分享一下我老师大神的人工智能教程!零基础,通俗易懂!http://blog.csdn.net/jiangjunshow
也欢迎大家转载本篇文章。分享知识,造福人民,实现我们中华民族伟大复兴!
决策树的概念其实不难理解,下面一张图是某女生相亲时用到的决策树:
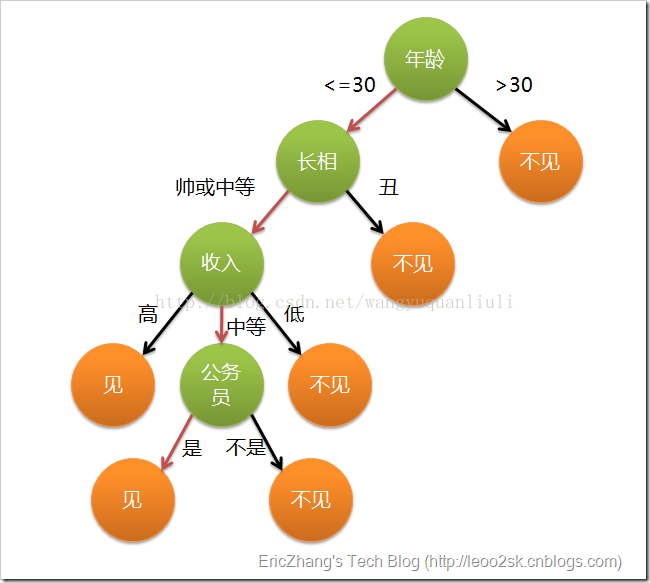
基本上可以理解为:一堆数据,附带若干属性,每一条记录最后都有一个分类(见或者不见),然后根据每种属性可以进行划分(比如年龄是>30还是<=30),这样构造出来的一棵树就是我们所谓的决策树了,决策的规则都在节点上,通俗易懂,分类效果好。
那为什么跟节点要用年龄,而不是长相?这里我们在实现决策树的时候采用的是ID3算法,在选择哪个属性作为节点的时候采用信息论原理,所谓的信息增益。信息增益指原有数据集的熵-按某个属性分类后数据集的熵。信息增益越大越好(说明按某个属性分类后比较纯),我们会选择使得信息增益最大的那个属性作为当层节点的标记,再进行递归构造决策树。
首先我们构造数据集:
- def createDataSet():
- dataSet = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]
- features = ['no surfacing','flippers']
- return dataSet,features
构造决策树:(采用python字典来递归构造,一些代码看看就能看懂)
- def treeGrowth(dataSet,features):
- classList = [example[-1] for example in dataSet]
- if classList.count(classList[0])==len(classList):
- return classList[0]
- if len(dataSet[0])==1:# no more features
- return classify(classList)
- bestFeat = findBestSplit(dataSet)#bestFeat is the index of best feature
- bestFeatLabel = features[bestFeat]
- myTree = {bestFeatLabel:{}}
- featValues = [example[bestFeat] for example in dataSet]
- uniqueFeatValues = set(featValues)
- del (features[bestFeat])
- for values in uniqueFeatValues:
- subDataSet = splitDataSet(dataSet,bestFeat,values)
- myTree[bestFeatLabel][values] = treeGrowth(subDataSet,features)
- return myTree
当没有多余的feature,但是剩下的样本不完全是一样的类别是,采用出现次数多的那个类别:
- def classify(classList):
- '''''
- find the most in the set
- '''
- classCount = {}
- for vote in classList:
- if vote not in classCount.keys():
- classCount[vote] = 0
- classCount[vote] += 1
- sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse = True)
- return sortedClassCount[0][0]
寻找用于分裂的最佳属性:(遍历所有属性,算信息增益)
- def findBestSplit(dataset):
- numFeatures = len(dataset[0])-1
- baseEntropy = calcShannonEnt(dataset)
- bestInfoGain = 0.0
- bestFeat = -1
- for i in range(numFeatures):
- featValues = [example[i] for example in dataset]
- uniqueFeatValues = set(featValues)
- newEntropy = 0.0
- for val in uniqueFeatValues:
- subDataSet = splitDataSet(dataset,i,val)
- prob = len(subDataSet)/float(len(dataset))
- newEntropy += prob*calcShannonEnt(subDataSet)
- if(baseEntropy - newEntropy)>bestInfoGain:
- bestInfoGain = baseEntropy - newEntropy
- bestFeat = i
- return bestFeat
选择完分裂属性后,就行数据集的分裂:
- def splitDataSet(dataset,feat,values):
- retDataSet = []
- for featVec in dataset:
- if featVec[feat] == values:
- reducedFeatVec = featVec[:feat]
- reducedFeatVec.extend(featVec[feat+1:])
- retDataSet.append(reducedFeatVec)
- return retDataSet
计算数据集的熵:
- def calcShannonEnt(dataset):
- numEntries = len(dataset)
- labelCounts = {}
- for featVec in dataset:
- currentLabel = featVec[-1]
- if currentLabel not in labelCounts.keys():
- labelCounts[currentLabel] = 0
- labelCounts[currentLabel] += 1
- shannonEnt = 0.0
- for key in labelCounts:
- prob = float(labelCounts[key])/numEntries
- if prob != 0:
- shannonEnt -= prob*log(prob,2)
- return shannonEnt
下面根据上面构造的决策树进行数据的分类:
- def predict(tree,newObject):
- while isinstance(tree,dict):
- key = tree.keys()[0]
- tree = tree[key][newObject[key]]
- return tree
- if __name__ == '__main__':
