唯品会Dragonfly日志系统的Elasticsearch实践
转载声明:
本文转自
唯品会Dragonfly日志系统的Elasticsearch实践
公众号:唯技术
作者: 潘卫华
转载仅为方便学习查看,一切权利属于原作者,如果带来不便请联系我删除。
0x01 摘要-唯品会日志系统初探
唯品会日志系统,承接了公司上千个应用的日志,提供了日志快速查询、统计、告警等基础服务,是保障公司技术体系正常运行必不可缺的重要系统之一。日均接入应用日志600亿条,压缩后大小约40TB,大促时日志峰值流量达到每分钟3亿条。
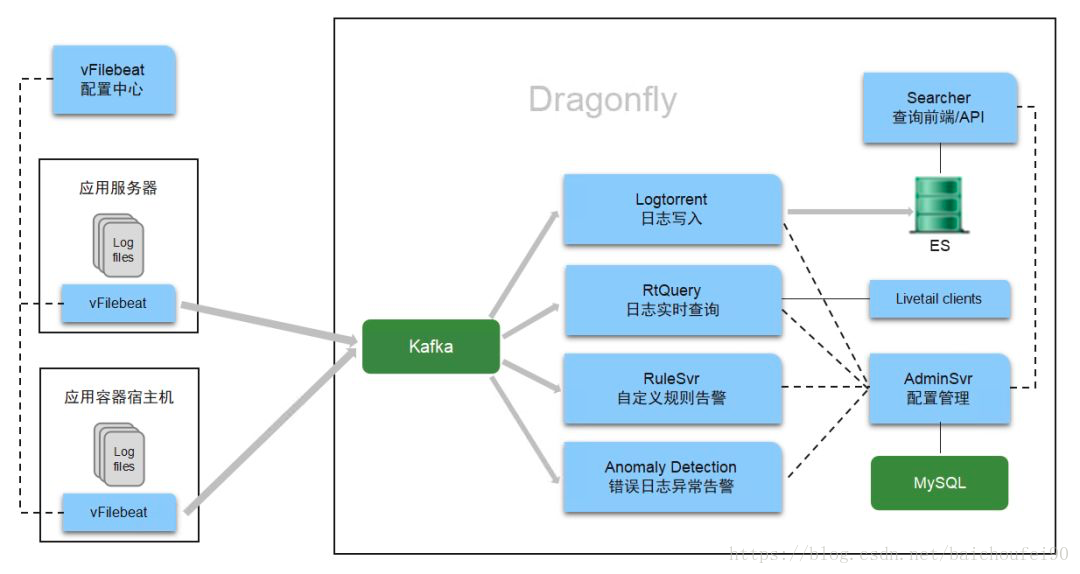
唯品会日志系统,取名Dragonfly,寓意像蜻蜓复眼一样,可以依据应用日志既准确又快速的观察到系统的运行细节、并发现系统的任何异动。最初,Dragonfly是围绕开源的ELK(Elasticsearch/Logstash/Kibana)技术栈打造的,后来架构不断演进,增加新的功能组件。目前的系统架构如下图所示。
但无论怎么演进,快速、稳定的日志查询始终是日志系统的核心服务所在,因此Elasticsearch可谓是Dragonfly系统中的核心组件。本文将重点介绍唯品会日志系统有效使用Elasticsearch的各种实践经验。
0x02 Elasticsearch简介
朋友圈里这个月最为热议的技术新闻之一,就是Elastic公司2018.10.6在纳斯达克上市,当天开盘后股价就上涨了一倍。将一项技术通过开源不断做大做强,成为无可争议的垂直领域领导者,最终实现上市获得更大发展——Elastic公司实现了无数软件创业公司的梦想,并提供了一个完美的创业成功典范。而Elasticsearch正是这家公司的招牌产品。
Elasticsearch(下面简称ES)是基于Apache Lucene打造的分布式文档存储+文本查询引擎。它通过倒排索引(inverted-index)技术提供极快速的文本查询和聚合统计功能,通过合理的索引和分片设计,又可以支持海量的文本信息。因此非常适合用于搭建日志平台。
尽管如此,将这样一个开源软件,既要能贴合公司内部的实际使用场景,又要做到高吞吐、高容量、高可靠,还是需要做不少细致的工作,下面会一一道来。
Dragonfly系统从2015年开始搭建,最初使用Elasticsearch 1.x,后来升级到5.6版本。
0x03 硬件配置
Dragonfly系统在不同机房搭建了多个ES集群(配置了跨集群查询),共上百台机器,最大的2个集群均有接近50台服务器。这些服务器包含了两种硬件配置类型:
●一种使用多个SSD磁盘,并拥有性能强劲的CPU。 SSD服务器作为集群中的热数据服务器使用,负责新日志的写入,并提供使用频率最高的最近几天的日志查询服务。
●另一种使用多个大容量的HDD/SATA磁盘,搭配较弱的CPU。 HDD服务器作为集群中的冷数据服务器使用,负责保存较早前的日志。由于早前的日志访问频率较低,因此不需要很好的性能,而看重磁盘容量。
两种类型服务器的磁盘均使用RAID0阵列,内存大小为64GB或128GB。
通过冷热分离,可以保证ES集群的写入和实时查询性能,又能在成本较低的情况下提供较长的日志保存时间,下面还会详细介绍ES集群的冷热分离是怎么实现的。
0x04 日志索引管理
ES中的文档数据是保存在索引(index)之中的。索引可以划分多个分片(shard)分布在不同的节点上,并通过配置一定的备份数实现高可用。
