注意:
在tensorflow中,一旦有涉及到文件路径的相关操作,请确保文件路径上所有目录名为英文!!!!否则可能会出现奇怪的错误!!
TensorFlow模型的保存与恢复(使用tf.train.Saver()和saver.restore()):
首先我们需要创建一个用来保存模型的对象saver:
saver = tf.train.Saver(max_to_keep=3)其中max_to_keep的值为最多保存的模型的个数,一旦超出会用新的模型替换掉旧的,当然这个参数也可以不写。一般max_to_keep取3-5即可。
如果我们想在每次循环结束时保存一个最新生成的模型,可以这样写:
import tensorflow as tf
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(iteration):
# 这里代表我们进行的训练过程
.....
# 训练完后我们要保存模型
saver.save(sess, save_path, global_step=i)
# save_path是保存模型的路径,注意保存路径要写上要保存的文件的名字,不要写文件后缀名在进行一次 saver.save() 后会创建后3个数据文件并创建一个检查点(checkpoint)文件:
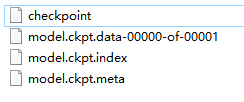
其中权重等参数被保存到 .ckpt.data 文件中,以字典的形式;
图和元数据被保存到 .ckpt.meta 文件中,可以被 tf.train.import_meta_graph 加载到当前默认的图。
如果我们只想保留最好的模型:
我们可以在上面保存循环路径前计算一下准确率或loss值,然后用if判断,只有本次结果比上次好才保存新的模型,否则没必要保存。
在实际应用中,保存模型还有另一种用处:
我们可以利用不同大小的学习率来获取多个局部最优点,当loss值基本稳定不再降低时,保存一个模型,然后调整学习率,再寻找下一个局部最优点,最后,我们可以用这些模型来做融合。
恢复模型并继续训练或测试:
import tensorflow as tf
import os
saver=tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(iteration):
if os.path.exists("./tmp/checkpoint"):
# 判断最新的保存模型检查点是否存在,如果存在则从最近的检查点恢复模型
saver.restore(sess, tf.train.latest_checkpoint('./tmp/'))
# 我们也可以取判断某一个我们保存的模型是否存在,而不一定是最近的检查点,如:
# if os.path.exists("./tmp/train_model"):
# saver.restore(sess,"./tmp/train_model")
# 这里代表我们进行的训练过程
.....
# 训练完后我们要保存模型
saver.save(sess, save_path, global_step=i)
# save_path是保存模型的路径,注意保存路径要写上要保存的文件的名字,不要写文件后缀名
# global_step=i将保存的模型的迭代次数作为后缀加入到模型名字中注意:
如果你是在一个.py文件中恢复另一个.py文件训练出来的模型,在导入模型之前,必须重新再定义一遍变量。我们在新的.py文件中定义的变量必须在恢复的模型中存在,但不是所有在恢复的模型中的变量,你都要重新定义。
saver 的操作必须在 sess 建立后进行,因为saver的方法是tensorflow中的方法,必须要开始Session会话后才能进行。
global_step=i将保存的模型的迭代次数作为后缀加入到模型名字中。
在测试时,我们可以通过下面的代码直接通过meta graph构建网络、载入训练时得到的参数,并使用默认的session:
saver = tf.train.import_meta_graph(‘model/model.meta’)
saver.restore(tf.get_default_session(),’ model/model.ckpt-16000’)保存和读取模型的实际例子:
import tensorflow as tf
import numpy as np
import os
# 用numpy产生数据x和y
x_data = np.linspace(-1, 1, 300)[:, np.newaxis] # 转置
noise = np.random.normal(0, 0.05, x_data.shape)
y_data = np.square(x_data) - 0.5 + noise
# 占位符x_ph和y_ph
x_ph = tf.placeholder(tf.float32, [None, 1])
y_ph = tf.placeholder(tf.float32, [None, 1])
# 隐藏层
w1 = tf.Variable(tf.random_normal([1, 10]))
b1 = tf.Variable(tf.zeros([1, 10]) + 0.1)
wx_plus_b1 = tf.matmul(x_ph, w1) + b1
hidden = tf.nn.relu(wx_plus_b1)
# 输出层
w2 = tf.Variable(tf.random_normal([10, 1]))
b2 = tf.Variable(tf.zeros([1, 1]) + 0.1)
wx_plus_b2 = tf.matmul(hidden, w2) + b2
y = wx_plus_b2
# loss函数,方差和平均值
loss = tf.reduce_mean(tf.reduce_sum(tf.square(y_ph - y), reduction_indices=[1]))
train_op = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
# 保存模型对象saver,设为最多保存5个模型
saver = tf.train.Saver(max_to_keep=5)
# 判断模型保存路径是否存在,不存在就创建(注意这里路径只是目录,没有文件名)
if not os.path.exists('tmp/'):
os.mkdir('tmp/')
# 初始化
with tf.Session() as sess:
if os.path.exists('tmp/checkpoint'): # 判断最近的检查点模型是否存在
saver.restore(sess, 'tmp/model.ckpt') # 如果存在就从模型中恢复变量,注意文件名不要加后缀名
else:
init = tf.global_variables_initializer() # 不存在就初始化变量
sess.run(init)
for i in range(1000):
_, loss_value = sess.run([train_op, loss], feed_dict={x_ph: x_data, y_ph: y_data})
if i % 100 == 0:
save_path = saver.save(sess, 'tmp/model.ckpt'+str(i))
print("迭代次数:%d , 训练损失:%s" % (i, loss_value))注意:
model.ckpt 必须存在我们指定的文件夹中,'tmp/model.ckpt' 这里至少要有一层文件夹,这个文件夹必须要先创建,否则无法保存。
恢复模型时同保存时一样,是 ‘tmp/model.ckpt’,和那3个文件名都不一样。
运行结果如下:
由于max_to_keep=5,因此上面的例子最多同时保存了5个模型。并且新的模型会依顺序替换旧的模型。
