构造价格模型
在利用多种不同属性(比如价格)对数值型数据进行预测时,贝叶斯分类器、决策树、支持向量机都不是最佳的算法。
本篇将对一系列算法进行考查,这些算法可以接受训练,根据之前见过的样本数据作出数据类的预测,而且它们还可以显示出预测的概率分布情况,以帮助用户对预测过程加以解释。后续部分将考查如何利用这些算法来构造价格预测模型。
进行数值预测的一项关键工作是确定哪些变量是重要的。
构造一个样本数据集
根据一个人为假设的简单模型来构造一个有关葡萄酒价格的数据集。酒的价格是根据酒的等级及其储藏的年代来共同决定的。该模型假设葡萄酒有‘峰值年’的现象,即:较之峰值年而言,年代稍早一些的酒的品质会比较好一些,而紧随其后的品质则稍差些。
def wineprice(rating,age):
peak_age=rating-50
#根据等级来计算价格
price=rating/2
if age>peak_age:
#经过‘峰值年’,后继5年里其品质将会变差
price=price*(5-(age-peak_age))
else:
#价格在接近‘峰值年’时会增加到原值的5倍
price=price*(5*((age+1)/peak_age))
if price<0: price=0
return price'''
构造表示葡萄酒价格的数据集,
并在原有价格的基础上通过‘噪声’随机地加减了20%,
以此来表现诸如税收和价格局部变动的情况
'''
def wineset1():
rows=[]
for i in range(300):
#随机生成年代和等级
rating=random()*50+50
age=random()*50
#得到一个参考价格
price=wineprice(rating,age)
#增加‘噪声’ ##########################################################
price*=(random()*0.4+0.8)
#加入数据集
rows.append({'input':(rating,age),'result':price})
return rows
K-最邻近算法(kNN)
通过寻找与当前所关注的商品情况相似的一组商品,对这些商品的价格求均值,进而作出价格预测,k指的是为了求得最终结果而参与求平均值运算的商品数量。
邻近数
过少过多均不好
定义相似度
寻找一种衡量两件商品之间相似程度的方法。
补充:欧几里得距离算法
#欧几里得距离算法
def euclidean(v1,v2):
d=0.0
for i in range(len(v1)):
d+=(v1[i]-v2[i])**2
return math.sqrt(d)
k-最邻近算法
优点:1、每次有新数据加入时,都无需重新进行训练

缺点:1、计算量大 2、该函数在计算距离是对年代和等级是同等看待的,但现实是,某些变量对最终价格所产生的影响往往比其他变量更大
def getdistance(data,vec1):
distancelist=[]
for i in range(len(data)):
vec2=data[i]['input']
distancelist.append((euclidean(vec1,vec2),i))
distancelist.sort()
return distancelist
def knnestimate(data,vec1,k=5):
#得到经过排序的距离值
dlist=getdistance(data,vec1)
avg=0.0
#对前k项结果求平均
for i in range(k):
idx=dlist[i][1]
avg+=data[idx]['result']
avg=avg/k
return avgprint(knnestimate(data,(95.0,3.0)))
print(knnestimate(data,(99.0,3.0)))
print(wineprice(95.0,5.0))
print(wineprice(99.0,3.0))
print("***kNN")
print(knnestimate(data,(99.0,5.0)))
print("***真实")
print(wineprice(99.0,5.0))#得到实际价格
print("***少")
print(knnestimate(data,(99.0,5.0),k=1)) #尝试更少的近邻
print("***多")
