数组序列(Array-Based Sequences)
1. 二维数组转置
grid = [['.', '.', '.', '.', '.', '.'],
['.', 'O', 'O', '.', '.', '.'],
['O', 'O', 'O', 'O', '.', '.'],
['O', 'O', 'O', 'O', 'O', '.'],
['.', 'O', 'O', 'O', 'O', 'O'],
['O', 'O', 'O', 'O', 'O', '.'],
['O', 'O', 'O', 'O', '.', '.'],
['.', 'O', 'O', '.', '.', '.'],
['.', '.', '.', '.', '.', '.']]
#转置四种种方法
grid_T =map(list,zip(*grid))
#grid_T = list(zip(*grid))
#grid_T = list(list(i) for i in zip(*grid))
#grid_T = [[row[i] for row in grid] for i in range(len(grid[0]))]
for line in grid_T:
dots = ''
for dot in line:
dots += dot
print(dots,end='\n')2.有序二维数组查找
题目描述:在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数
class Solution:
def Find_lower_left(self,target,array):
""" 从左下向右上检测 """
cols = len(array[0])-1
rows = len(array)-1
i = rows
j=0
while j<=cols and i>=0:
if target>array[i][j]:
j +=1
elif target<array[i][j]:
i -=1
else:
return True
return False
def Find_upper_right(self,target,array):
""" 从右上向左下检测 """
rows = len(array)-1
cols = len(array[0])-1
i = 0
j = cols
while i<=rows and j >=0:
if target>array[i][j]:
i +=1
elif target< array[i][j]:
j -=1
else:
return True
return False
if __name__=="__main__":
solution = Solution()
target = 11
array = [[1,3,5],[7,9,11],[13,15,17]]
print(solution.Find_lower_left(target,array))
print(solution.Find_upper_right(target,array))链表(Linked Lists)
1.单项列表实现反向打印
#-*- coding:utf-8 -*-
class ListNode:
def __init__(self, x):
self.val = x
self.next = None
class Solution:
"""
反向打印链表
"""
def printListFromTailToHead(self, listNode):
# write code here
pre_header = listNode
result = []
while pre_header != None:
#result.append(pre_header.val)
# return result[::-1] or result.reverse()
result.insert(0,pre_header.val)
pre_header = pre_header.next
return result
def printListFromTailToHead_1(self, listNode):
# 递归的方法
if listNode is not None:
return list(self.printListFromTailToHead_1(listNode.next))+ list([listNode.val])
else:
return []
if __name__ == "__main__":
solution = Solution()
Node_1 = ListNode(1)
Node_2 = ListNode(2)
Node_3 = ListNode(3)
Node_1.next = Node_2
Node_2.next = Node_3
print(solution.printListFromTailToHead(Node_1))2.双向列表
class _DoubleLinkedBase:
'''A base class providing a doubly linked list representation.'''
class _Node:
__slots__ = '_element','_prev','_next'
def __init__(self,element,prev,next_):
self._element = element
self._prev = prev
self._next = next_
def __init__(self):
# 这里header和trailer只是一个前后标识,并没有实际存储作用
self._header = self._Node(None,None,None)
self._trailer = self._Node(None,None,None)
self._header._next = self._trailer
self._trailer._prev = self._header
self._size = 0
def __len__(self):
return self._size
def is_empty(self):
return self._size == 0
def _insert_between(self,e,predecessor,successor):
newest = self._Node(e,predecessor,successor)
predecessor._next = newest
successor._prev = newest
self._size += 1
return newest
def _delete_node(self,node):
predecessor = node._prev
successor = node._next
predecessor._next = successor
successor._prev = predecessor
self._size -= 1
element = node._element
node._prev = node._next = node._element = None
return element3.循环列表

class CircularQueue:
'''使用循环链表实现队列的存储。'''
class _Node:
__slots__ = '_element','_next'
def __init__(self,element,next_):
self._element = element
self._next = next_
def __init__(self):
self._tail = None
self._size = 0
def __len__(self):
return self._size
def is_empty(self):
return self._size == 0
def first(self):
if self.is_empty():
raise IndexError
head = self._tail._next
return head._element
def dequeue(self):
if self.is_empty():
raise IndexError
oldhead = self._tail._next
if self._size==1:
self._tail = None
else:
self._tail._next = oldhead._next
self._size -= 1
return oldhead._element
def enqueue(self,e):
newest = self._Node(e,None)
if self.is_empty():
newest._next = newest
else:
newest._next = self._tail._next
self._tail._next = newest
self._tail = newest
self._size +=1
def rotat(self):
'''将前部元素旋转到队列的后面'''
if self._size > 0:
self._tail = self._tail._next4.位置列表
我们定义了一个 PositionalList ADT以及一个更简单的 class Position 抽象数据类型来描述列表中的位置。位置实例是一个简单对象,只支持以下方法:p.element() 返回存储在位置p的元素
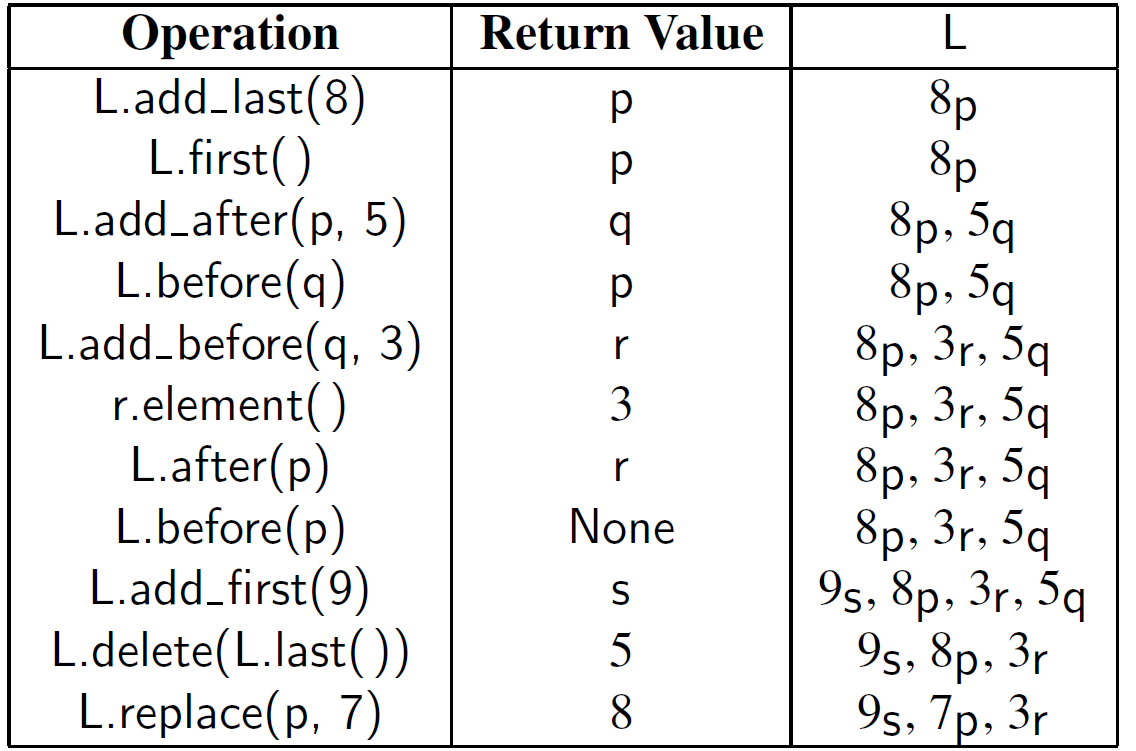
class PositionalList(_DoubleLinkedBase):
'''元素的顺序链表容器允许位置访问'''
class Position:
'''表示单个元素位置的抽象'''
def __init__(self,container,node):
self._container = container
self._node = node