- dataset,features = createDataSet()
- tree = treeGrowth(dataset,features)
- print tree
- print predict(tree,{'no surfacing':1,'flippers':1})
- print predict(tree,{'no surfacing':1,'flippers':0})
- print predict(tree,{'no surfacing':0,'flippers':1})
- print predict(tree,{'no surfacing':0,'flippers':0})
结果如下:
决策树是这样的:
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
四个预测:
yes
no
no
no
和给定的数据集分类一样(预测的数据是从给定数据集里面抽取的,当然一般数据多的话,会拿一部分做训练数据,剩余的做测试数据)
归纳一下ID3的优缺点:
优点:实现比较简单,产生的规则如果用图表示出来的话,清晰易懂,分类效果好
缺点:只能处理属性值离散的情况(连续的用C4.5),在选择最佳分离属性的时候容易选择那些属性值多的一些属性。
最近开始学习machine learning方面的内容,大致浏览了一遍《machine learning in action》一书,大概了解了一些常用的算法如knn,svm等具体式干啥的。
在kaggle上看到一个练手的项目:digit classification,又有良好的数据,于是打算用这个项目把各种算法都跑一遍,加深自己对各算法的研究,该文会不断更新。。。。。。
我们的数据集是mnist,链接:http://yann.lecun.com/exdb/mnist/
mnist的结构如下,选取train-images
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
呐,由于智商比较拙急,看了这个形式居然没看明白,所以特此写出要注意的点,送给同样没看明白的童鞋。
首先该数据是以二进制存储的,我们读取的时候要以'rb'方式读取,其次,真正的数据只有[value]这一项,其他的[type]等只是来描述的,并不真正在数据文件里面。
由offset我们可以看出真正的pixel式从16开始的,一个int 32字节,所以在读取pixel之前我们要读取4个 32 bit integer,也就是magic number,number of images,number of rows,number of columns,读取二进制文件用struct比较方便,struct.unpack_from('>IIII',buf,index)表示按照大端方式读取4个int.
虽然数据集网站写着“Users of Intel processors and other low-endian machines must flip the bytes of the header.”,而我的电脑就是intel处理器,但是我尝试了一把还是得用大端方式读,读出来才是“2051 60000 28 28”,用小端方式读取就不正确了,这个小小实验一把就行。
下面先把数据文件直观的表现出来,用matplotlib把二进制文件用图像表现出来。具体如下:
- # -*- coding:utf-8
- import numpy as np
- import struct
- import matplotlib.pyplot as plt
- filename = 'train-images.idx3-ubyte'
- binfile = open(filename,'rb')#以二进制方式打开
- buf = binfile.read()
- index = 0
- magic, numImages, numRows, numColums = struct.unpack_from('>IIII',buf,index)#读取4个32 int
- print magic,' ',numImages,' ',numRows,' ',numColums
- index += struct.calcsize('>IIII')
- im = struct.unpack_from('>784B',buf,index)#每张图是28*28=784Byte,这里只显示第一张图
- index += struct.calcsize('>784B' )
决策树的概念其实不难理解,下面一张图是某女生相亲时用到的决策树:
基本上可以理解为:一堆数据,附带若干属性,每一条记录最后都有一个分类(见或者不见),然后根据每种属性可以进行划分(比如年龄是>30还是<=30),这样构造出来的一棵树就是我们所谓的决策树了,决策的规则都在节点上,通俗易懂,分类效果好。
那为什么跟节点要用年龄,而不是长相?这里我们在实现决策树的时候采用的是ID3算法,在选择哪个属性作为节点的时候采用信息论原理,所谓的信息增益。信息增益指原有数据集的熵-按某个属性分类后数据集的熵。信息增益越大越好(说明按某个属性分类后比较纯),我们会选择使得信息增益最大的那个属性作为当层节点的标记,再进行递归构造决策树。
首先我们构造数据集:
- def createDataSet():
- dataSet = [[1,1,'yes'],[1,1,'yes'],[1,0,'no'],[0,1,'no'],[0,1,'no']]
- features = ['no surfacing','flippers']
- return dataSet,features
构造决策树:(采用python字典来递归构造,一些代码看看就能看懂)
- def treeGrowth(dataSet,features):
- classList = [example[-1] for example in dataSet]
- if classList.count(classList[0])==len(classList):
- return classList[0]
- if len(dataSet[0])==1:# no more features
- return classify(classList)
- bestFeat = findBestSplit(dataSet)#bestFeat is the index of best feature
- bestFeatLabel = features[bestFeat]
- myTree = {bestFeatLabel:{}}
- featValues = [example[bestFeat] for example in dataSet]
- uniqueFeatValues = set(featValues)
- del (features[bestFeat])
- for values in uniqueFeatValues:
- subDataSet = splitDataSet(dataSet,bestFeat,values)
