以下内容摘自各个博客,文中会进行标注,做个人概览用,没有仔细斟酌对错。
CTPN(2016)
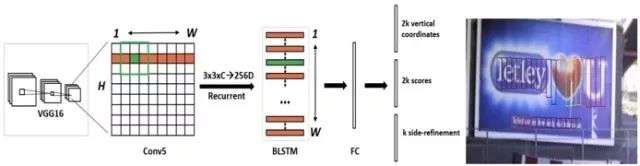
CTPN是目前流传最广、影响最大的开源文本检测模型,可以检测水平或微斜的文本行。文本行可以被看成一个字符sequence,而不是一般物体检测中单个独立的目标。同一文本行上各个字符图像间可以互为上下文,在训练阶段让检测模型学习图像中蕴含的这种上下文统计规律,可以使得预测阶段有效提升文本块预测准确率。【1】
- 用VGG16的前5个Conv stage(到conv5)得到feature map(W*H*C)
- 在Conv5的feature map的每个位置上取3*3*C的窗口的特征,这些特征将用于预测该位置k个anchor(anchor的定义和Faster RCNN类似)对应的类别信息,位置信息。
- 将每一行的所有窗口对应的3*3*C的特征(W*3*3*C)输入到RNN(BLSTM)中,得到W*256的输出
- 将RNN的W*256输入到512维的fc层
- c层特征输入到三个分类或者回归层中。第二个2k scores 表示的是k个anchor的类别信息(是字符或不是字符)。第一个2k vertical coordinate和第三个k side-refinement是用来回归k个anchor的位置信息。2k vertical coordinate表示的是bounding box的高度和中心的y轴坐标(可以决定上下边界),k个side-refinement表示的bounding box的水平平移量。这边注意,只用了3个参数表示回归的bounding box,因为这里默认了每个anchor的width是16,且不再变化(VGG16的conv5的stride是16)。回归出来的box如Fig.1中那些红色的细长矩形,它们的宽度是一定的。
- 用简单的文本线构造算法,把分类得到的文字的proposal(图Fig.1(b)中的细长的矩形)合并成文本线【2】
RRPN(2017)
基于旋转区域候选网络(RRPN, Rotation Region Proposal Networks)的方案,将旋转因素并入经典区域候选网络(如Faster RCNN)。【1】
整体结构和Faster-RCNN可以说是一样的。训练阶段,一个文本区域的ground truth用一个5元组(x,y,h,w,θ)来表示,(x,y)表示边界框的几何中心的坐标。高度h表示短边的长度,宽度w表示长边的长度,而θ表示x正轴到边界框长边的角度。统的锚点公使用大小(scale)和比例(aspect ratio)两个变量,作者对传统的锚点进行了改进,以适应自然场景下的文本检测。首先,新增了方向这个变量,加入6个方向角:−π/6、0、π/6、π/3、π/2、2π/3。其次,由于文本区域的形状比较特殊,将比例调整为:1:2、1:5和1:8。大小还是8,16和32保持不变。【3】

RRPN中方案中提出了旋转感兴趣区域(RRoI,Rotation Region-of-Interest)池化层,将任意方向的区域建议先划分成子区域,然后对这些子区域分别做max pooling、并将结果投影到具有固定空间尺寸小特征图上。【1】
EAST(2017)
EAST(Efficient and Accuracy Scene Text detection pipeline)模型中,首先使用全卷积网络(FCN)生成多尺度融合的特征图,然后在此基础上直接进行像素级的文本块预测。该模型中,支持旋转矩形框、任意四边形两种文本区域标注形式。对应于四边形标注,模型执行时会对特征图中每个像素预测其到四个顶点的坐标差值。对应于旋转矩形框标注,模型执行时会对特征图中每个像素预测其到矩形框四边的距离、以及矩形框的方向角。该模型检测英文单词效果较好、检测中文长文本行效果欠佳。或许,根据中文数据特点进行针对性训练后,检测效果还有提升空间。【1】
- Feature extractor stem: 利用Inception的思想,即不同尺寸的卷积核的组合可以适应多尺度目标的检测,作者在这里采用PVANet模型,提取不同尺寸卷积核下的特征并用于后期的特征组合。
- Feature merging branch: 在这一部分用来组合特征,并通过上池化和concat恢复到原图的尺寸。
- Output layer: ①通过一个(1x1,1)的卷积核获得score_map。score_map与原图尺寸一致,每一个值代表此处是否有文字的可能性。 ②通过一个(1x1,4)的卷积核获得RBOX 的geometry_map。有四个通道,分别代表每个像素点到文本矩形框上,右,底,左边界的距离。另外再通过一个(1x1, 1)的卷积核获得该框的旋转角,这是为了能够识别出有旋转的文字。 ③通过一个(1x1,8)的卷积核获得QUAD的geometry_map,八个通道分别代表每个像素点到任意四边形的四个顶点的距离。
- Threshold&NMS过滤: 在假设来自附近像素的几何图形倾向于高度相关的情况下,逐行合并几何图形,并且在合并同一行中的几何图形时将迭代合并当前遇到的几何图形。【4】

