全文搜索的需求非常大。而开源的解决办法Elasricsearch(Elastic)就是一个非常好的工具。目前是全文搜索引擎的首选。

Elastic 的底层是开源的Lucene。Elastic提供了REST API的操作接口。是Lucene的扩展。底层依旧是索引,但是可以把大索引切成n片,放到不同的节点,所以就实现了分布式。也就理所当然的是读写负载均衡。此外,他还是一个分布式实时文档存储,其中每个field可被搜索。 ES 可以自动将海量数据分布到多台服务器上去存储和检索海量数据。可以在秒级别在每台服务器上分析数据。
下面简单的介绍一下Elastic并且从零开始搭建一个Elastic。
一、简介
基本组件: (1).索引(index):文档容器,类似于关系型数据库中的库。索引名必须是小写字母。
(2).类型(type):类型是索引内部的逻辑分区。其意义完全取决与用户需求,一个索引内部可定义多个类型。类似于关系型数据库中的表结构,字段。
(3).文档(document):文档是Lucene索引和搜索的原子单位。它包含多个域。基于JSON格式存储。每个域的格式类似于字典
(4).映射(mapping):原始内容存储为文档之前的分析,映射就是定义此映射过程该如何实现。(例如切词,过滤)
集群组件:(1)Cluster:ES的集群标识为集群名称。默认为“elasticsearch”,节点靠此名字决定加入到哪一个集群中。一个节点只能属于一个集群。
(2).Node:运行单个ES实例的主机。节点的标识靠节点名。
(3).Shard:将索引切割成为的物理存储组件,但每一个shared都是一个独立且完整的索引,创建索引时,ES默认分割为5个shard。用户也可以按需自定义,创建完成后不可修改。shard有两种,primary和replica。用于负载均衡。
ES Cluster启动过程。通过多播(或单播)在9300/tcp查找同一集群中的其他节点,并建立通信。集群中所有节点会选举出一个主节点负责管理整个集群状态。以及在集群范围内决定shared的分布。
二、安装
安装环境 Linux centos7.3 3台. 直接就安装成集群。Elastic 的安装需要Java环境。不会配置Java环境的请参考这篇文章
这里也简单的演示一下JAVA的环境配置。首先准备好jdk的tar包。下载网页
# mkdir /usr/java
# tar xf jdk-8u151-linux-i586.tar.gz -C /usr/java
# vim /etc/profile
JAVA_HOME=/usr/java/jdk1.8.0_151
export JRE_HOME=/usr/java/jdk1.8.0_151/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH# update-alternatives --install /usr/bin/java java /usr/java/jdk1.8.0_151/bin/java 300
# update-alternatives --install /usr/bin/javac javac /usr/java/jdk1.8.0_151/bin/javac 300
# update-alternatives --config java
共有 3 个程序提供“java”。
选择 命令
-----------------------------------------------
*+ 1 /usr/lib/jvm/jre-1.7.0-openjdk.x86_64/bin/java
2 /usr/lib/jvm/jre-1.6.0-openjdk.x86_64/bin/java
3 /usr/java/jdk1.8.0_151/bin/java
按 Enter 来保存当前选择[+],或键入选择号码:3
若出现 -bash: /usr/java/jdk1.8.0_151/bin/java: /lib/ld-linux.so.2: bad ELF interpreter: 没有那个文件或目录 这个错误, 则执行 yum install glibc.i686 即可。
至此,安装成功jdk。下来安装Elasticsearch。下载页面
下载好rpm包。执行
# rpm -ivh elasticsearch-6.1.1.rpm
warning: elasticsearch-6.1.1.rpm: Header V4 RSA/SHA512 Signature, key ID d88e42b4: NOKEY
Preparing... ########################################### [100%]
Creating elasticsearch group... OK
Creating elasticsearch user... OK
1:elasticsearch ########################################### [100%]
### NOT starting on installation, please execute the following statements to configure elasticsearch service to start automatically using chkconfig
sudo chkconfig --add elasticsearch
### You can start elasticsearch service by executing
sudo service elasticsearch start
# systemctl start elasticsearch
# vim /etc/elasticsearch/elasticsearch.yml
cluster.name: my-elastic
# 集群名字,相同集群名字的节点会放到同一个集群下
node.name: "node-1"
# 节点名字
discovery.zen.minimum_master_nodes: 2
#指定集群中的节点中有几个有master资格的节点。
#对于大集群可以写3个以上。
discovery.zen.ping.timeout: 3s
#默认是3s,这是设置集群中自动发现其它节点时ping连接超时时间
discovery.zen.ping.multicast.enabled: false
#设置是否打开多播发现节点,默认是true。
network.bind_host: 192.168.40.129
