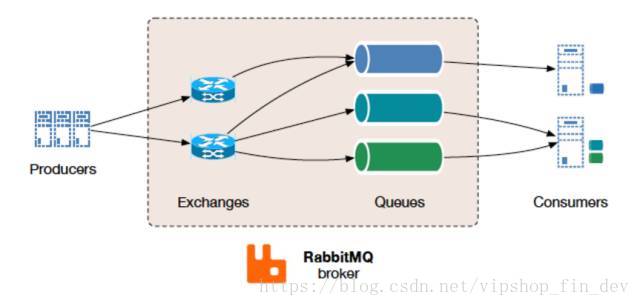
RabbitMQ:是采用Erlang语言实现的AMQP协议的消息中间件,最初起源于金融系统,用于在分布式系统中存储转发消息。可支持“点-点”、“请求-应答”和“发布-订阅”等多种通信模式。
通信可以按需设置为同步或异步。发布者将消息发送到交换区,消费者从队列中检索消息。利用交换区将生产者与队列解耦,可确保生产者没有硬编码路由决策的负担
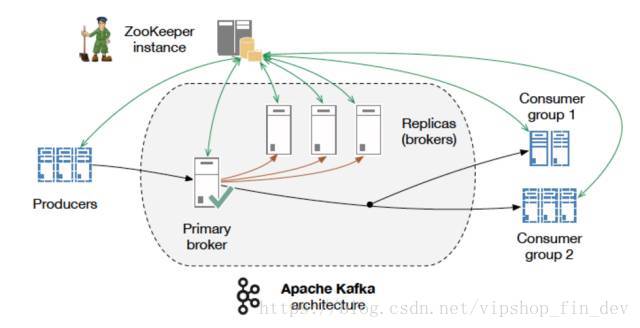
Kafka:起初是由LinkedIn公司采用Scala语言开发的一个分布式、多分区、多副本且基于zookeeper协调的分布式消息系统,现已捐献给Apache基金会。它是一种高吞吐量的分布式发布订阅消息系统,以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark、Flink等都支持与Kafka集成。擅长处理大量发布-订阅消息和数据流,具有持久、快速和可扩展的特点。
消息的发布描述为producer,消息的订阅描述为consumer,将中间的存储阵列称作broker(代理)。kafka对消息保存时根据Topic进行归类,发送消息者就是Producer,消息接受者就是Consumer,每个kafka实例称为broker。然后三者都通过Zookeeper进行协调。kafka存储是基于硬盘存储的,通过线性读写的方式实现快速地读写。
三、对比
1)、应用场景
RabbitMQ,遵循AMQP协议,由内在高并发的erlanng语言开发,用在实时的对可靠性要求比较高的消息传递上。
Kafka是Linkedin于2010年12月份开源的消息发布订阅系统,它主要用于处理活跃的流式数据,大数据量的数据处理上。
2)、架构设计
RabbitMQ遵循AMQP协议,RabbitMQ的broker由Exchange,Binding,queue组成,其中exchange和binding组成了消息的路由键;客户端Producer通过连接channel和server进行通信,Consumer从queue获取消息进行消费(长连接,queue有消息会推送到consumer端,consumer循环从输入流读取数据)。rabbitMQ以broker为中心;有消息的确认机制。
Kafka遵从一般的MQ结构,producer,broker,consumer,以consumer为中心,消息的消费信息保存的客户端consumer上,consumer根据消费的点,从broker上批量pull数据;无消息确认机制。
3)、吞吐量
Kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。
RabbitMQ在吞吐量方面稍逊于Kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
4)、可用性
RabbitMQ支持miror的queue,主queue失效,miror queue接管。
Kafka的broker支持主备模式。
5)、扩展性
Kafka采用zookeeper对集群中的broker、consumer进行管理,可以注册topic到zookeeper上;通过zookeeper的协调机制,producer保存对应topic的broker信息,可以随机或者轮询发送到broker上;并且producer可以基于语义指定分片,消息发送到broker的某分片上。
RabbitMQ的负载均衡需要单独的loadbalancer进行支持。
消息中间件市场上琳琅满目,这比如犹如小马过河,要贴合自身业务需求,选择合适的最重要,不管是选项什么技术组件,一定要问自己是否需要?引入能带来什么样的提升?技术服务于业务,不能盲目的只为了引入而限制了业务的开展。
四、Kafka集群搭建
1)、前期准备
scala-2.12.6.tgz
zookeeper-3.4.13.tar.gz
kafka_2.12-2.0.0.tgz
