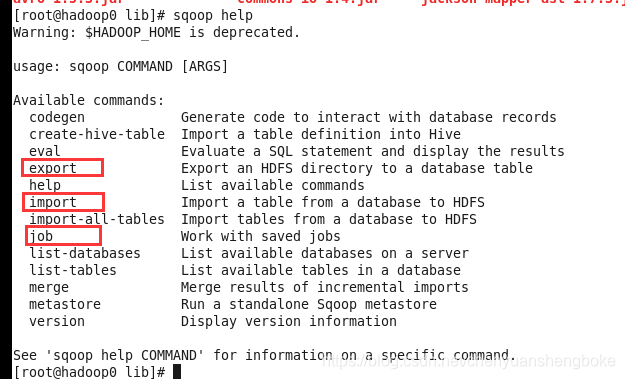
SQOOP是用于对数据进行导入导出的。
(1)把MySQL、Oracle等数据库中的数据导入到HDFS、Hive、HBase中
(2)把HDFS、Hive、HBase中的数据导出到MySQL、Oracle等数据库中
SQOOP的安装(在hadoop0上)
解压缩
tar -zxvf sqoop…
重命名
mv sqoop… sqoop
设置环境变量
vi /etc/profile
export SQOOP_HOME=/usr/local/sqoop
export PATH=.:$SQOOP_HOME/bin…
环境变量设置好了以后,执行source /etc/profile
将MySQL驱动复制到/usr/local/sqoop/lib/目录下:
cp /usr/local/hive/lib/mysql-connector-java-5.1.10.jar /usr/local/sqoop/lib/
1.把数据从mysql导入到hdfs(默认是/user/)中
sqoop ##sqoop命令
import ##表示导入
–connect jdbc:mysql://ip:3306/sqoop ##告诉jdbc,连接mysql的url
–username root ##连接mysql的用户名
–password admin ##连接mysql的密码
–table mysql1 ##从mysql导出的表名称
–fields-terminated-by ‘\t’ ##指定输出文件中的行的字段分隔符
-m 1 ##复制过程使用1个map作业
–hive-import ##把mysql表数据复制到hive空间中。如果不使用该选项,意味着复制到hdfs中
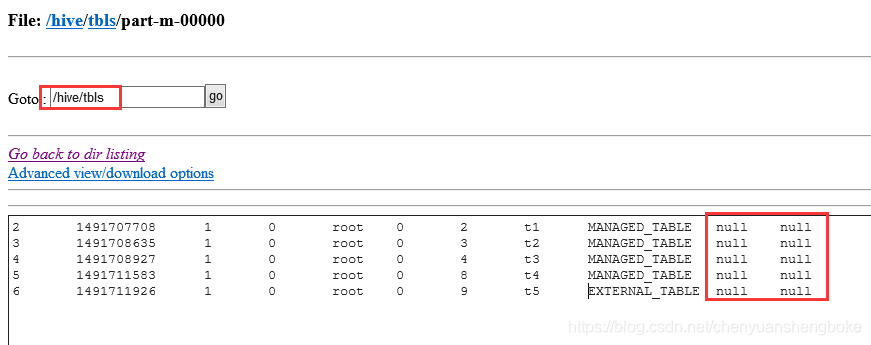
sqoop import --connect jdbc:mysql://hadoop0:3306/hive --username root --password admin --table TBLS --fields-terminated-by ‘\t’ -m 1 --append --hive-import
sqoop import --connect jdbc:mysql://hadoop0:3306/hive --username root --password admin --table TBLS --fields-terminated-by ‘\t’ --null-string ‘**’ -m 1 --append --hive-import
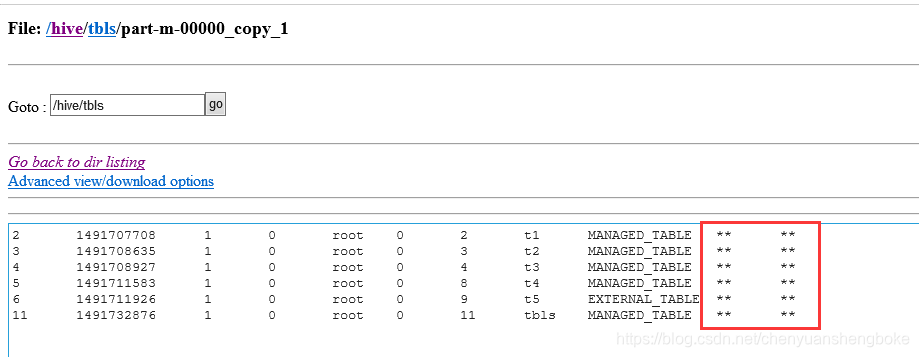
–null-string '’ 表示对于null值,使用代替。默认显示null。
–fields-terminated-by ‘\t’ 指定输出的列分隔符
–lines-terminated-by ‘\n’ 指定输出的行分隔符
–append 追加数据到HDFS源文件中。
-m 表示启动的Mapper任务数量。默认是4个。