- myTree[bestFeatLabel][values] = treeGrowth(subDataSet,features)
- return myTree
当没有多余的feature,但是剩下的样本不完全是一样的类别是,采用出现次数多的那个类别:
- def classify(classList):
- '''''
- find the most in the set
- '''
- classCount = {}
- for vote in classList:
- if vote not in classCount.keys():
- classCount[vote] = 0
- classCount[vote] += 1
- sortedClassCount = sorted(classCount.iteritems(),key = operator.itemgetter(1),reverse = True)
- return sortedClassCount[0][0]
寻找用于分裂的最佳属性:(遍历所有属性,算信息增益)
- def findBestSplit(dataset):
- numFeatures = len(dataset[0])-1
- baseEntropy = calcShannonEnt(dataset)
- bestInfoGain = 0.0
- bestFeat = -1
- for i in range(numFeatures):
- featValues = [example[i] for example in dataset]
- uniqueFeatValues = set(featValues)
- newEntropy = 0.0
- for val in uniqueFeatValues:
- subDataSet = splitDataSet(dataset,i,val)
- prob = len(subDataSet)/float(len(dataset))
- newEntropy += prob*calcShannonEnt(subDataSet)
- if(baseEntropy - newEntropy)>bestInfoGain:
- bestInfoGain = baseEntropy - newEntropy
- bestFeat = i
- return bestFeat
选择完分裂属性后,就行数据集的分裂:
- def splitDataSet(dataset,feat,values):
- retDataSet = []
- for featVec in dataset:
- if featVec[feat] == values:
- reducedFeatVec = featVec[:feat]
- reducedFeatVec.extend(featVec[feat+1:])
- retDataSet.append(reducedFeatVec)
- return retDataSet
计算数据集的熵:
- def calcShannonEnt(dataset):
- numEntries = len(dataset)
- labelCounts = {}
- for featVec in dataset:
- currentLabel = featVec[-1]
- if currentLabel not in labelCounts.keys():
- labelCounts[currentLabel] = 0
- labelCounts[currentLabel] += 1
- shannonEnt = 0.0
- for key in labelCounts:
- prob = float(labelCounts[key])/numEntries
- if prob != 0:
- shannonEnt -= prob*log(prob,2)
- return shannonEnt
下面根据上面构造的决策树进行数据的分类:
- def predict(tree,newObject):
- while isinstance(tree,dict):
- key = tree.keys()[0]
- tree = tree[key][newObject[key]]
- return tree
- if __name__ == '__main__':
- dataset,features = createDataSet()
- tree = treeGrowth(dataset,features)
- print tree
- print predict(tree,{'no surfacing':1,'flippers':1})
- print predict(tree,{'no surfacing':1,'flippers':0})
- print predict(tree,{'no surfacing':0,'flippers':1})
- print predict(tree,{'no surfacing':0,'flippers':0})
结果如下:
决策树是这样的:
{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}}
四个预测:
yes
no
no
no
和给定的数据集分类一样(预测的数据是从给定数据集里面抽取的,当然一般数据多的话,会拿一部分做训练数据,剩余的做测试数据)
归纳一下ID3的优缺点:
优点:实现比较简单,产生的规则如果用图表示出来的话,清晰易懂,分类效果好
缺点:只能处理属性值离散的情况(连续的用C4.5),在选择最佳分离属性的时候容易选择那些属性值多的一些属性。
最近开始学习machine learning方面的内容,大致浏览了一遍《machine learning in action》一书,大概了解了一些常用的算法如knn,svm等具体式干啥的。
在kaggle上看到一个练手的项目:digit classification,又有良好的数据,于是打算用这个项目把各种算法都跑一遍,加深自己对各算法的研究,该文会不断更新。。。。。。
我们的数据集是mnist,链接:http://yann.lecun.com/exdb/mnist/
mnist的结构如下,选取train-images
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
呐,由于智商比较拙急,看了这个形式居然没看明白,所以特此写出要注意的点,送给同样没看明白的童鞋。
首先该数据是以二进制存储的,我们读取的时候要以'rb'方式读取,其次,真正的数据只有[value]这一项,其他的[type]等只是来描述的,并不真正在数据文件里面。
由offset我们可以看出真正的pixel式从16开始的,一个int 32字节,所以在读取pixel之前我们要读取4个 32 bit integer,也就是magic number,number of images,number of rows,number of columns,读取二进制文件用struct比较方便,struct.unpack_from('>IIII',buf,index)表示按照大端方式读取4个int.