jdk版本可以1.8,对应前期需要的软件,可以直接去官网下载。Scala官网下载会超时,可参考一下链接,修改对应版本号即可。
http://downloads.typesafe.com/scala/2.12.6/scala-2.12.6.tgz
Scala和Zk已提前安装,具体方法可以参考网上资料。
ZK如下:
192.168.xxx.1:2181
192.168.xxx.2:2181
192.168.xxx.3:2181
2)、Kafka集群搭建
针对master主机服务器(192.168.xxx.1),其他主机服务器类似
2.1)、上传kafka包到指定目录/opt/software_lw,并解压并拷贝至/usr/local/kafka;
tar -zxvf kafka_2.10-0.10.1.0.tgz
mv kafka_2.12-2.0.0 /usr/local/kafka
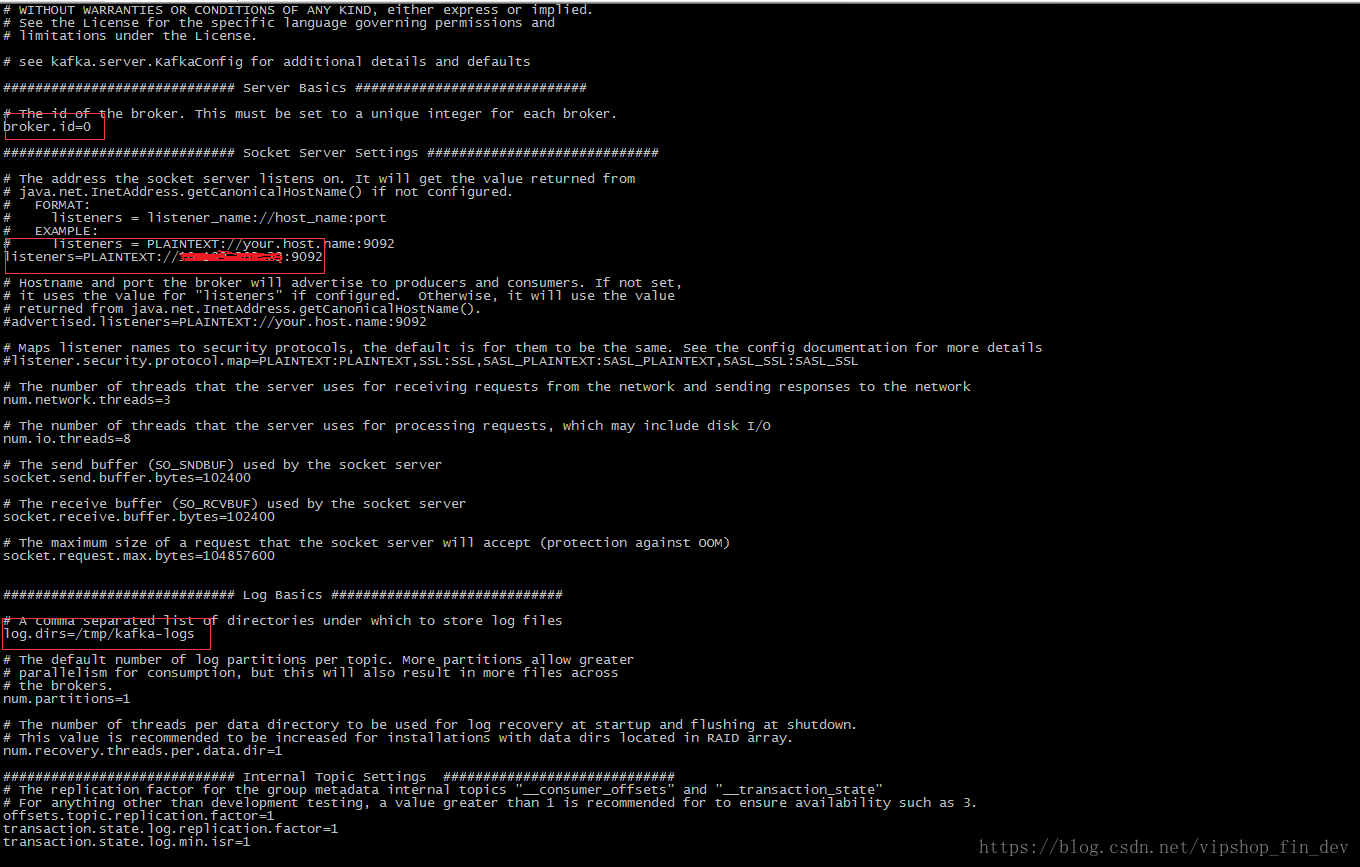
2.2)、修改集群配置文件config/server.properties;
broker.id=0 #主键ID,必须保持唯一
listeners=PLAINTEXT://192.168.xxx.1:9092 #本机IP
log.dirs=/tmp/kafka-logs #日志目录
zookeeper.connect=192.168.xxx.1:2181,192.168.xxx.2:2181,192.168.xxx.3:2181 #zk集群地址

2.3)、其他服务器搭建;
拷贝master服务器的kafka至slave01和slave02的 /usr/local/目录,scp -r kafka_2.12-2.0.0 [email protected]:/usr/local/kafka/,另一台服务器(192.168.xxx.3)
类似master服务器,修改对应config/server.properties文件
3)、Kafka集群测试
3.1)、zookeeper集群启动
3.2)、kafka集群启动
三台机分别执行开启命令:bin/kafka-server-start.sh -daemon config/server.properties
jps查看进程
3.3)、创建主题和查看主题
创建(replication-factor一定要大于1,否则kafka只有一份数据,leader一旦崩溃程序就没有输入源了,分区数目视输入源而定)
bin/kafka-topics.sh --create --zookeeper 192.168.xxx.1:2181,192.168.xxx.2:2181,192.168.xxx.3:2181 --replication-factor 3 --partitions 3 --topic topic_LwTest
查看
bin/kafka-topics.sh --list --zookeeper 192.168.xxx.1:2181,192.168.xxx.2:2181,192.168.xxx.3:2181
3.4)、开启生产者和消费者
master服务器输入信息,slave01或slave02会显示master输的的信息
生产者(master)
bin/kafka-console-producer.sh --broker-list 192.168.xxx.1:9092,192.168.xxx.2:9092,192.168.xxx.3:9092 --topic topic_LwTest
消费者(slave01或slave02服务器)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.xxx.1:9092,192.168.xxx.2:9092,192.168.xxx.3:9092 --topic topic_LwTest --from-beginning
注意:高版本已经废弃原bin/kafka-console-consumer.sh --zookeeper 消费方式