def element(self):
return self._node._element
def __eq__(self, other):
return type(other) is type(self) and other._node is self._node
def __ne__(self, other):
return not(self == other) # opposite of __eq__
def _validate(self, p):
if not isinstance(p, self.Position):
raise TypeError(' p must be proper Position type')
if p._container is not self:
raise ValueError('p does not belong to this container')
if p._node._next is None:
raise ValueError(' p is no longer valid')
return p._node
def _make_position(self, node):
'''添加position属性'''
if node is self._header or node is self._trailer:
return None
else:
return self.Position(self, node)
def first(self):
return self._make_position(self._header._next)
def last(self):
return self._make_position(self._trailer._prev)
def before(self, p):
node = self._validate(p)
return self._make_position(node._prev)
def after(self, p):
node = self._validate(p)
return self._make_position(node._next)
def __iter__(self):
cursor = self.first()
while cursor is not None:
yield cursor.element()
cursor = self.after(cursor)
def _insert_between(self,e,predecessor,successor):
node = super()._insert_between(e,predecessor,successor)
return self._make_position(node)
def add_first(self, e):
return self._insert_between(e, self._header,self._header._next)
def add_last(self, e):
return self._insert_between(e, self._trailer._prev,self._trailer)
def add_before(self, p ,e):
original = self._validate(p)
return self._insert_between(e, original._prev, original)
def add_after(self, p, e):
original = self._validate(p)
return self._insert_between(e, original, original._next)
def delete(self, p):
original = self._validate(p)
return self._delete_node(original)
def replace(self, p, e):
original = self._validate(p)
old_value = original._element
original._element = e
return old_value
栈(Stacks)
1.利用列表实现栈
class ArrayStack:
'''LIFO Stack implementation using a Python list as underlying storage.'''
def __init__(self):
self.data = []
def __len__(self):
return len(self.data)
def is_empty(self):
return len(self.data) == 0
def push(self, e):
self.data.append(e)
def top(self):
if self.is_empty():
raise Exception('Stack is empty')
return self.data[-1]
def pop(self):
if self.is_empty():
raise Exception('Stack is empty')
return self.data.pop()2.利用链表实现栈
class LinkedStack:
class _Node:
__slots__ = '_element','_next' # __slots__变量限制该class能添加的属性
def __init__(self,element,next):
self._element = element
self._next = next
def __init__(self):
self._head = None # 链表的第一个node
self._size = 0
def __len__(self):
return self._size
def is_empty(self):
return self._size == 0
def push(self, e):
self._head = self._Node(e,self._head)
self._size += 1
def top(self):
if self.is_empty():
raise IndexError('Stack is empty')
return self._head._element
def pop(self):
if self.is_empty():
raise IndexError('Stack is empty')
answer = self._head._element
self._head = self._head._next
self._size -= 1
return answer
Link-Based vs. Array-Based Sequences
数组:
- 数组提供基于整数索引的元素的O(1)时间访问。相反,定位第k个元素在链表中需要O(k)时间从开始遍历列表,或者可能是O(n-k)时间,如果从双端向后遍历链表。
- 基于数组的表示通常使用比链接结构更少的内存,但有时会出现存储空间大于存储元素情况,造成内存浪费。
- 插入和删除操作非常昂贵(后继内存会相应移动)
链表优势:
- 基于链表的结构支持O(1)时间插入和删除在任意位置。而基于数组的列表类,在索引k处插入或弹出使用O(n-k+1)时间,因为所有后续元素会被循环移位
- 利用分散内存存储元素,没有浪费内存,插入和删除操作方便
3.字符串公式计算
def Evaluate(expr):
ops = LinkedStack()
vals = LinkedStack()
for i in expr:
if i == '(':
pass
elif i == '+':
ops.push(i)
elif i == '-':
ops.push(i)
elif i == '*':
ops.push(i)
elif i == '/':
ops.push(i)
elif i == '//':
ops.push(i)
elif i == ')': # 如果字符为),弹出运算符合操作数,计算结果并压入栈
op = ops.pop()
v = vals.pop()
if op == '+':
v = vals.pop() + v
if op == '-':
v = vals.pop() - v
if op == '*':
v = vals.pop() * v
if op == '/':
v = vals.pop() / v
if op == '//':
v = vals.pop()//v
vals.push(v)
else:
vals.push(int(i))
return vals.pop()
if __name__ == '__main__':
print( Evaluate('(1+(2*2))'))4.判断字符串数学公式是否合法
def match_math(expr):
'''Return True if all delimiters are properly match; False otherwise.'''
lefty = '({['
righty = ')}]'
S = LinkedStack()
for c in expr:
if c in lefty:
S.push(c)
elif c in righty:
if S.is_empty():
return False
if righty.index(c) != lefty.index(S.pop()):
return False
return S.is_empty()
if __name__ == '__main__':
print( match_math('(1+(2*2))'))5.文件内容顺序倒置
def reverse_file(file_name):
'''Overwrite given file with its contents line-by-line reversed.'''