print(knnestimate(data,(99.0,5.0),k=10)) #尝试更少的近邻为邻近分配权重
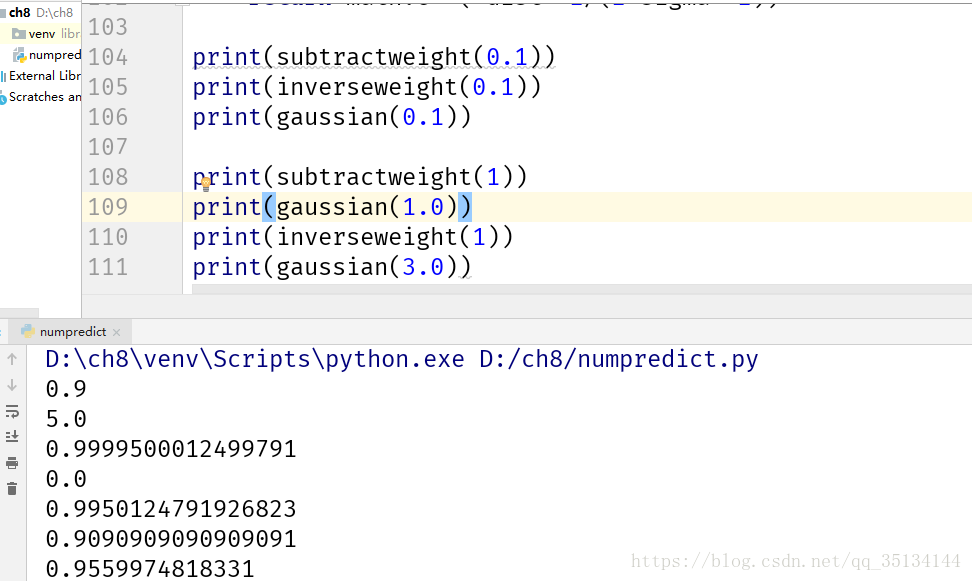
反函数
该函数最为简单的一种形式是返回距离的倒数,不过有时候,完全一样或非常接近的商品,会使权重值变得非常之大,甚至是无穷大,基于这样的原因,有必要在对距离求倒数之前先加上一个小小的常量
def inverseweight(dist,num=1.0,const=0.1):
return num/(dist+const)
缺陷在于它会为近邻项赋以很大的权重,而稍远一点的项,其权重则会‘衰减’得很快。这种情况也许正是我们所期望的,但有的时候,这也会使算法对噪声变的更加敏感。
减法函数
def subtractweight(dist,const=1.0):
if dist>const:
return 0
else:
return const-dist
该函数克服了反函数对近邻项权重分配过大的潜在问题,但是由于权重值最终会跌至0,因此,我们有可能找不到距离足够近的项,将其视作近邻,即:对于某些项,算法根本就无法作出预测。
高斯函数
‘钟型曲线’
#高斯函数
def gaussian(dist,sigma=10.0):
return math.e**(-dist**2/(2*sigma**2))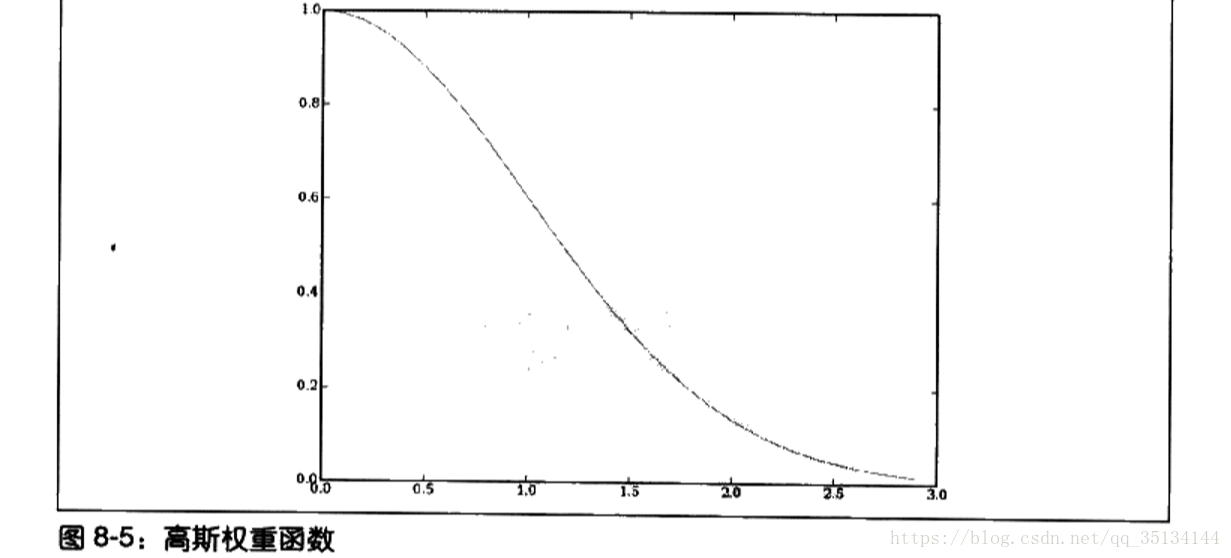

加权KNN

#加权KNN
def weightedknn(data,vec1,k=5,weightf=gaussian):
#得到距离值
dlist=getdistances(data,vec1)
avg=0.0
totalweight=0.0
#得到加权平均值
for i in range(k):
dist=dlist[i][0]
idx=dlist[i][1]
weight=weightf(dist)
avg+=weight*data[idx]['result']
totalweight+=weight
avg=avg/totalweight
return avg交叉验证

def dividedata(data,test=0.05):
trainset=[]
testset=[]
for row in data:
if random()<test:
testset.append(row)
else:
trainset.append(row)
return trainset,testset
def testalgorithm(algf,trainset,testset):
error=0.0
for row in testset:
guess=algf(trainset,row['input'])
error+=(row['result']-guess)**2
return error/len(testset)
def crossvalidate(algf,data,trials=100,test=0.05):
error=0.0
for i in range(trials):
trainset,testset=dividedata(data,test)
error+=testalgorithm(algf,trainset,testset)
return error/trials
def knn3(d,v):
return knnestimate(d,v,k=3)
def knn1(d,v):
return knnestimate(d,v,k=1)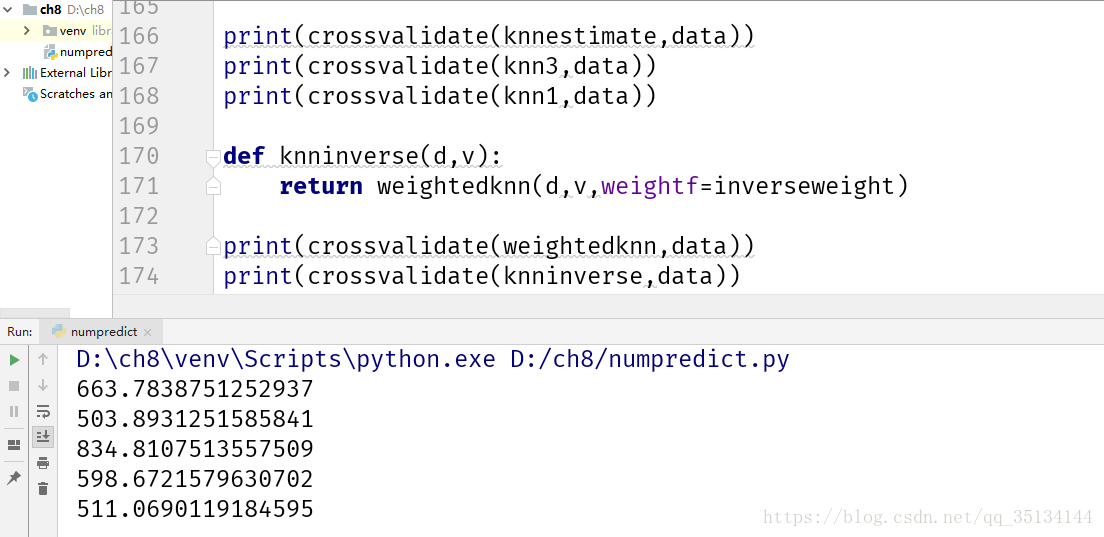
选择太少或太多的近邻都会导致效果不佳。
加权kNN算法似乎能够针对上述数据给出更好的结果。
对于一个特定的训练集而言,选择参数只须做一次即可,但随着训练集内容的增长,偶尔还须对其进行再次的更新。
不同类型的变量
def wineset2():
rows=[]
for i in range(300):
#随机生成年代和等级
rating=random()*50+50
age=random()*50
aisle=float(randint(1,20))
bottlesize=[375.0,750.0,1500.0,3000.0][randint(0,3)]
#得到一个参考价格
price=wineprice(rating,age)
price*=(bottlesize/750)