sqoop import --connect jdbc:mysql://hadoop0:3306/hive --username root --password admin --table TBLS --fields-terminated-by ‘\t’ --null-string ‘**’ -m 1 --append --hive-import --check-column ‘TBL_ID’ --incremental append --last-value 6
增量导入模式:
–check-column ‘列名’ 检查哪些列作为增加导入的依据
–incremental (append或lastmodified)其中,append是根据是否追加了指定行来判断的,lastmodified是根据值是否改变来判断的
–last-value 上次的值是多少
在表中增加一个‘TBL_ID’ 7,然后在导入,就会发现有数据在导入。
2.把数据从hdfs导出到mysql中(同一个导出操作可重复执行,会导出很多一样的数据)
sqoop
export ##表示数据从hive复制到mysql中
–connect jdbc:mysql://ip:3306/sqoop
–username root
–password admin
–table mysql2 ##mysql中的表,即将被导入的表名称
–export-dir ‘/user/root/warehouse/mysql1’ ##hive中被导出的文件目录
–fields-terminated-by ‘\t’ ##hive中被导出的文件字段的分隔符
注意:mysql2必须存在
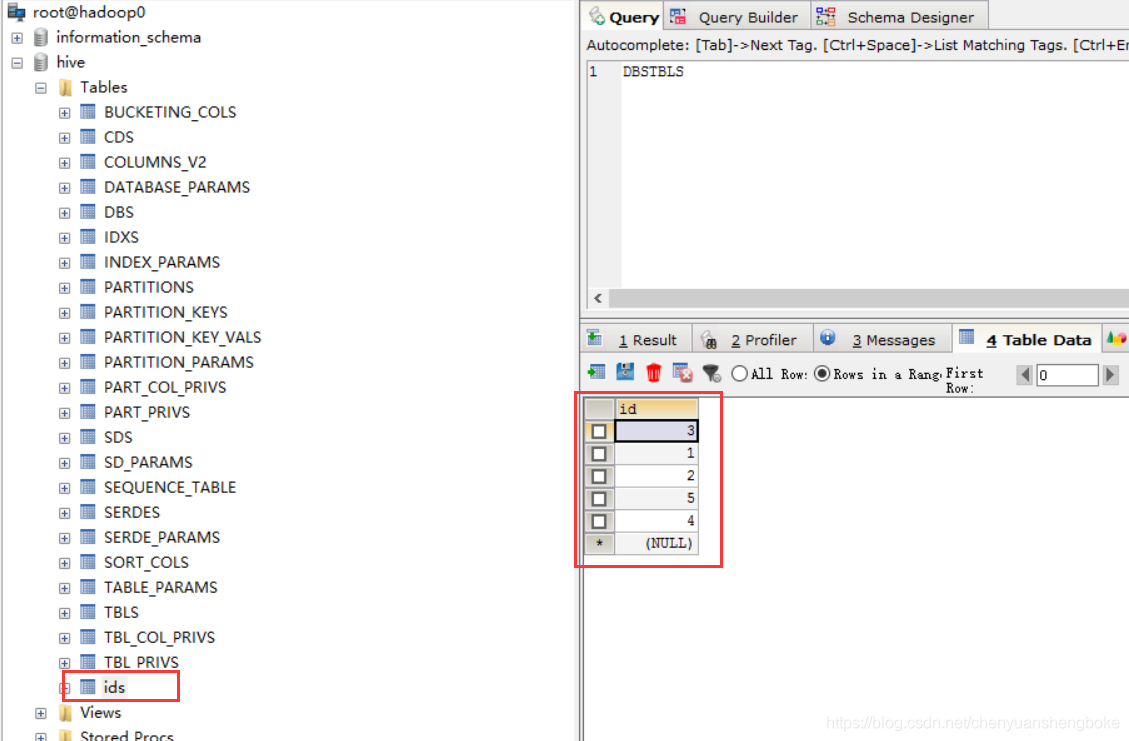
先在hive下创建一个空表ids(id int)—直接在GUI工具里创建即可,创建一个/ids/id(必须创建一个目录,然后将ids中的数据上传到id中,因为导出只能按照目录导出),上传到HDFS中。将HDFS中的ids到处到mysql中
hadoop fs -put /root/id /ids/id
sqoop export --connect jdbc:mysql://hadoop0:3306/hive --username root --password admin --table ids --fields-terminated-by ‘\t’ --export-dir ‘/ids’
3.设置为作业,运行作业
sqoop job --create myjob – import --connect jdbc:mysql://hadoop0:3306/hive --username root --password admin --table TBLS --fields-terminated-by ‘\t’ --null-string ‘**’ -m 1 --append --hive-import
查看创建的job:
sqoop job --list
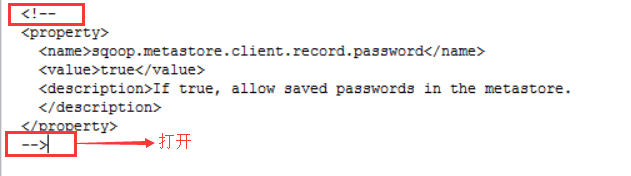
执行job:(要输入密码admin,可以在sqoop-site.xml中打开保存密码的部分,就可以不用输入密码了)
sqoop job --exec myjob
删除job:
sqoop job --delete myjob
- 导入导出的事务是以Mapper任务为单位。