S = LinkedStack()
original = open(file_name)
for line in original:
S.push(line.rstrip('\n'))
original.close()
output = open(file_name,'w')
while not S.is_empty():
output.write(S.pop() + '\n')
output.close()
if __name__ == '__main__':
reverse_file('tst.txt')队列(Queues)
1.python内部集成队列
import queue #单向
from collections import deque #双向2.数组实现队列
class ArrayQueue:
DEFAULT_CAPACITY = 10 #固定大小,循环使用
def __init__(self):
self._data = [None]*ArrayQueue.DEFAULT_CAPACITY #是一个具有固定容量的列表实例的引用。
self._size = 0 #表示存储在队列中的元素的当前数量
self._front = 0 #队列第一个元素在数据中的索引
def __len__(self):
return self._size
def is_empty(self):
return self._size == 0
def first(self):
'''Return (but do not remove) the element at the front of the queue'''
if self.is_empty():
raise IndexError('Queue is empty')
return self._data[self._front]
def dequeue(self):
'''Remove and return the first element of the queue'''
if self.is_empty():
raise IndexError('Queue is empty')
answer = self._data[self._front]
self._data[self._front] = None
self._front = (self._front +1)%len(self._data)
self._size -= 1
return answer
def enqueue(self, e):
if self._size == len(self._data):
self._resize(2 * len(self._data))
avail = (self._front + self._size)%len(self._data) #在_data范围内循环使用
self._data[avail] = e
self._size += 1
def _resize(self,cap):
old = self._data
self._data = [None] * cap
walk = self._front
for k in range(self._size):
self._data[k] = old[walk]
walk = (1+walk) % len(old)
self._front = 0
3.链表实现队列
class LinkedQueue:
class _Node:
__slots__ = '_element','_next'
def __init__(self, element, next):
self._element = element
self._next = next
def __init__(self):
self._head = None
self._tail = None
self._size = 0
def __len__(self):
return self._size
def is_empty(self):
return self._size == 0
def first(self):
if self.is_empty():
raise IndexError('Queue is empty')
return self._head._element
def dequeue(self):
if self.is_empty():
raise IndexError('Queue is empty')
answer = self._head._element
self._head = self._head._next
self._size -= 1
if self.is_empty():
self._tail = None
return answer
def enqueue(self, e):
newest = self._Node(e,None)
if self.is_empty():
self._head = newest
else:
self._tail._next = newest
self._tail = newest
self._size += 1
树(Trees)
将链表插入的灵活性和有序数组查找的高效性结合的数据结构:
| p.element( ):返回在节点p点存储的元素 |
| T.root():返回根节点T,or None if T is empty. |
| T.is root(p): 如果是根节点则返回为真. |
| T.parent(p): 返回节点p的父节点,or None if p is the root of T. |
| T.num children(p): 返回节点p的子节点数量 |
| T.children(p): 生成节点p的子结点迭代器. |
| T.is leaf(p): 判断是否为叶节点. |
| len(T): 计算T中存储的元素个数 |
| T.is empty( ): 判断T是否为空. |
| T.positions( ):产生遍历树中所有节点的迭代器(前向,后向,中序,宽度优先) |
| iter(T): 产生遍历树中所有存储在T中元素的迭代器 |
这里实现上述基本方法的预定义类Tree
class Tree:
'''Abstract base class representing a tree structure.'''
class Position:
def element(self):
raise NotImplementedError(' must be implemented by subclass') #必须由子类实现
def __eq__(self, other):
raise NotImplementedError(' must be implemented by subclass')
def __ne__(self, other):
return not (self == other)
def root(self):
raise NotImplementedError(' must be implemented by subclass')
def parent(self, p):
raise NotImplementedError(' must be implemented by subclass')
def num_children(self, p):
raise NotImplementedError(' must be implemented by subclass')
def children(self, p):
raise NotImplementedError(' must be implemented by subclass')
def __len__(self):
raise NotImplementedError(' must be implemented by subclass')
def __iter__(self):
for p in self.positions():
yield p.element()
def is_root(self, p):
return self.root() == p
def is_leaf(self, p):
return self.num_children(p) == 0
def is_empty(self):
return len(self) == 0
def positions(self):
#return self.preorder()
#return self.inorder()
#return self.postorder()
#return self.breadthfirst()
1. 计算树的深度和高度
def depth(self, p):
"""自上而下计算深度"""
if self.is_root(p):
return 0
else:
return 1+self.depth(self.parent(p))
#######################################################################
def _height1(self): # works, but O(n^2) worst-case time
"""Return the height of the tree."""
return max(self.depth(p) for p in self.positions() if self.is_leaf(p))
def _height2(self, p): # time is linear in size of subtree
"""Return the height of the subtree rooted at Position p."""
