flink实战案例一:flink集群的搭建与部署
1.下载Flink压缩包
下载地址:http://flink.apache.org/downloads.html
根据集群环境的情况下载相应的版本的flink压缩包
hadoop2.6,Scala2.11,所以下载:flink-1.5.0-bin-hadoop26-scala_2.11.tgz
解压
tar -zxf flink-1.5.0-bin-hadoop26-scala_2.11.tgz
配置
这里面需要我们配置的有:slaves和flink-conf.yaml文件,这里面masters文件是用来配置HA的,只要我们不配置HA的话,就不需要配置masters文件(flink也是master/slave结构,但是对于此时master的选择是执行启动脚本的机器为master)。但是slave需要我们配置,配置对应的主机名即可(伪分布式和分布式的区别也就是实际上slave节点的个数,以及分布式在多个节点上而已)。接下来需要我们配置的就是flink-conf.yaml,flink和spark还是有区别的,spark配置文件分spark-env.sh和spark-default.conf文件,而flink的配置都在flink-conf.yaml中完成配置。
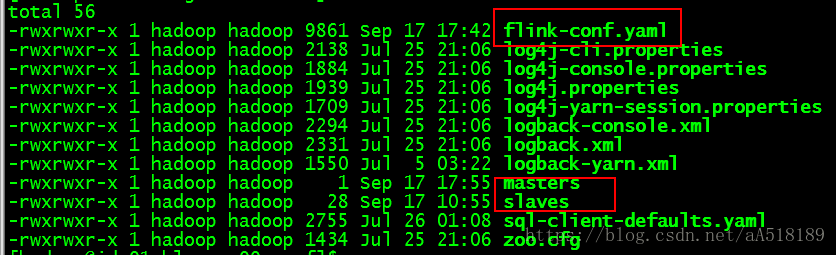
flink-conf.yaml主要配置
jobmanager.rpc.address: node #配置JobManager进行RPC通信的地址,使用默认即可
jobmanager.rpc.port: 6123 #配置JobManager进行RPC通信的端口,使用默认即可
taskmanager.numberOfTaskSlots: 2 #配置每一个slave节点上task的数目
taskmanager.memory.preallocate: false #配置是否在Flink集群启动时候给TaskManager分配内存,默认不进行预分配,这样在我们不适用flink集群时候不会占用集群资源
parallelism.default: 2 # 用于未指定的程序的并行性和其他并行性,默认并行度
jobmanager.web.port: 5566 #指定JobManger的可视化端口,尽量配置一个不容易冲突的端口
state.backend.fs.checkpointdir: hdfs://node:9000/flink-checkpoints #配置checkpoint目录
fs.hdfs.hadoopconf: /home/daxin/bigdata/hadoop/etc/hadoop/ #配置hadoop的配置文件
fs.hdfs.hdfssite: /home/daxin/bigdata/hadoop/etc/hadoop/hdfs-site.xml #访问hdfs系统使用的
**
fs.default-scheme: hdfs://node:9000/
#设置默认文件系统,笔者在开始搭建集群时候由于没设置此项导致读“/word/hadoop.txt”无法访问hdfs文件系统,默认值是本地文件系统
**
注意:flink-conf.yaml中配置key/value时候在“:”后面需要有一个空格,否则配置不会生效。
Flink集群的启停
.启动flink集群
[root@hadoop2 flink-1.5.0]# bin/start-cluster.sh
停止flink集群
[root@hadoop2 flink-1.5.0]# bin/stop-cluster.sh
然后jps查看一下进程:
5401 TaskManager
5085 JobManager
看见这两个进程就代表启动成功了