#增加‘噪声’ ##########################################################
price*=(random()*0.2+0.9)
#加入数据集
rows.append({'input':(rating,age,aisle,bottlesize),'result':price})
return rows
即使数据集现在包含了更多的信息,而且噪声也比以前更少了,但是crossvalidate函数实际返回的结果较之以前却更为糟糕。其原因在于,算法现在还不知道如何对不同的变量加以区别对待。
因为之前的两个变量都位于同一值域范围内,因此,利用这些变量一次性算出距离值是有意义的。
酒瓶尺寸和原先的变量相比,对距离计算所产生的影响更为显著——其影响将超过任何其他变量对距离计算所构成的影响,这意味着,在计算距离的过程中其他变量根本就未被考虑在内。除此之外,还可能会遇到的另一个问题是数据集中引入了完全不相关的变量,如安放葡萄酒的通道号。
按比例缩放

def rescale(data, scale):
scaleddata = []
for row in data:
scaled = [scale[i] * row['input'][i] for i in range(len(scale))]
scaleddata.append({'input': scaled, 'result': row['result']})
return scaleddata
对缩放结果进行优化
大多数时候我们所面对的数据集都不是自己构造的,而且我们也未必知道,到底哪些变量是不重要的,而哪些变量又对计算结果有着重大的影响。理论上我们可以尝试大量不同的组合,直到发现一个足够好的结果为止,不过也许有数以百计的变量须要考查,并且这项工作可能会非常地乏味。
def createcostfunction(algf,data):
def costf(scale):
sdata=rescale(data,scale)
return crossvalidate(algf,sdata,trials=10)
return costf
weightdomain=[(0,20)]*4from optimization import annealingoptimize,geneticoptimize
data = wineset2()
costf=createcostfunction(knnestimate,data)
print(annealingoptimize(weightdomain,costf,step=5))
print(geneticoptimize(weightdomain,costf,popsize=50,step=1,mutprob=0.2,elite=0.2,maxiter=100))实验做的有问题。。。。。。。。。
利用模拟退火以及遗传算法等优化算法地一个好处在于,我们很快就能发觉哪些变量是重要地,并且其重要程度有多大。
不对称分布
若葡萄酒购买者分别来自两个彼此独立的群组:一部分人是从小酒馆购得的葡萄酒,而另一部分人则是从折扣店购得,并且后者得到了50%的折扣。
def wineset3():
rows=wineset1()
for row in rows:
if random()<0.5:
#葡萄酒是从折扣店购得的
row['result']*=0.5
return rows算法给出的评价值将同时涉及两组人群,这就相当于可能有25%的折扣。为了不只是简单地得到一个平均值,则需要一种方法能够在某些方面更近一步地对数据进行考查。
估计概率密度
假设输入条件为99%和20年,那么我们需要一个函数来告诉我们,价格介于40美元和80美元之间的几率是50%,而价格介于80美元和100美元之间的几率也是50%。
函数首先计算位于该范围内近邻的权重值,然后计算所有近邻的权重值,最终的概率等于在指定范围内的近邻权重之和除以所有权重之和。
def probguess(data,vec1,low,high,k=5,weightf=gaussian):
dlist=getdistances(data,vec1)
nweight=0.0
tweight=0.0
for i in range(k):
dist=dlist[i][0]
idx=dlist[i][1]
weight=weightf(dist)
v=data[idx]['result']
#当前数据点位于指定范围内吗?