if self.is_leaf(p):
return 0
else:
return 1 + max(self._height2(c) for c in self.children(p))
def height(self, p):
if p is None:
p = self.root()
return self._height2(p)2.前序遍历
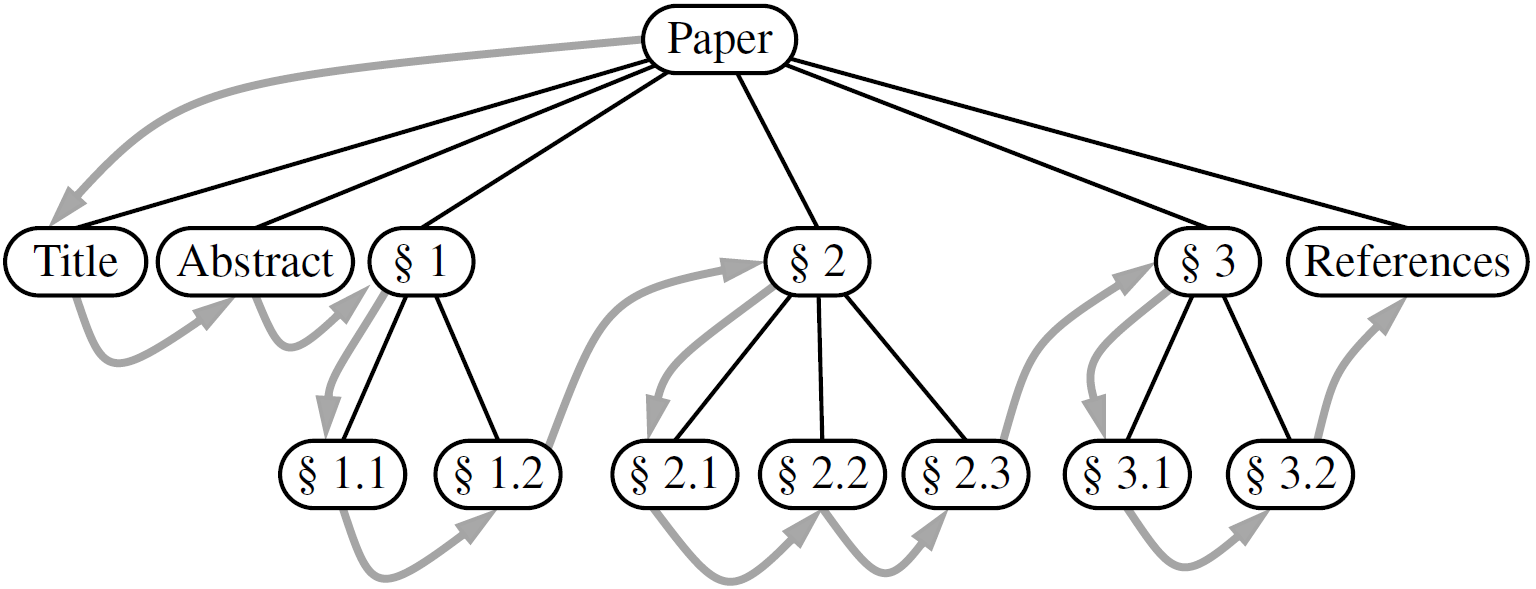
输入:树结构T,遍历以p为根的子树
Algorithm preorder(T, p): perform the “visit” action for position p for each child c in T.children(p) do preorder(T, c) #递归遍历以C为根的子树 ############################################################### def preorder(self): if not self.is_empty(): for p in self._subtree_preorder(self.root()): yield p def _subtree_preorder(self, p): """迭代器""" yield p #先对p进行访问 for c in self.children(p): for other in self._subtree_preorder(c): yield other
3.中序遍历

输入:遍历以p为根的子树
Algorithm inorder(p): if p has a left child lc then inorder(lc) #递归遍历P的左子树 perform the “visit” action for position p if p has a right child rc then inorder(rc) #递归遍历P的右子树 ############################################################# def inorder(self): if not self.is_empty(): for p in self._subtree_inorder(self.root()): yield p def _subtree_inorder(self, p): if self.left(p) is not None: for other in self._subtree_inorder(self.left(p)): yield other yield p if self.right(p) is not None: for other in self._subtree_inorder(self.right(p)): yield other
4.后序遍历
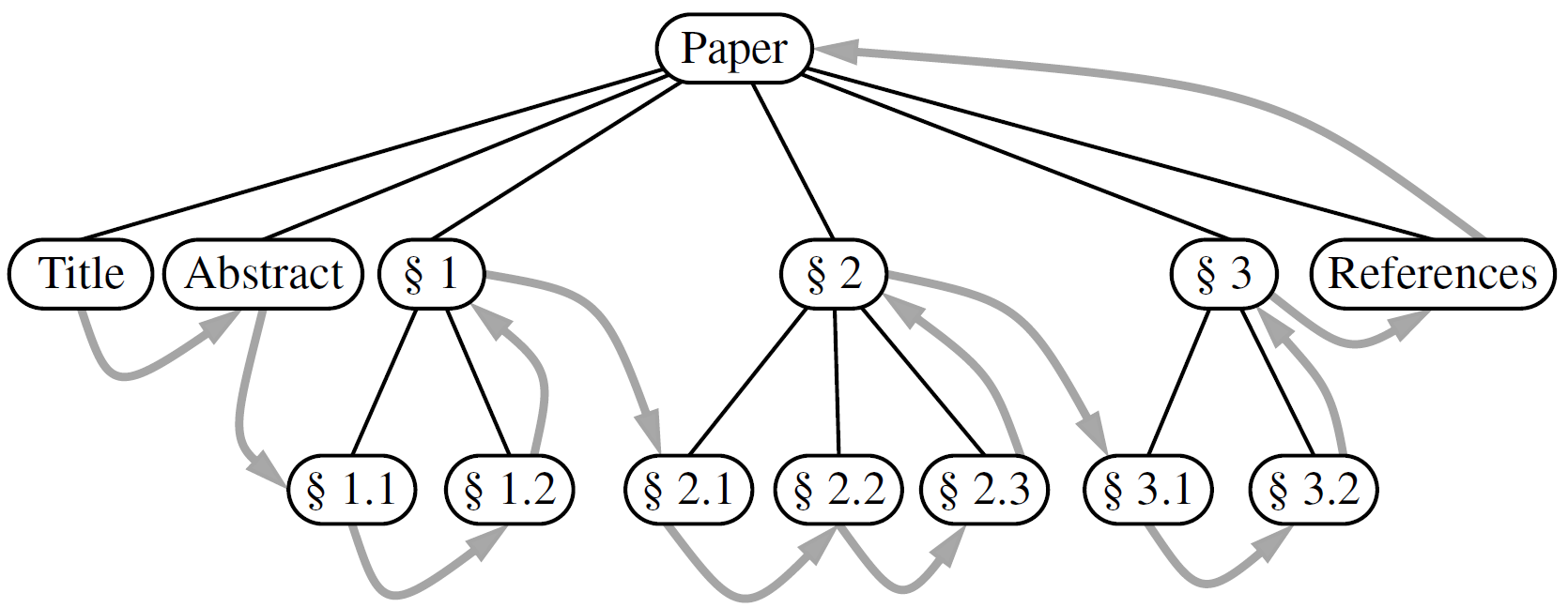
输入:树结构T,遍历以p为根的子树
Algorithm postorder(T, p): for each child c in T.children(p) do postorder(T, c) #递归遍历以C为根的子树 perform the “visit” action for position p ######################################################### def postorder(self): """Generate a postorder iteration of positions in the tree.""" if not self.is_empty(): for p in self._subtree_postorder(self.root()): # start recursion yield p def _subtree_postorder(self, p): """Generate a postorder iteration of positions in subtree rooted at p.""" for c in self.children(p): # for each child c for other in self._subtree_postorder(c): # do postorder of c's subtree yield other # yielding each to our caller yield p # visit p after its subtrees
5.广度优先遍历
广度优先遍历是用于游戏中常用的方法
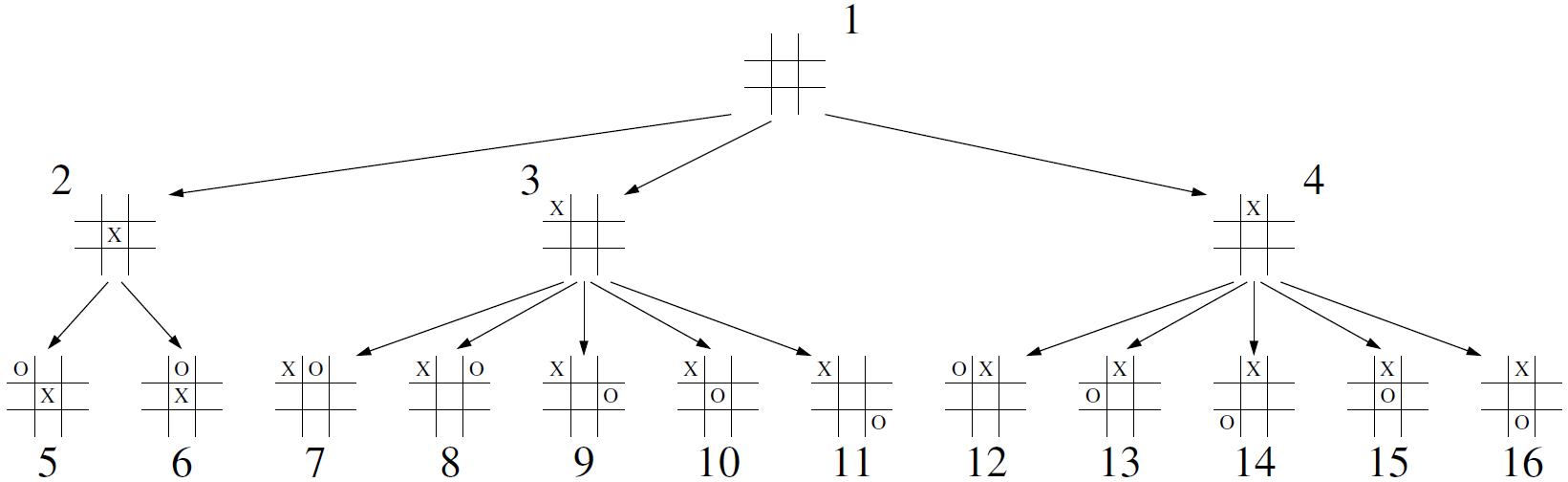
输入:树结构T
Algorithm breadthfirst(T): Initialize queue Q to contain T.root( ) while Q not empty do p = Q.dequeue( ) #P是队列中最古老的条目 perform the “visit” action for position p for each child c in T.children(p) do Q.enqueue(c) #将P的孩子添加到队列的末尾以供稍后访问 ############################################################################ def breadthfirst(self): if not self.is_empty(): fringe = LinkedQueue() fringe.enqueue(self.root()) while not fringe.is_empty(): p = fringe.dequeue() yield p for c in self.children(p): fringe.enqueue(c)
二叉树(Binary Trees)
令T为非空二叉树,n为节点数,为外部节点(叶节点),
为内部节点,h为高度:
对于一棵满二叉树,外部节点或者说是叶子节点数是n,则内部节点数是n-1。
| T.left(p): 返回左节点,or None if p has no left child. |
| T.right(p): 返回右节点,or None if p has no right child. |
| T.sibling(p): 返回同级的兄弟节点,or None if p has no sibling. |
class BinaryTree(Tree):
'''Abstract base class representing a binary tree structure.'''
def left(self, p):
raise NotImplementedError(' must be implemented by subclass')
def right(self, p):
raise NotImplementedError(' must be implemented by subclass')
def sibling(self, p):
'''返回兄弟结点位置'''
parent = self.parent(p)
if parent is None:
return None
else:
if p == self.left(parent):
return self.right(parent)
else:
return self.left(parent)
def children(self, p):
if self.left(p) is not None:
