了解到哈希学习是在哈希编码阶段进行的,参考上一节基于hash的ANN框架
哈希学习的目的是:学习一个复杂的哈希功能,y=h(x),把一个输入点x映射成哈希码y,且满足q点的最近邻尽可能与实际结果相近,并且在编码空间的查询也是有效的。要满足这些要求,需考虑以下5个部分:哈希函数、编码空间的相似性、输入空间的相似性、损失函数、优化技术。
一、哈希函数
哈希函数可以是基于线性的、核函数、球面函数、深度神经网络、无参函数。
1.线性哈希函数
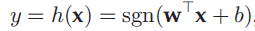
当z>=0时,sgn(z)=1,当z<0时,sgn(z)=-1(或0)。w是映射向量,b是偏移量。
2.核哈希函数
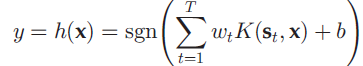
st表示从数据集中随意获得的代表样本或者是数据集的聚类中心,wt表示权重。
3.无参哈希函数
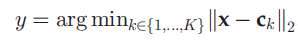
常用于基于量化的方案,其中c1,c2…ck表示中心点,可由k-means等得到,y是正整数。距离(例如汉明距离)直接从哈希码中计算得到,且使用对应中心的哈希码计算距离。
总结:线性函数可以被有效评估,核函数和无参哈希由于可扩展性,他们的查询准确性较高。哈希函数一般不用做哈希学习的分类标准,是因为线性哈希函数都能被扩展为非线性哈希函数。
二、相似性
相似性包括编码空间相似性、输入空间相似性。
2.1 输入空间相似性
在输入空间中,任意一对点(xi,xj)之间的距离d主要是欧式距离,||xi-xj||2,相似性s被定义为关于距离d的函数,典型函数是高斯相似性、余弦相似性、语义相似性(按顺序)
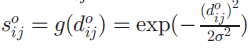
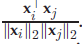
语义相似性是二值化的,如果两个点属于同一类,则s=0,反之为1.
2.2 编码空间相似性
在编码空间中,两个点(yi,yj)之间的距离主要是汉明距离,定义是不同点的数量,公式如下:
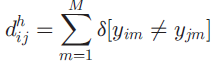
三、损失函数
损失函数的设计规则是保持相似性顺序,例如,使从哈希码得到的最近邻查询结果和从输入空间获得的真实查询结果最小化。主要研究的有成对相似性保持、多相似性保持、隐式相似性保持、基于量化的方法。
四、优化技术
哈希函数参数优化来自两方面:1.sgn函数 2.时间复杂性很高
五、分类
根据以上五个方面,现有哈希学习函数分类可分为:成对相似性保持、多相似性保持、隐式相似性保持、和量化方法。
注:本文内容来源:A Survey on Learning to Hash如果是入门级同学,不建议看此篇论文