if v>=low and v<=high:
nweight+=weight
tweight+=weight
if tweight==0 : return 0
#概率等于位于指定范围内的权重值除以所有权重值
return nweight/tweight
绘制概率分布
第一种方法:累计概率分布
图形从概率为0开始,尔后随着商品在某一价位出命中的概率值而逐级递增。直至最高位处,图形对应的概率值达到1
#绘制概率分布
from pylab import *
# a=array([1,2,3,4])
# b=array([4,2,3,1])
# plot(a,b)
# show()
# t1=arange(0.0,10.0,0.1)
# plot(t1,sin(t1))
# show()
#累积概率
def cumulativegraph(data,vec1,high,k=5,weightf=gaussian):
t1=arange(0.0,high,0.1)
cprob=array([probguess(data,vec1,0,v,k,weightf) for v in t1])
plot(t1,cprob)
show()第二种:假设每个位点的概率都等于其周边概率的一个加权平均
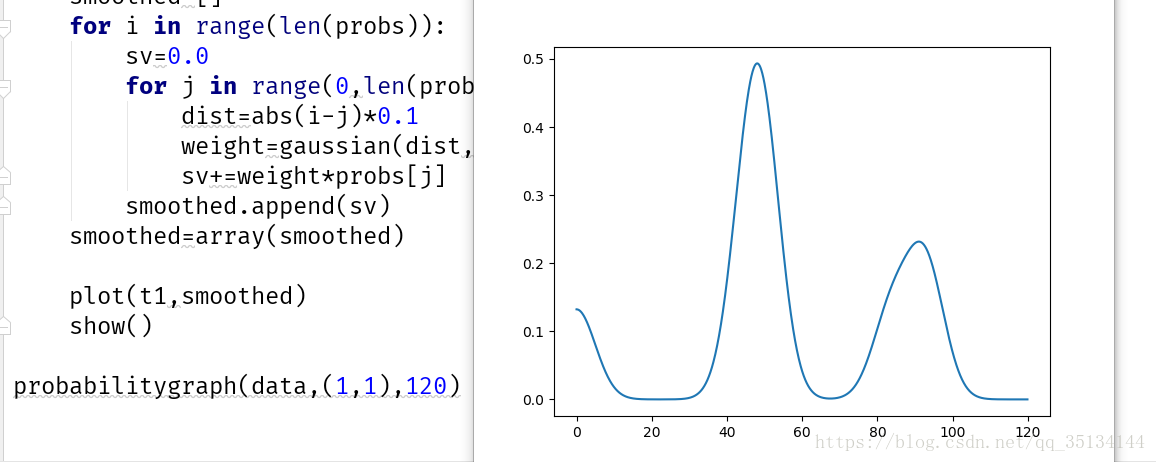
def probabilitygraph(data,vec1,high,k=5,weightf=gaussian,ss=5.0):
#建立一个代表价格的值域范围
t1=arange(0.0,high,0.1)
#得到整个值域范围内的所有概率
probs=[probguess(data,vec1,v,v+0.1,k,weightf) for v in t1]
#通过加上近邻概率的高斯计算结果,对概率值做平滑处理
smoothed=[]
for i in range(len(probs)):
sv=0.0
for j in range(0,len(probs)):
dist=abs(i-j)*0.1
weight=gaussian(dist,sigma=ss)
sv+=weight*probs[j]
smoothed.append(sv)
smoothed=array(smoothed)
plot(t1,smoothed)
show()