yield self.left(p)
if self.right(p) is not None:
yield self.right(p)
1.根据前向和中序遍历得到树结构
class TreeNode:
def __init__(self,x):
self.val = x
self.right = None
self.left = None
class Solution:
def reConstructBinaryTree(self, pre, tin):
"""
:param pre: 前向遍历
:param tin: 中序遍历
:return: 树结构
"""
if not pre or not tin:
return None
root = TreeNode(pre.pop(0))
index = tin.index(root.val)
# 递归
root.left = self.reConstructBinaryTree(pre,tin[:index])
root.right = self.reConstructBinaryTree(pre,tin[index+1:])
return root
if __name__=="__main__":
solution = Solution()
pre = [1,2,4,7,3,5,6,8]
tin = [4,7,2,1,5,3,8,6]
tree = solution.reConstructBinaryTree(pre,tin)
print(tree)
利用链表结构实现二叉树
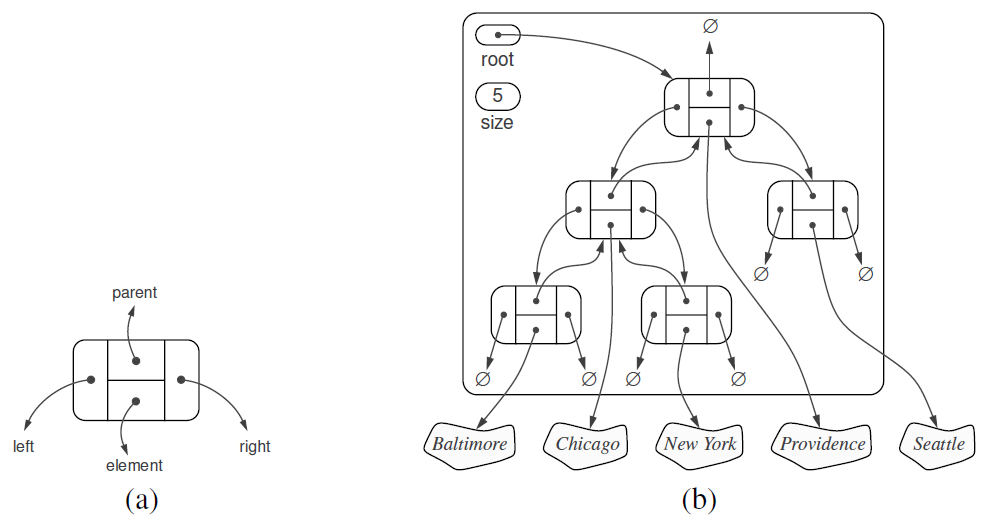
此处将上述两节中未实现函数实现,并添加如下函数
| T.add root(e): 为空树T创建根节点, 并存储元素e,返回根节点; an error occurs if thetree is not empty. |
| T.add left(p, e): 创建新节点存储e, 作为左子结点连接到 p节点, and return the resulting position;an error occurs if p already has a left child. |
| T.add right(p, e): 创建新节点存储e, 作为右子结点连接到 p节点, and return the resulting position;an error occurs if p already has a right child. |
| T.replace(p, e):用元素e替换p节点所存储元素,and return the previously stored element |
| T.delete(p): 移除节点p,用子结点替换,并返回节点p所存储元素,an error occurs if p has two children. |
| T.attach(p, T1, T2): 将树T1、树T2分别作为左子树和右子树,合并到p节点。an error condition occurs if p is not a leaf. |
class LinkedBinaryTree(BinaryTree):
class _Node:
__slots__ = '_element','_parent','_left','_right'
def __init__(self,element,parent=None,left=None,right=None):
self._element = element
self._parent = parent
self._left = left
self._right = right
class Position(BinaryTree.Position):
def __init__(self, container, node):
self._container = container
self._node = node
def element(self):
return self._node._element
def __eq__(self, other):
return type(other) is type(self) and other._node is self._node
def _validate(self, p):
if not isinstance(p , self.Position):
raise TypeError
if p._container is not self:
raise ValueError
if p._node._parent is p._node:
raise ValueError
return p._node
def _make_position(self, node):
return self.Position(self, node) if node is not None else None
def __init__(self):
self._root = None
self._size = 0
def __len__(self):
return self._size
def root(self):
return self._make_position(self._root)
def parent(self, p):
node = self._validate(p)
return self._make_position(node._parent)
def left(self, p):
node = self._validate(p)
return self._make_position(node._left)
def right(self, p):
node = self._validate(p)
return self._make_position(node._right)
def num_children(self, p):
node = self._validate(p)
count = 0
if node._left is not None:
count += 1
if node._right is not None:
count += 1
return count
def _add_root(self, e):
if self._root is not None:
raise ValueError
self._size = 1
self._root = self._Node(e)
return self._make_position(self._root)
def _add_left(self, p, e):
node = self._validate(p)
if node._left is not None:
raise ValueError
self._size += 1
node._left = self._Node(e,node)
return self._make_position(node._left)
def _add_right(self, p, e):
node = self._validate(p)
if node._right is not None:
raise ValueError
self._size += 1
node._right = self._Node(e,node)
return self._make_position(node._right)
def _replace(self, p, e):
node = self._validate(p)
old = node._element
node._element = e
return old