虽然数据集网站写着“Users of Intel processors and other low-endian machines must flip the bytes of the header.”,而我的电脑就是intel处理器,但是我尝试了一把还是得用大端方式读,读出来才是“2051 60000 28 28”,用小端方式读取就不正确了,这个小小实验一把就行。
下面先把数据文件直观的表现出来,用matplotlib把二进制文件用图像表现出来。具体如下:
- # -*- coding:utf-8
- import numpy as np
- import struct
- import matplotlib.pyplot as plt
- filename = 'train-images.idx3-ubyte'
- binfile = open(filename,'rb')#以二进制方式打开
- buf = binfile.read()
- index = 0
- magic, numImages, numRows, numColums = struct.unpack_from('>IIII',buf,index)#读取4个32 int
- print magic,' ',numImages,' ',numRows,' ',numColums
- index += struct.calcsize('>IIII')
- im = struct.unpack_from('>784B',buf,index)#每张图是28*28=784Byte,这里只显示第一张图
- index += struct.calcsize('>784B' )
最近开始学习machine learning方面的内容,大致浏览了一遍《machine learning in action》一书,大概了解了一些常用的算法如knn,svm等具体式干啥的。
在kaggle上看到一个练手的项目:digit classification,又有良好的数据,于是打算用这个项目把各种算法都跑一遍,加深自己对各算法的研究,该文会不断更新。。。。。。
我们的数据集是mnist,链接:http://yann.lecun.com/exdb/mnist/
mnist的结构如下,选取train-images
TRAINING SET IMAGE FILE (train-images-idx3-ubyte):
[offset] [type] [value] [description]
0000 32 bit integer 0x00000803(2051) magic number
0004 32 bit integer 60000 number of images
0008 32 bit integer 28 number of rows
0012 32 bit integer 28 number of columns
0016 unsigned byte ?? pixel
0017 unsigned byte ?? pixel
........
xxxx unsigned byte ?? pixel
呐,由于智商比较拙急,看了这个形式居然没看明白,所以特此写出要注意的点,送给同样没看明白的童鞋。
首先该数据是以二进制存储的,我们读取的时候要以'rb'方式读取,其次,真正的数据只有[value]这一项,其他的[type]等只是来描述的,并不真正在数据文件里面。
由offset我们可以看出真正的pixel式从16开始的,一个int 32字节,所以在读取pixel之前我们要读取4个 32 bit integer,也就是magic number,number of images,number of rows,number of columns,读取二进制文件用struct比较方便,struct.unpack_from('>IIII',buf,index)表示按照大端方式读取4个int.
虽然数据集网站写着“Users of Intel processors and other low-endian machines must flip the bytes of the header.”,而我的电脑就是intel处理器,但是我尝试了一把还是得用大端方式读,读出来才是“2051 60000 28 28”,用小端方式读取就不正确了,这个小小实验一把就行。
下面先把数据文件直观的表现出来,用matplotlib把二进制文件用图像表现出来。具体如下:
- # -*- coding:utf-8
- import numpy as np
- import struct
- import matplotlib.pyplot as plt
- filename = 'train-images.idx3-ubyte'
- binfile = open(filename,'rb')#以二进制方式打开
- buf = binfile.read()
- index = 0
- magic, numImages, numRows, numColums = struct.unpack_from('>IIII',buf,index)#读取4个32 int
- print magic,' ',numImages,' ',numRows,' ',numColums
- index += struct.calcsize('>IIII')
- im = struct.unpack_from('>784B',buf,index)#每张图是28*28=784Byte,这里只显示第一张图
- index += struct.calcsize('>784B' )