什么是Hystrix?
在分布式系统中,不可避免地会出现许多依赖的服务不可用的情况。Hystrix通过实现容错和延时容忍逻辑来实现对相互依赖的分布式服务的控制。Hystrix主要通过隔离服务的调用,阻止级联的服务调用失败以及提供降级策略来提升系统的整体可伸缩性(resiliency)。
Hystrix 在2011年开始由Netflix的API团队开发,并逐渐在Netflix内部得到广泛使用。
Hystrix的目的
Hystrix被设计用来:
- 通过引入第三方客户端库实现对保护应用避免受延时和失败的服务调用带来的影响。
- 在复杂的系统中防止级联故障(cascading failures)
- 快速失败,快速回复
- 回退和优雅降级
- 提供近实时的监控、告警和操作控制。
Hystrix解决什么问题?
分布式系统中存在众多的服务,每个服务都难免出现不可用的情况。如果主应用(关注的应用)没有和这些不可用的服务隔离,将遭受被这些服务拖垮的危险。
例如,对于一个依赖30个可用性为99.99%服务的应用,其本身的可用性将是:
0.9999^30=99.7%
这意味着,10,000,000次前端中,将有30,000次失败
每个月中,应用不可用的时间将至少是2小时
实际情况往往比这更差。
在一切都正常时,客户发来的请求的调用示意如下:
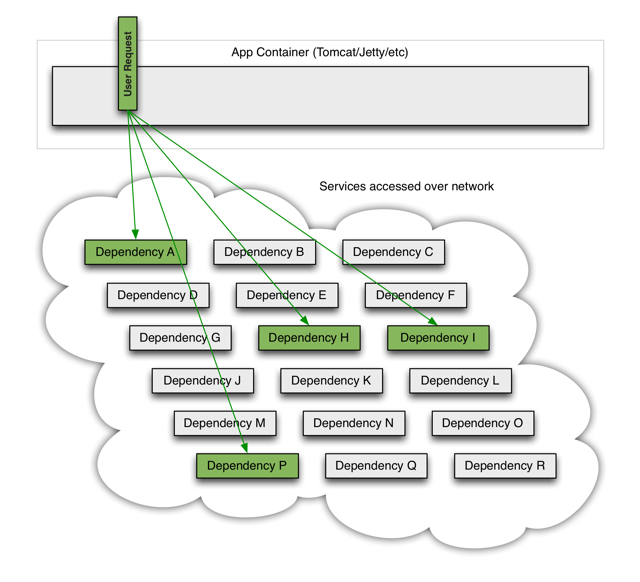
当某一个后台服务出现超时,或者不可用,他将阻塞整个请求: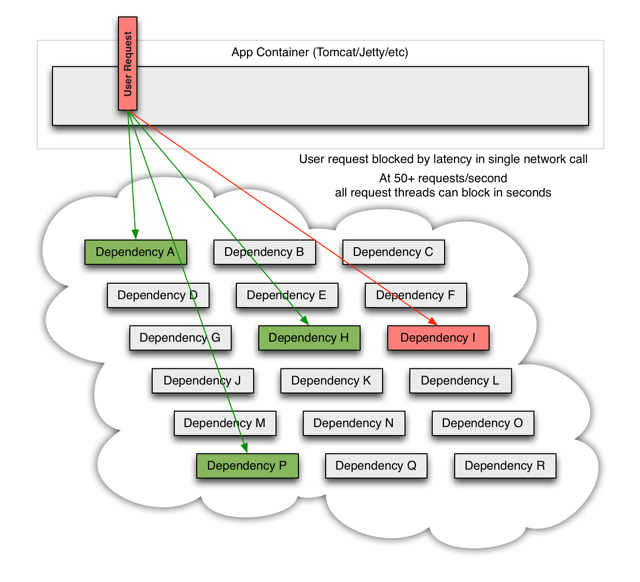
对于访问量大的后台服务,如果一旦出现超时,数秒内真个应用的系统资源可能会被立刻耗尽。
在应用中,任何一个通过网络实现的外部调用都是可能失败的。更甚的是,这些不可用的服务,将会逐渐耗尽所有调用其提供服务的其他应用的资源,最终可能导致整个系统的雪崩。
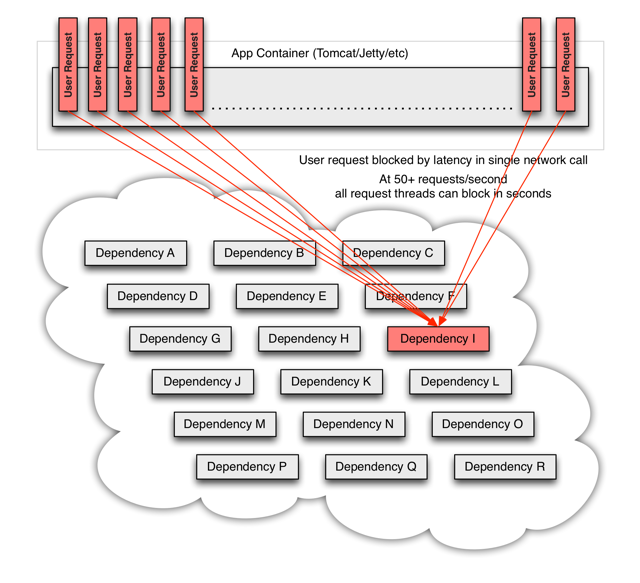
对于通过第三方组件实现网络访问的情况,这种问题更加严重。第三方组件对于应用来说是一个黑盒,其实现细节不可见,对于不同的客户端组件,网络和资源的配置情况各不相同,并且通常难以修改和监控。
更糟糕的是,还可能存在那些我们并不知道的由第三方组件引入的可变的依赖,引起巨大的网络资源消耗或者错误的远程调用。
网络不可用;服务或者节点失效;新组件引入的功能改变;组件的bug。凡此种种,都是需要隔离起来的错误,避免一个服务的不可用导致整个应用或者系统的不可用。
##Hystrix 遵循的设计原则:
- 防止单个依赖耗尽整个容器用户线程。
- 采用去掉负荷和快速失败,而不是排队
- 在任何可行的情况下通过降级避免失败
- 通过隔离策略(隔离舱bulkhead,泳道swimlan,断路器circuit break 设计模式)来限制单个依赖可能引起的影响
- 通过近实时的指标、监控和告警来降低错误发现时间
- 配置修改快速生效,支持动态属性设置,提供实时修改配置功能
- 避免应用受到所有的依赖的失败带来的影响,而不只是网络拥堵
Hystrix如何实现其目标?
to be continue…