def _delete(self, p):
node = self._validate(p)
if self.num_children(p) == 2:
raise ValueError
child = node._left if node._left else node._right
if child is not None:
child._parent = node._parent
if node is self._root:
self._root = child
else:
parent = node._parent
if node is parent._left:
parent._left = child
else:
parent._right = child
self._size -= 1
node._parent = node
return node._element
def _attach(self, p, t1, t2):
node = self._validate(p)
if not self.is_leaf(p):
raise ValueError('position must be leaf')
if not type(self) is type(t1) is type(t2): # all 3 trees must be same type
raise TypeError('Tree types must match')
self._size += len(t1) + len(t2)
if not t1.is_empty(): # attached t1 as left subtree of node
t1._root._parent = node
node._left = t1._root
t1._root = None # set t1 instance to empty
t1._size = 0
if not t2.is_empty(): # attached t2 as right subtree of node
t2._root._parent = node
node._right = t2._root
t2._root = None # set t2 instance to empty
t2._size = 0
基于链表结构的二叉树的性能

优先队列(Priority Queue)
总是处理下一个优先级最高的事件,一个合适的数据结构应该支持两种操作:删除优先级最高元素和插入元素。
优先队列和队列(删除最老的元素)以及栈(删除最新元素)类似
| P.add(k, v) | 插入键值对(k,v) |
| P.min() | 返回优先队列中键值最小的键值对; 如果为队列空报错 |
| P.remove_min() | 删除并返回优先队列中键值最小的键值对; 如果为队列空报错 |
| P.is_empty( ): | 是否为空 |
| len(P): | 返回键值对的个数 |
class PriorityQueueBase:
class _Item:
__slots__ = '_key', '_value'
def __init__(self, k, v):
self._key = k
self._value = v
def __lt__(self, other): # self < other
return self._key < other._key
def is_empty(self):
return len(self) == 0
1. 利用数组实现(无序)

class UnsortedPriorityQueue(PriorityQueueBase):
def _find_min(self): # 选择排序
if self.is_empty():
raise IndexError
small = self._data.first()
walk = self._data.after(small)
while walk is not None:
if walk.element() < small.element():
small = walk
walk = self._data.after(walk)
return small
def __init__(self):
self._data = PositionalList()
def __len__(self):
return len(self._data)
def add(self, key, value):
self._data.add_first(self._Item(key , value))
def min(self):
p = self._find_min()
item = p.element()
return (item._key, item._value)
def remove_min(self):
p = self._find_min()
item = self._data.delete(p)
return (item._key, item._value)
2. 利用数组实现(有序)

class SortedPriorityQueue(PriorityQueueBase):
def __init__(self):
self._data = PositionalList()
def __len__(self):
return len(self._data)
def add(self, key, value):
newest = self._Item(key, value)
walk = self._data.last()
while walk is not None and newest < walk.element(): # 插入排序
walk = self._data.before(walk)
if walk is None:
self._data.add_first(newest)
else:
self._data.add_after(walk,newest)
def min(self):
"""Return but do not remove (k,v) tuple with minimum key.
Raise Empty exception if empty.
"""
if self.is_empty():
raise IndexError('Priority queue is empty.')
p = self._data.first()
item = p.element()
return (item._key, item._value)
def remove_min(self):
"""Remove and return (k,v) tuple with minimum key.
Raise Empty exception if empty.
"""
if self.is_empty():
raise IndexError('Priority queue is empty.')
item = self._data.delete(self._data.first())
return (item._key, item._value)
堆结构(Heap)
数据结构二叉堆能够更好的实现优先队列的基本操作。是一组能够用堆有序的完全二叉树排序的元素,并在数组中按照层级存储(不使用数组的第一个位置)
堆有序:当一颗二叉树的每个节点都大于等于它的两个子节点时。且根节点是二叉堆的最大节点

- 在堆中,位置k的父节点的位置为
,两个子节点的位置分别为2k和2k+1。
- 可以通过计算数组的索引在树中移动:从a[k]向上一层就令k等于k/2,向下一层则令k等于2k和2k+1.