SegLInk(2017)
SegLink模型的标注数据中,先将每个单词切割为更易检测的有方向的小文字块(segment),然后用邻近连接(link )将各个小文字块连接成单词。这种方案方便于识别长度变化范围很大的、带方向的单词和文本行。【1】
阅读原论文Section 3.1部分很好理解。

- Given an input image I of size wI × hI , the model outputs a fixed number of segments and links, which are then filtered by their confidence scores and combined into whole word bounding boxes. A bounding box is a rotated rectangle denoted by b = (xb, yb, wb, hb, θb), where xb, yb are the coordinates of the center, wb, hb the width and height, and θb the rotation angle.
- Segments and links are detected on 6 of the feature layers, which are conv4 3, conv7, conv8 2, conv9 2, conv10 2, and conv11.A convolutional predictor with 3 × 3 kernels is added to each of the 6 layers to detect segments and links. We index the feature layers and the predictors by l = 1, . . . , 6.
- We detect segments by estimating the confidence scores and geometric offsets to a set of default boxes [14] on the input image.For simplicity, we only associate one default box with a feature map location.(一些转换公式省略)
- Within-Layer Link Detection: Links are not only necessary for combining segments into whole words but also helpful for separating two nearby words – between two nearby words, the links should be predicted as negative.we define the within-layer neighbors of a segment as its 8-connected neighbors on the same feature layer.A predictor outputs 16 channels for the links to the 8-connected neighboring segments. Every 2 channels are softmax-normalized to get the score of a link.
- Cross-Layer Link Detection: segments of the same word could be detected on multiple layers at the same time, producing redundancies. To address this problem, we further propose another type of links, called cross-layer links.A cross-layer link connects segments on two feature layers with adjacent indexes.Every segment has 4 cross-layer neighbors. The correspondence is ensured by the double-size relationship between the two layers.



Baoguang Shi, Xiang Bai, Serge Belongie. Detecting Oriented Text in Natural Images by Linking Segments, CVPR 2017
PixelLink
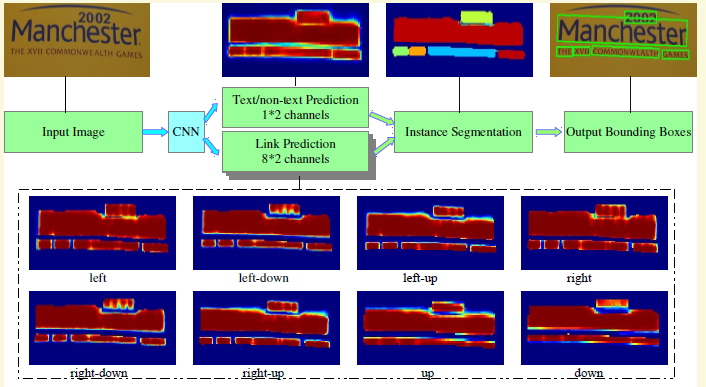
相当于EAST和SegLink的结合,只不过由SegLink中连接segment转变为连接pixel。自然场景图像中一组文字块经常紧挨在一起,通过语义分割方法很难将它们识别开来,所以PixelLink模型尝试用实例分割方法解决这个问题。
- the whole model has two separate headers, one for text/non-text prediction, and the other for link prediction. Softmax is used in both, so their outputs have 1*2=2 and 8*2=16 channels, respectively.
- It is worth noting that, given two neighboring positive pixels, their link are predicted by both of them, and they should be connected when one or both of the two link predictions are positive.
- Bounding boxes of CCs are then extracted through methods like minAreaRect in OpenCV (Its 2014).
Dan Deng, Haifeng Liu, Xuelong Li, Deng Cai. PixelLink: Detecting Scene Text via Instance Segmentation, AAAI 2018
参考文献
【3】论文阅读之R-RPN
【4】EAST: An Efficient and Accurate Scene Text Detector 自然场景下的文字识别(原理及代码理解)