#设置绑定的ip地址,这是我的虚拟机的IP。
network.publish_host: 192.168.40.129
#设置其它节点和该节点交互的ip地址。
network.host: 0.0.0.0
#同时设置bind_host和publish_host上面两个参数。
transport.tcp.port: 9300
#设置参与集群的端口
http.port: 9200
#接收请求端口
#discovery.zen.ping.unicast.hosts:["节点1的 ip","节点2 的ip","节点3的ip"]
#指明集群中其它可能为master的节点ip,以防es启动后发现不了集群中的其他节点。
接下来给其余的两个节点同样的步骤安装Elasticsearch。
三、核心概念
{
"id" : "qWAEoJU",
"product_name" : "蒂花之秀",
"product_desc" : "乌黑亮丽",
"category" : "2",
"category_name" : "日化用品"
}
四、安装后相关简介
# pwd
/usr/share/elasticsearch/bin
# ls
elasticsearch elasticsearch-env elasticsearch-keystore elasticsearch-plugin elasticsearch-translog
# yum -y install kibana-6.1.1-x86_64.rpm

五、简单操作
curl -X GET localhost:9200/_cat/indices# curl -X PUT localhost:9200/test_index?pretty
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test_index"
}
# curl -X DELETE localhost:9200/test_index?pretty
{
"acknowledged" : true
}六、入门案例实战
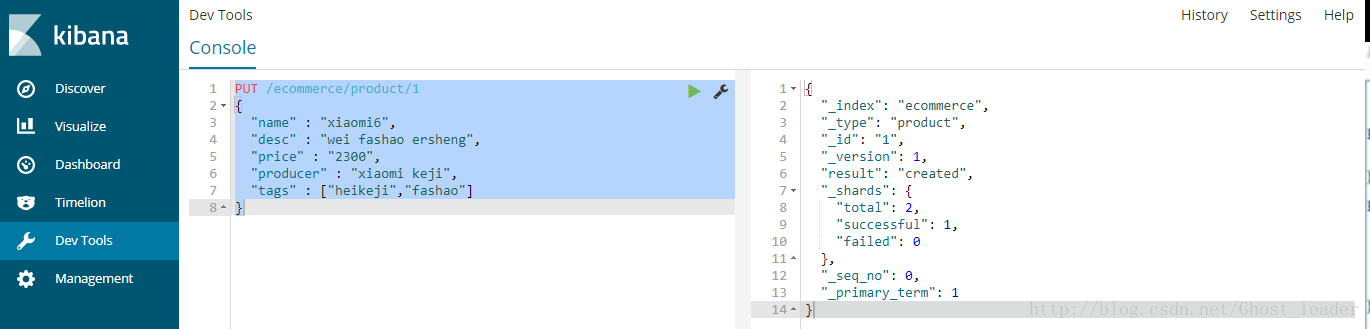
PUT /ecommerce/product/1
{
"name" : "xiaomi6",
"desc" : "wei fashao ersheng",
"price" : "2300",
"producer" : "xiaomi keji",
"tags" : ["heikeji","fashao"]
}
PUT /ecommerce/product/2
{
"name" : "iphoneX",
"desc" : "gaoduan daqi",
"price" : "8300",
"producer" : "apple",
"tags" : ["qianwei","shishang"]
}# curl -XGET localhost:9200/ecommerce/product/1
{"_index":"ecommerce","_type":"product","_id":"1","_version":1,"found":true,"_source":{
"name" : "xiaomi6",
"desc" : "wei fashao ersheng",
"price" : "2300",
"producer" : "xiaomi keji",
"tags" : ["heikeji","fashao"]
}三、修改,替换商品
POST /ecommerce/product/1/_update
{
"doc":{
"price": "2400"
}
}DELETE /ecommerce/product/1高级操作
搜索所有的商品。GET ecommerce/product/_search{
"took": 90,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 2,
"max_score": 1,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "2",
"_score": 1,
"_source": {
"name": "iphoneX",
"desc": "gaoduan daqi",
"price": "8300",
"producer": "apple",
"tags": [
"qianwei",
"shishang"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_score": 1,
"_source": {
"name": "xiaomi6",
"desc": "wei fashao ersheng",
"price": "2400",
"producer": "xiaomi keji",
"tags": [
"heikeji",
"fashao"
]
}
}
]
}
}查询名字里带 xiaomi 的商品。
GET /ecommerce/product/_search?q=name:xiaomiGET /ecommerce/product/_search
{
"query" : {
"match" : {
"name" :"xiaomi"
}
}
}GET ecommerce/product/_search
{
"query":{
"match_all": {}},
"from":1,
"size":1
}GET ecommerce/product/_search
{
"query":{
"match_all": {}
},
"_source": ["name","price"]
}查出商品包含xiaomi且价格大于2000元的。
GET ecommerce/product/_search
{
"query":{
"bool":{
"must":{
"match":{
"name":"xiaomi"
}
},
"filter":{
"range":{
"price":{
"gt": 2000
}
}
}
}
}
}GET ecommerce/product/_search
{
"query":{
"match_phrase":{
"producer": "keji"
}
}
}GET ecommerce/product/_search
{
"query":{
"match":{
"producer": "keji"
}
},
"highlight": {
"fields": {
"producer": {}
}
}
}更多详细的查询语法或其他内容