- 一颗大小为N的完全二叉树的高度为
插入元素后上浮(Up-Heap Bubbling)
- 当某个节点的优先级上升
- 如在堆底加入一个新的元素时
我们需要由下至上恢复堆的顺序,让新元素上浮到合适位置。

删除最大元素后下沉(Down-Heap Bubbling)
- 当某个节点的优先级下降
- 如将根节点替换为一个较小元素
我们需要由上至下恢复堆的顺序,让新元素下沉到合适位置。

class HeapPriorityQueue(PriorityQueueBase): # base class defines _Item
""""""
#------------------------------ nonpublic behaviors ------------------------------
def _parent(self, j):
return (j-1) // 2
def _left(self, j): #数组存储从index=0开始
return 2*j + 1
def _right(self, j):
return 2*j + 2
def _has_left(self, j):
return self._left(j) < len(self._data) # index beyond end of list?
def _has_right(self, j):
return self._right(j) < len(self._data) # index beyond end of list?
def _swap(self, i, j):
"""Swap the elements at indices i and j of array."""
self._data[i], self._data[j] = self._data[j], self._data[i]
def _upheap(self, j):
parent = self._parent(j)
if j > 0 and self._data[j] < self._data[parent]:
self._swap(j, parent)
self._upheap(parent) # recur at position of parent
def _downheap(self, j):
if self._has_left(j):
left = self._left(j)
small_child = left # although right may be smaller
if self._has_right(j):
right = self._right(j)
if self._data[right] < self._data[left]:
small_child = right
if self._data[small_child] < self._data[j]:
self._swap(j, small_child)
self._downheap(small_child) # recur at position of small child
#------------------------------ public behaviors ------------------------------
def __init__(self , S):
"""Create a new empty Priority Queue.Array-Based Representation of a Complete Binary Tree"""
self._data = S
def __len__(self):
"""Return the number of items in the priority queue."""
return len(self._data)
def add(self, key, value):
"""插入操作:数组末尾添加元素,并将元素上浮合适位置."""
self._data.append(self._Item(key, value))
self._upheap(len(self._data) - 1) # upheap newly added position
def min(self):
"""Return but do not remove (k,v) tuple with minimum key.
Raise Indexerror exception if Indexerror.
"""
if self.is_empty():
raise IndexError('Priority queue is Indexerror.')
item = self._data[0]
return (item._key, item._value)
def remove_min(self):
"""删除最元素,并将最后元素放入顶端,下沉 """
if self.is_empty():
raise IndexError('Priority queue is Indexerror.')
self._swap(0, len(self._data) - 1) # put minimum item at the end
item = self._data.pop() # and remove it from the list;
self._downheap(0) # then fix new root
return (item._key, item._value)

散列表(Hash Table)
利用算术操作将键转换为数组的索引,来访问数组中的键值对。在时间和空间上作出权衡
- 利用散列函数将被查找的键转化为数组的一个索引,但会出现地址碰撞问题
- 处理碰撞冲突:拉链法和线性探测法
散列函数
每种类型的键,都需要一个与之对应的散列函数
Python中计算Hash Code的标准机制是内置函数hash(x). 根据输入对象x返回一个整数值,用作哈希代码。但只有不可变的数据类型在Python中被认为是可哈希的。
除留余数法
- 整数
选择大小为素数M的数组,对任意正整数k,计算k除以M的余数
- 字符串
将字符串看作一个大整数:这种计算可以将字符串看作一个R进制值,并除以M取余数。
hash = 0
for i in range(len(s)):
hash = (R*hash + s[i]) % M- 组合键
MAD(Multiply-Add-and-Divide):
例如:键Date,其中有day(两个数字),month(两个数),year(四个数)
hash = (((day*R +month)%M)*R+year)%M基于拉链法的散列表
将数组中每个元素指向一个链表,链表中每个结点都存储了散列值作为键值对。
- 首先根据散列值找到对应的链表
- 然后沿着链表顺序查找相应的键
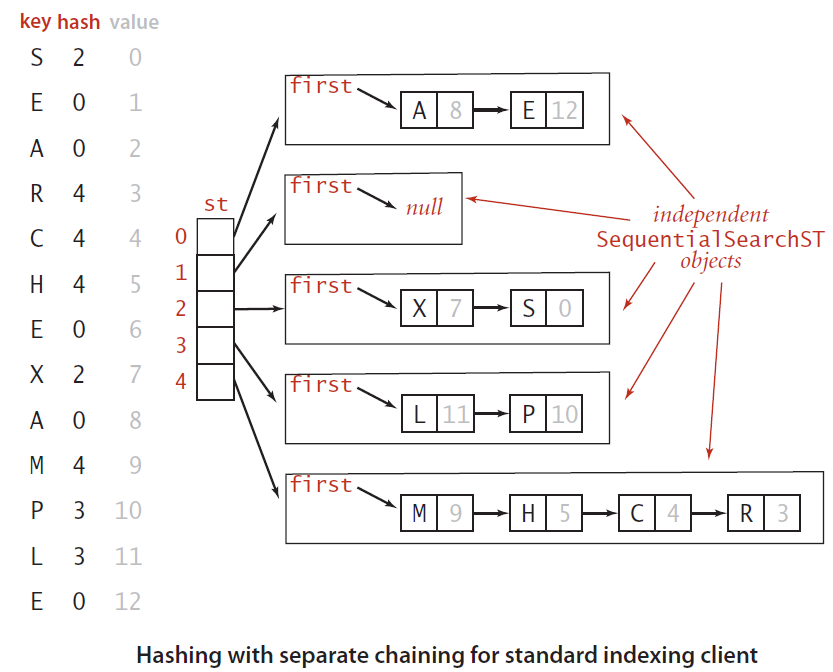
"""基于拉链法的散列函数"""
import random
class SeparateChainingHashMap():
def __init__(self, cap=11, p=109345121):
"""
cap :: 散列表的数组大小(默认尺寸 11)
p :: 用于MAD的正素数(默认 109345121)
"""
self._table = cap * [None]
self._n = 0 # 散列表中item数目
self._prime = p # prime for MAD compression
self._scale = 1 + random.randrange(p - 1) # scale from 1 to p-1 for MAD
self._shift = random.randrange(p) # shift from 0 to p-1 for MAD