对于日志数据,通常把每个应用、每天的日志保存到不同的索引中(这是以下很多讨论的前提)。要承接公司上千个应用的海量日志,又要应对每个应用每天不同的数据量,如何有效管理这些日志索引,成为Dragonfly能否提供稳定和快速服务的关键。下面将分多个方面为你介绍。你不会在官方文档中直接找到这些知识,它们来源于我们多年的实战经验。
4.1 索引预创建
当有一个写入请求,而请求中指定的索引不存在时,ES会自动创建一个5分片的新索引。因为要完成寻找合适的节点、创建主分片、创建备份分片、广播新的集群信息、更新字段mapping等一系列的操作,创建一个新索引是耗时的。根据集群规模、新索引的分片数量而不同,在我们的集群中创建一个新索引需要几秒到几十秒的时间。如果要在新的一天开始的时刻,大量新一天的日志同时到来时触发创建上千个索引,必然会造成集群的长时间服务中断。因此,每天的索引必须提前创建。
此外,还有一个必须提前创建索引的关键原因,就是ES索引的分片数在创建时就必须给定,不能再动态增加(早期版本还不能减少,ES 5.x开始提供了shrink操作)。在两种情况下会造成问题:
●如果某个应用的日志量特别大,如果我们使用过少的分片数(如默认的5个分片),就会造成严重的热点问题,也就是分配到这个大索引分片的节点,将要处理更多的写入和查询数据量,成为集群的瓶颈。
●大部分的应用日志量非常小,如果分配了过多的分片数,就会造成集群需要维护的活跃分片数目很大,在节点间定时同步的集群信息数据也会很大,在集群繁忙的时候更容易出现请求超时,在集群出现故障的时候恢复时间也更长。
出于以上考虑,必须提前创建索引,并为不同应用的索引指定合适的分片数量。分片的数量可以由以下公式计算:
n_shards=avg_index_size/ size_per_shard * magnified_factor
其中:
●avg_index_size为前N天这个应用索引大小的指数移动平均值(日期越靠近、权重越大)
●size_per_shard为期望每个分片的大小。分片过大容易造成上述热点问题,同时segment merge操作的开销更大(下面详细介绍),在需要移动分片时耗时也会较久;而过小又会造成集群分片总数过多。因此要选取一个均衡的大小,我们使用的是20GB。
●magnified_factor为扩大系数,是我们根据公司特有的促销场景引入的。在促销日,业务请求数会数倍甚至数十倍于平时,日志量也会相应增长,因此我们需要在促销日为索引增加更多分片数。
索引预创建的操作我们放在前一天的清早(后面会看到,开销很大的操作我们都放在夜间和凌晨)进行。即今天凌晨会根据之前索引大小的EMA及上述公式计算出分片数,创建明天的索引。
4.2 替补索引
这是很有意思的一个概念,你不会在任何其他ES相关的文章找到它(如果有,请注意百分百是抄袭:)
它解决的是这样的问题:即使我们已经提前估算出一个应用的日志索引的分片数,但是仍然会有异常情况。有时你会发现某个应用某一天的日志忽然增加了很多,可能是开发打开了DEBUG级别开关查问题,也可能在做压测,或者可能是bug死循环的打印了无数stacktrace。有时是一个新接入的应用,由于没有历史索引,所以并不能估算出需要的分片数。以上情况都有可能引起分片数不足的问题。
记得上面提到过索引在创建后就不能再动态调整分片数了,怎么破?