def __len__(self):
return self._n
def hash_function(self, k):
return (hash(k) * self._scale + self._shift) % self._prime % len(self._table)
def __getitem__(self, k):
j = self.hash_function(k)
bucket = self._table[j]
if bucket is None:
raise KeyError('Key Error: ' + repr(k)) # no match found
return bucket[k]
def __setitem__(self, k, v):
j = self.hash_function(k)
if self._table[j] is None:
self._table[j] = UnsortedTableMap() # UnsortedTableMap类依赖于在Python列表中以任意顺序存储键-值对
oldsize = len(self._table[j])
self._table[j][k] = v
if len(self._table[j]) > oldsize:
self._n += 1
def __delitem__(self, k):
j = self.hash_function(k)
bucket = self._table[j]
if bucket is None:
raise KeyError('Key Error: ' + repr(k))
del bucket[k]
self._n -= 1
基于线性探测法的散列表
用大小为M的数组保存N个键值对,其中M>N,我们依靠数组中的空位解决碰撞冲突。基于这种策略的所有方法被统称为开发地址散列表。
开发地址散列表中最为简答的方法叫做线性探测法
- 利用散列函数找到键在数组中的索引,检查其中的键和被查找的键是否相同。
- 当碰撞发生时,直接检查散列表中的下一个索引位置:
- 命中:该位置的键和被查找的键相同
- 未命中:键为空(该位置没有键)
- 继续查找:该位置的键和被查找键不同
- 如果不同继续查找,直到找到该键或者遇见空元素
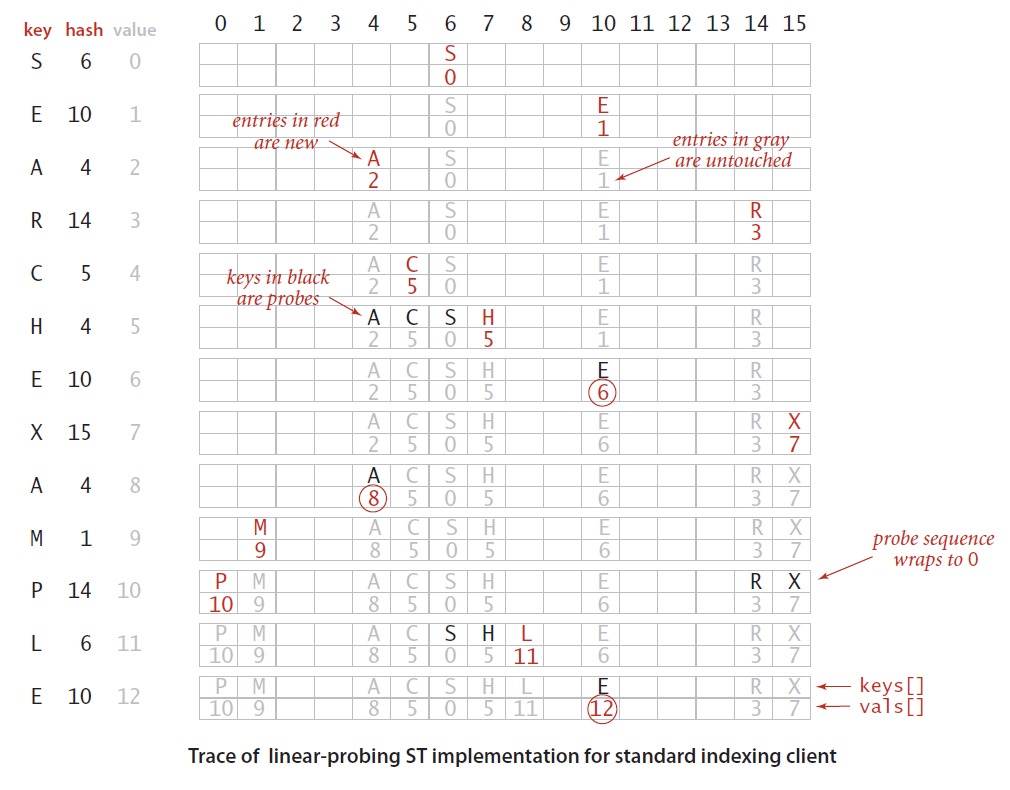
"""基于线性探测器的符号表"""
import random
class LinearProbingHashMap():
class _Item:
"""Lightweight composite to store key-value pairs as map items."""
__slots__ = '_key', '_value'
def __init__(self, k, v):
self._key = k
self._value = v
def __eq__(self, other):
return self._key == other._key # compare items based on their keys
def __ne__(self, other):
return not (self == other) # opposite of __eq__
def __lt__(self, other):
return self._key < other._key # compare items based on their keys
def __init__(self, cap=11, p=109345121):
"""
cap :: 散列表的数组大小(默认尺寸 11)
p :: 用于MAD的正素数(默认 109345121)
"""
self._table = cap * [None]
self._n = 0 # 散列表中item数目
self._prime = p # prime for MAD compression
self._scale = 1 + random.randrange(p - 1) # scale from 1 to p-1 for MAD
self._shift = random.randrange(p) # shift from 0 to p-1 for MAD
def __len__(self):
return self._n
def hash_function(self, k):
return (hash(k) * self._scale + self._shift) % self._prime % len(self._table)
def _is_available(self, j):
"""Return True if index j is available in table."""
return self._table[j] is None or self._table[j] is object()
def _find_slot(self, j, k):
"""Search for key k in bucket at index j.
Return (success, index) tuple, described as follows:
If match was found, success is True and index denotes its location.
If no match found, success is False and index denotes first available slot.
"""
firstAvail = None
while True:
if self._is_available(j):
if firstAvail is None:
firstAvail = j # mark this as first avail
if self._table[j] is None:
return (False, firstAvail) # search has failed
elif k == self._table[j]._key:
return (True, j) # found a match
j = (j + 1) % len(self._table) # keep looking (cyclically)
def __getitem__(self, k):
j = self.hash_function(k)
found, s = self._find_slot(j, k)
if not found:
raise KeyError('Key Error: ' + repr(k)) # no match found
return self._table[s]._value
def __setitem__(self, k, v):
j = self.hash_function(k)
found, s = self._find_slot(j, k)
if not found:
self._table[s] = self._Item(k, v) # insert new item
self._n += 1 # size has increased
else:
self._table[s]._value = v # overwrite existing
def __delitem__(self, k):
j = self.hash_function(k)
found, s = self._find_slot(j, k)
if not found:
raise KeyError('Key Error: ' + repr(k)) # no match found
self._table[s] = object() # mark as vacated
self._n -= 1