让我们来新创建一个替补索引(substitude index)吧,这一天接下来的所有日志都会写到这里。替补索引的命名,我们会在原索引名的基础上加上-subst后缀,因此用户在查询今天的日志时,查询接口仍可以通过一定的规则指定同时使用今天的“正选”索引和替补索引。
我们定时扫描当天索引的平均分片大小,一旦发现某个索引的分片大小过大,就及时创建替补索引。注意,创建替补索引时仍需指定分片数,这是根据当天已过去的小时数比上还剩下的小时数,以及当时已经写入的数据量估算得出的。
替补索引还有一种使用场景。有时促销是在晚上进行的,一到促销开始,请求量和日志量会出现一个非常大的尖峰。而由于已经写入了大半天的日志,分片已经比较大,这时任何的写入都可能引起更大规模的segment merge(熟悉ES的同学会知道,每次refresh会生成新的segment,小的segment会不断merge变成更大的segment,越大的segment merge时对磁盘IO和CPU的开销占用越大。这相当于HBase的compaction行为,也同样会有写放大问题),会使写入速率受到限制。而如果这时切换到新的索引写入(场上球员请全部给我下来~),就可以减轻merge的影响,对保障流量尖峰时ES集群的写入速率非常有帮助。
这种促销日的替补索引是提前创建的。分片数的计算、以及还有可能使用到“替补的替补”,就不再赘述了。
4.3 Force Merge
当数据写入ES时先产生小的segment。segment会占用堆内存,数量过多对查询时间也有影响。因此ES会按一定的策略进行自动合并segment的动作,这前文已经提过。此外,ES还提供force merge的方法(在早期版本称为optimize),通过调用此方法可以进一步强化merge的效果。
具体的,我们在凌晨执行定时任务,对前一天的索引,按照分片大小以及每个segment 500MB的期望值,计算出需要合并到的segment数量,然后执行force merge。
通过这个操作,我们可以节省很多堆内存。具体每个节点segment的内存占用,可以在_nodes//stats api中查看到。当segment memory一项占用heap大小2/3以上,很容易造成各种gc问题。
另外由于force merge操作会大量读写磁盘,要保证只在SSD服务器上执行。
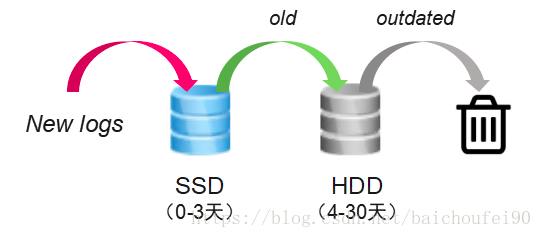
4.4 冷热分离
最初搭建ES集群时,为了保证读写速率,我们使用的都是SSD类型的服务器。但由于SSD磁盘成本高,容量小,随着接入应用越来越多,不得不缩短日志保存天数,一度只能提供7天的日志,用户开始产生抱怨。
我们自然而然产生了冷热分离的想法。当时在网上并不能找到ES冷热分离部署的案例,但出于曾经翻阅过官方文档多遍后对ES各种api的熟悉,我们认为是可行的。
●首先,在节点的配置文件中通过node.tag属性使用不同的标签可以区分不同类型的服务器(如硬件类型,机柜等);
●通过index.routing.allocation.include/exclude的索引设置可以指定索引分片只能分配在某种tag的服务器上;
●利用以上方法,我们在创建的新的索引时,指定只分配在热数据服务器(SSD服务器)上。使拥有强劲磁盘IO和CPU性能的热数据服务器承接了新日志的写入和查询;
●设置夜间定时任务,将N天前的索引修改为只能分配在冷数据服务器(HDD服务器)上。使访问频率降低的索引relocate到大磁盘容量的服务器中保存。
通过以上冷热分离的部署方法,我们只增加了少量大磁盘容量的服务器(成本比SSD类型的服务器还低很多),就将日志保存时长增加到了30天,部分应用可以按需保存更长时间。
4.5 日志归档
从上面可以看出,通过冷热分离,热数据服务器只存放最近3天的日志索引,其余27天的索引都存放在冷数据服务器上。这样的话,冷数据服务器的segment memory将非常大,远超过官方文档建议的不超过32GB的heap配置。如果要增加heap到32GB以上,会对性能有一定影响。
考虑到越久远的日志,查询的可能性越低,我们将7天以前的日志进行了归档——也就是close索引的操作。close的索引是不占用内存的,也就解决了冷数据服务器的heap使用问题。
Dragonfly前端放开放了归档日志管理的页面,用户如需查询7天前的日志,可以自助打开已经归档的日志——也就是重新open已经close掉的索引。
0x05 日志写入降级策略
前面已经提到过,我们公司促销高峰时的日志量会达到平日的数十倍。我们不可能配备足够支撑促销高峰期日志量的服务器规模,因为那样的话在全年大部分时间内很多服务器资源是浪费的。而在服务器规模有限的情况下,ES集群的写入能力是有限的,如果不采取任何措施,在促销高峰期、以及万一集群有故障发生时,接入的日志将发生堆积,从而造成大面积的写入延迟,用户将完全无法查询最新的日志。此时如果有业务故障发生但无法通过日志来分析的话,问题会非常致命。
因此就需要有合理的降级措施和预案,以保证当日志流入速率大于日志写入ES集群的速率时,Dragonfly仍能提供最大限度的服务。我们首先需要做出取舍,制订降级服务的目标,最终我们采用的是:保证各个应用都有部分服务器的日志可以实时查询。
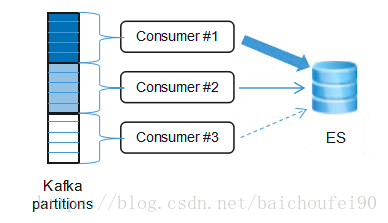
唯品会的日志,是从应用服务器先采集到Kafka做缓存的,因此可以在读取Kafka数据写入ES的过程中做一些处理。严格来说如何实现这一目标并不属于Elasticsearch的范畴。
要达到降级服务目标,我们需要设计一套组合拳:
●日志上传到Kafka时,使用主机名作为partitioning hash key,即同一台应用服务器的日志会采集到同一个Kafka topic的partition中;
●在消费Kafka topic时,使用同一个consumer group的多个实例,每个consumer实例设置不同的处理优先级;
●对Kafka consumer按照优先级不同,配置不同的写ES的线程数。优先级越高,写入线程数越多,写入速率越快;优先级越低,写入线程数越少,甚至暂停写入;
●这样就能保证高优先级的consumer能够实时消费某些partition并写入到ES中,通过hashing采集到那些被实时消费的partition的主机日志,也将在ES中可以被实时查询;
●随着度过日志流量高峰,当ES集群支持高优先级consumer的日志写入没有压力时,可以逐步增加次高优先级consumer的写入线程数。直到对应partition的堆积日志被消费完,又可以对更低优先级的consumer进行同样的调整;
●最终所有堆积的日志都被消费完,降级结束。
0x06 结语
除了核心组件Elasticsearch,Dragonfly日志系统还在日志格式规范、日志采集客户端、查询前端、规则告警、错误日志异常检测等方面做了很多的工作,有机会再跟大家继续分享。